
一.引言
上一文中讲到了如何构建 Pipeline - Estimator 训练模型以及通过 Pipeline - Transfomer 预测数据,本文基于用户豆瓣影评与评分构建二分类模型判断评论属于正向或者负向,属于基础的 NLP 二分类问题,构建该模型需要如下 Stage:
Stage1 - 数据清洗并构建 DataFrame
Stage2 - 分词工具对用户影评进行分词
Stage3 - HashingTF 将分词向量化供后续训练
Stage4 - LogisticRegression 实现二分类模型
Stage5 - 存储 Pipeline Model 并读取模型预测
后续将基于这 5 个 Stage 介绍。

**- 星际穿越剧照 **
二.Stage1 - 数据准备
1.数据样式
首先看下原始数据的样式:

数据共分为3列,分别为 Movie [影名]、Score [评分] 与 Comment [评论],由于本文的目标是用 LR 实现评论情感的二分类,所以我们需要人工指定一个 Label,0 代表负向评价,1 代表正向评价,基于一般认知,我们将 Score > 3 的影评认定为正向,即 Label 为 1,<= 3 则认为负向,Label = 0。
2.读取数据
使用 sc 将数据读取为 RDD 随后调用隐式转换切换为 DF,这里 positive 就是上面提到的,> 3 的 comment Label = 1.0,<= 3 的 Label 为 0.0。
val commentAndLabel = spark.sparkContext.textFile(inputPath).mapPartitions(partition => {
partition.map(line => {
try {
val info = line.split("##")
val movieName = info(0)
val score = info(1)
val positive = if (score != "null" && score.toInt > 3) 1.0 else 0.0
val oriComment = info(2)
(movieName, score, positive, oriComment)
} catch {
case _: Throwable =>
null
}
})
}).filter(_ != null)
val data = spark.createDataFrame(commentAndLabel)
.toDF("movie", "score", "label", "comment")
3.平均得分与 Top 5
基于上述数据 DataFrame,我们先用前面的 Spark Sql 语句统计下每个 Movie 的平均分并查看当前的 Top 5 电影。
// 平均分 Map
data.createOrReplaceTempView("MovieComment")
val avgScore = spark.sql("select movie, avg(score) from MovieComment group by movie")
.collect()
.map(row => (row.getString(0), row.getDouble(1)))
.toMap
println(s"Total Movie Num: ${avgScore.size}")
avgScore.toArray.sortBy(-_._2).slice(0, 5).zipWithIndex.foreach{ case (movieInfo, index) => {
println(s"Top${index + 1} - <<${movieInfo._1}>> Avg: ${avgScore.apply(movieInfo._1)}")
}}
共有 255 部电影,其中排名最高的是陈导的霸王别姬,平均分达到了 4.74 🌟🌟🌟🌟🌟

4.训练集、测试集划分
对数据有整体了解后,我们首先划分训练集与数据集,前面提到过 randomSplit 函数可以配合比例轻松实现划分,这里采用雪碧的比例。
// 划分训练集、测试集
val trainAndTestRatio = Array(0.8, 0.2)
val pipelineData = data.randomSplit(trainAndTestRatio, 99)
val trainData = pipelineData(0)
val testData = pipelineData(1)
// 相关统计
println(s"AllSamples: ${commentAndLabel.count()} TrainSample: ${trainData.count} TestSamples: ${testData.count()}")
可以看到 255 部电影共包含 50590 条 comment 数据,其中训练样本 4w+,测试样本 1w+。基本的 Dataframe 已经搞定,下面我们整理 Transformer 与 Estimator 并构建 Pipeline。
AllSamples: 50590 TrainSample: 40373 TestSamples: 10217
三.Stage-2 - Comment 分词
1.Tokenizer 🙅🏻♀️
先拿上篇文章使用的 Tokenizer 试试水:
val tokenizer = new Tokenizer()
.setInputCol("comment")
.setOutputCol("output")
tokenizer.transform(trainData).select("movie", "comment", "output").show(10)
完了,BBQ 了呀,Tokenizer 只能分割空格隔开的语句,当前场景下无明显空格分隔符,所以都是一整句当做一个词,因此放弃该方案。

2.JieBa 分词 🙆🏻♀️
Java 有很多分词工具,这里选择之前 python 也用到过的 JieBa,还有 ikanalyzer、Ansj 等等,大家也可以多多尝试。
<!-- 开源中文分词器 Jieba -->
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>
<!-- 开源中文分词器 Ansj -->
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>
<!-- 开源中文分词器 IK -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
2.1 Jieba 分词示例
val jiebaTokenizer = new JiebaTokenizer()
.setInputCol("comment")
.setOutputCol("output")
jiebaTokenizer.transform(trainData).select("movie", "comment", "output").show(10)
这里 JiebaTokenizer 为我们自定义的分词器,内部调用 Jieba 实现分词处理并过滤 StopWords,这下看下来比上面好多了,但是有一些人名或者物品识别也不是太好,这与分词器的内部中文词库大小相关联,这里我们先凑乎用一下。

2.2 自定义 Jieba 分词 Transformer
val jieba = new JiebaSegmenter()
jieba.sentenceProcess(text)
初始化分词器并调用 setenceProcess 方法即可实现分词效果,但是官方未提供原生 jiebaTokenizer,所以只能将分词步骤提前到数据准备阶段的 RDD MapPartition 中才能达到分词的效果:

这样虽然简单,但是违背了 Pipeline 的初衷,我们不得不把第一步 Tokenizer 分词的 Stage 从 Pipeline 中提出,为了 Pipeline 的统一性,我们继承 org.apache.spark.ml.UnaryTransformer 自定义实现 JiebaTokenizer Transformer:
import com.huaban.analysis.jieba.JiebaSegmenter
import org.apache.spark.annotation.Since
import org.apache.spark.ml.UnaryTransformer
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.param.Param
import org.apache.spark.ml.util.{DefaultParamsReadable, DefaultParamsWritable, Identifiable, MLReader, MLWriter}
import org.apache.spark.sql.types._
class JiebaTokenizer(override val uid: String)
extends UnaryTransformer[String, Array[String], JiebaTokenizer] with DefaultParamsWritable with java.io.Serializable {
lazy val jieba = new JiebaSegmenter()
def this() = this(Identifiable.randomUID("JiebaTokenizer"))
val inputPath = "./stopwords.txt"
val stopWords = scala.io.Source.fromFile(inputPath)
.getLines().toSet
override protected def outputDataType: DataType = new ArrayType(StringType, true)
override protected def validateInputType(inputType: DataType): Unit = {
require(inputType == DataTypes.StringType,
s"Input type must be string type but got $inputType."
)
}
override protected def createTransformFunc: String => Array[String] = {
parseContent
}
/**
* Jieba 分词
*/
private def parseContent(text: String): Array[String] = {
if (text == null || text.isEmpty) {
return Array.empty[String]
}
jieba.sentenceProcess(text).toArray().map(_.toString).filter(str => !stopWords.contains(str))
}
}
object JiebaTokenizer extends DefaultParamsReadable[JiebaTokenizer] {
override def load(path: String): JiebaTokenizer = {
super.load(path)
}
}
关于如何在 Spark ML 中继承 UnaryTransformer 实现自定义 Transformer 博主会在下一篇文章详细讲解一下每个函数的使用方法与解释,有需要的同学可以关注下~
四.Stage-3 HashingTF 向量化
HashingTF 负责将原始分词文本进行词频统计并 Hash 得到数组索引,这里读取前面 Jieba 分词生成的 output Col 并将新的结果输出至 vector Col,需要注意 numFeatures 的设置,实际场景下应该基于自己分词后去重的分词词库大小来决定该参数,这里由于我们评论五花八门,所以不考虑去重词库大小,直接设置为 20w。
val hashingTF = new HashingTF()
.setInputCol("output")
.setOutputCol("vector")
.setNumFeatures(200000)
hashingTF.transform(jiebaTokenizer.transform(trainData)).select("movie", "comment", "vector").show(10)
通过两步 Transformer,向量化数据终于搞定,下面搭配 Estimator - LR 即可构成完整 Pipeline。

五.Stage-4 通过 LR 构建 Pipeline
LR 前两篇文章都有过讲解,这里不再赘述,直接生成 Pipeline:
val lr = new LogisticRegression()
val pipeline = new Pipeline()
.setStages(Array(jiebaTokenizer, hashingTF, lr))
val paramMap = ParamMap(lr.maxIter -> 20, lr.regParam -> 0.01)
.put(jiebaTokenizer.inputCol -> "comment", jiebaTokenizer.outputCol -> "words")
.put(hashingTF.numFeatures -> 200000, hashingTF.inputCol -> "words", hashingTF.outputCol -> "features")
// 调用fit()函数,训练数据
val model = pipeline.fit(trainData, paramMap)
paramMap 中分别为 JiebaTokenizer、HashingTF 与 LR 配置相关参数,原始 comment 将先转化为 words 列,随后转化为 features 列,配合最先生成的情感 Label 供 LR 训练模型。
六.Stage-5 模型存储与复用
经过一系列操作,我们的 Pipeline Model 终于构建完毕,下面将训练好的模型存储,并在需要使用的时候 load 加载完成预测。
1.模型存储与加载
println(s"Start Save Model: ${System.currentTimeMillis()}")
val output = "./output"
model.write.overwrite().save(output)
val newModel = PipelineModel.load(output)
println(s"End Save Model: ${System.currentTimeMillis()}")
采用 model.write 实现模型存储,如果需要覆盖之前的模型可以增加 overwrite 选项,读取模型则是通过 org.apache.spark.ml.PipelineModel 类实现。
2.预测评论情感
上面留了 20% 的数据作为测试集,下面测试下我们的情感模型效果如何:
// 在测试集上进行预测
newModel.transform(testData.sample(0.1, 99))
.select("movie", "comment", "score", "probability", "prediction")
.collect()
.foreach { case Row(movie: String, comment: String, score: String, prob: Vector, prediction: Double) =>
println(s"($movie, $comment) --> real=$score avg=${avgScore(movie)} prob=$prob, prediction=$prediction")
}
分别打印电影名与原始评论作为文本信息,打印真实分数与平均分数作为当前电影的真实评价,最终打印预测概率,0 为负向评论代表用户不喜欢该电影,1 为正向评论代表用户喜欢该电影,理想情况下,预测概率应该与用户的原始评价分有关 🌟🌟🌟🌟🌟,因为给的星越高,代表评价越高,评论里的描述也越正向,反之同理。
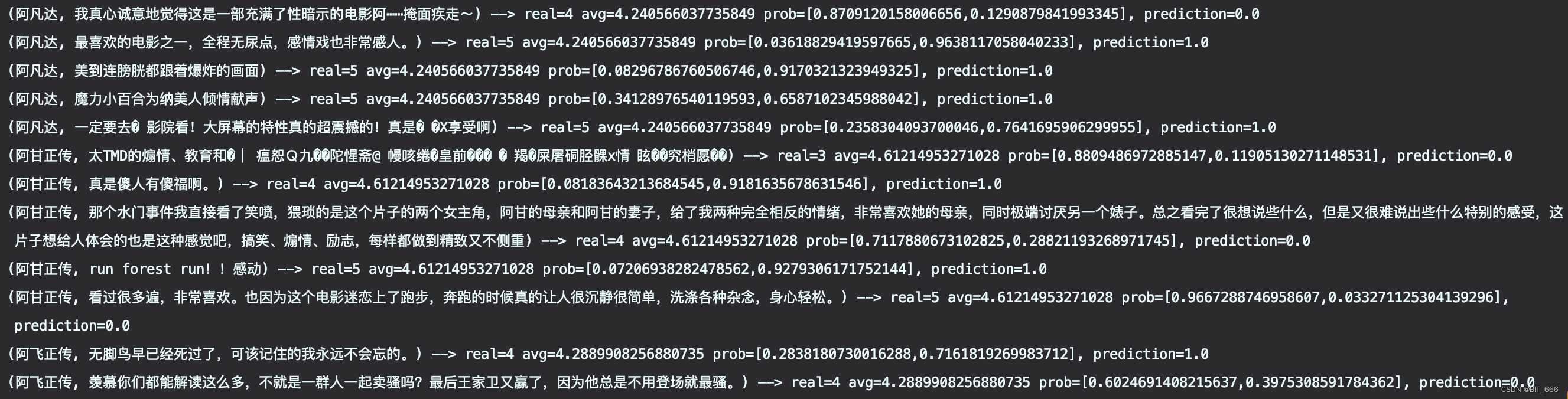
这里简单挑几个样本看看模型效果如何:
✅ A.为什么又是“一个崽的神奇冒险”,那么点儿耍帅镜头想糊弄谁呢?
real=3,avg=2.17,加上略带消极的评论,预测为 0 基本正确
❎ B.还不错,真实事件
real=3,avg=1.56,单看分数应该是烂片无疑了,但是由于评论正向,所以预测为 1,虽然与label不符合,但是感觉也可以算正确
✅ C.无聊透顶,近乎儿戏,仍旧是个人目前为止最讨厌的一部漫威
负向评论无疑,real=2,预测为 0,预测正确
❎ D.难得看到漫威拍严肃题材,一个时刻生活在谎言中的封闭国家,一个遭受外来文化冲击的封建体制,在超英片中已经是很有追求了
中肯中带有一些正向,real 也达到了 4 分,但是正向的概率却只有 0.04,这里失真比较严重
七.总结
上面通过 Spark ML Pipeline 构建了简单的 NLP 情感分类模型,可以看到评论场景下,一些评论与实际打分存在差异,可能用户不喜欢却依旧打了高分,或者存在粉丝刷榜随意打高分的情况,这些在真实场景下都会对模型带来噪声,影响模型的学习。除此之外,这里除了通过简单的二分类实现情感分析,还可以使用多分类模型预测电影评星 [1-5] 或者使用线性、多项式回归预测电影得分,这涉及到多分类和回归的知识,后面有机会我们也会介绍。

It takes a strong man to save himself, and a great man to save another.
最后留下自己最喜欢的🎬 <<肖申克的救赎>> ,大家有最喜欢的电影也可以留在评论区,一起分享 (^▽^)
版权归原作者 BIT_666 所有, 如有侵权,请联系我们删除。