
1、 数据集介绍
SVHN全称Street View House Number数据集,它是深度学习诞生初期被创造出来 的众多数字识别数据集中的一个,也是唯一一个基于实拍图片制作而成的数字识别 数据集。其风格与MNST数据集相似,每张图像中是裁剪后获得的一个数字,并且 是数字0~9相关的十分类,但整个数据集支持识别、检测、无监督三种任务,SVHN 数据集也因此具有三种不同的benchmark。由于SVHN原始图像都来源于谷歌地球 (Google Earth)街景图中的门牌号,其像素信息中自然场景图像的复杂性较高, 数字识别难度更大,对识别模型的要求明显也更高。在学术界,当大家已经厌倦 MNIST数据集和Fashion-MNIST数据集上99%的准确率时,常常会使用SVHN数据 集来验证自己的网络架构在实拍照片上的能力。同时,虽然是实拍数据集,但 SVHN识别集的图像被处理得很小(尺寸为32x32,通道为3),样本量也在10万左 右,可以在CPU上实现迭代,是非常适合用来走完整流程的数据集。
2、提前停止算法
优化算法以寻找损失函数的全局最小值作为目的,理想状态下,当算法找到了全局最优时神经网络就“收敛”了,迭代就会停止。然而遗憾的是,我们并不知道真正的全局最小值是多少,所以无法判断算法是否真正找到了全局最小值。其次,一种经常发生的情况可可能是,算法真实能够获取的局部最小值为0.5,且优化算法可能右很短的时间内就锁定了(0.500001,0.49999)之间的范围,但由于学习率等超参数的设置问题,始终无法到达最小值0.5。这两种情况下优化算法都会持续(无效地)逆代下去,因此我们会需要人为来停止神经网络。我们只会在两种情况下停止神经网络的迭代:
1.神经网络已经达到了足够好的效果(非常接近收敛状态),持续迭代下去不会有助于算法效果,比如说,会陷入过拟合,或者会让模型停滞不前
2.神经网络的训练时间太长了,即便我们知道它还没有找到最优结果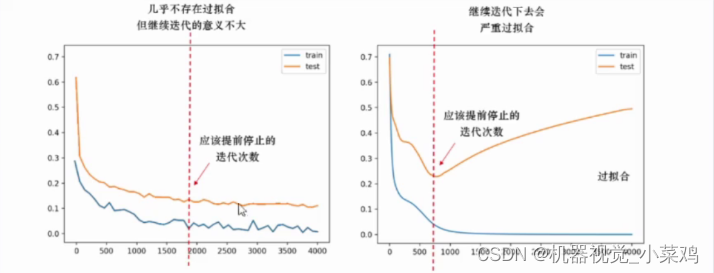
那我们如何找到这个测试集损失不再下降、准确率不再上升的某一时间点”呢?此时,我们可以规定一个阈值,例如,当连续次迭代中,损失函数的减小值都低于阈值tol,或者测试集的分数提升值都低于阈值to的时候,我们就可以令迭代停止了。此时,即便我们规定的epochsi还没有被用完,我们也可以认为神经网络已经非常接近“收敛”,可以将神经网络停下了。这种停止在机器学习中被称为"eary stopping"”。有时候,学习率衰减也可能会与early stopping结合起来。在有的神经网络中,我们或许会规定,当连续次迭代中损失函数的减小值都低于阈值tol时,将学习率进行衰减。当然,如果我们使用的优化算法中本来就带有学习率衰减的机制,那我们则不需要考虑这点了。 在实际实现提前停止的时候,我们规定连续次是连续5次(如果你愿意,可以设这个值为超参数)。同时,损失函数的减小值并不是在这一轮迭代和上一轮迭代中进行比较,我们需要让本轮迭代的损失与历史迭代最小损失比较,如果历史最小损失-本轮迭代的损失>tol,我们才认可损失函数减小了。这种设置对于不稳定的构不太友好,如果我们发现模型不稳定,则可以设置较小的阈值。基于这个思路,来看具体的代码:
classEarlyStopping():def__init__(self,patience=5,tol=0.0005):#惯例地定义我们所需要的一切变量/属性
self.patience = patience
self.tol = tol
self.counter =0
self.lowest_loss =None
self.early_stop =Falsedef__call__(self,val_loss):#这一轮迭代地损失与历史最低损失之间的差if self.lowest_loss ==None:
self.lowest_loss = val_loss
elif self.lowest_loss - val_loss > self.tol:
self.lowest_loss = val_loss
self.counter =0elif self.lowest_loss - val_loss < self.tol:
self.counter +=1print("\t NOTICE: Early stopping counter {} of {}".format(self.counter,self.patience))if self.counter >=self.patience:print('\t NOTICE: Early stopping Actived')
self.early_stop =Truereturn self.early_stop
3、 训练过程
3.1、前期准备
导入所需包以及函数
import os
import torch
os.environ['KMP_DUPLICATE_LTB_OK']='True'#用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True#用于加速Gpu代码import torchvision
from torch import nn,optim
from torch.nn import functional as F
from torchvision import transforms as T
from torchvision import models as M
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from time import time
import datetime
import random #控制随机性import numpy as np
import pandas as pd
import gc #垃圾回收#设置全局的随机数种子
torch.manual_seed(1412)
random.seed(1412)
np.random.seed(1412)
3.1.1、 设备准备
配置设备
torch.cuda.is_available()
device = torch.device('cuda'if torch.cuda.is_available()else'cpu')
3.1.2、加载数据集
3.1.2.1、 加载数据集,用于查看数据集特征
train = torchvision.datasets.SVHN(root='SVHN',split='train',download=True)
test = torchvision.datasets.SVHN(root='SVHN',split='test',download=True)
查看数据集相关信息

3.1.2.2、 加载数据集为tensor格式
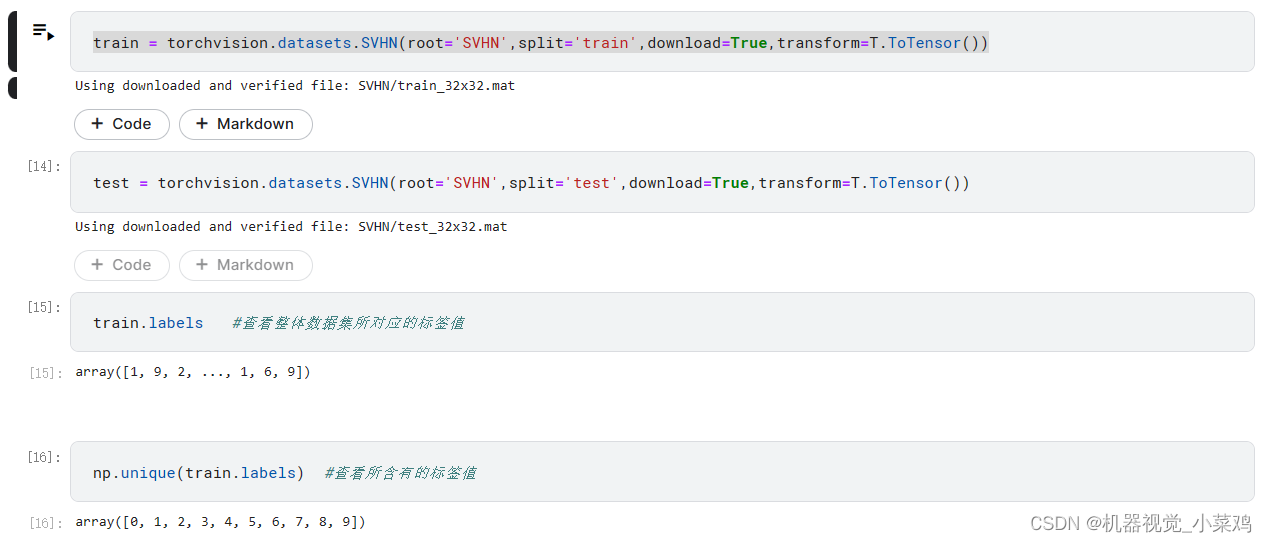
查看数据集中,图片的大小以及通道数
编写程序,使图像可视化
#让每个数据集随机显示五张图象import matplotlib.pyplot as plt
import numpy as np
import random
defplotsample(data):#只能接受tensor格式
fig,axs = plt.subplots(1,5,figsize=(10,10))#建立子图for i inrange(5):
num = random.randint(0,len(data)-1)
nping = torchvision.utils.make_grid(data[num][0]).numpy()
nplabel = data[num][1]#提取标签
axs[i].imshow(np.transpose(nping,(1,2,0)))
axs[i].set_title(nplabel)
axs[i].axis("off")#消除每个子图的坐标轴
效果展示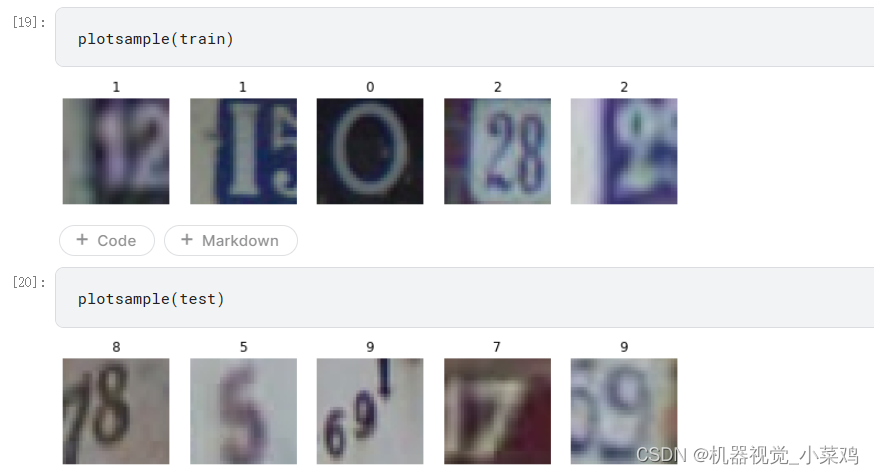
3.1.2.3 数据增强操作
trainT = T.Compose([T.RandomCrop(28),T.RandomRotation(degrees=[-30,30]),T.ToTensor(),T.Normalize(mean=[0.485,0.456,0.106],std=[0.229,0.224,0.225])])
testT = T.Compose([T.RandomCrop(28),T.ToTensor(),T.Normalize(mean=[0.485,0.456,0.106],std=[0.229,0.224,0.225])])
train = torchvision.datasets.SVHN(root='SVHN',split='train',download=True,transform=trainT)
test = torchvision.datasets.SVHN(root='SVHN',split='test',download=True,transform=testT)
对增强后的数据进行可视化
3.2、构建网络
加载经典网络
torch.manual_seed(1412)
resnet18_ =M.resnet18()
vgg16_ =M.vgg16()
自定义MyResNet网络
classMyResNet(nn.Module):def__init__(self):super().__init__()
self.block1 = nn.Sequential(nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1,bias=False),resnet18_.bn1,resnet18_.relu)
self.block2 = resnet18_.layer2
self.block3 = resnet18_.layer3
self.avgpool = resnet18_.avgpool
self.fc = nn.Linear(in_features=256,out_features=10,bias=True)defforward(self,x):
x = self.block1(x)
x = self.block3(self.block2(x))
x = self.avgpool(x)
x = x.view(x.shape[0],256)
x = self.fc(x)return x
自定义MyVgg网络
classMyVgg(nn.Module):def__init__(self):super().__init__()
self.features = nn.Sequential(*vgg16_.features[0:9]#星号用于解码,nn.Conv2d(128,128,kernel_size=3,stride=1,padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(2,2,padding=0,dilation=1,ceil_mode=False))
self.avgpool = vgg16_.avgpool
self.fc = nn.Sequential(nn.Linear(7*7*128,out_features=4096,bias=True),*vgg16_.classifier[1:6],nn.Linear(in_features=4096,out_features=10,bias=True))defforward(self,x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.shape[0],7*7*128)
x = self.fc(x)return x
网络验证
from torchinfo import summary
summary(MyResNet(),(10,3,28,28),depth=3)
#打印输出==========================================================================================
Layer (type:depth-idx) Output Shape Param #==========================================================================================
MyResNet [10,10]--
├─Sequential:1-1[10,64,28,28]--
│ └─Conv2d:2-1[10,64,28,28]1,728
│ └─BatchNorm2d:2-2[10,64,28,28]128
│ └─ReLU:2-3[10,64,28,28]--
├─Sequential:1-2[10,128,14,14]--
│ └─BasicBlock:2-4[10,128,14,14]--
│ │ └─Conv2d:3-1[10,128,14,14]73,728
│ │ └─BatchNorm2d:3-2[10,128,14,14]256
│ │ └─ReLU:3-3[10,128,14,14]--
│ │ └─Conv2d:3-4[10,128,14,14]147,456
│ │ └─BatchNorm2d:3-5[10,128,14,14]256
│ │ └─Sequential:3-6[10,128,14,14]8,448
│ │ └─ReLU:3-7[10,128,14,14]--
│ └─BasicBlock:2-5[10,128,14,14]--
│ │ └─Conv2d:3-8[10,128,14,14]147,456
│ │ └─BatchNorm2d:3-9[10,128,14,14]256
│ │ └─ReLU:3-10[10,128,14,14]--
│ │ └─Conv2d:3-11[10,128,14,14]147,456
│ │ └─BatchNorm2d:3-12[10,128,14,14]256
│ │ └─ReLU:3-13[10,128,14,14]--
├─Sequential:1-3[10,256,7,7]--
│ └─BasicBlock:2-6[10,256,7,7]--
│ │ └─Conv2d:3-14[10,256,7,7]294,912
│ │ └─BatchNorm2d:3-15[10,256,7,7]512
│ │ └─ReLU:3-16[10,256,7,7]--
│ │ └─Conv2d:3-17[10,256,7,7]589,824
│ │ └─BatchNorm2d:3-18[10,256,7,7]512
│ │ └─Sequential:3-19[10,256,7,7]33,280
│ │ └─ReLU:3-20[10,256,7,7]--
│ └─BasicBlock:2-7[10,256,7,7]--
│ │ └─Conv2d:3-21[10,256,7,7]589,824
│ │ └─BatchNorm2d:3-22[10,256,7,7]512
│ │ └─ReLU:3-23[10,256,7,7]--
│ │ └─Conv2d:3-24[10,256,7,7]589,824
│ │ └─BatchNorm2d:3-25[10,256,7,7]512
│ │ └─ReLU:3-26[10,256,7,7]--
├─AdaptiveAvgPool2d:1-4[10,256,1,1]--
├─Linear:1-5[10,10]2,570==========================================================================================
Total params:2,629,706
Trainable params:2,629,706
Non-trainable params:0
Total mult-adds (G):2.07==========================================================================================
Input size (MB):0.09
Forward/backward pass size (MB):38.13
Params size (MB):10.52
Estimated Total Size (MB):48.75==========================================================================================
summary(MyVgg(),(10,3,28,28),depth=4)#打印输出为:==========================================================================================
Layer (type:depth-idx) Output Shape Param #==========================================================================================
MyVgg [10,10]--
├─Sequential:1-1[10,128,7,7]--
│ └─Conv2d:2-1[10,64,28,28]1,792
│ └─ReLU:2-2[10,64,28,28]--
│ └─Conv2d:2-3[10,64,28,28]36,928
│ └─ReLU:2-4[10,64,28,28]--
│ └─MaxPool2d:2-5[10,64,14,14]--
│ └─Conv2d:2-6[10,128,14,14]73,856
│ └─ReLU:2-7[10,128,14,14]--
│ └─Conv2d:2-8[10,128,14,14]147,584
│ └─ReLU:2-9[10,128,14,14]--
│ └─Conv2d:2-10[10,128,14,14]147,584
│ └─ReLU:2-11[10,128,14,14]--
│ └─MaxPool2d:2-12[10,128,7,7]--
├─AdaptiveAvgPool2d:1-2[10,128,7,7]--
├─Sequential:1-3[10,10]--
│ └─Linear:2-13[10,4096]25,694,208
│ └─ReLU:2-14[10,4096]--
│ └─Dropout:2-15[10,4096]--
│ └─Linear:2-16[10,4096]16,781,312
│ └─ReLU:2-17[10,4096]--
│ └─Dropout:2-18[10,4096]--
│ └─Linear:2-19[10,10]40,970==========================================================================================
Total params:42,924,234
Trainable params:42,924,234
Non-trainable params:0
Total mult-adds (G):1.45==========================================================================================
Input size (MB):0.09
Forward/backward pass size (MB):14.71
Params size (MB):171.70
Estimated Total Size (MB):186.50==========================================================================================
3.3、 定义训练函数
deffit_test(net,batchdata,testdata,criterion,opt,epochs,tol,modelname,PATH):"""
对模型进行训练,并在每个epoch后输出训练集和测试集上的准备率/损失
"""
SamplePerEpoch = batchdata.dataset.__len__()
allsamples = SamplePerEpoch * epochs
trainedsample =0
trainlosslist =[]
testlosslist =[]
early_stopping = EarlyStopping(tol=tol)
highestacc =Nonefor epoch inrange(1,epochs+1):
net.train()
correct_train =0
loss_train =0for batch_idx,(x,y)inenumerate(batchdata):
x = x.to(device,non_blocking=True)
y = y.to(device,non_blocking=True).view(x.shape[0])
sigma = net.forward(x)
loss = criterion(sigma,y)
loss.backward()
opt.step()
opt.zero_grad()
yhat = torch.max(sigma,1)[1]#真正的预测标签
correct = torch.sum(yhat==y)#实际预测正确的样本数量
trainedsample += x.shape[0]
loss_train += loss
correct_train += correct
if(batch_idx+1)%125==0:print("Epoch{}:[{}/{}({:.0f})%)]".format(epoch,trainedsample,allsamples,100*trainedsample/allsamples))
TrainAccThisEpoch =float(correct_train*100)/SamplePerEpoch
TrainLossThisEpoch =float(loss_train*100)/SamplePerEpoch
trainlosslist.append(TrainLossThisEpoch)#清理GPU内存 清理掉不需要的中间变量del x,y,correct
gc.collect()#清除数据与变量相关的缓存
torch.cuda.empty_cache()#测试一次
net.eval()
loss_test =0
correct_test =0
TestSample = testdata.dataset.__len__()for x,y in testdata:with torch.no_grad():
x = x.to(device,non_blocking=True)
y = y.to(device,non_blocking=True).view(x.shape[0])
sigma = net.forward(x)
loss = criterion(sigma,y)
yhat = torch.max(sigma,1)[1]
correct = torch.sum(yhat==y)
loss_test += loss
correct_test += correct
TestAccThisEpoch =float(correct_test*100)/TestSample
TestLossThisEpoch =float(loss_test*100)/TestSample
testlosslist.append(TestLossThisEpoch)print("\t Train loss:{:.6f},Test loss:{:.6f},Train acc:{:.3f}%,test acc:{:.3f}%".format(TrainLossThisEpoch
,TestLossThisEpoch
,TrainAccThisEpoch
,TestAccThisEpoch))del x,y,correct
gc.collect()#清除数据与变量相关的缓存
torch.cuda.empty_cache()if highestacc ==None:
highestacc = TestAccThisEpoch
if highestacc < TestAccThisEpoch:
highestacc = TestAccThisEpoch
torch.save(net.state_dict(),os.path.join(PATH,modelname+".pt"))print("\t Weight Saved")#提前停止
early_stop = early_stopping(TestLossThisEpoch)if early_stop =="True":breakprint("Done")return trainlosslist,testlosslist
定义绘画函数
defplotloss(trainloss, testloss):
plt.figure(figsize=(10,7))
plt.plot(trainloss,color="red",label="Trainloss")
plt.plot(testloss,color="orange",label="Testloss")
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
3.4、定义整体过程函数
deffull_procedure(net,epochs,bs,modelname,PATH,lr =0.001,alpha =0.99,gamma =0,wd =0,tol=10**(-5)):
torch.manual_seed(1412)
torch.cuda.manual_seed(1412)
torch.cuda.manual_seed_all(1412)
batchdata = DataLoader(train,batch_size=bs,shuffle=True,drop_last=False,pin_memory=True)
testdata = DataLoader(test,batch_size=bs,shuffle=False,drop_last=False,pin_memory=True)
criterion = nn.CrossEntropyLoss(reduction="sum")
opt = optim.RMSprop(net.parameters(),lr=lr,alpha=alpha,momentum=gamma,weight_decay=wd)
trainloss,testloss = fit_test(net,batchdata,testdata,criterion,opt,epochs,tol,modelname,PATH)return trainloss,testloss
3.5、 开始迭代训练
PATH ="/kaggle/working/SVHN"
avgtime =[]for i inrange(1):
torch.manual_seed(1412)
torch.cuda.manual_seed(1412)
torch.cuda.manual_seed_all(1412)
resnet18_ = M.resnet18()
net = MyResNet().to(device,non_blocking=True)
start = time()
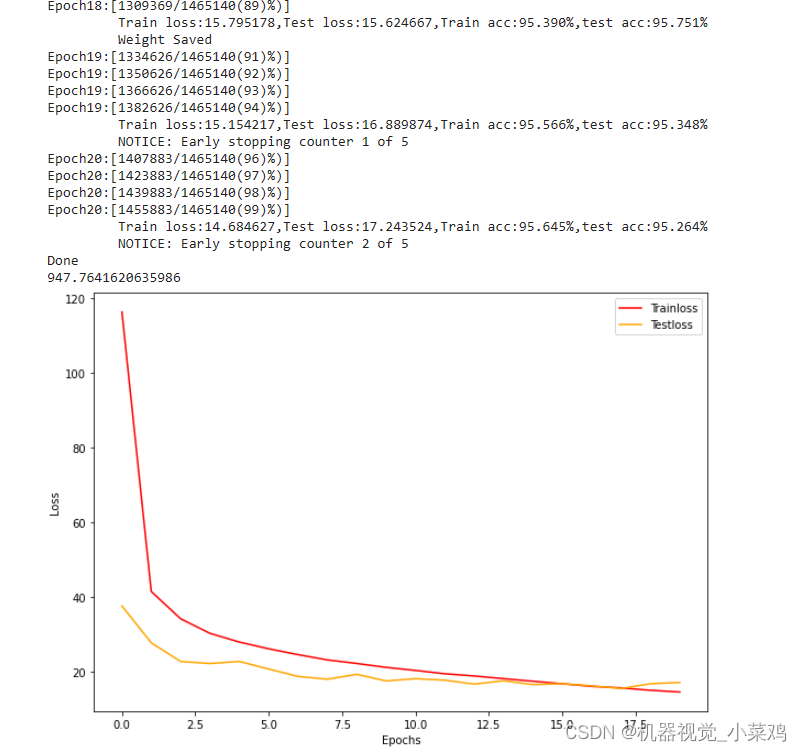
trainloss,testloss = full_procedure(net,epochs=20,bs=128,modelname="model_seletion_resnet",PATH=PATH)print(time()-start)
plotloss(trainloss,testloss)
3.6、 给出训练结果,并画出图形
版权归原作者 机器视觉_小菜鸡 所有, 如有侵权,请联系我们删除。