
使用来自大约10K的前10分钟的游戏数据来预测高elo排名游戏的结果
介绍
《英雄联盟》是一款以团队为基础的战略游戏,两支拥有五名强大召唤师的队伍将面在峡谷中进行对决,而团队的目标是拆掉对方的基地。
一场典型的英雄联盟游戏通常需要持续30到45分钟,并且每个游戏可以分为三个阶段:对线阶段,中期和后期。玩家通常会花前10到15分钟在自己的分路(上,中,下,JG)中进行发育,以尽早获得装备和等级上的优势。在游戏的中期阶段,玩家开始专注于宏观层面:推线,拆塔,获取地图目标(男爵,小龙)以及进行区域的小团战。在后期游戏中,如果游戏尚未结束,则每个团队都必须决定如何结束游戏,例如:压制男爵/长老龙或1-4分推等。
在此项目中,我使用了Kaggle收集的名为“ michel's fanboi”的数据,数据集包含前10分钟。大约统计 从高ELO(钻石I到大师)的10k排名游戏(SOLO QUEUE)。可以在此处找到完整的描述和数据源(https://www.kaggle.com/bobbyscience/league-of-legends-diamond-ranked-games-10-min)
每个团队的英雄组合将对游戏结果有着至关重要的影响,因为有些英雄在游戏早期很强大,而其他英雄将在游戏中后期大幅增长。这就是为什么所有的排名游戏和职业游戏在比赛前都会有一个ban/pick阶段。然而,玩家通过技能和地图意识对游戏产生的影响并不会在英雄组合技能衔接中体现出来。特别是一些玩家,比如RNG。无论对手是否有反挡拆,Uzi在对线阶段都可以获得明显的优势。
同时,我们可以看到,在很多高级游戏,团队组合,特别是游戏后期的组合,在对线阶段会出现更多的不确定性,如一个团队如果能在对线获取非常大的的优势,那么对手即便是后期的英雄,有时候也会输掉比赛。我的目标是了解兑现阶段的表现(前10分钟)是如何影响最终结果的。
我使用Jupyter笔记本和R studio作为代码编辑器。我使用Pandas、NumPy和Matlibplot包进行了一些数据探索。然后,我实现了9个模型,包括集成模型、叠加模型和其他7个分类器。一致性最高的模型为叠加模型,其交叉验证的平均正确率为0.732158,标准差为+/- 0.005171。
数据探索
数据集共有9879场比赛的信息,其中蓝队获胜4930场,占49.9%。这是一个非常平衡的数据集。
图1显示了两个团队的死亡人数。紫分表示红队获胜,黄分表示蓝队获胜。我了解到蓝队在前10分钟杀死超过15人后赢得了所有的比赛。蓝队的胜率在戏剧性地杀死7人之后开始上升。
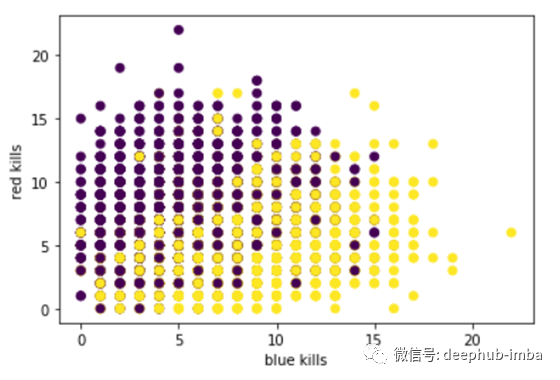
图1
图2显示了两支球队的助攻次数。这与杀戮情节有着相同的模式。然而,在对线阶段,每支队伍只有一场比赛可以杀死20个以上,而在对线阶段,有许多比赛双方都能得到20次以上的助攻。这表明,大多数的杀戮可能来自下路,或者是打野gank了很多次。
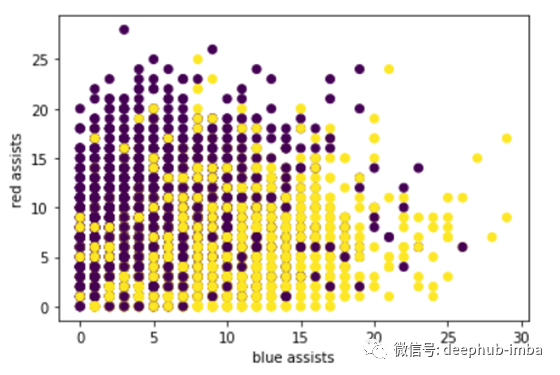
图2 助攻
图3显示了获取金钱数的比较。这张图给了我一个明显的暗示,如果蓝队能在前10分钟内获得2万枚以上的金牌,他们就极有可能赢得比赛。我还手动设置了一个“绿色区域”,即蓝色团队在前10分钟内获得超过21,055枚金牌的游戏。在这个数据样本中,蓝色队伍赢得了所有落在“绿色区域”的比赛。
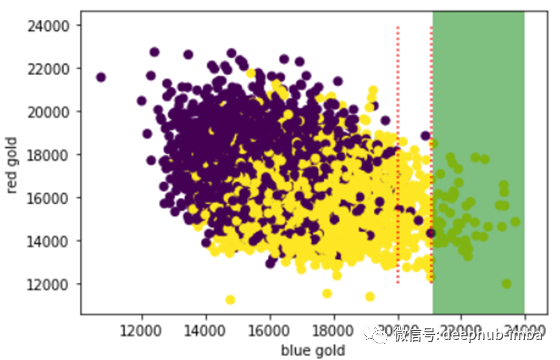
图3 玩家金币
然后,我研究了蓝队在对线阶段取得的金币差异与比赛结果之间的关系。图4显示,当蓝队在前10分钟(红区)的金币差距在-6324和6744之间时,比赛非常不稳定,最终结果可能对任何一方有利。
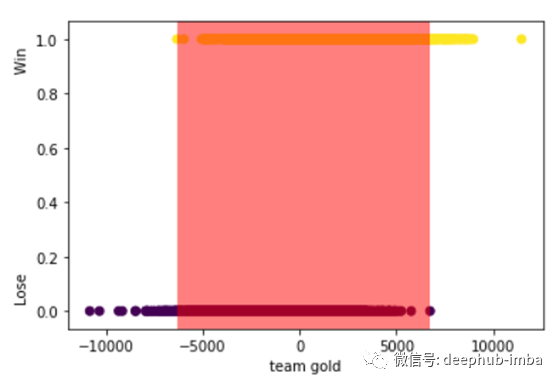
图4 团队金币
在《英雄联盟》的游戏中,在游戏中后期拥有更好视野的团队更容易获得主动权。然而,在游戏早期,视野有多重要?图5并没有显示出视觉在早期游戏中的重要性,这有点超出了我的预期。
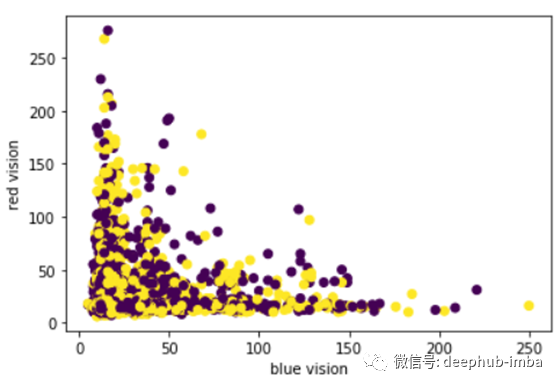
图5 视野
图6显示了蓝队在对线阶段的经验差异与比赛结果之间的关系。当游戏在前10分钟的经验差大约是+/- 5000 XP时,游戏实际上是50-50。在一个普通的框架游戏中,中路和上路可以在大约10分钟内的差距可以达到8级,下路和打野可以分别达到6级。从7级到8级需要1150 XP,从5级到6级需要880 XP。5000经验优势意味着在早期游戏中,每条通道平均会提高至少1级(
1150*2+880*3=4940
)。
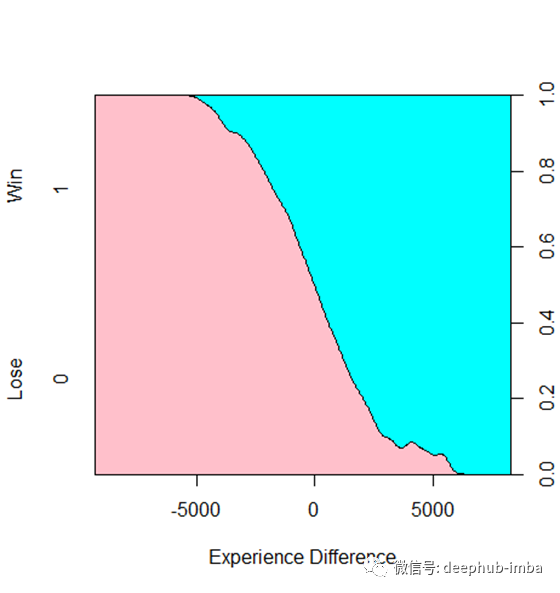
图6 经验差距
除此之外,我还发现了一些有趣的统计数据:
- 当蓝队的KDA在前10分钟大于或等于3时,他们有76.51%的胜率。
- 当蓝队能够在前10分钟内摧毁一座塔时,他们的胜率为75.43%。
- 当蓝队在前10分钟杀死8个人时,他们有69.86%的胜率。
工程特性
因为游戏中有许多价值较大的功能,如经验,总金币等。我对这些特性应用了StandardScaler()和MinMaxScaler()。在测试之后,我决定对项目的其余部分使用StandardScaler()转换。
我还创建了以下功能:
blueKDA/redKDA:蓝队在前10分钟内的杀死比。它是由[(blueKills+blueAssists)/blueDeaths]计算的。我也使用了相同的过程来创建redKDA。
KDADiff:两队之间的KDA差。计算方法为[blueKDA-redKDA]。
blueGoldAdv:这个特性是一个二元变量。它表示蓝队在比赛开始的10分钟内是否至少有20000枚金币的优势。
blueDiffNeg:这个特性是一个二元变量。它表示蓝队在比赛开始前10分钟的金牌差距是否小于或等于-6324。
blueDiffPos:这个特性是一个二元变量。它表示蓝队在比赛开始前10分钟的金牌差距是否大于或等于6744。
建模
因为实际上没有设置检验标准模型有效性的工具,所以这里选择使用交叉验证技术,并使用准确性和ROC作为评估指标。
我测试了以下9种模型:
AdaBoostClassifier, CatBoostClassifier, XGBoostClassifier, Support Vector Classifier, LogisticRegression, RandomForestClassifier, KNeighborsClassifier,EnsembleVoteClassifier, StackingClassifier
eclf = EnsembleVoteClassifier(clfs=[cat,logreg, knn, svc,ada,rdf,xgb], weights=[1,1,1,1,1,1,1])
labels = ['CatBoost','Logistic Regression', 'KNN', 'SVC','AdaBoost',"Random Forest",'XGBoost','Ensemble']
cv=KFold(n_splits = 5, random_state=2022,shuffle=True)
for clf, label in zip([cat,logreg, knn, svc, ada, rdf, xgb,eclf], labels):
scores = cross_val_score(clf, info_x, info_y,
cv=cv,
scoring='accuracy',
n_jobs=-1)
print("[%s] Accuracy: %0.6f (+/- %0.6f) Best: %0.6f " % (label,scores.mean(), scores.std(), scores.max()))
图7显示了这九个模型的输出。经过超参数调整后,堆叠模型的平均准确度为0.732158,为第三佳得分。尽管如此,它的标准偏差也最低,表明它在防止交叉验证测试中过拟合方面表现最佳。集成模型和堆叠模型的ROC得分也最高和第二。
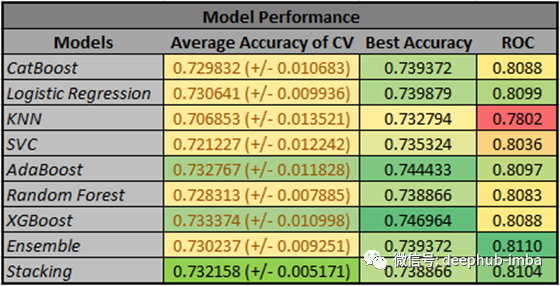
图7
plt.figure()
lw = 1#knn
knn.fit(X_train,y_train)
knn_pred = knn.predict_proba(X_test)
fpr, tpr, threshold = roc_curve(y_test,knn_pred[:,1])
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, color='tab:blue',
lw=lw, label='KNN ROC curve (area = %0.4f)' % roc_auc)
... ...
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([-0.02, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve')
plt.legend(loc="lower right")
plt.show()
图8是我上面提到的所有模型的ROC图:
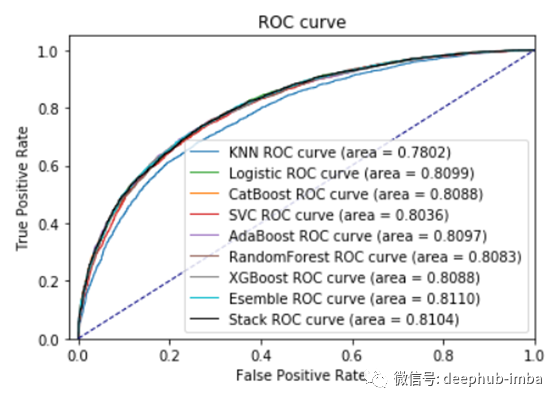
图8
错误预测分析
在该项目结束时,我将数据集按7:3的比例分为训练和测试数据集,并使用堆叠模型对训练数据集进行拟合。然后,我对模型错误预测的实例进行了更多分析。我想了解,在什么样的条件下游戏将变得更加不可预测。
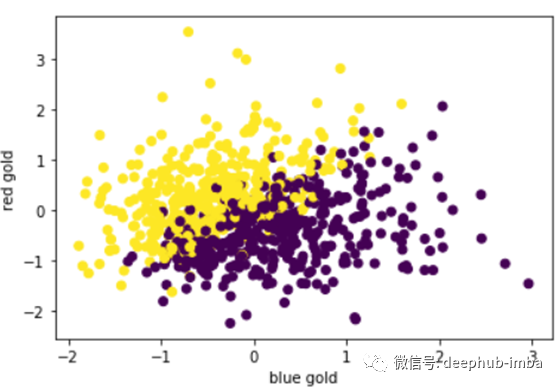
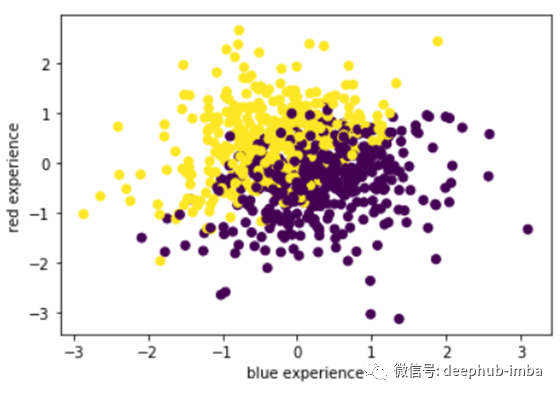
图9和图10展示了两个团队在前10分钟的总金牌和总经验。这两幅图清楚地表明,拥有早期金牌优势和经验的球队最终输掉了比赛。测试集中有799个错误的预测。
我也更进一步研究了打野的表现,因为在对战游戏中,两个团队的上路者通常都需要打野的帮助才能获得主动权。图11显示了打野的表现。这是整个测试数据集,错误的预测和正确的预测分别在“ blueTotalJungleMinionsKilled”和“ redTotalJungleMinionsKilled”之间的平均差异。错误预测的“ JGDiff”小于整个测试数据集的平均水平,这意味着当蓝色打野的表现超出平均水平时,预测会变得更加困难。

结论
我的模型显然遇到了瓶颈,因为它们均无法产生高于0.75的准确性得分。我的假设是最终数据集仅包含44个要素,这是一个非常低维的数据集,因为《英雄联盟》可能从每场游戏中捕获数百个变量。对于进一步的实验,可以将诸如英雄组合,时间范围,特定玩家的冠军熟练度等功能纳入分析。
英雄联盟是过去十年来全球最受欢迎的游戏之一。它召集了来自不同地区的玩家,让他们在召唤师峡谷中分享快乐。即使我试图预测排名游戏的结果,但我始终理解,保持游戏魅力的唯一方法就是使其尽可能不可预测。最激动人心的时刻总是伴随着巨大的复出而进行的终极小组战斗。
最后所有的代码都在这里:https://github.com/jinhangjiang/LOLAnalysis-10mins
作者:Jinhang Jiang
deephub翻译组