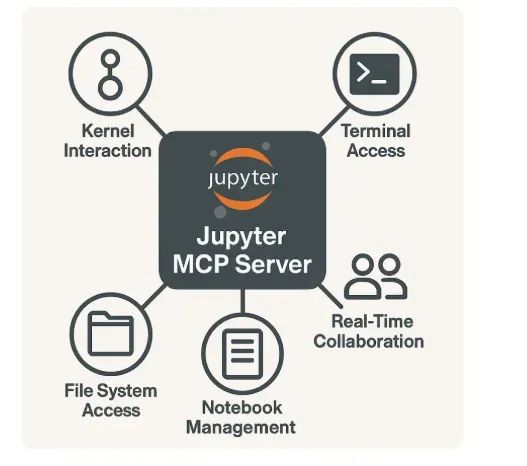
Jupyter MCP服务器部署实战:AI模型与Python环境无缝集成教程
Jupyter MCP 服务器作为模型上下文协议在 Jupyter 生态系统中的具体实现,充当了大型语言模型与用户 Jupyter 工作环境之间的技术桥梁。

图神经网络在信息检索重排序中的应用:原理、架构与Python代码解析
基于图的重排序是信息检索和图机器学习交叉领域一个令人兴奋的发展。通过明确表示检索到的文档以及外部知识之间的关系,这些方法解决了传统检索器孤立地考虑每个文档的局限性。

CUDA重大更新:原生Python可直接编写高性能GPU程序
NVIDIA CUDA架构师Stephen Jones在GTC 2025主题演讲中明确表示:"我们致力于将加速计算与Python进行深度集成,使Python成为CUDA生态系统中具有一等公民地位的编程语言。
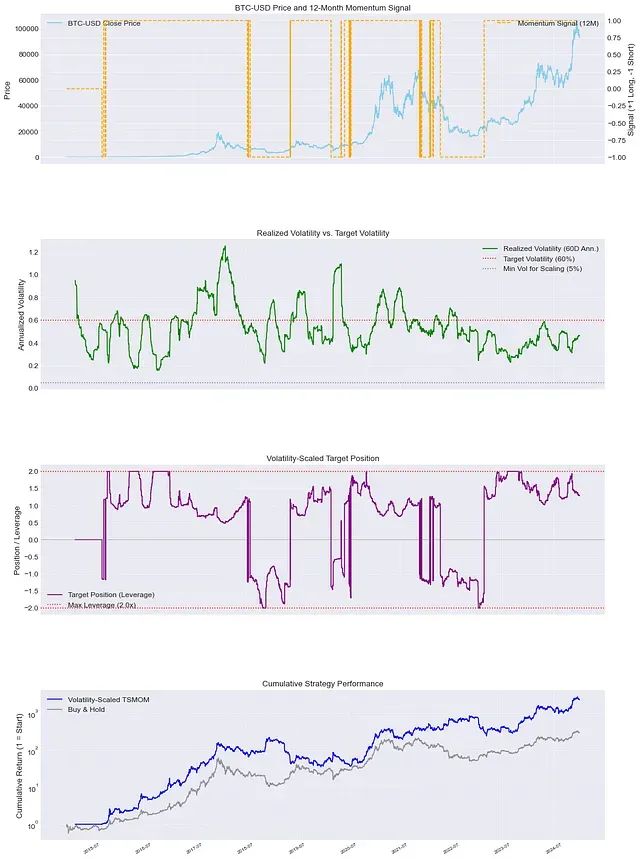
Python实现时间序列动量策略:波动率标准化让量化交易收益更平稳
本文将系统性地分析波动率调整时间序列动量策略的机制原理、实施方法以及其在现代量化投资框架中的重要地位。

解读 Python 3.14:模板字符串、惰性类型、Zstd压缩等7大核心功能升级
本文将深入分析 Python 3.14 中最为显著的**七项核心技术特性**,探讨它们对开发效率与应用架构的实际影响。
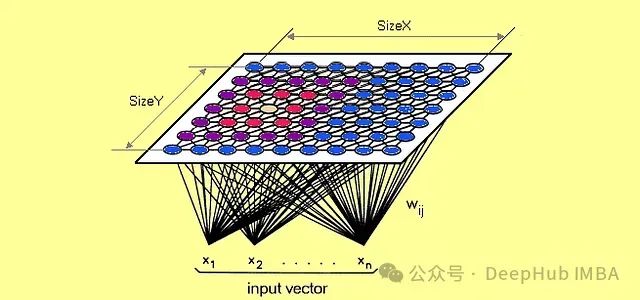
面向概念漂移的动态自组织映射(SOM)及其在金融风险预警中的效能评估
自组织映射(Self-Organizing Maps),又称**Kohonen映射**,是由芬兰学者**Teuvo Kohonen**在20世纪80年代提出的一种无监督神经网络模型。其核心功能是将高维数据空间投影到低维(通常为二维)网格结构中。
基于马尔可夫链的状态转换,用概率模型预测股市走势
马尔可夫链本质上是一个依据特定概率规则从一个状态转移至另一个状态的数学系统。其核心特征在于:**系统的下一个状态仅依赖于当前状态,而非之前的状态序列**。
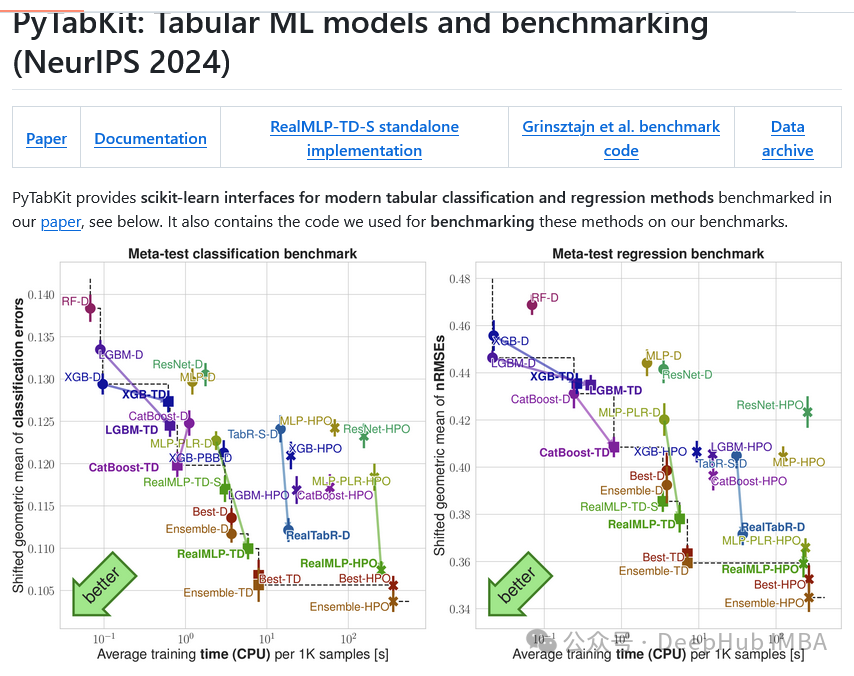
PyTabKit:比sklearn更强大的表格数据机器学习框架
**PyTabKit** 专为表格数据的分类和回归任务设计,集成了 **RealMLP** 等先进技术以及优化的梯度提升决策树(GBDT)超参数配置,为表格数据处理提供了新的技术选择。
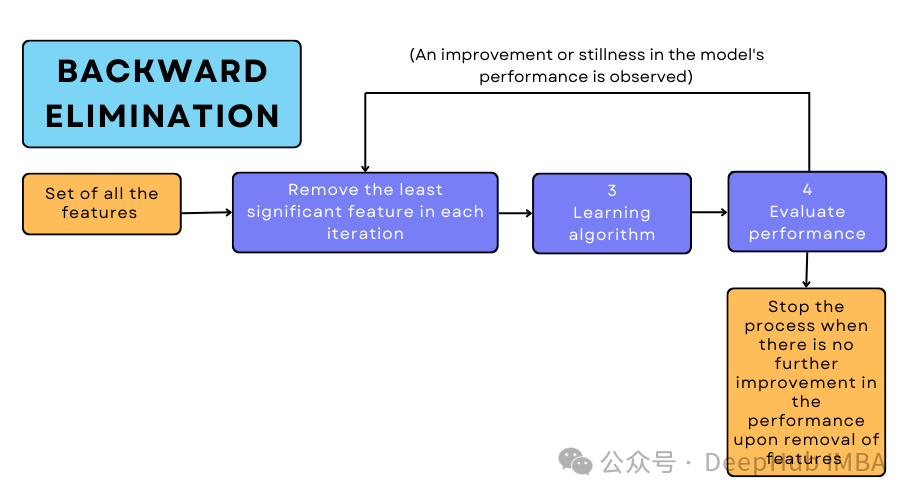
机器学习特征筛选:向后淘汰法原理与Python实现
向后淘汰法(Backward Elimination)是机器学习领域中一种重要的特征选择技术,其核心思想是通过系统性地移除对模型贡献较小的特征,以提高模型性能和可解释性。
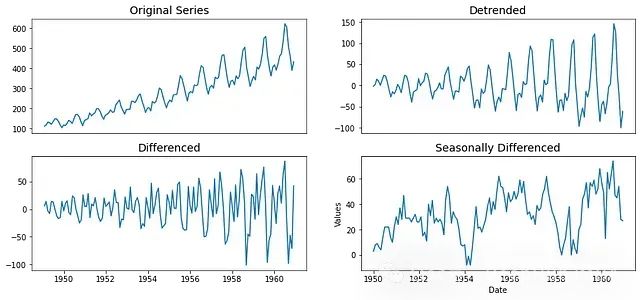
趋势还是噪声?ADF与KPSS检验结果矛盾时的高级时间序列处理方法
当我们遇到ADF检验失败而KPSS检验通过的情况时,这表明我们面对的是一个平稳但具有确定性趋势的时间序列。
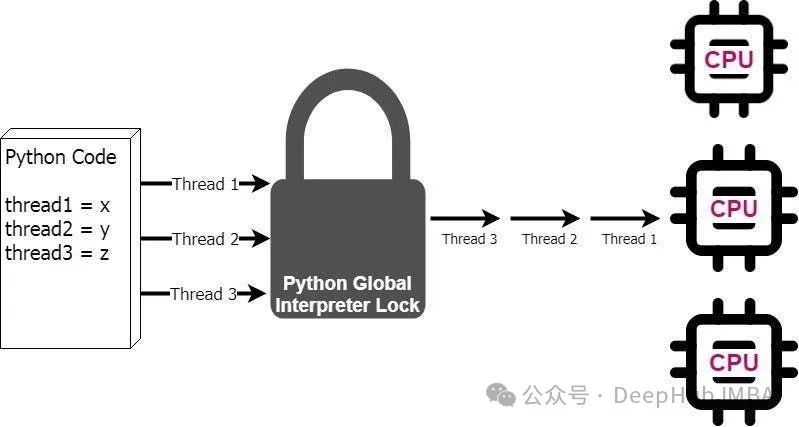
Python GIL(全局解释器锁)机制对多线程性能影响的深度分析
本文将主要基于CPython(用C语言实现的Python解释器,也是目前应用最广泛的Python解释器)展开讨论。
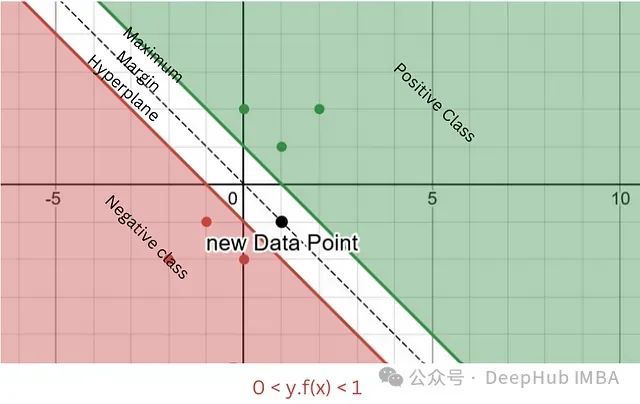
深入剖析SVM核心机制:铰链损失函数的原理与代码实现
铰链损失(Hinge Loss)是支持向量机(Support Vector Machine, SVM)中最为核心的损失函数之一。该损失函数不仅在SVM中发挥着关键作用,也被广泛应用于其他机器学习模型的训练过程中。
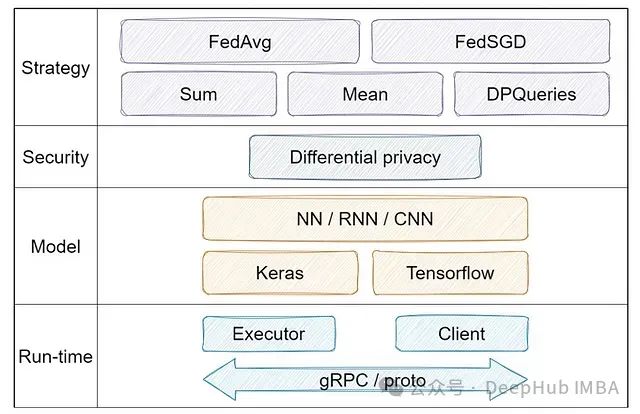
十大主流联邦学习框架:技术特性、架构分析与对比研究
联邦学习领域已发展出多个针对不同技术需求和应用场景的框架工具。这些工具在框架灵活性、使用便捷性和安全特性等方面各具特色。我们这里总结了10个联邦学习具有代表性框架
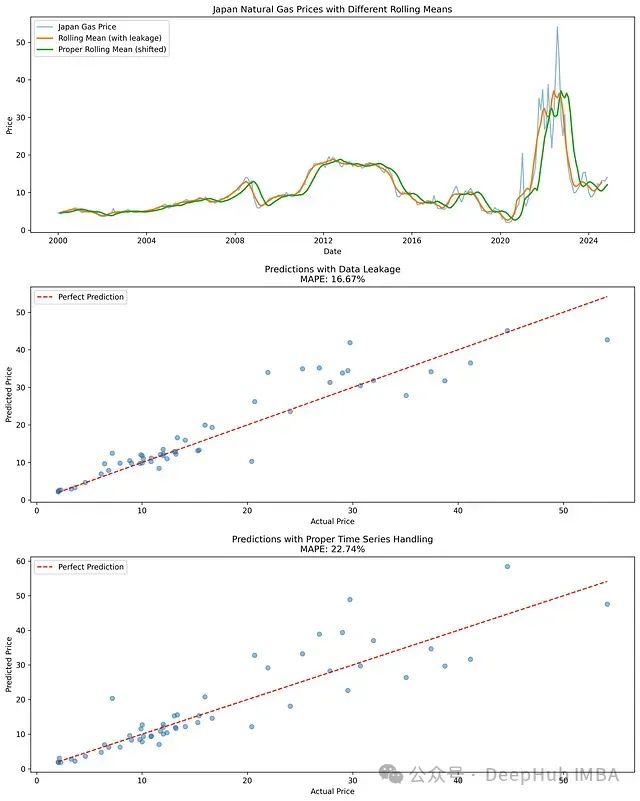
构建可靠的时间序列预测模型:数据泄露检测、前瞻性偏差消除与因果关系验证
在时间序列分析领域中,存在多种可能影响分析结果有效性的技术挑战。其中,数据泄露、前瞻性偏差和因果关系违反是最为常见且具有显著影响的问题。

Python高性能编程:五种核心优化技术的原理与Python代码
在性能要求较高的应用场景中,Python常因其执行速度不及C、C++或Rust等编译型语言而受到质疑。然而通过合理运用Python标准库提供的优化特性,我们可以显著提升Python代码的执行效率。
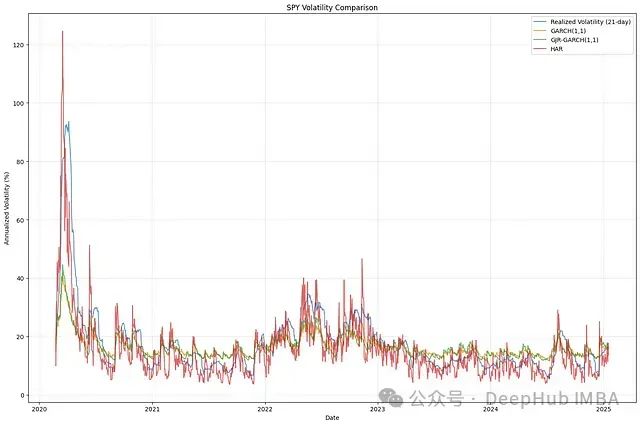
金融波动率的多模型建模研究:GARCH族与HAR模型的Python实现与对比分析
本文着重探讨三种主流波动率建模方法:广义自回归条件异方差模型(GARCH)、Glosten-Jagannathan-Runkle-GARCH模型(GJR-GARCH)以及异质自回归模型(HAR)
Python时间序列分析:使用TSFresh进行自动化特征提取
**TSFresh(基于可扩展假设检验的时间序列特征提取)**是一个专门用于时间序列数据特征自动提取的框架。该框架提取的特征可直接应用于分类、回归和异常检测等机器学习任务。
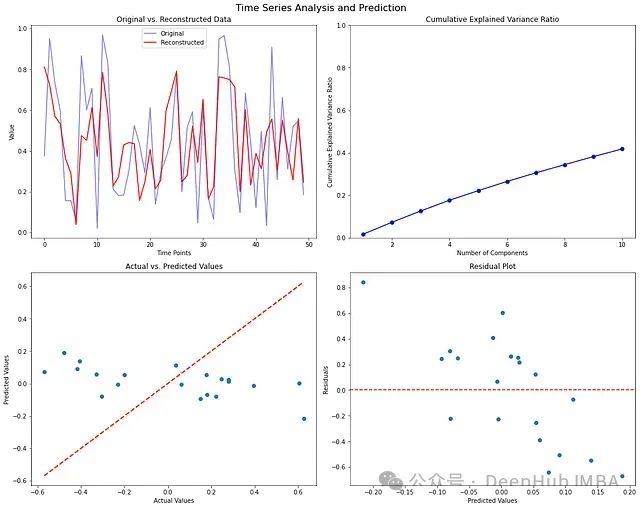
使用Python实现基于矩阵分解的长期事件(MFLEs)时间序列分析
基于矩阵分解的长期事件(Matrix Factorization for Long-term Events, MFLEs)分析技术应运而生。这种方法结合了矩阵分解的降维能力和时间序列分析的特性,为处理大规模时间序列数据提供了一个有效的解决方案。
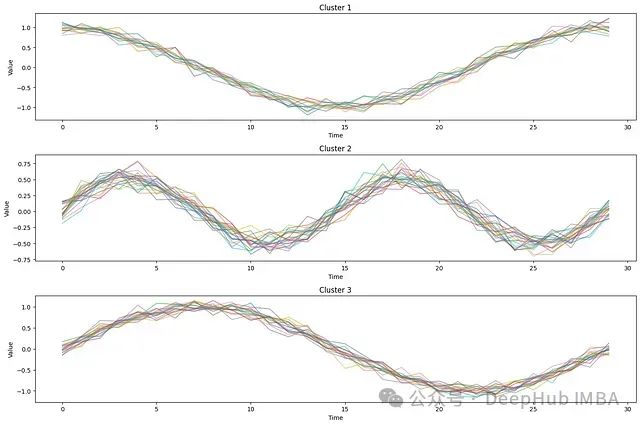
Python时间序列分析工具Aeon使用指南
**Aeon** 是一个专注于时间序列处理的开源Python库,其设计理念遵循scikit-learn的API风格,为数据科学家和研究人员提供了一套完整的时间序列分析工具。该项目保持活跃开发,截至2024年仍持续更新。
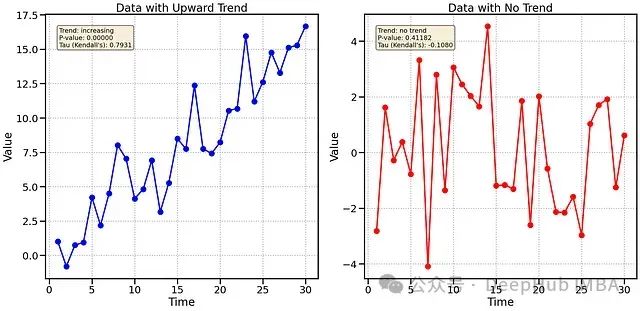
五种被低估的非常规统计检验方法:数学原理剖析与多领域应用价值研究
本文将详细介绍五种具有重要应用价值的统计检验方法,并探讨它们在免疫学(TCR/BCR库分析)、金融数据分析和运动科学等领域的具体应用。



