
Python用pandas进行大数据Excel两文件比对去重
背景介绍:
通俗理解有两个excel文件 分别为A和B
我要从B中去掉A中含有的数据,数据量大约在300w左右
因为数据量较大,无论是wps还是office自带的去重都无法正常使用这样就需要用到脚本了
话不多说,代码如下:
import pandas as pd
from tqdm import tqdm
# 引号内填写需要去重的表格路径
targetExcel = r'./222.xlsx'
# 引号内填写依据表格的路径
basisExcel = r'./11.xlsx'
# 引号内填写输出字段
field = 'removeRepeatResult'
def removeRepeat():
count = 0
ind = 1
targetIndex = field + str(ind)
resultExcel = {
field+'1': []
}
header = ['A','B','C','D','E','F','G','H','I','J','K']
print('读取数据')
target_Excel = pd.read_excel(targetExcel,header=None,names=header, dtype='object')
basis_Excel = pd.read_excel(basisExcel,header=None,names=['A'], dtype='object')
print('读取成功')
for index in tqdm(header):
for i in tqdm(target_Excel[index], leave=False):
if pd.isnull(i):
continue
elif i in list(basis_Excel['A']):
continue
else:
resultExcel[targetIndex].append(i)
count += 1
if count >= 1020000:
count = 0
ind += 1
targetIndex = field + str(ind)
resultExcel[targetIndex] = []
print('等待数据合并')
df = pd.concat([pd.DataFrame(i) for i in resultExcel.values()], axis=1)
df.fillna(0) # 取消长短不一致问题
df.to_excel('resultExcel.xlsx', header=None, index=False) # 取消表头与行号
#上一行中自定义文件名!
removeRepeat()
input('>>> 任意键退出...')
运行效果图:
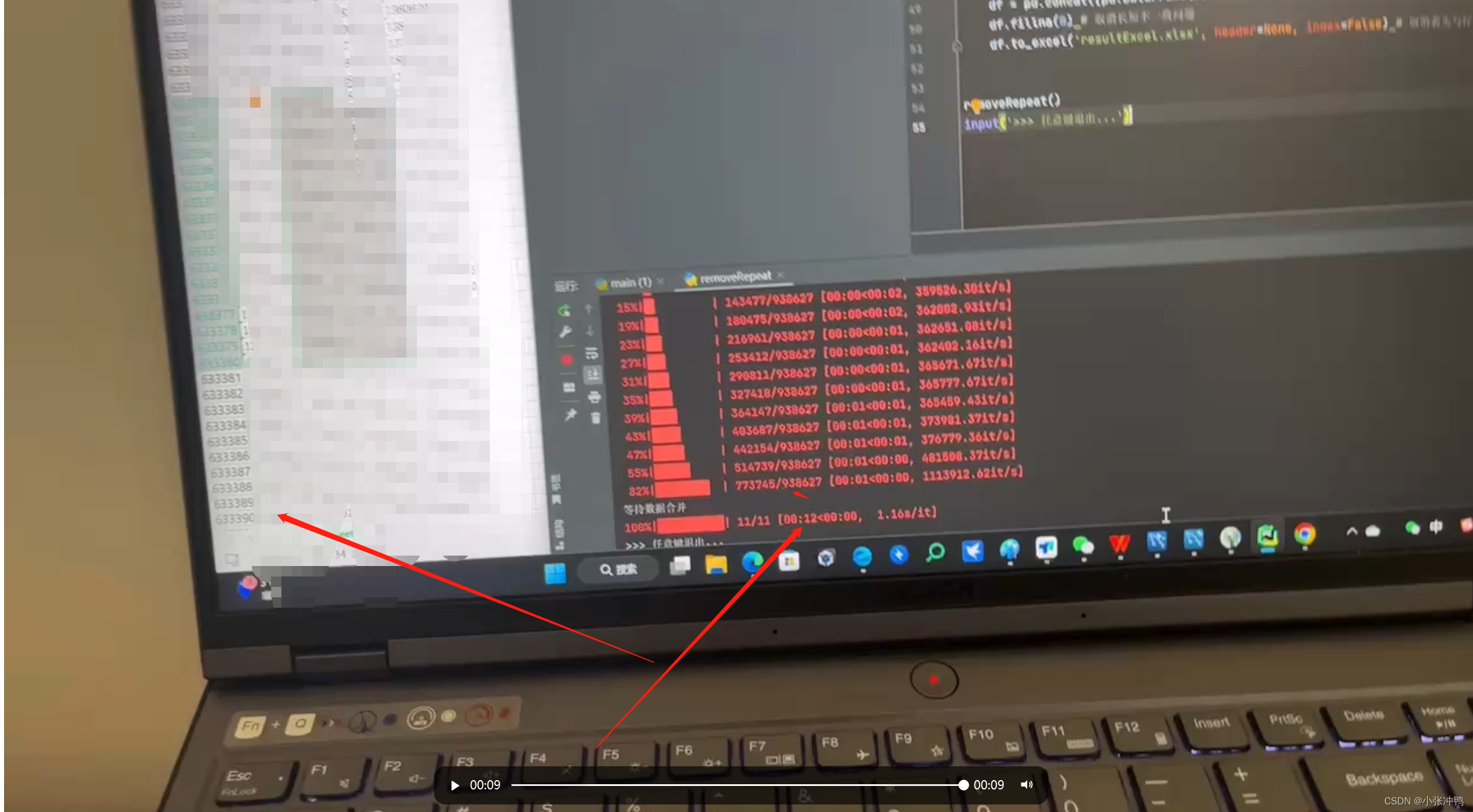
欢迎大家指导交流,共同学习,共同进步!
本文转载自: https://blog.csdn.net/xiaozhang0316/article/details/128807913
版权归原作者 小张冲鸭 所有, 如有侵权,请联系我们删除。
版权归原作者 小张冲鸭 所有, 如有侵权,请联系我们删除。