
在Pandas中,update()方法用于将一个DataFrame或Series对象中的值更新为另一个DataFrame或Series对象中的对应值。这个方法可以用来在原地更新数据,而不需要创建一个新的对象。
update()方法有几个参数,其中最重要的是other参数,它指定了用来更新当前对象的另一个DataFrame或Series对象。当调用update()方法时,它会将other对象中的值替换当前对象中相应位置的值。。

下面是
update()
方法的基本语法:
DataFrame.update(other, overwrite=True, filter_func=None, errors='raise')
other:要用来更新当前对象的另一个DataFrame或Series对象。overwrite:一个布尔值,指定是否要覆盖当前对象中的值。默认为True,表示用other对象中的值完全替换当前对象中的值;如果设置为False,则只会替换NaN值。filter_func:一个可调用对象,用于筛选要更新的值。只有返回True的值才会被更新。errors:指定处理错误的方式。默认为'raise',表示如果更新过程中出现错误,将引发异常;如果设置为'ignore',则会忽略错误并继续执行。
需要注意的是,
update()
方法会就地修改当前对象,而不会返回一个新的对象。这与许多Pandas方法的行为不同,因为它们通常会返回一个新的对象。因此在使用
update()
方法之前,请确保对数据进行了适当的备份或者确保没有破坏原始数据的需求。
让我们从需要更新开始,我们的数据如下:
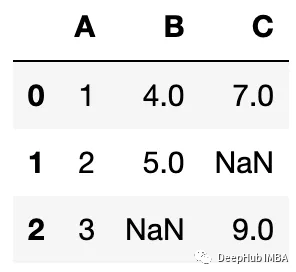
我们想要将下面的数据匹配到原始数据上:
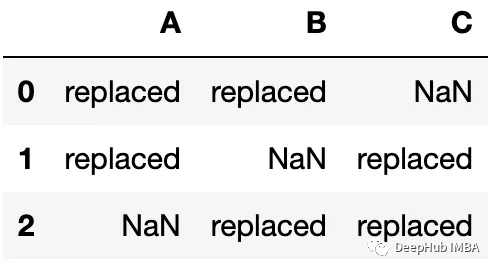
如果直接使用,看看结果是什么:
df.update(df1)
df
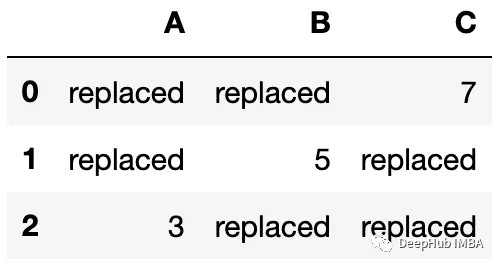
所有单元格都将被替换,除非我们的新DF有空,update()方法内联地改变了原始的数据,而不是创建副本。
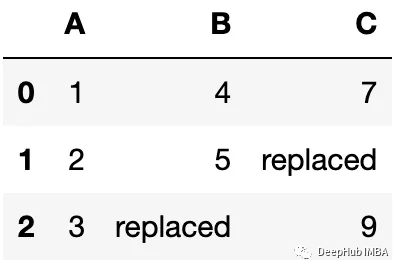
overwrite参数
除了空值所有单元格都被替换了,这时因为.update()只是假设新数据更相关。如果只想替换缺失的值,请可以设置参数' overwrite = False '
df.update(df1,overwrite=False)
df
filter_func参数
也可以通过使用' filter_func '参数来更新除null以外的单元格。例如只替换偶数的值。
df.update(df1,filter_func=lambda x : x%2==0)
df
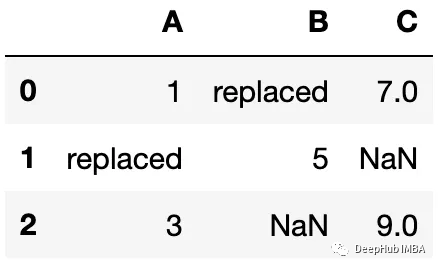
可以看到只更新了符合判断条件的值。
update()
方法可以方便的将一个DataFrame或Series对象中的值更新为另一个DataFrame或Series对象中的对应值,但是我们却很少用到它。所以在处理缺失或者过期数据更新时,pandas中的update方法是一个很有用的工具。但是需要注意的是,在使用
update()
方法之前,需要对数据进行了适当的备份或者确保没有破坏原始数据的需求,因为他会直接修改我们的DF。