
Pytorch基础训练库Pytorch-Base-Trainer(支持模型剪枝 分布式训练)
1.Introduction
开源不易,麻烦给个【Star】
尊重原创,转载请注明出处:https://panjinquan.blog.csdn.net/article/details/122662902
GitHub - PanJinquan/Pytorch-Base-Trainer: Pytorch分布式训练框架Pytorch分布式训练框架. Contribute to PanJinquan/Pytorch-Base-Trainer development by creating an account on GitHub.https://github.com/PanJinquan/Pytorch-Base-Trainer考虑到深度学习训练过程都有一套约定成俗的流程,鄙人借鉴**Keras**开发了一套基础训练库: **Pytorch-Base-Trainer(PBT)**; 这是一个基于Pytorch开发的基础训练库,支持以下特征:
- 支持多卡训练训练(DP模式)和分布式多卡训练(DDP模式),参考build_model_parallel
- 支持argparse命令行指定参数,也支持config.yaml配置文件
- 支持最优模型保存ModelCheckpoint
- 支持自定义回调函数Callback
- 支持NNI模型剪枝(L1/L2-Pruner,FPGM-Pruner Slim-Pruner)nni_pruning
- 非常轻便,安装简单
诚然,诸多大公司已经开源基础库,如MMClassification,MMDetection等库; 但碍于这些开源库安装麻烦,依赖库多,版本差异大等问题;鄙人还是开发了一套属于自己的, 比较lowbi的基础训练库Pytorch-Base-Trainer(PBT), 基于PBT可以快速搭建自己的训练工程; 目前,基于PBT完成了通用分类库(PBTClassification),通用检测库(PBTDetection),通用语义分割库( PBTSegmentation)以及,通用姿态检测库(PBTPose)
通用库类型说明****PBTClassification通用分类库集成常用的分类模型,支持多种数据格式,样本重采样PBTDetection通用检测库集成常用的检测类模型,如RFB,SSD和YOLOXPBTSegmentation通用语义分割库集成常用的语义分割模型,如DeepLab,UNet等PBTPose通用姿态检测库集成常用的人体姿态估计模型,如UDP,Simple-base-line
基于PBT框架训练的模型,已经形成了一套完整的Android端上部署流程,支持CPU和GPU
人体姿态估计2DPose人脸+人体检测人像抠图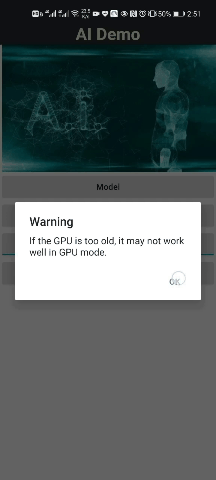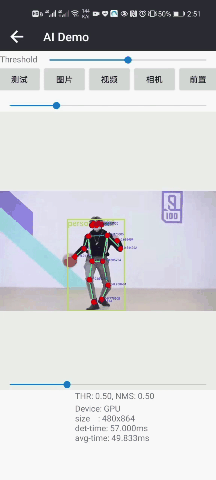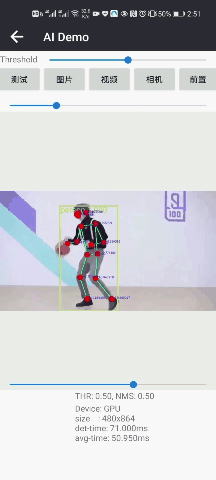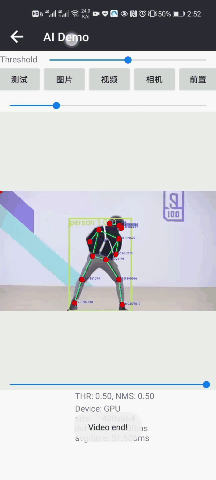

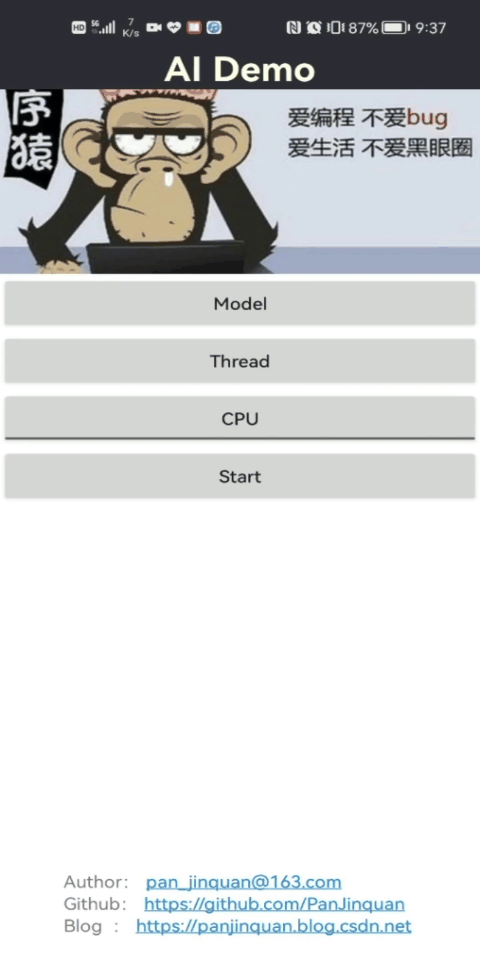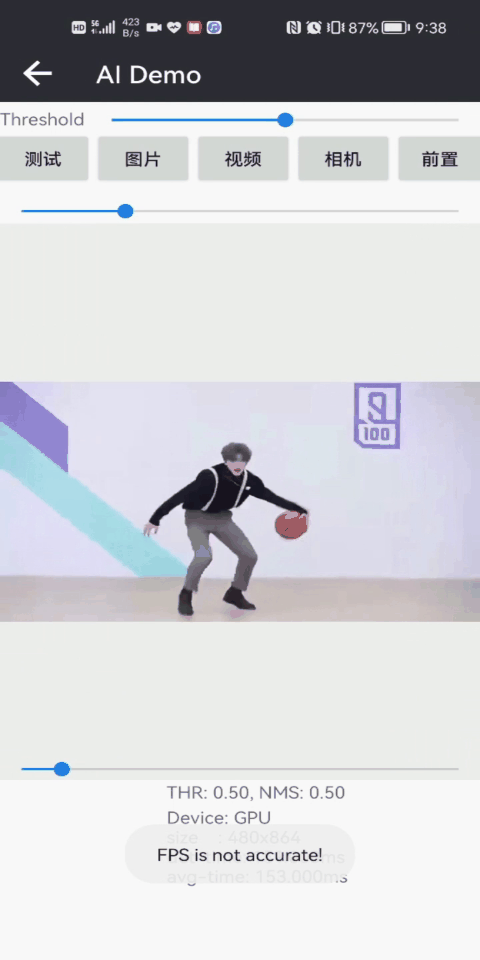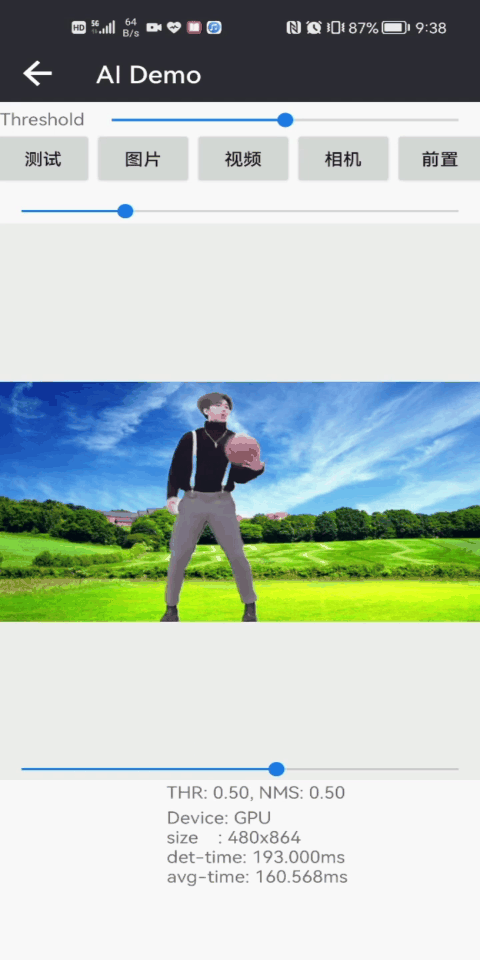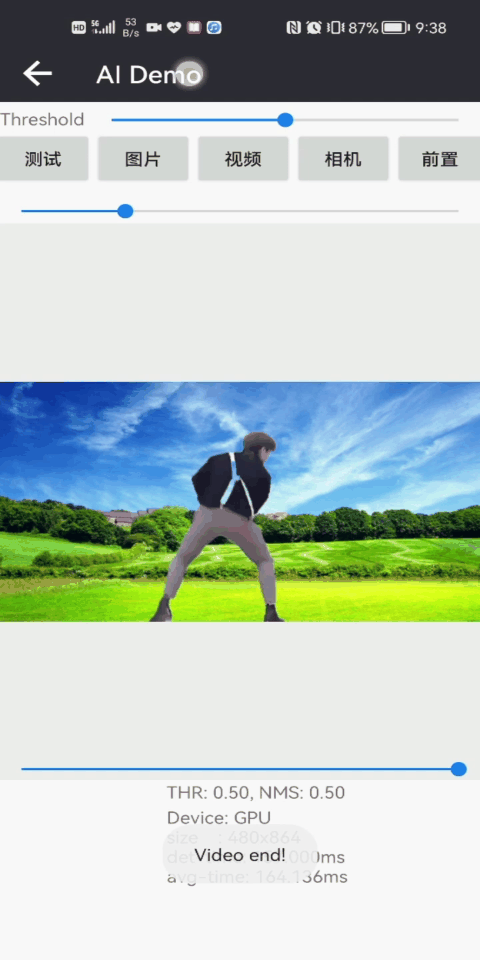 CPU/GPU:70/50msCPU/GPU:30/20msCPU/GPU:150/30ms
CPU/GPU:70/50msCPU/GPU:30/20msCPU/GPU:150/30ms
PS:受商业保护,目前,仅开源Pytorch-Base-Trainer(PBT),基于PBT的分类,检测和分割以及姿态估计训练库,暂不开源。
2.Install
- 源码安装
git clone https://github.com/PanJinquan/Pytorch-Base-Trainer
cd Pytorch-Base-Trainer
bash setup.sh #pip install dist/basetrainer-*.*.*.tar.gz
- pip安装
pip install basetrainer
- 使用NNI 模型剪枝工具,需要安装NNI
# Linux or macOS
python3 -m pip install --upgrade nni
# Windows
python -m pip install --upgrade nni
3.训练框架
PBT基础训练库定义了一个基类(Base),所有训练引擎(Engine)以及回调函数(Callback)都会继承基类。
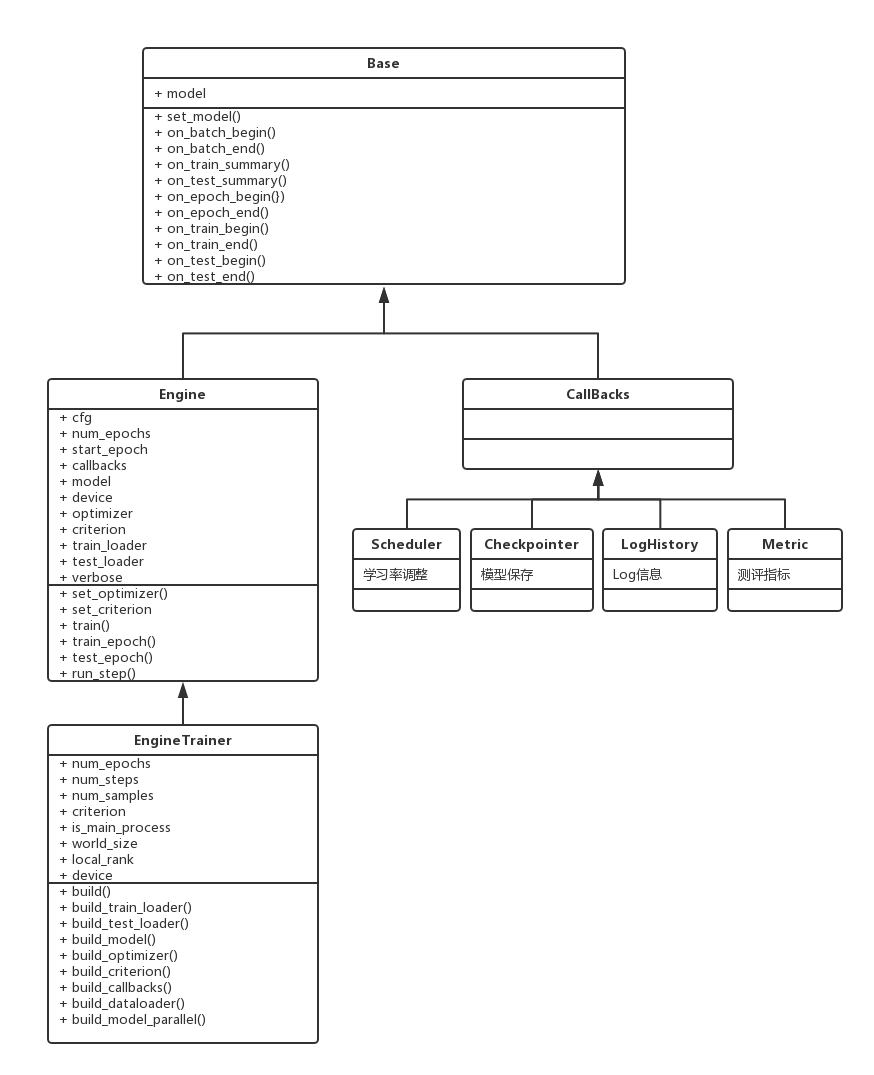
(1)训练引擎(Engine)
Engine
类实现了训练/测试的迭代方法(如on_batch_begin,on_batch_end),其迭代过程参考如下,用户可以根据自己的需要自定义迭代过程:
self.on_train_begin()
for epoch in range(num_epochs):
self.set_model() # 设置模型
# 开始训练
self.on_epoch_begin() # 开始每个epoch调用
for inputs in self.train_dataset:
self.on_batch_begin() # 每次迭代开始时回调
self.run_step() # 每次迭代返回outputs, losses
self.on_train_summary() # 每次迭代,训练结束时回调
self.on_batch_end() # 每次迭代结束时回调
# 开始测试
self.on_test_begin()
for inputs in self.test_dataset:
self.run_step() # 每次迭代返回outputs, losses
self.on_test_summary() # 每次迭代,测试结束时回调
self.on_test_end() # 结束测试
# 结束当前epoch
self.on_epoch_end()
self.on_train_end()
EngineTrainer
类继承
Engine
类,用户需要继承该类,并实现相关接口:
接口说明build_train_loader定义训练数据build_test_loader定义测试数据build_model定义模型build_optimizer定义优化器build_criterion定义损失函数build_callbacks定义回调函数
另外,
EngineTrainer
类还是实现了两个重要的类方法(build_dataloader和build_model_parallel),用于构建分布式训练
类方法说明build_dataloader用于构建加载方式,参数distributed设置是否使用分布式加载数据build_model_parallel用于构建模型,参数distributed设置是否使用分布式训练模型
(2)回调函数(Callback)
每个回调函数都需要继承(Callback),用户在回调函数中,可实现对迭代方法输入/输出的处理,例如:
回调函数说明LogHistoryLog历史记录回调函数,可使用Tensorboard可视化ModelCheckpoint保存模型回调函数,可选择最优模型保存LossesRecorder单个Loss历史记录回调函数,可计算每个epoch的平均值MultiLossesRecorder用于多任务Loss的历史记录回调函数AccuracyRecorder用于计算分类Accuracy回调函数get_scheduler各种学习率调整策略(MultiStepLR,CosineAnnealingLR,ExponentialLR)的回调函数
4.使用方法
basetrainer
使用方法可以参考example.py,构建自己的训练器,可通过如下步骤实现:
- step1: 新建一个类
ClassificationTrainer,继承trainer.EngineTrainer - step2: 实现接口
def build_train_loader(self, cfg, **kwargs):
"""定义训练数据"""
raise NotImplementedError("build_train_loader not implemented!")
def build_test_loader(self, cfg, **kwargs):
"""定义测试数据"""
raise NotImplementedError("build_test_loader not implemented!")
def build_model(self, cfg, **kwargs):
"""定于训练模型"""
raise NotImplementedError("build_model not implemented!")
def build_optimizer(self, cfg, **kwargs):
"""定义优化器"""
raise NotImplementedError("build_optimizer not implemented!")
def build_criterion(self, cfg, **kwargs):
"""定义损失函数"""
raise NotImplementedError("build_criterion not implemented!")
def build_callbacks(self, cfg, **kwargs):
"""定义回调函数"""
raise NotImplementedError("build_callbacks not implemented!")
step3: 在初始化中调用build
def __init__(self, cfg):
super(ClassificationTrainer, self).__init__(cfg)
...
self.build(cfg)
...
step4: 实例化ClassificationTrainer,并使用launch启动分布式训练
def main(cfg):
t = ClassificationTrainer(cfg)
return t.run()
if __name__ == "__main__":
parser = get_parser()
args = parser.parse_args()
cfg = setup_config.parser_config(args)
launch(main,
num_gpus_per_machine=len(cfg.gpu_id),
dist_url="tcp://127.0.0.1:28661",
num_machines=1,
machine_rank=0,
distributed=cfg.distributed,
args=(cfg,))
5.Example: 构建自己的分类Pipeline
basetrainer使用方法可以参考example.py
python example.py
- 目标支持的backbone有:resnet[18,34,50,101], ,mobilenet_v2等,详见backbone等 ,其他backbone可以自定义添加
- 训练参数可以通过两种方法指定: (1) 通过argparse命令行指定 (2)通过config.yaml配置文件,当存在同名参数时,以配置文件为默认值
参数类型参考值****说明train_datastr, list-训练数据文件,可支持多个文件test_datastr, list-测试数据文件,可支持多个文件work_dirstrwork_space训练输出工作空间net_typestrresnet18backbone类型,{resnet,resnest,mobilenet_v2,...}input_sizelist[128,128]模型输入大小[W,H]batch_sizeint32batch sizelrfloat0.1初始学习率大小optim_typestrSGD优化器,{SGD,Adam}loss_typestrCELoss损失函数schedulerstrmulti-step学习率调整策略,{multi-step,cosine}milestoneslist[30,80,100]降低学习率的节点,仅仅scheduler=multi-step有效momentumfloat0.9SGD动量因子num_epochsint120循环训练的次数num_warn_upint3warn_up的次数num_workersint12DataLoader开启线程数weight_decayfloat5e-4权重衰减系数gpu_idlist[ 0 ]指定训练的GPU卡号,可指定多个log_freqin20显示LOG信息的频率finetunestrmodel.pthfinetune的模型use_pruneboolTrue是否进行模型剪枝progressboolTrue是否显示进度条distributedboolFalse是否使用分布式训练
一个简单分类例子如下:
# -*-coding: utf-8 -*-
"""
@Author : panjq
@E-mail : [email protected]
@Date : 2021-07-28 22:09:32
"""
import os
import sys
sys.path.append(os.getcwd())
import argparse
import basetrainer
from torchvision import transforms
from torchvision.datasets import ImageFolder
from basetrainer.engine import trainer
from basetrainer.engine.launch import launch
from basetrainer.criterion.criterion import get_criterion
from basetrainer.metric import accuracy_recorder
from basetrainer.callbacks import log_history, model_checkpoint, losses_recorder, multi_losses_recorder
from basetrainer.scheduler import build_scheduler
from basetrainer.optimizer.build_optimizer import get_optimizer
from basetrainer.utils import log, file_utils, setup_config, torch_tools
from basetrainer.models import build_models
print(basetrainer.__version__)
class ClassificationTrainer(trainer.EngineTrainer):
""" Training Pipeline """
def __init__(self, cfg):
super(ClassificationTrainer, self).__init__(cfg)
torch_tools.set_env_random_seed()
cfg.model_root = os.path.join(cfg.work_dir, "model")
cfg.log_root = os.path.join(cfg.work_dir, "log")
if self.is_main_process:
file_utils.create_dir(cfg.work_dir)
file_utils.create_dir(cfg.model_root)
file_utils.create_dir(cfg.log_root)
file_utils.copy_file_to_dir(cfg.config_file, cfg.work_dir)
setup_config.save_config(cfg, os.path.join(cfg.work_dir, "setup_config.yaml"))
self.logger = log.set_logger(level="debug",
logfile=os.path.join(cfg.log_root, "train.log"),
is_main_process=self.is_main_process)
# build project
self.build(cfg)
self.logger.info("=" * 60)
self.logger.info("work_dir :{}".format(cfg.work_dir))
self.logger.info("config_file :{}".format(cfg.config_file))
self.logger.info("gpu_id :{}".format(cfg.gpu_id))
self.logger.info("main device :{}".format(self.device))
self.logger.info("num_samples(train):{}".format(self.num_samples))
self.logger.info("num_classes :{}".format(cfg.num_classes))
self.logger.info("mean_num :{}".format(self.num_samples / cfg.num_classes))
self.logger.info("=" * 60)
def build_optimizer(self, cfg, **kwargs):
"""build_optimizer"""
self.logger.info("build_optimizer")
self.logger.info("optim_type:{},init_lr:{},weight_decay:{}".format(cfg.optim_type, cfg.lr, cfg.weight_decay))
optimizer = get_optimizer(self.model,
optim_type=cfg.optim_type,
lr=cfg.lr,
momentum=cfg.momentum,
weight_decay=cfg.weight_decay)
return optimizer
def build_criterion(self, cfg, **kwargs):
"""build_criterion"""
self.logger.info("build_criterion,loss_type:{},num_classes:{}".format(cfg.loss_type, cfg.num_classes))
criterion = get_criterion(cfg.loss_type, cfg.num_classes, device=self.device)
return criterion
def build_train_loader(self, cfg, **kwargs):
"""build_train_loader"""
self.logger.info("build_train_loader,input_size:{}".format(cfg.input_size))
transform = transforms.Compose([
transforms.Resize([int(128 * cfg.input_size[1] / 112), int(128 * cfg.input_size[0] / 112)]),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop([cfg.input_size[1], cfg.input_size[0]]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
dataset = ImageFolder(root=cfg.train_data, transform=transform)
cfg.num_classes = len(dataset.classes)
cfg.classes = dataset.classes
loader = self.build_dataloader(dataset, cfg.batch_size, cfg.num_workers, phase="train",
shuffle=True, pin_memory=False, drop_last=True, distributed=cfg.distributed)
return loader
def build_test_loader(self, cfg, **kwargs):
"""build_test_loader"""
self.logger.info("build_test_loader,input_size:{}".format(cfg.input_size))
transform = transforms.Compose([
transforms.Resize([int(128 * cfg.input_size[1] / 112), int(128 * cfg.input_size[0] / 112)]),
transforms.CenterCrop([cfg.input_size[1], cfg.input_size[0]]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
dataset = ImageFolder(root=cfg.train_data, transform=transform)
loader = self.build_dataloader(dataset, cfg.batch_size, cfg.num_workers, phase="test",
shuffle=False, pin_memory=False, drop_last=False, distributed=False)
return loader
def build_model(self, cfg, **kwargs):
"""build_model"""
self.logger.info("build_model,net_type:{}".format(cfg.net_type))
model = build_models.get_models(net_type=cfg.net_type, input_size=cfg.input_size,
num_classes=cfg.num_classes, pretrained=True)
if cfg.finetune:
self.logger.info("finetune:{}".format(cfg.finetune))
state_dict = torch_tools.load_state_dict(cfg.finetune)
model.load_state_dict(state_dict)
if cfg.use_prune:
from basetrainer.pruning import nni_pruning
sparsity = 0.2
self.logger.info("use_prune:{},sparsity:{}".format(cfg.use_prune, sparsity))
model = nni_pruning.model_pruning(model,
input_size=[1, 3, cfg.input_size[1], cfg.input_size[0]],
sparsity=sparsity,
reuse=False,
output_prune=os.path.join(cfg.work_dir, "prune"))
model = self.build_model_parallel(model, cfg.gpu_id, distributed=cfg.distributed)
return model
def build_callbacks(self, cfg, **kwargs):
"""定义回调函数"""
self.logger.info("build_callbacks")
# 准确率记录回调函数
acc_record = accuracy_recorder.AccuracyRecorder(target_names=cfg.classes,
indicator="Accuracy")
# loss记录回调函数
loss_record = losses_recorder.LossesRecorder(indicator="loss")
# Tensorboard Log等历史记录回调函数
history = log_history.LogHistory(log_dir=cfg.log_root,
log_freq=cfg.log_freq,
logger=self.logger,
indicators=["loss", "Accuracy"],
is_main_process=self.is_main_process)
# 模型保存回调函数
checkpointer = model_checkpoint.ModelCheckpoint(model=self.model,
optimizer=self.optimizer,
moder_dir=cfg.model_root,
epochs=cfg.num_epochs,
start_save=-1,
indicator="Accuracy",
logger=self.logger)
# 学习率调整策略回调函数
lr_scheduler = build_scheduler.get_scheduler(cfg.scheduler,
optimizer=self.optimizer,
lr_init=cfg.lr,
num_epochs=cfg.num_epochs,
num_steps=self.num_steps,
milestones=cfg.milestones,
num_warn_up=cfg.num_warn_up)
callbacks = [acc_record,
loss_record,
lr_scheduler,
history,
checkpointer]
return callbacks
def run(self, logs: dict = {}):
self.logger.info("start train")
super().run(logs)
def main(cfg):
t = ClassificationTrainer(cfg)
return t.run()
def get_parser():
parser = argparse.ArgumentParser(description="Training Pipeline")
parser.add_argument("-c", "--config_file", help="configs file", default="configs/config.yaml", type=str)
# parser.add_argument("-c", "--config_file", help="configs file", default=None, type=str)
parser.add_argument("--train_data", help="train data", default="./data/dataset/train", type=str)
parser.add_argument("--test_data", help="test data", default="./data/dataset/val", type=str)
parser.add_argument("--work_dir", help="work_dir", default="output", type=str)
parser.add_argument("--input_size", help="input size", nargs="+", default=[224, 224], type=int)
parser.add_argument("--batch_size", help="batch_size", default=32, type=int)
parser.add_argument("--gpu_id", help="specify your GPU ids", nargs="+", default=[0], type=int)
parser.add_argument("--num_workers", help="num_workers", default=0, type=int)
parser.add_argument("--num_epochs", help="total epoch number", default=50, type=int)
parser.add_argument("--scheduler", help=" learning scheduler: multi-step,cosine", default="multi-step", type=str)
parser.add_argument("--milestones", help="epoch stages to decay learning rate", nargs="+",
default=[10, 20, 40], type=int)
parser.add_argument("--num_warn_up", help="num_warn_up", default=3, type=int)
parser.add_argument("--net_type", help="net_type", default="mobilenet_v2", type=str)
parser.add_argument("--finetune", help="finetune model file", default=None, type=str)
parser.add_argument("--loss_type", help="loss_type", default="CELoss", type=str)
parser.add_argument("--optim_type", help="optim_type", default="SGD", type=str)
parser.add_argument("--lr", help="learning rate", default=0.1, type=float)
parser.add_argument("--weight_decay", help="weight_decay", default=0.0005, type=float)
parser.add_argument("--momentum", help="momentum", default=0.9, type=float)
parser.add_argument("--log_freq", help="log_freq", default=10, type=int)
parser.add_argument('--use_prune', action='store_true', help='use prune', default=False)
parser.add_argument('--progress', action='store_true', help='display progress bar', default=True)
parser.add_argument('--distributed', action='store_true', help='use distributed training', default=False)
parser.add_argument('--polyaxon', action='store_true', help='polyaxon', default=False)
return parser
if __name__ == "__main__":
parser = get_parser()
cfg = setup_config.parser_config(parser.parse_args(), cfg_updata=True)
launch(main,
num_gpus_per_machine=len(cfg.gpu_id),
dist_url="tcp://127.0.0.1:28661",
num_machines=1,
machine_rank=0,
distributed=cfg.distributed,
args=(cfg,))
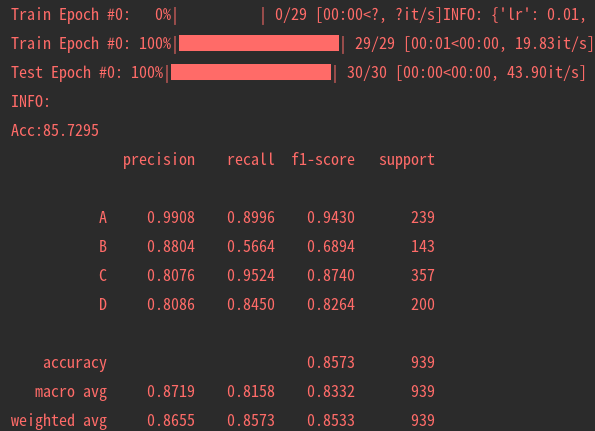
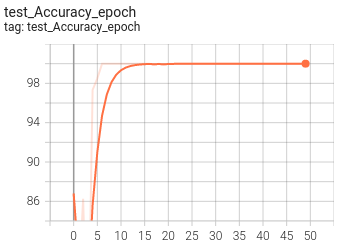
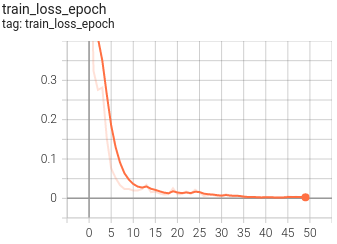
6.可视化
目前训练过程可视化工具是使用Tensorboard,使用方法:
tensorboard --logdir=path/to/log/



7.其他
作者PKing联系方式pan_jinquan@163.com
版权归原作者 pan_jinquan 所有, 如有侵权,请联系我们删除。