
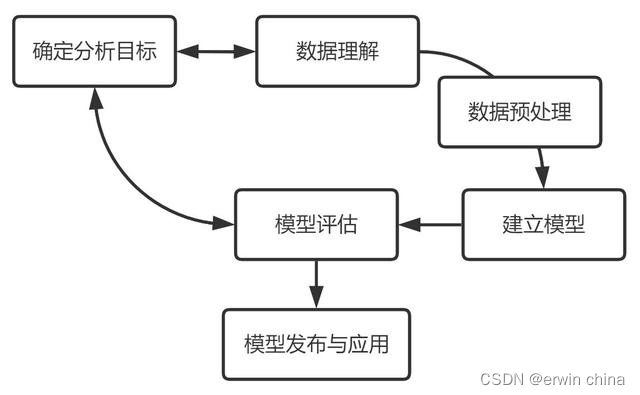
数据建模的基本流程主要包含六个步骤:确定分析目标、数据理解、数据准备、建立模型、模型评估、模型发布与应用。
数据建模是以业务为驱动,基于数据构建科学模型应用于实际中去解决问题的过程。这个过程并不以模型构建、或者模型落地就终止的,而是随着业务在不断地循环改进的。我参考了跨行业数据挖掘标准流程 CRISP-DM 和个人的一些拙见,对数据建模的六个环节进行整理,具体如下:
1.确定分析目标
一切分析的开始都是要基于明确的分析目标,不论何种业务场景,在分析前都需要了解好业务背景、业务需求,明确这次分析是为了解决什么业务问题,分析工作的最核心的需求是什么。如何理解业务需求可以做好以下两点:
与相关进行需求讨论,内容围绕业务逻辑、需求合理性、可行性等方面进行。
确定好分析需求后,指定分析框架和项目计划表。分析框架主要包括:目标变量的定义,大致的分析思路,数据抽样规则,潜在自变量的罗列,项目风险评估,大致的落地应用方案。
2.数据理解
数据理解阶段的重点是放在数据采集获取上。在工作中就是常说的“提数”,这个过程可以进行一系列的数据探索和熟悉,识别数据质量问题,发现数据的内部属性等,可以初步形成一些对数据的假设。
提数是数据建模的基础工作,也是影响模型输出结论的最重要的一步。如果源数据就错了,就不要想分析结果是对的。所以常常会有人说,数据分析工作其实是需要花大概80%的时间在数据上的。
在提数的过程中,需要注意:
要足够熟悉业务,一定要和业务相关人员进行深入沟通,确定好需要什么样的数据指标;
数据常常是有时效的,要考虑抽取的数据是否符合现在的业务需求;
核实数据源的真实性,数据的规范性等等。
3.数据准备(预处理)
拿到数据后,需要思考,这些数据质量有没有问题?以及需要进行怎么样的加工?
常常涉及到的内容会有:
抽样分析:数据量特别大的时候就需要抽取部分数据进行检查
规模分析:常常与抽样分析结合,用以分析某个指标的总体规模
缺失值处理:灵活运用删除和插值
异常值处理:一般都是直接删除
数据转换:规范化、压缩分布区间、分组、分箱等
筛选有效的自变量:有时候自变量特别多,就需要从中选取贡献度最大的部分自变量,筛选指标有:皮尔逊相关系数、数据降维方法等,对一些共线性的自变量,可以生成一个新的综合性的变量进行替代。
不过实际中的业务往往会很复杂,甚至于业务逻辑更加复杂,使得有些问题的发现和解决往往不是一蹴而就的,需要进行多次尝试,或者在后面的操作中发现问题之后再回过头来进行处理。
4.建立模型
数据模型开发的目的是为了从数据中挖掘有价值的信息。实际中比较常见的应用场景有:预测、评价、聚类、推荐、异常检测。
根据确定的分析目标,搭建相关的数据模型,这些模型往往都是基于基础模型进行优化改进的,实际中复杂的往往是数据,模型有时候逻辑并不复杂,且复杂的模型在实际中的应用效果很多时候反而没那么如意。在这个过程中也可以对比多个模型,选取表现较好或表现较为稳定的。一些场景的常见应对算法:
划分群体:聚类、分类
购物篮分析:相关、聚类
预测:回归、时间序列
推荐:关联分析
满意度调查:回归、聚类、分类…
5.模型评估
模型的评估是要以分析目标为导向的,是需要模型更快、还是需要模型更准确、还是需要模型的泛化性能更好、抑或是需要模型的稳定性强等等,都是建立在一开始确立的分析业务目标的基础之上。
此外,还需要对得到的模型提出这两个问题:
这个模型解决了什么问题?是否符合一开始的目标;
模型的解决效果是怎么样的?
6.模型发布与应用
到了这一步,要将模型投入到实际的业务中应用以产生价值,当然,到这里还不算结束,还需要对模型的应用效果做及时的跟踪反馈,以便之后的优化更新。数据模型就像一个产品一样,它的生命周期从一开始到最后淘汰,在这个过程中是需要不断更新迭代的,就算业务变了,数据模型的搭建经验也可以迁移到其他业务中去。
落地前:相关开发人员要撰写清晰的应用文档以便模型高效实施;落地后:跟踪落地效果,及时优化模型及应用方案。最后,对数据模型开发项目做好经验总结。
版权归原作者 erwin china 所有, 如有侵权,请联系我们删除。