
超越YOLOv7、v8! YOLOv6 v3.0正式发布!!!
YOLOv6 全新版本v3.0正式发布!
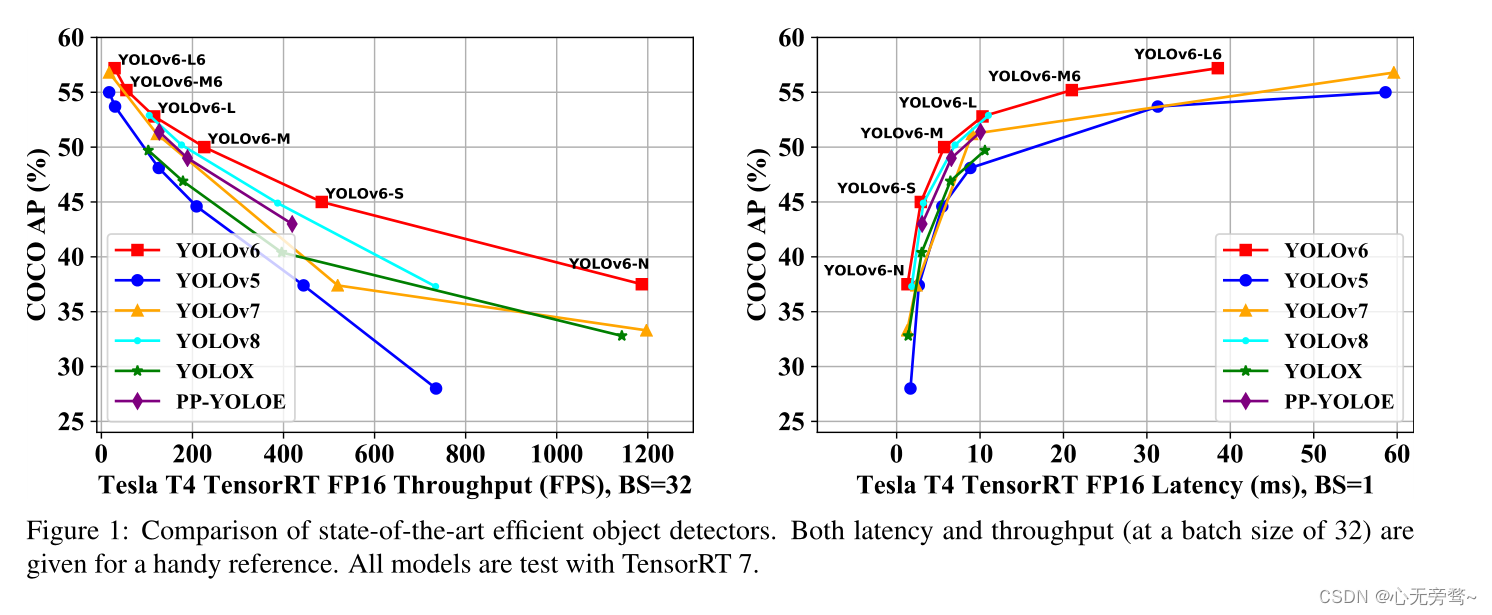
引入新的网络架构和训练方案,其中YOLOv6-S以484 FPS的速度达到45.0% AP,超过YOLOv5-S、YOLOv8-S,其代码刚刚开源
由于前段时间Ultralytics公司透露出V8的发布消息,美团也坐不住了,YOLO社区一直情绪高涨!
随着中国农历新年2023(兔年)的到来,美团技术团队对YOLOv6进行了许多新的网络架构和训练方案的改进。此版本标识为YOLOv6 v3.0。
论文代码都已经开源!!!
GitHub地址:https://github.com/meituan/YOLOv6
论文地址:https://arxiv.org/abs/2301.05586
**论文 **

摘要:
自我们的前两个版本以来,YOLO社区一直处于高涨的情绪中 在2023年兔年到来之际,我们对YOLOv6的网络架构和训练方案进行了许多新的改进。这个版本被确定为YOLOv6 v3.0。对于性能的一瞥,我们的YOLOv6N在COCO数据集上达到了37.5%的AP,用NVIDIA Tesla T4 GPU测试的吞吐量为1187 FPS。YOLOv6S在484 FPS的情况下达到了45.0%的AP,超过了其他相同规模的主流检测器(YOLOv5-S、YOLOv8S、YOLOX-S和PPYOLOE-S)。而YOLOv6-M/L在相似的推理速度下,也比其他检测器取得了更好的准确性表现(分别为50.0%/52.8%)。此外,通过扩展骨干和颈部设计,我们的YOLOv6-L6实现了最先进的实时准确性。我们仔细进行了广泛的实验,以验证每个改进组件的有效性。我们的代码可在https://github.com/meituan/YOLOv6提供。
网络结构改进
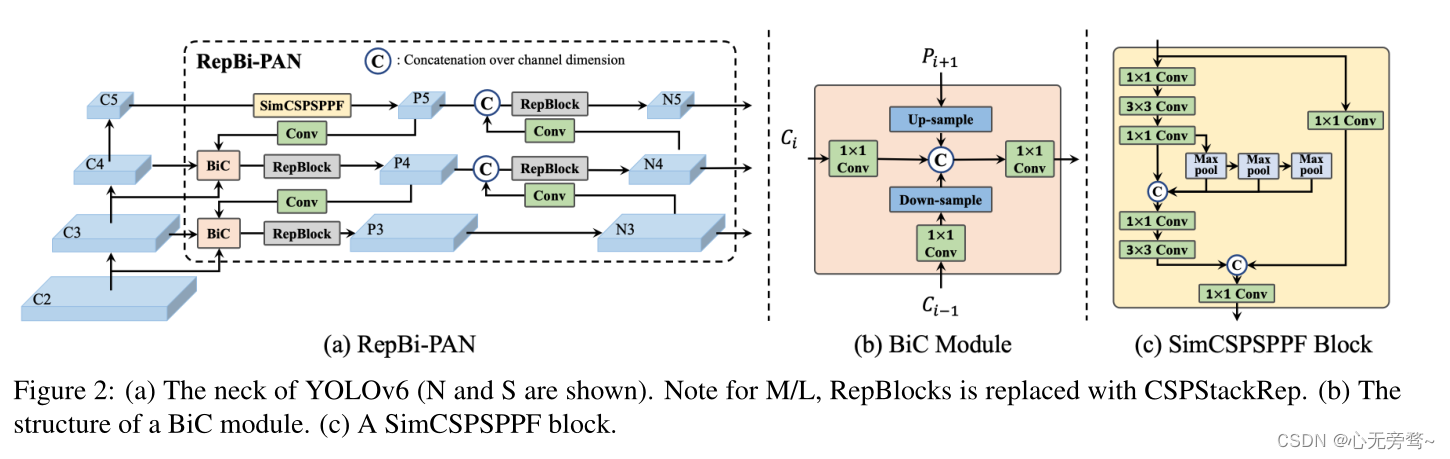
YOLOv6的颈部(图中是N和S)。注意M/L,RepBlocks被替换为CSPStackRep。 (b) 一个BiC模块的结构。(c) 一个SimCSPSPPF块。
具体更新如下:
- 检测器的颈部更新了一个双向的串联(BiC)模块,以提供更准确的定位信号。SPPF[5]被简化成SimCSPSPPF块,它带来了性能上的提升,而速度上的下降可以忽略不计。
- 提出了一种锚辅助训练(AA T)策略,在不触及推理效率的前提下,享受基于锚和无锚范式的优势。
- 深化了YOLOv6,使其在骨干和颈部有了另一个阶段,这加强了它在高分辨率输入的COCO数据集上达到了新的最先进的性能。
- 涉及到一种新的自我蒸馏策略,以提高YOLOv6小模型的性能,其中DFL[8]的较重分支在训练期间被作为增强的辅助回归分支,并在推理时被移除,以避免速度明显下降。
具体的更新思路可以查看论文。
新旧模型对比
v3.0版本
模型输入尺寸mAPval
0.5:0.95速度T4
trt fp16 b1
(fps)速度T4
trt fp16 b32
(fps)Params
(M)FLOPs
(G)YOLOv6-N64037.577911874.711.4YOLOv6-S64045.033948418.545.3YOLOv6-M64050.017522634.985.8YOLOv6-L64052.89811659.6150.7YOLOv6-N6128044.922828110.449.8YOLOv6-S6128050.39810841.4198.0YOLOv6-M6128055.2475579.6379.5YOLOv6-L6128057.22629140.4673.4
- 除了 YOLOv6-N6/S6 模型是训练了300轮的结果,其余模型均为自蒸馏训练之后的结果;
- mAP 和速度指标是在 COCO val2017 数据集上评估的,P5模型输入分辨率为 640×640,P6模型输入分辨率为 1280×1280;
- 速度是在 T4 上测试的,TensorRT 版本为 7.2;
- 复现 YOLOv6 的速度指标,请查看 速度测试 教程;
- YOLOv6 的参数和计算量是在推理模式下计算的;
旧版模型
模型输入尺寸mAPval
0.5:0.95速度T4
trt fp16 b1
(fps)速度T4
trt fp16 b32
(fps)Params
(M)FLOPs
(G)YOLOv6-N64035.9300e
36.3400e80212344.311.1YOLOv6-T64040.3300e
41.1400e44965915.036.7YOLOv6-S64043.5300e
43.8400e35849517.244.2YOLOv6-M64049.517923334.382.2YOLOv6-L-ReLU64051.711314958.5144.0YOLOv6-L64052.59812158.5144.0
- 速度是在 T4 上测试的,TensorRT 版本为 7.2;
** 量化模型**
模型输入尺寸精度mAPval
0.5:0.95速度T4
trt b1
(fps)速度T4
trt b32
(fps)YOLOv6-N RepOpt640INT834.811141828YOLOv6-N640FP1635.98021234YOLOv6-T RepOpt640INT839.87411167YOLOv6-T640FP1640.3449659YOLOv6-S RepOpt640INT843.3619924YOLOv6-S640FP1643.5377541
- 速度是在 T4 上测试的,TensorRT 版本为 8.4;
- 精度是在训练 300 epoch 的模型上测试的;
快速开始
安装
git clone https://github.com/meituan/YOLOv6
cd YOLOv6
pip install -r requirements.txt
在coco数据集上复现请参考教程 训练 COCO 数据集.
在自定义数据集上微调模型
单卡
# P5 models
python tools/train.py --batch 32 --conf configs/yolov6s_finetune.py --data data/dataset.yaml --fuse_ab --device 0
# P6 models
python tools/train.py --batch 32 --conf configs/yolov6s6_finetune.py --data data/dataset.yaml --img 1280 --device 0
多卡(推荐使用DDP模式)
# P5 models
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py --batch 256 --conf configs/yolov6s_finetune.py --data data/dataset.yaml --fuse_ab --device 0,1,2,3,4,5,6,7
# P6 models
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py --batch 128 --conf configs/yolov6s6_finetune.py --data data/dataset.yaml --img 1280 --device 0,1,2,3,4,5,6,7
- fuse_ab: 增加anchor-based预测分支并使用联合锚点训练模式 (P6模型暂不支持此功能)
- conf: 配置文件路径,里面包含网络结构、优化器配置、超参数信息。如果您是在自己的数据集训练,我们推荐您使用yolov6n/s/m/l_finetune.py配置文件;
- data: 数据集配置文件,以 COCO 数据集为例,您可以在 COCO 下载数据, 在这里下载 YOLO 格式标签;
- 确保您的数据集按照下面这种格式来组织;
├── coco
│ ├── annotations
│ │ ├── instances_train2017.json
│ │ └── instances_val2017.json
│ ├── images
│ │ ├── train2017
│ │ └── val2017
│ ├── labels
│ │ ├── train2017
│ │ ├── val2017
其它详情请看:** GitHub地址:**https://github.com/meituan/YOLOv6
最后附一篇详细的介绍文章:超越YOLOv8!| YOLOv6 v3.0正式来袭!
版权归原作者 心无旁骛~ 所有, 如有侵权,请联系我们删除。