
本文为作为类ChatGPT的模型ChatGLM的前期基础论文2《AN OPEN BILINGUAL PRE-TRAINED MODEL》的精读笔记,基础论文1的精读笔记请见《GLM论文精读-自回归填空的通用语言模型》。希望对大家有帮助,欢迎讨论交流。GLM-130B,主要思想概述:一个双语(英文和中文)的基于GLM的双向稠密模型。并没有使用GPT风格的架构,而是采用通用语言模型(GLM)算法(Du et al.,2022)来利用其双向注意力优势和自回归空白填充目标,模型参数为1300亿,语料约训练了4000亿个文本标记,在语义理解和文本生成任务上性能强大。
论文地址: https://arxiv.org/abs/2210.02414
论文代码: GitHub - THUDM/GLM-130B: GLM-130B: An Open Bilingual Pre-Trained Model (ICLR 2023)
官方博客: GLM-130B:开源的双语预训练模型 | GLM-130B
学习完后的最大感受是这是一个非常扎实的工作,论文的附录里把相关架构的选择思考、数据的构成乃至训练的log和主要失败的实验都记录公开了,不愧是T大!
论文架构概述
论文的主要贡献包括:- 1)架构选择- 通用语言模型GLM- 组件改进:旋转位置编码、DeepNorm、GeGLU- 2)工程实现- 并行策略:数据、张量、流水线3D并行- 多平台高效适配- 3)训练策略改进- 梯度爆炸的问题,采用了嵌入层梯度缩减策略- 解决注意力数值溢出问题,采用了FP32的softmax计算策略,训练稳定性有提升
- GLM-130B的代码: 目前只开源了evaluate部分代码和checkpoint,并没有直接开源train的代码,基于研究目的可以申请获得。
架构
训练目标- 自监督的自回归文本填空(95%tokens)。GLM利用自回归文本填空作为其主要的预训练目标。它掩盖了随机的连续跨度(例如,下面的例子中的 "complete unknown"),并对其进行自回归预测。上下文之间的注意力(例如,"like a [MASK], like a rolling stone")是双向的。相反,被掩盖的标记之间的注意力,和从上下文到被掩盖的标识符的注意力是自回归掩码的。
 - (注: glm的注意力双向和单向的介绍,刘潇的视频大概在14min左右)- - 在GLM-130B的实现中,有两种不同的MASK标识符,表示两个不同的目的(To support both understanding and generation, it mixes two corruption objectives, each indicated by a special mask token):- [MASK]根据泊松分布 (λ=3)对输入中标识符进行短跨度的采样,主要服务对文本的理解能力目标;([MASK]: short blanks in sentences whose lengths add up to a certain portion of the input.)- [gMASK]掩盖一个长的跨度,从其位置到整个文本的结束,主要服务对文本的生成目标能力目标。 ([gMASK]: random-length long blanks at the end of sentences with prefix contexts provided) - 多任务学习预训练(5%tokens)。T5(Raffel et al.,2020)和ExT5(Aribandi et al.,2022)表明,预训练中的多任务学习比微调更有帮助,因此论文建议在GLM-130B的预训练中包括各种指令提示数据集,包括语言理解、生成和信息抽取。
- (注: glm的注意力双向和单向的介绍,刘潇的视频大概在14min左右)- - 在GLM-130B的实现中,有两种不同的MASK标识符,表示两个不同的目的(To support both understanding and generation, it mixes two corruption objectives, each indicated by a special mask token):- [MASK]根据泊松分布 (λ=3)对输入中标识符进行短跨度的采样,主要服务对文本的理解能力目标;([MASK]: short blanks in sentences whose lengths add up to a certain portion of the input.)- [gMASK]掩盖一个长的跨度,从其位置到整个文本的结束,主要服务对文本的生成目标能力目标。 ([gMASK]: random-length long blanks at the end of sentences with prefix contexts provided) - 多任务学习预训练(5%tokens)。T5(Raffel et al.,2020)和ExT5(Aribandi et al.,2022)表明,预训练中的多任务学习比微调更有帮助,因此论文建议在GLM-130B的预训练中包括各种指令提示数据集,包括语言理解、生成和信息抽取。
从概念上讲,与GPT风格的模型相比,具有双向注意力的填空目标能够更有效地理解上下文:当使用[MASK]时,GLM-130B表现为BERT(Devlin et al.,2019)和T5(Raffel et al.,2020);当使用[gMASK]时,GLM-130B的行为与PrefixLM类似(Liu等人,2018;Dong等人,2019)。
位置编码- GLM-130B使用旋转位置编码(RoPE)。谷歌的PaLM和ElutherAI的GPT-系列也采用这种编码。RoPE是一种相对位置编码,它利用复数空间的正交投影矩阵来表示标识符的相对距离。还有其他的相对位置编码选项,如Bigscience的BLOOM所使用的AliBi。但在我们的初步实验中,*我们发现RoPE编码优势:1)当序列长度增长时,RoPE的实现速度更快。2)RoPE对双向注意力更友好,在下游微调实验中效果更好- 位置编码通常的划分:- 1)相对位置编码: Transformer-XL论文里提出attention中建模单词两两之间的相对距离。相对位置编码2021年来得到较多发展,ALiBI 和RoPE。其中ALiBi是给Attention加上bias矩阵(不同注意力头系数不同) 。RoPE旋转式编码,是一种相对位置编码,但是其是以绝对编码的形式实现相对编码。EleutherAI 、Google PalM 530B采用,实验表明RoPE 对GLM更有效且更容易实现双向相对注意力。- 2)绝对位置编码: 最早的transformer的三角函数式编码,Bert、GPT中提出的可学习式编码。
DeepNorm 归一化,使用DeepNet的Post-LN。
- 原始的BERT论文采用的是Post-LN 结构。 但20年左右有论文证明Post-LN 结构容易发散,21年近年来文本生成的大模型普遍采用Pre-LN结构。 数百亿/多模态混合精读训练(FP16)中,Pre-LN也不稳定,实验发现Pre-的变体Sandwich-LN结构可以缓解这一现象
- Pre-LN虽然容易训练,但性能不如稳定训练后的Post-Ln .
- 202203提出的DeepNet,调整残差,更改初始化,能更加稳定的训练千层。千亿模型上,DeepNorm比Sandwich-LN 更稳定。
- 在GLM-130B中,我们决定使用Post-LN,并使用新提出的DeepNorm来克服不稳定性。DeepNorm的重点是改进初始化,可以帮助Post-LN变换器扩展到1000层以上。在我们的初步实验中,模型扩展到130B,Sandwich-LN的梯度在大约2.5k步时就会出现损失突变(导致损失发散),而带有DeepNorm的Post-Ln则保持健康并呈现出较小的梯度大小(即更稳定)。*即稳定训练1000层Post-LN 的方法, DeepNorm(x) = LayerNorm(@x +g(x)) , @>1
FFN改成GLU
- GLM-130B中改进transformer结构中的前馈网络(FFN),用GLU(在PaLM中采用)取代它,实验效果表明选择带有GeLU激活的GLU训练更稳定.(对比了另一个新提出的门控单元GAU)
- GeGLU需要三个投影矩阵;为了保持相同数量的参数,与只利用两个矩阵的FFN相比,我们将其隐藏状态减少到2/3。
训练
训练的难题
- 效率和稳定性两大权衡。据其观察,大模型比我们认为的那些小模型更容易受到不可避免的噪音数据和意外涌现的梯度影响。原因是,在训练效率和稳定性之间存在着权衡,其中效率:我们需要一个低精度的浮点格式(如FP16),以减少内存和计算成本;稳定性:低精度浮点格式容易出现溢出和下溢。
浮点数格式:FP16混合精度
- FP16 用于前向和后向,FP32 用于优化器状态和主权重(Mixed-Precision. We follow the common practice of a mixedprecision (Micikevicius et al., 2018) strategy (Apex O2), i.e., FP16 for forwards and backwards and FP32 for optimizer states and master weights). 选择FP16作为其训练浮点格式。FP16混合精度已经成为主流大规模模型训练框架的默认选项,用于训练十亿到百亿规模的模型,但其存在容易遇到精度问题。为了让更多开发者使用,GLM-130B仍然选择FP16作为其训练浮点格式(此话表明只是训练浮点格式为FP16,其他的非浮点格式并不一定是FP16,如在softmax计算时使用的是FP32)。
嵌入层:梯度缩减
- 现象:在训练的早期阶段,嵌入层的梯度范数明显比其他层大。根据经验,我们发现大多数训练崩溃都发生在其梯度范数激增之后。已有解决方案:BLOOM汇报了使用嵌入归一化(我们也发现它能稳定训练),但同时,其牺牲了相对较大的下游性能。
- GLM-130B的解决方案:由于根本问题是输入嵌入层的急剧梯度,我们建议缩小输入嵌入层的梯度。实现起来相当简单。word_embedding = word_embedding * α + word_embedding.detach() * (1 - α) , 这就把梯度缩小到α。在我们的实践中,我们发现α=0.1对GLM-130B是最好的。
- 效果:初步实验中,我们观察到,对于早期阶段的训练来说,缩小嵌入梯度并没有减缓收敛速度;相反,没有缩小梯度的模型会出现意外的尖峰,并在5k步左右出现训练崩溃的情况。
- 梯度收缩是一种避免训练崩溃的事后技术。从本质上讲,崩溃是由异常的损失 "梯度"形成的,要么是由于噪声数据,要么是正向计算中的精度上溢或者下溢。
训练稳定性提升与注意力计算选择FP32 softmax
- 背景:观察到,在大型语言模型中,注意力的计算操作是最容易上溢或下溢的。CogView显示,不同的注意力头对其注意力分数有非常不同的数值范围,有些注意力头计算出的平均分数可以达到+1e4或-1e-3。这种不同的数值范围会导致在softmax计算中FP16下的频繁上溢或下溢。CogView提出了精度瓶颈放松(PB-Relax)来缓解这个问题,它在做softmax之前扣除了每个头的注意力得分矩阵中的最大绝对值。
 - 混合精度训练,以模型参数fp16进行存储的。具体的细节见22年9月14的视频48min左右开始讲。
- 混合精度训练,以模型参数fp16进行存储的。具体的细节见22年9月14的视频48min左右开始讲。- 训练中不稳定解决- Attention score层: softmax in 32 可以避免上下溢出- 调小embedding层梯度,缓解前期梯度爆炸问题
- 在softmax中使用FP32。事实证明,PB-Relax在GLM-130B的训练中很慢,可能是因为在96个大小为2048*2048的注意分数矩阵中寻找最大值和操作标量对CUDA内核不友好。最后,经过几周的艰苦探索,我们发现避免这一问题的最快和最简单的方法是在softmax计算中使用FP32。与完全的FP16计算相比,它几乎没有任何速度上的损失,但明显提高了训练的稳定性。
训练数据集
1)自监督空白填充(95%token)
- 共计2.5T的中英混合语料。1.3T中文语料。包括Wudao语料和从网络上爬取的250G中文语料(包括在线论坛、百科和问答)。1.2T Pile英文语料。GLM-130B在此任务中同时使用[MASK]和[gMASK]。- 字符级别27%,训练填空能力[MASK],短文本- 每个片段的长度从均值为3的泊松分布中采样,总片段长度为原始序列长度的15%- 单个字符级任务的最大序列长度为512,,4个任务拼接到一起,构成2048- 文档级别66%,训练生成能力[gMask],长文本- 一个文本序列中只有一个片段,片段长度为原始序列长度的50%~100%- 最大序列长度为2048
2)多任务指令预训练(5%token)
- 5%的训练标记来自多任务指令预训练MIP(Multi-Task Instruction Pre-Training,MIP)数据集。一个只含有一个片段的文本序列,片段为下游任务数据的原始预测目标
训练成本估算
- GLM-130B的预训练持续了60天,使用96个DGX-A100(40G)节点,等价花费490万美元的云服务费用(实际应该比这个低)
超参数配置

其中该词表和分词器是基于icetk实现的。icetk是一个统一的图像、中文和英文的多模态标记器。
工程实现与优化
并行策略:高效训练千亿模型

- 采用Zero优化器在数据并行组内分摊优化器状态
- 模型并行:将模型参数分布到多个GPU上,里面包括1)张量并行(切分参数矩阵,每个GPU计算一部分,增加一部分额外通行,降低计算粒度) 2)流水线并行,将网路分成多段并行,引入流水线气泡。 3) ZeRO-3: 将参数分布到数据并行组中,算之前先取回参数,增加了额外通信时间.。 整体并行策略: 张量并行随着模型规模增大缓慢扩展,但不超过单机规模,其余全部使用流水线并行,通过调整微批处理大小减少气泡占比
其他优化-算子融合
- 融合多个element-wise算子,提升10%左右的计算速度
其他优化-流水线平衡
- 流水线首尾阶段各少放置一个层平衡占用,节省10%左右的内存
跨平台兼容,swDeepSpeed训练库
- 支持神威架构,一行代码 无缝替换兼容
- 实现并行通信策略,混合精度策略,ZeRO优化器
- 同一套训练框架可在三个训练集群上对齐训练曲线
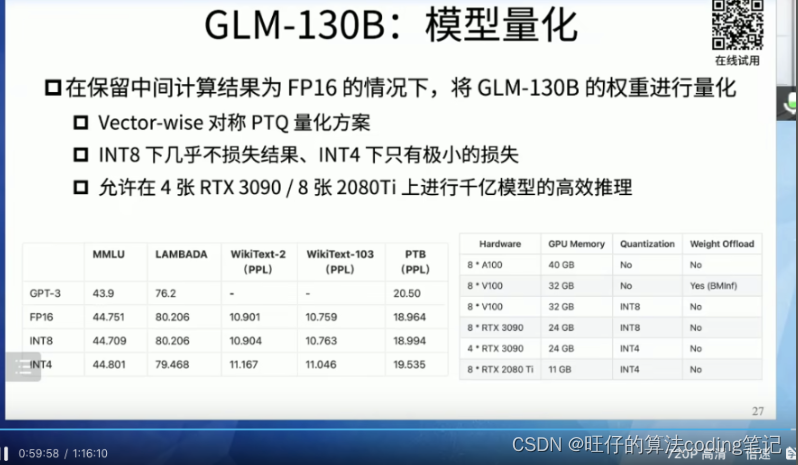
GLM模型量化
- 将GLM-130B的权重进行量化-

- 支持INT4的量化精度
效果-优势
双语,同时支持中文和英文
高精度(英文) ,在LAMBADA数据集上由于GPT-3 175B
高精度(中文),在7个零样本的CLUE数据集上明显优于ERNIE
高效推理,可以基于FasterTransformer进行快速推理(相比Metatron提速最高可达2.5倍)
低门槛推理:最低量化INT4
跨平台,支持在navidia、海光DCU、昇腾910和神威处理器上的训练
零样本学习,中文语言理解基准CLUE ,acc的效果不错
零样本学习,大规模多任务语言理解MMLU 数据集上的,包括57个关于人类知识的多选题,效果不错
参考与致谢:
本笔记主要是参考如下文献整理而成,向前辈大佬们致敬!
GLM-130B/README_zh.md at main · THUDM/GLM-130B · GitHub
GLM-130B:开源的双语预训练模型 | GLM-130B
GLM-130B:开源的双语千亿预训练模型——可在4张3090或8张1080Ti上使用的千亿模型_哔哩哔哩_bilibili
论文阅读-GLM-130B:一种开放的双语预训练模型(2023) - 知乎
版权归原作者 旺仔的算法coding笔记 所有, 如有侵权,请联系我们删除。