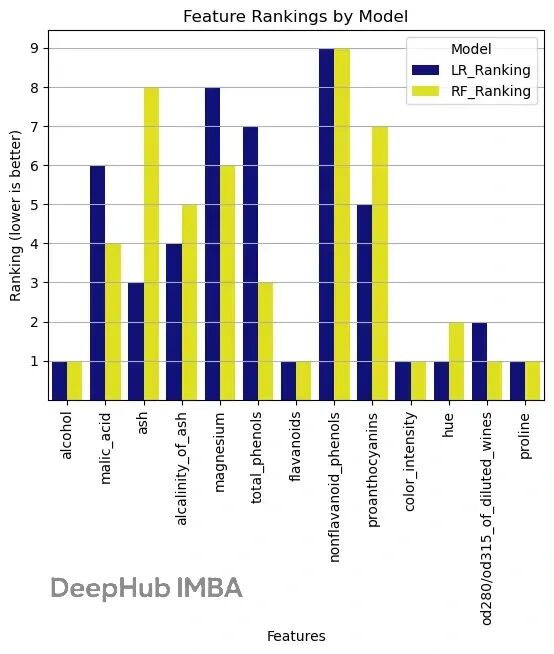
sklearn 特征选择实战:用 RFE 找到最优特征组合
本文会详细介绍RFE 的工作原理,然后用 scikit-learn 跑一个完整的例子。
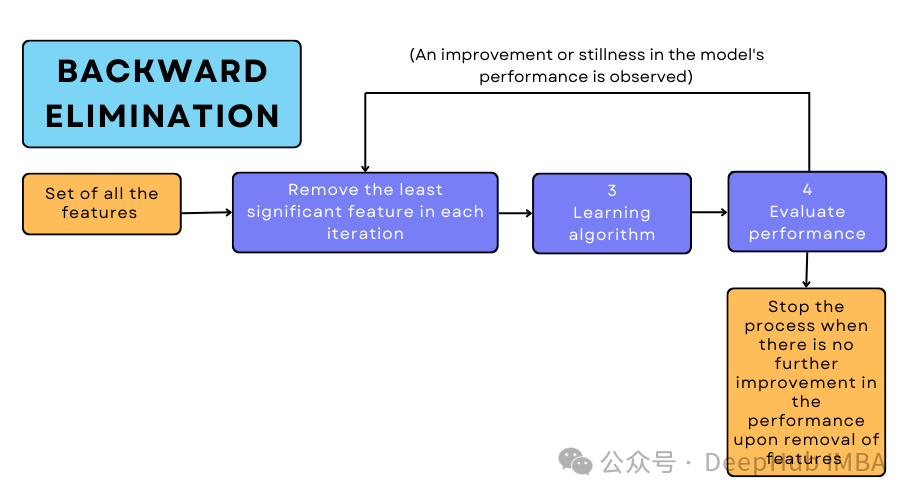
机器学习特征筛选:向后淘汰法原理与Python实现
向后淘汰法(Backward Elimination)是机器学习领域中一种重要的特征选择技术,其核心思想是通过系统性地移除对模型贡献较小的特征,以提高模型性能和可解释性。

Featurewiz-Polars:基于XGBoost的高性能特征选择框架,一行代码搞定特征选择
,Featurewiz已成为许多数据科学家的首选工具,在学术领域获得**140多篇Google Scholar论文引用**。
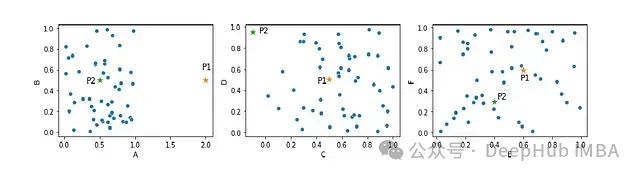
基于特征子空间的高维异常检测:一种高效且可解释的方法
本文将重点探讨一种替代传统单一检测器的方法:不是采用单一检测器分析数据集的所有特征,而是构建多个专注于特征子集(即*子空间*)的检测器系统。
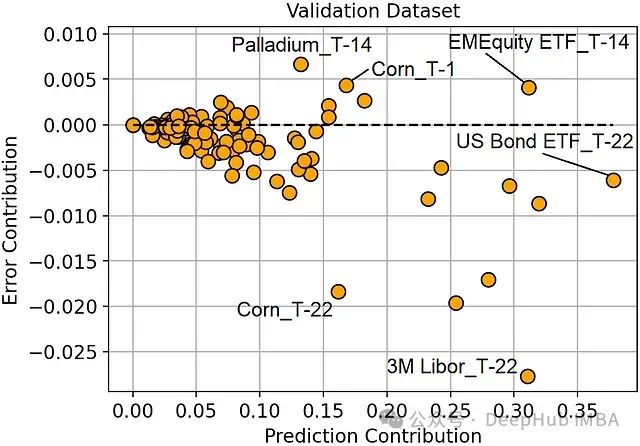
机器学习模型中特征贡献度分析:预测贡献与错误贡献
本文将探讨特征重要性与特征有效性之间的关系,并引入两个关键概念:预测贡献度和错误贡献度。
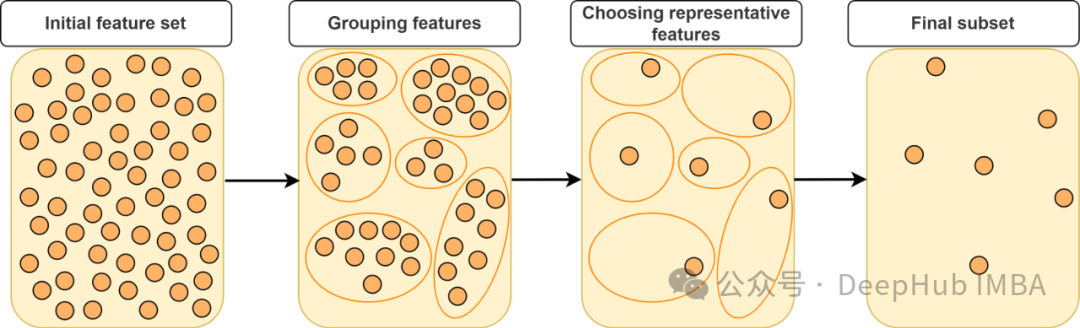
精简模型,提升效能:线性回归中的特征选择技巧
在本文中,我们将探讨各种特征选择方法和技术,用以在保持模型评分可接受的情况下减少特征数量。通过减少噪声和冗余信息,模型可以更快地处理,并减少复杂性。

通过强化学习策略进行特征选择
在本文中,我们将介绍并实现一种新的通过强化学习策略的特征选择。
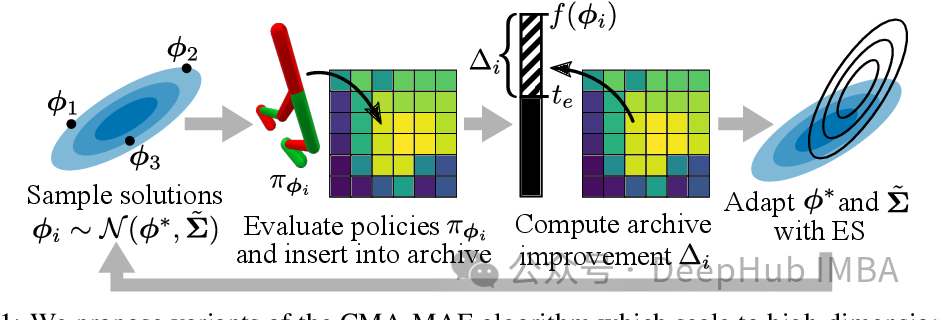
基于协方差矩阵自适应演化策略(CMA-ES)的高效特征选择
特征选择是指从原始特征集中选择一部分特征,以提高模型性能、减少计算开销或改善模型的解释性。
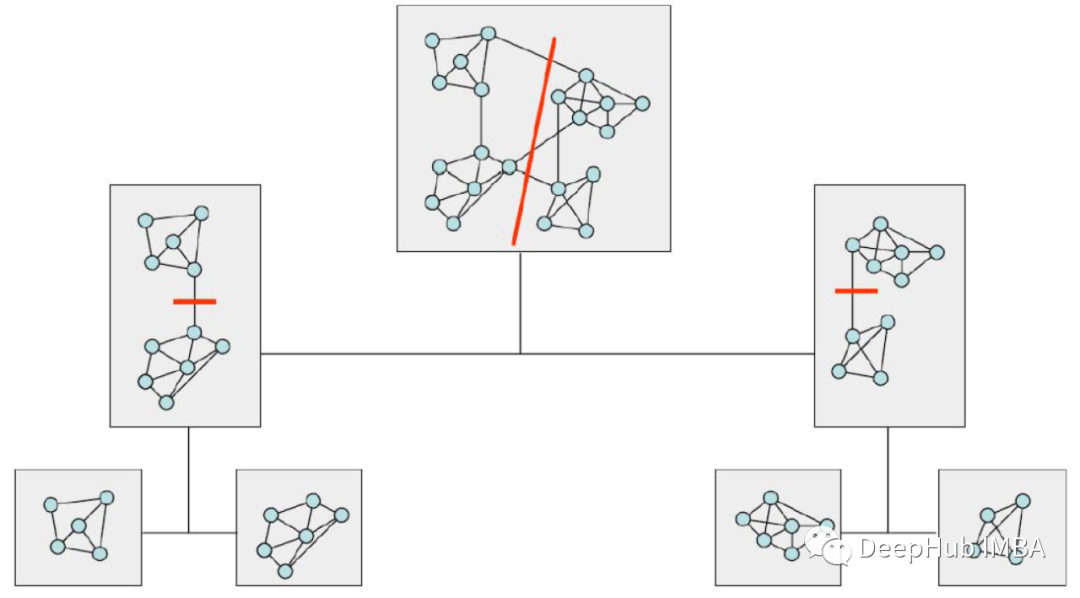
使用谱聚类(spectral clustering)进行特征选择
在本文中,我们将介绍一种从相关特征的高维数据中选择或提取特征的有用方法。
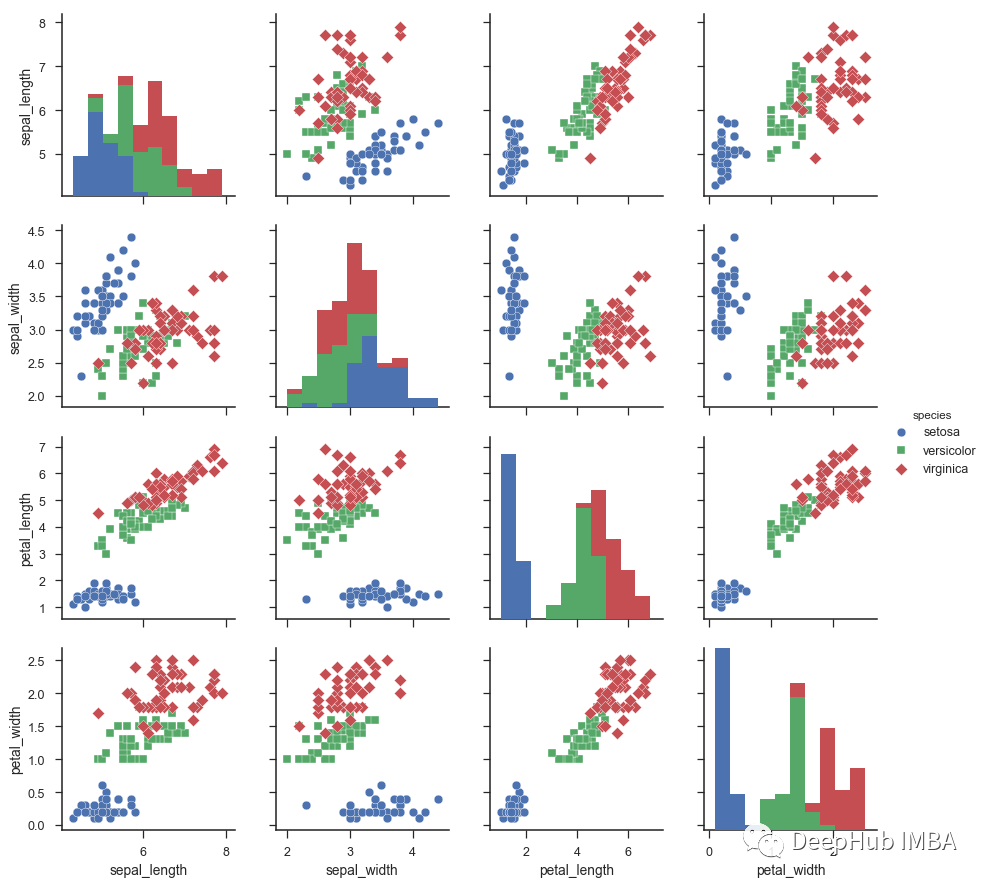
特征选择技术总结
在本文中,我们将回顾特性选择技术并回答为什么它很重要以及如何使用python实现它。
时间序列中的特征选择:在保持性能的同时加快预测速度
在这篇文章中,我们展示了特征选择在减少预测推理时间方面的有效性,同时避免了性能的显着下降。tspiral 是一个 Python 包,它提供了各种预测技术。并且它与 scikit-learn 可以完美的集成使用。
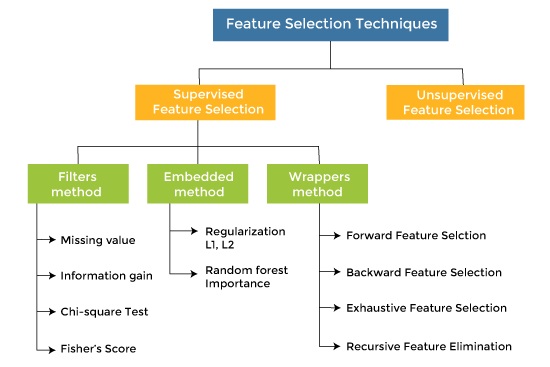
特征选择:11 种特征选择策略总结
“特征选择”意味着可以保留一些特征并放弃其他一些特征。本文的目的是概述一些特征选择策略



