
MiniGPT-4:
github库
https://github.com/Vision-CAIR/MiniGPT-4
在线测试网址
案例一:分析图片内容
出结果较慢,建议图片小一点,并且提示文字尽可能简短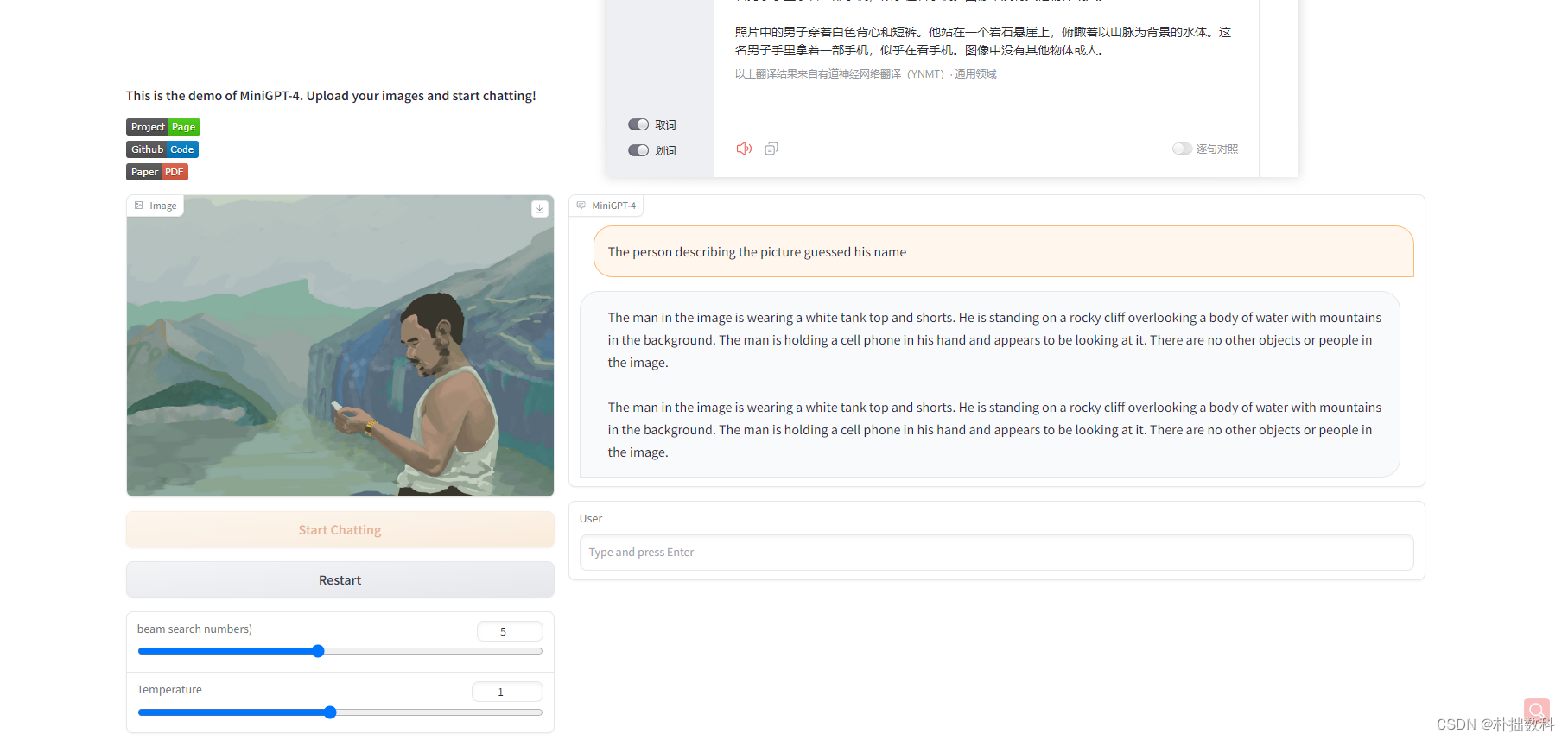
The man in the image is wearing a white tank top and shorts. He is standing on a rocky cliff overlooking a body of water with mountains in the background. The man is holding a cell phone in his hand and appears to be looking at it. There are no other objects or people in the image.
照片中的男子穿着白色背心和短裤。他站在一个岩石悬崖上,俯瞰着以山脉为背景的水体。这名男子手里拿着一部手机,似乎在看手机。图像中没有其他物体或人。
正方体上的字母是什么字母是什么颜色在什么位置上?
What are the letters on the cube what are the colors and where are the letters?


原理
最近的GPT-4展示了非凡的多模式能力,例如直接从手写文本生成网站和识别图像中的幽默元素。
这些特征在以前的视觉语言模型中很少观察到。我们认为GPT-4先进的多模态生成能力的主要原因在于使用了更先进的大型语言模型(LLM)。
为了研究这一现象,我们提出了MiniGPT-4,它使用一个投影层将冻结的视觉编码器与冻结的LLM, Vicuna对齐。我们的研究结果表明,MiniGPT-4具有许多类似于GPT-4所展示的功能,如详细的图像描述生成和从手写草稿创建网站。
此外,我们还观察到MiniGPT-4中的其他新兴功能,包括根据给定图像编写故事和诗歌,为图像中显示的问题提供解决方案,根据食物照片教用户如何烹饪等。
在我们的实验中,我们发现只有对原始图像-文本对进行预训练才能产生缺乏连贯性的非自然语言输出,包括重复和句子碎片。
为了解决这个问题,我们在第二阶段策划了一个高质量的、对齐良好的数据集,使用会话模板来微调我们的模型。
这一步对于增强模型的生成可靠性和整体可用性至关重要。值得注意的是,我们的模型具有很高的计算效率,因为我们只使用大约500万对齐的图像-文本对来训练一个投影层。
视频演示模型MiniGPT-4由一个预先训练的ViT和Q-Former的视觉编码器、一个单一的线性投影层和一个先进的Vicuna大型语言模型组成。MiniGPT-4只需要训练线性层以使视觉特征与骆马对齐。MiniGPT-4的架构。
MiniGPT-4官方文档
MiniGPT-4:使用高级大型语言模型增强视觉语言理解
Deyao Zhu(在就业市场上!),Jun Chen(在就业市场上!),沈小倩,Xiang Li,和穆罕默德 · 埃尔霍赛尼.* 同等贡献
阿卜杜拉国王科技大学
介绍
- MiniGPT-4 仅使用一个投影层将来自 BLIP-2 的冻结视觉编码器与冻结 LLM(小羊驼)对齐。
- 我们用两个阶段训练 MiniGPT-4. 第一个传统的预训练阶段是使用 4 个 A100 在 10 小时内使用大约 500 万个对齐的图像-文本对进行训练。在第一阶段之后,小羊驼能够理解图像。但小羊驼的繁殖能力受到严重影响。
- 为了解决这个问题并提高可用性,我们提出了一种新颖的方法,通过模型本身和 ChatGPT 一起创建高质量的图像-文本对。在此基础上,我们创建了一个小(总共 3500 对)但高质量的数据集。
- 第二个微调阶段是在对话模板中对该数据集进行训练,以显著提高其生成可靠性和整体可用性。令我们惊讶的是,这个阶段的计算效率很高,使用单个 A100 只需大约 7 分钟。
- MiniGPT-4 产生了许多新兴的视觉语言功能,类似于 GPT-4 中演示的功能。
入门
安装
准备代码和环境
Git 克隆我们的存储库,创建一个 Python 环境,并通过以下命令激活它
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4
2. 准备预先训练的小羊驼砝码
当前版本的 MiniGPT-4 是在 Vicuna-13B 的 V0 Versoin 上构建的。请参考我们的说明here来准备小羊驼砝码。最终权重将位于具有以下结构的单个文件夹中:
vicuna_weights
├── config.json
├── generation_config.json
├── pytorch_model.bin.index.json
├── pytorch_model-00001-of-00003.bin
...
然后,在第 16 行的模型配置文件here中设置小羊驼重量的路径。
准备预训练的 MiniGPT-4 检查点
要使用我们的预训练模型,请下载预训练检查点here。然后,在第 11 行的评估配置文件评估 _configs/minigpt4_EVAL.YAML中设置预训练检查点的路径。
本地启动演示
通过运行以下命令,在你的本地计算机上尝试我们的演示demo.py
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml
在这里,我们将 Vicuna 默认加载为 8 位,以节省一些 GPU 内存使用。此外,默认的波束搜索宽度为 1. 在此设置下,演示大约需要 23G GPU 内存。如果你有更强大的 GPU 和更大的 GPU 内存,则可以通过在配置文件MINIPT4_EVAL.YAML中将“低 _ 资源”设置为“假”并使用更大的波束搜索宽度来运行 16 位模型。
训练
MiniGPT-4 的训练包含两个对准阶段。
1. 第一次预培训阶段
在第一个预训练阶段,使用来自 LAION 和 CC 数据集的图像-文本对来训练模型,以对准视觉和语言模型。要下载和准备数据集,请查看我们的第一阶段数据集准备说明。在第一阶段之后,视觉特征被映射并且可以被语言模型理解。要启动第一阶段训练,请运行以下命令。在我们的实验中,我们使用 4 个 A100. 你可以在配置文件列车 _ 配置/MiniGPT4_ 阶段 1_pretrain.yaml中更改保存路径
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage1_pretrain.yaml
2、第二次微调阶段
在第二阶段,我们使用自己创建的小型高质量图文对数据集,并将其转换为对话格式,以进一步对齐 MiniGPT-4. 要下载和准备我们的第二阶段数据集,请查看我们的第二阶段数据集准备说明。要启动第二阶段对齐,请首先在中列车 _ 配置/MiniGPT4_ 阶段 1_pretrain.yaml指定阶段 1 中训练的检查点文件的路径。你还可以在此处指定输出路径。然后,运行以下命令。在我们的实验中,我们使用 1 个 A100。
torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage2_finetune.yaml
在第二阶段对准之后,MiniGPT-4 能够连贯地和用户友好地谈论图像。
鸣谢
- MiniGPT-4 的BLIP2模型结构遵循 BLIP-2. 不要忘记检查这个伟大的开源工作,如果你以前不知道它!
- Lavis这个仓库是建立在 LAVIS 之上的!
- 只有 13B 参数的小羊驼Vicuna神奇的语言能力令人惊叹。而且它是开源的!
如果你在研究或应用中使用 MiniGPT-4,请引用此 Bibtex:
@misc{zhu2022minigpt4,
title={MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models},
author={Deyao Zhu and Jun Chen and Xiaoqian Shen and xiang Li and Mohamed Elhoseiny},
year={2023},
}
版权归原作者 朴拙数科 所有, 如有侵权,请联系我们删除。