
我今天要捅一个火药桶问题:如何进行单测。因为关于这个话题的争论实在太多了。为了减少非议,首先,我要界定一下问题范围,我这里所说的测试是针对分布式系统服务(微服务)的单元测试,不同的产品形态,测试方法差异很大,比如嵌入式系统、office软件的测试不是我们要讨论的范围。其次,我直接给观点,我认为微服务的单元测试的最佳实践就是:粗粒度单元测试优先,细粒度单元测试补足,关注测试效率(执行效率、代码效率)和代码可测性,不追求数字的代码覆盖率,但求吾心自足。
1.都是概念惹得祸
关于单元测试的定义,教科书上都是这么说的:单元测试(unit testing),是指对软件中的最小可测试单元进行检查和验证。对于单元测试中单元的含义,一般来说,要根据实际情况去判定其具体含义,如C语言中单元指一个函数,Java里单元指一个类。工厂在组装一台电视机之前,会对每个元件都进行测试,这就是单元测试。
就和当年的“微服务”概念惹的祸一样,“单元”和“微”直接指向了“小”的意思,导致研发过程中,写了大量细粒度的针对类和方法的单元测试,却收益甚微,投入产出完全不成正比。在这个背景下,有人提出我们要从金字塔测试模式转向菱形测试模式,来解决单元测试效率低下,效益不足的问题:
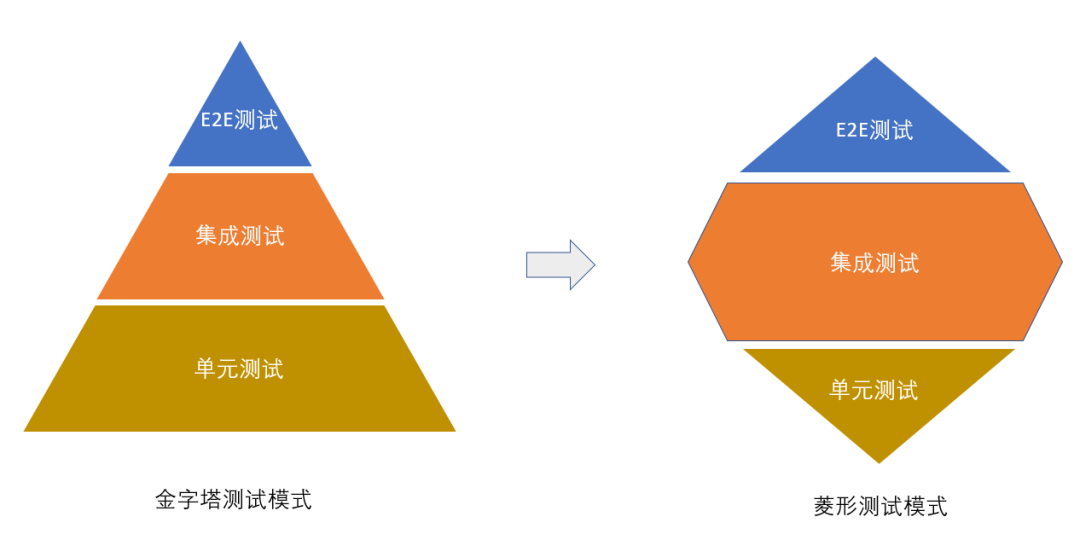
2.重新定义单元测试
和Martin Fowler当年出来道歉,承认“微服务”这个概念有意无意的诱导很多团队把服务捣碎,弄得一地鸡毛、哀鸿遍野一样。面对单元测试的争议,以及其带来的问题,老人家又一次出来开始澄清概念,说我们对“单元”的认知有误解,在这篇讨论关于测试模型的文章中,Martin特意向Kent beck求证了unit test的定义问题,kent说:
From the early days of XP-inspired unit testing there were those who disliked the term “unit test” and proposed using names like “microtest” or “programmer test” instead. (当初起unit test这个名字的时候,就有很多人提出反对意见,可能叫开发者测试更合适一些。)
Martin在这篇文章的核心观点是,你们不要再纠结什么金字塔模式和什么菱形模式了,也不要再纠结集成测试(Integration test)和单元测试(Unit test)的边界问题了。他们都属于开发者测试,即开发人员要去做的测试,只要不是QA要做的测试都是Dev测试。所以对于开发人员而言,选择对你效益最大的测试方式,管他是Integration test还是unit test呢。他试图用Dev测试这个概念,来抹平集成测试和单元测试的差异。实际上,也是在变相承认菱形测试模式要比金字塔测试模式更有效的事实。
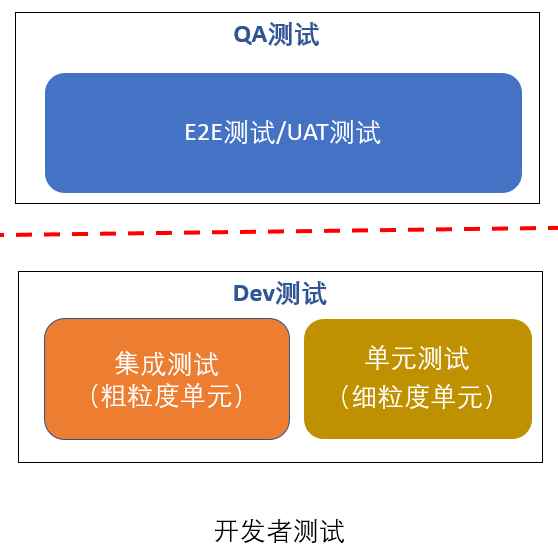
好吧,我们好像又一次被玩了。好在,有我给大家及时止血。就像我当年劝大家不要把服务拆的太碎一样,我今天也要劝大家不要把测试写的太碎。更准确的说,也不是太碎,应该是该粗的粗,该细的细。因为粗有粗的方式,细有细的好处。为了区分这个粗和细,我要创造两个新的概念,对不起大家,Martin刚澄清了一个概念,我又搞出两个新概念,没办法,语言就是这么模糊,语言的模糊性也是个哲学问题,有兴趣可以去看看维特根斯坦的“语言游戏说”。这两个新概念是:
- 粗粒度单元测试(CUT,Coarse-grained Unit Test):这个概念对应的是我们传统认知上的Integration Test,粗的意思这个“单元”很大,跨了整个应用。
- 细粒度单元测试(FUT,Fine-grained Unit Test): 这个概念对应的是我们传统认知上的Unit Test,就是测一个类、一个方法。
导言的时候我说了,要粗粒度测试优先,对于微服务而言,效率最高的测试就是直接从对外接口开始测,这样做的好处至少有两点,首先是我们可以用尽量少的测试代码,覆盖更多的功能逻辑,测试效率高。其次是我们可以在保证接口不变的情况下,对内部逻辑进行重构,重构效率高。能达到同样的效果,谁TM愿意一个类一个方法的写测试,关键是大部分代码都是一坨一坨的(可测性差),你让我测单个类,单个方法我也无从下手啊。当然粗粒度也会引入新的问题,如何解决这些问题,下面会详细说。这里你首先要记住,先考虑集成测试(粗粒度单元测试)就对了。
3. 如何正确实施“粗粒度单元测试”
对于微服务分布式系统而言,“粗粒度单元测试”最大挑战在于如何解决周边依赖问题,对于一个典型的应用而言,它可能会依赖数据库、消息中间件、缓存系统等,以及周边的其它服务。如何处理这些依赖,是我们必须要面对和要解决的问题。其实方案只有一种叫Test Double(测试替身),即要用“替身”来代替依赖,从而让程序在没有真正依赖环境的情况下,仍然可以运行,验证功能。这些“替身”有不少fancy的名字,比如dummy、fake、stub、mock、spy等,这里我就不啰嗦这些概念的差异了,也不重要。重要的是我们该如何高效的实施“粗粒度单元测试”。
3.1 mock
使用mock是我们处理外部依赖的最常见做法,有很多的框架比如Mockito,EasyMock支持我们去做mock的事情,比如对于常见的数据库依赖,我们可以通过如下的方式去mock:
import static org.mockito.Mockito.*;
public class UserServiceTest {
@Test
public void testGetUserById() {
// 创建一个模拟的 UserRepository
UserRepository userRepositoryMock = mock(UserRepository.class);
// 创建一个 UserService 实例,将模拟的 UserRepository 传入
UserService userService = new UserService(userRepositoryMock);
// 设置模拟的 UserRepository 的行为
User expectedUser = new User(1, "John");
expectedUser.setAge(35);
expectedUser.setSex("male");
expectedUser.setEducation("doctor");
when(userRepositoryMock.getUserById(1)).thenReturn(expectedUser);
// 调用 UserService 的方法
User actualUser = userService.getUserById(1);
// 验证模拟的 UserRepository 的方法是否被正确调用
verify(userRepositoryMock).getUserById(1);
// 断言返回的用户是否符合预期
assertEquals(expectedUser, actualUser);
}
}
这种方法有效,但存在两个问题:
- 比较繁琐,当需要构造的对象有大量字段的时候,需要额外写很多的代码。
- 有些功能测不全,比如这里的SQL语句就不能被测试到,因为数据库的访问是被mock掉的。
3.2 embedded server
鉴于以上的问题,我发现很多团队都开始转向embedded方案,即在本地拉起一个真实的内嵌依赖服务,比如我用到了Redis缓存,那么我可以使用embedded-redis启动一个本地的redis,从而连接到“真实”的redis环境。使用很简单,只需要加入下面的依赖就可以。在Junit5的Extension帮助下,我们可以很优雅的使用embedded的服务。
<dependency>
<groupId>com.github.codemonstur</groupId>
<artifactId>embedded-redis</artifactId>
<version>1.4.2</version>
<scope>test</scope>
</dependency>
类似的,我们常用的中间件比如kafka、MySQL、MongoDB等等都有相对应的embedded的方案。对于非中间件,比如其它服务依赖,我们可以使用wiremock来做其它服务API的“替身”。这些动作在很大程度上可以帮助我们消解依赖问题,这样做可以给我们带来以下好处:
- 在同样代码覆盖率的情况下,使用embedded的集成测试方案,可以写更少的测试用例和代码,研发效率更高
- 因为使用的是真实中间件服务,可以让我们的测试更加贴近真实环境,测试的有效性更高
- 测试的入口是接口。这种更大测试粒度带来的好处是,可以帮助我们更好的重构内部业务逻辑,而不用担心破坏测试用例,如果UT太细的话,重构代码的同时还要重写UT,比较麻烦。
你也许会说,和Mock方案相比,这里的数据准备并没有比Mock少多少啊,实际上的确如此,对于测试数据,我们可以使用测试夹具(Test Fixtures)把测试数据用json/xml的形式放在resource下面,这样可以提升我们的数据复用和数据准备效率。
除此之外,embedded还有一个比较严重的问题——慢!即在运行测试的时候,需要拉起整个环境,整个过程很耗时,一般情况下,如果要启动3个embedded服务,短则一分钟多则几分钟,这显然与我们通常认为的单测要“短平快”不相符。这会极大的抑制我们在开发阶段,频繁的执行测试,以获得quick feedback的积极性,更不用说TDD了。
3.3 TestsContainer
实际上对于测试运行慢的问题,我早年在eBay工作的时候,就深受其扰,当时eBay的服务框架很厚重,其init过程慢且繁琐,启动一下测试至少要5分钟,是可忍孰不可忍。为了解决这个问题,我当时写了一个小工具,期望hold住服务进程,从而可以实现“启动一次,多次运行”。当我发布这个小工具的时候,它简直成为了团队的救星,设想如果一个开发人员一天要运行20次测试,因为这个工具就能节省100分钟的等待时间。
后来随着COLA开源,我把这个小工具作为COLA的一个组件一起开源,取名叫TestsContainer,寓意是承载Tests的容器。实际上,这个工具背后的原理非常简单,只做了两件事:
- 用一个while(true)循环hold住Spring容器,并不断监听用户从console的输入,来决定执行哪个用例。
- 使用Junit5的Launcher执行用例,因为Junit和Spring集成的很好,Launcher会自动处理相关Spring的依赖。然而在Junit5之前,是手动采用反射的方式,注入Spring的依赖,繁琐且容易有bug。
通过这种方式,用例执行慢的问题在一定程度上得到了很大缓解。最近在灵衢项目,代码写的比较多,我每天至少都要用这个工具执行近百次的测试用例。
除此之外,还有一个工具叫TestContainers,这名字和我的工具很像,但完全不是一回事。它是用Docker容器来代替embedded server方案,这个工具给到我的启示是我们可以用Docker容器把依赖的中间件在本地预置启动好,这样就不用每次都重新拉起新的embedded服务,同样也可以提效。在我最近开发的项目中,因为embedded-GaussDB有问题,我采用的就是用Docker安装了一个本地的GaussDB来解决依赖问题,这种方式可以让我的本地调测更快。不过在CI的环境中,因为没有预安装的数据库,我们还是得采用embedded方式。好在一个应用的test suite只需要启动一次embedded的服务,所以CI的回归测试整体时间损耗也是可以接受的。
3.4 “粗粒度单元测试”小结
说了这么多,总结一下,对于分布式微服务系统而言,我们提倡“粗粒度单元测试”优先的做法,其好处是:粗粒度便于内部重构、测试效率高、测试有效性高。其缺点是依赖启动时间长,为了解决这个问题。我们可以通过COLA-TestsContainer实现“启动一次,多次运行”来实现提效。我们也可以用Docker容器方案,在本地预安装依赖服务,从而减少反复启动带来的时间损耗。
5.“细粒度单元测试”也有它的妙用
熟悉COLA架构的同学,应该知道,我主张把核心的业务逻辑沉淀到domain领域层,为了保证domain层的纯粹和解耦,我们要尽量保证domain里面的逻辑是pojo的,不依赖任何的技术细节(Spring框架、Web框架、中间件等)。对于Domain层,就特别适合单元测试,也就是我这里说的“细粒度单元测试”。因为它粒度小、执行速度快。
举个例子,在我最近在做华为云的灵衢项目里,有一个灵衢网络分配通过配置区间分配vlan的关键业务逻辑。在我重构之前,这段关键逻辑完全是过程式的淹没在一个长方法里。我看了之后,“抽性大发”,抽象了一个VlanScope的概念,专门负责Scope配置解析和vlanId分配,用VlanScope这个专门的Domain Enitity(领域对象)将这个关键逻辑,从不起眼的代码段中凸显出来,给它足够的尊重。
重构之后的VlanScope其实现逻辑如下:
public class VlanScope {
private static class Scope {
int start;
int end;
private Scope(int start, int end) {
this.start = start;
this.end = end;
}
}
private List<Scope> scopes = new ArrayList<>();
/**
* 使用vlan的配置信息初始化构造VlanScope
*
* @param vlanScopeConfig 配置内容格式为“3000-3390,3500-3600” 表示这两个区间内的vlan是可用的。
*/
public VlanScope(String vlanScopeConfig) {
if (StringUtils.isEmpty(vlanScopeConfig)) {
throw new XlinkException.ConfigError("config vlan_scope can not be empty");
}
String[] vlanScopes = vlanScopeConfig.split(",");
for (String vlanScope : vlanScopes) {
String[] scopeStr = vlanScope.split("-");
Scope scope = new Scope(Integer.valueOf(scopeStr[0]), Integer.valueOf(scopeStr[1]));
scopes.add(scope);
}
}
/**
* 分配vlan,从配置的vlanScope中除去occupiedVlan,选择一个可用的vlan,否则报错
*
* @param occupiedVlans
*/
public int allocateVlan(Set<String> occupiedVlans) {
for (Scope scope : scopes) {
int vlan = scope.start;
while (vlan <= scope.end) {
if (!occupiedVlans.contains(String.valueOf(vlan))) {
return vlan;
}
vlan++;
}
}
throw new XlinkException("no available vlan, allocate vlan failed");
}
}
这种领域能力的沉淀,不仅让原来的业务语义更加清晰,也极大的提升了代码的可测试性。让我们有机会对关键业务逻辑进行更加充分的测试。因为这个UT只是测试vlan配置和分配的功能,而且是pojo的,符合我们传统关于单元测试“短平快”的定义。当然在本文,你知道,我们给了它一个新的名称:细粒度单元测试。对于上面的代码,我们可以用以下的“细粒度单元测试”去覆盖:
public class VlanScopeTest {
@Test
public void testEmptyConfig() {
assertThrows(XlinkException.ConfigError.class, () -> {
VlanScope vlanScope = new VlanScope("");
});
}
@Test
public void testInvalidConfig() {
assertThrows(NumberFormatException.class, () -> {
VlanScope vlanScope = new VlanScope("3000-abc");
});
}
@Test
public void testValidConfig() {
VlanScope vlanScope = new VlanScope("3000-3390,3500-3600");
List<VlanScope.Scope> scopes = vlanScope.getScopes();
assertEquals(2, scopes.size());
}
@Test
public void testAllocateFail() {
assertThrows(XlinkException.class, () -> {
VlanScope vlanScope = new VlanScope("3000-3001,3500-3501");
Set<String> occupiedVlan = Set.of("3000", "3001", "3500", "3501");
vlanScope.allocateVlan(occupiedVlan);
});
}
@Test
public void testAllocateSuccess() {
VlanScope vlanScope = new VlanScope("3000-3001,3500-3600");
Set<String> occupiedVlan = Set.of("3000", "3001", "3500");
int vlan = vlanScope.allocateVlan(occupiedVlan);
assertEquals(3501, vlan);
}
}
可以看到,在本UT中,我们不仅测试了正常情况,也测试了更多的异常情况,因为其可测性好,运行也快,而且又是关键业务逻辑,值得我们多花些时间写UT覆盖更多的场景。而这种敏捷性、灵活性,正是“粗粒度单元测试”所缺失的。所以作为“粗粒度单元测试”的补充,“细粒度单元测试”在测试pojo的Domain层逻辑上能发挥重要的补充作用。这就是我在导言中说的细粒度测试补足的含义。
6. 代码覆盖率,要写多少测试才够
以上介绍的粗粒度单元测试优先,细粒度单元测试补足,是Dev测试的方法。接下来我要聊聊哲学问题,即大家一直争论不休的代码覆盖率问题。首先,我要表明一下我的态度,我反对一切单纯追求数字的刻板形式主义。比如什么代码覆盖率必须要90%,否则不能合入代码。这个数字有一些参考意义,但最多只是个手段,不能上纲上线的作为管理目标,代码质量才是我们的目标。否则即使你完成任务式的(dutifully)实现了100%的覆盖率,但UT里面的assert都没有,也不会对代码质量提升有什么帮助。
这里,我想引用Kent Beck(TDD发明人,敏捷宣言起草人)在一篇stackoverflow回复中关于测试实用主义哲学的言论,因为我也是一个典型的实用主义者,他说:
“I get paid for code that works, not for tests, so my philosophy is to test as little as possible to reach a given level of confidence,If I don't typically make a kind of mistake (like setting the wrong variables in a constructor), I don't test for it. I do tend to make sense of test errors, so I'm extra careful when I have logic with complicated conditionals.”
kent的意思大概是:我的测试哲学是只测试我认为有必要测试的部分,比如这个constructor里面的设值我认为不会出错,我就不测,那个条件分支很复杂容易出错,我就多测。不追求数字的代码覆盖率,但求吾心自足(有足够的信心交付我开发的代码)。
所以,这里我的态度也很明确了,即不追求数字的代码覆盖率,但求吾心自足。
7.总结
在分布式微服务系统的研发中,我们应该遵循以下的开发者测试策略:
- 优先使用粗粒度单元测试(集成测试),因为其测试效率更高、更有效、更稳定、更有利于重构、ROI(投入产出比)更高
- 使用TestsContainer,或者预安装好的中间件,解决集成测试依赖启动慢的问题,不能实现快速反馈,就会抑制执行测试的积极性,更不用说TDD了
- 对关键的业务逻辑,要沉淀为pojo的领域能力,提升其可测试性。然后用细粒度单元测试(单元测试)对其进行充分测试,逻辑越关键、越复杂,越要多测
- 测试的代码覆盖率差不多就行了(80%?),关键是要有效,无效100%也是白搭。不要为了管理要求弄虚作假,按照上面3个步骤,做到无愧吾心就好
版权归原作者 张建飞(Frank) 所有, 如有侵权,请联系我们删除。