Jmeter性能测试(性能测试,Jmeter使用与结果分析)
性能测试是一个全栈工程师/架构师必会的技能之一,只有学会性能测试,才能根据得到的测试报告进行分析,找到系统性能的瓶颈所在,而这也是优化架构设计中重要的依据。本文简单讲述了性能测试以及性能测试工具Jmeter。另外,我会将其他测试相关的文章也放在这个系列。性能测试就是通过特定的方式对被测试系统按照一定
Python大数据之pandas快速入门(二)
能够知道 DataFrame 和 Series 数据结构能够加载 csv 和 tsv 数据集能够区分 DataFrame 的行列标签和行列位置编号能够获取 DataFrame 指定行列的数据locilocloc和iloc的切片操作[]
PyCharm中安装pandas包出错解决方法
在pycharm中导入pandas包出错解决方法
学以致用——植物信息录入(selenium+pandas+os+tkinter)
数据读取pandas,自动化测试selenium,os系统操作,tkinter图形化界面。组合实现网站信息批量录入。
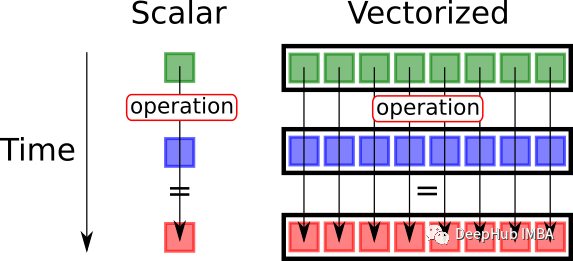
向量化操作简介和Pandas、Numpy示例
在本文中,我们将探讨什么是向量化,以及它如何简化数据分析任务。
学以致用——植物信息录入1.0(selenium+pandas+os+tkinter)
好事多磨,好书多看,好代码多练
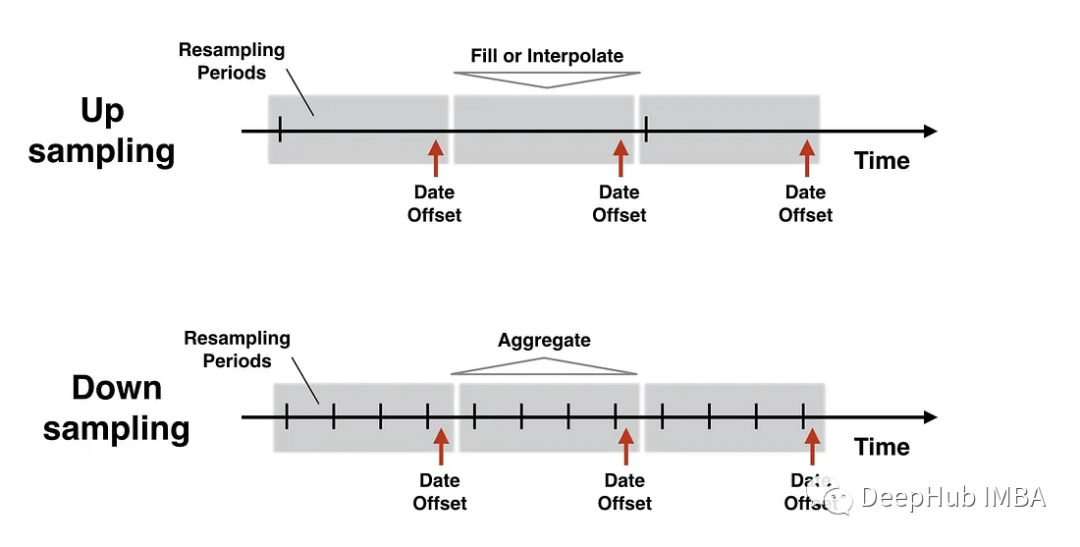
时间序列的重采样和pandas的resample方法介绍
重采样是时间序列分析中处理时序数据的一项基本技术。它是关于将时间序列数据从一个频率转换到另一个频率,它可以更改数据的时间间隔,通过上采样增加粒度,或通过下采样减少粒度。

Pandas DataFrame 数据存储格式比较
Pandas 支持多种存储格式,在本文中将对不同类型存储格式下的Pandas Dataframe的读取速度、写入速度和大小的进行测试对比。

15个基本且常用Pandas代码片段
以上这15个Pandas代码片段是我们日常最常用的数据操作和分析操作。熟练的掌握它,并将它们合并到工作流程中,可以提高处理和探索数据集的效率和效果。

Pandas 2.1发布了
2023年3月1日,Pandas 发布了2.0版本。6个月后(8月30日),更新了新的2.1版。让我们看看他有什么重要的更新。

Pandas字符串操作的各种方法速度测试
由于LLM的发展, 很多的数据集都是以DF的形式发布的,所以通过Pandas操作字符串的要求变得越来越高了,所以本文将对字符串操作方法进行基准测试,看看它们是如何影响pandas的性能的。因为一旦Pandas在处理数据时超过一定限制,它们的行为就会很奇怪。

使用Pandas进行数据清理的入门示例
数据清理是数据分析过程中的关键步骤,它涉及识别缺失值、重复行、异常值和不正确的数据类型。获得干净可靠的数据对于准确的分析和建模非常重要。
Python用pandas进行大数据Excel两文件比对去重300w大数据处理
通俗理解有两个excel文件 分别为A和B我要从B中去掉A中含有的数据,数据量大约在300w左右因为数据量较大,无论是wps还是office自带的去重都无法正常使用这样就需要用到脚本了。
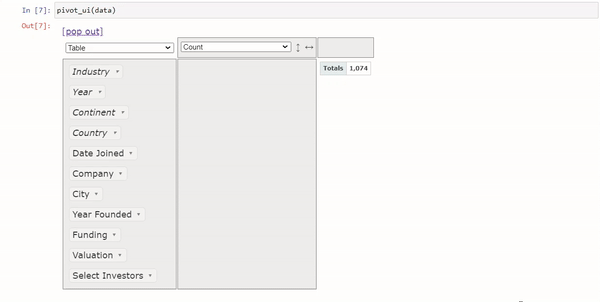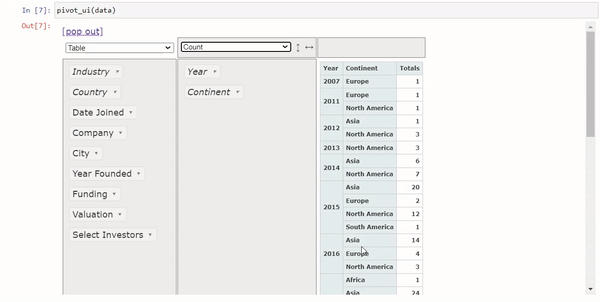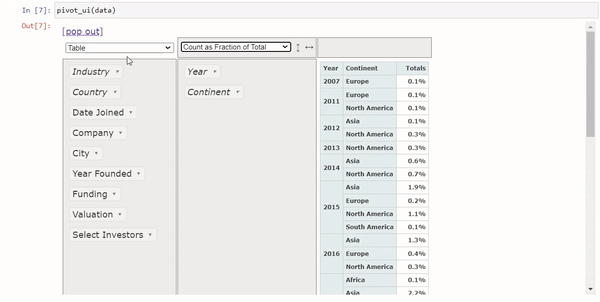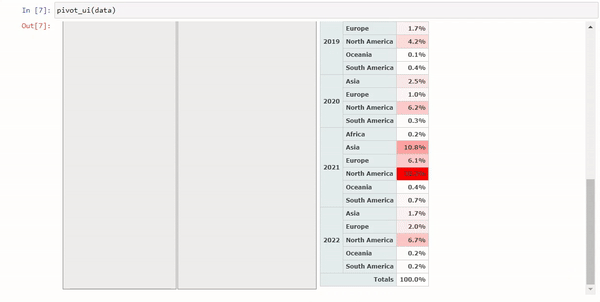
4个将Pandas换为交互式表格Python包
Pandas是我们日常处理表格数据最常用的包,但是对于数据分析来说,Pandas的DataFrame还不够直观,所以今天我们将介绍4个Python包,可以将Pandas的DataFrame转换交互式表格,让我们可以直接在上面进行数据分析的操作。
【数据分析入门】人工智能、数据分析和深度学习是什么关系?如何快速入门 Python Pandas?
本文胎教般地科普了人工智能、深度学习和数据分析的区别和联系,并就数据分析中所常用的Python Pandas库做了快速入门的全面引导
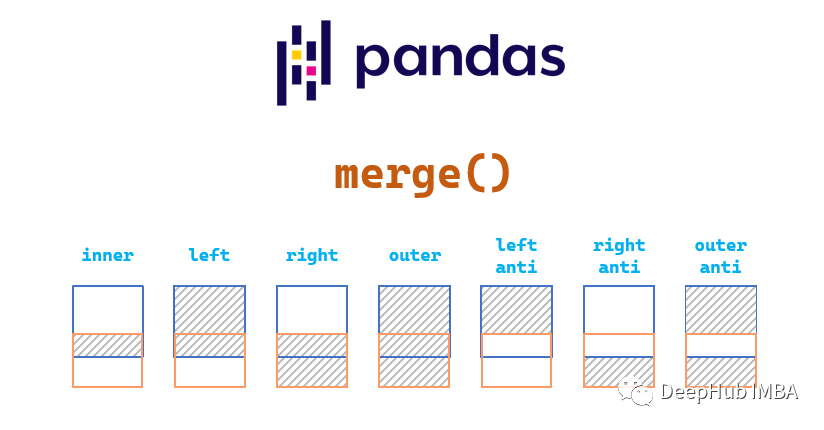
Pandas 的Merge函数详解
在日常工作中,我们可能会从多个数据集中获取数据,并且希望合并两个或多个不同的数据集。这时就可以使用Pandas包中的Merge函数。在本文中,我们将介绍用于合并数据的三个函数
数字新技术浪潮:大数据、云计算、物联网、区块链与人工智能
本文将探讨数字新技术中的五大关键技术:大数据、云计算、物联网、区块链和人工智能。我们将对这些技术进行简要概述,分析它们在现实世界中的应用,并展望它们对未来产业和社会发展的影响。
大数据下的竞彩足球胜平负分析技巧1
什么是有效的数据支撑?这里指的是某种条件/组合条件下的准确率,比如70%以上、80%以上。
Vscode——查看变量的所有值
pip install pandas



