
hw7
代码
任务描述
使用bert来做问答任务
答案是都是可以在Document找到的,输入Document和Query 输出两个数字分别表示答案在Document中的开始和结束位置。
输入格式如下: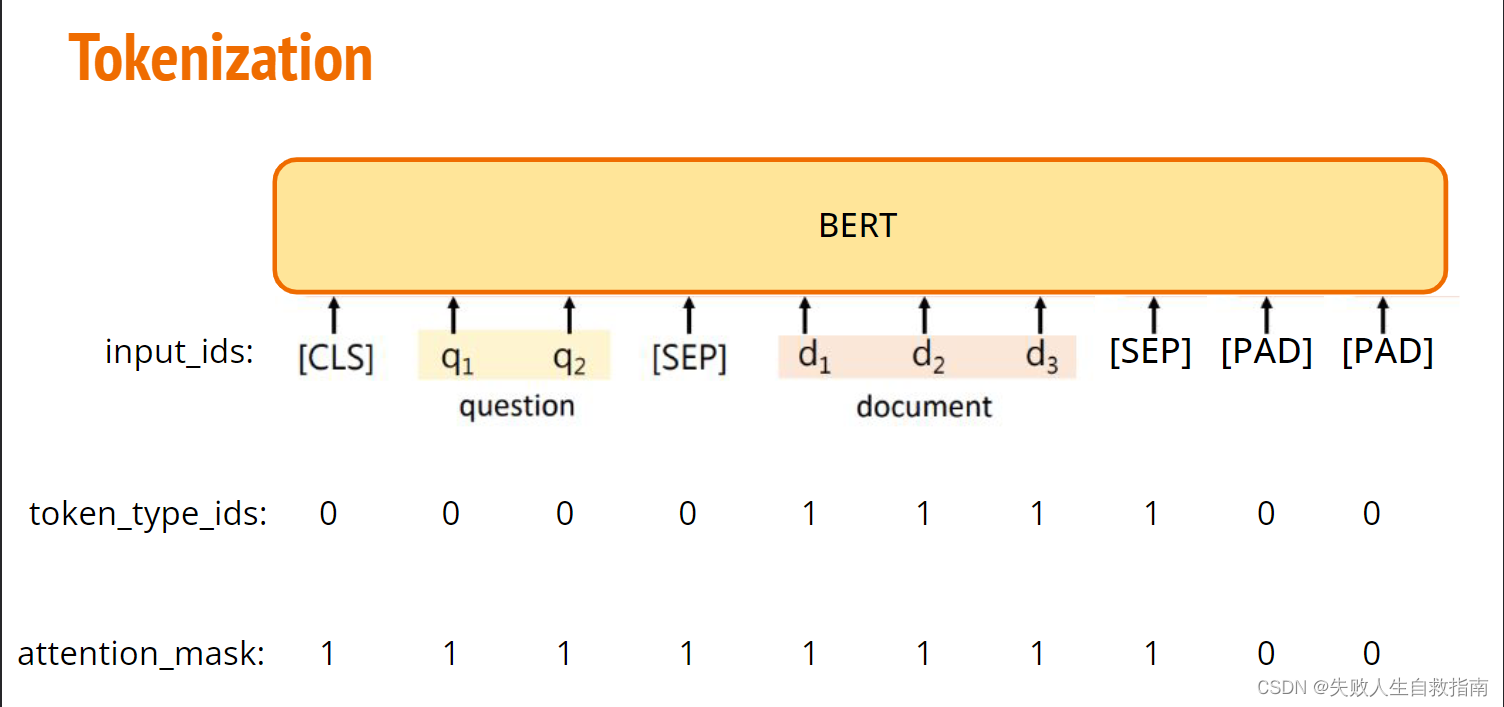
实验要求

实验过程
- doc stride,初始时Doc stride等于max_paragraph_len,这样会导致在测试时如果答案在边界附近就会被切割到两个不同的window中,从而导致预测错误。所以应该将doc stride调小一点,使得测试的window有所重叠。
- preprocessing数据前处理,之前训练的时候选取paragraph的时候总是让答案在段落的中间位置,这样会导致模型学到奇怪的东西,比如测试的时候输出的答案都比较偏向于中心位置,这样显然是不对的,因为测试的时候我们并不知道答案会落到哪里,因此在选取段落时应该随机选取,从最左边到最右边随机选取开始位置。代码如下:
start_min =max(0, answer_end_token - self.max_paragraph_len +1)
start_max =min(answer_start_token,len(tokenized_paragraph)- self.max_paragraph_len)
start_max=max(start_min,start_max)
paragraph_start = random.randint(start_min, start_max +1)
paragraph_end = paragraph_start + self.max_paragraph_len
- postprocessing数据后处理,测试的时候输出的结果可能会有问题,此时即便它概率很高也不能用,这些问题包括开始位置大于结束位置,开始位置或结束位置不在paragraph中。
if start_index > end_index or start_index < paragraph_start or end_index > paragraph_end:
continue
数据后处理还包括UNK的处理,有些字符Bert编码后是UNK,要将这些UNK字符还原为其原本的结果。
answer = answer.replace(' ','')if'[UNK]'inanswer:print('发现 [UNK],这表明有文字无法编码, 使用原始文本')#print("Paragraph:", paragraph)#print("Paragraph:", paragraph_tokenized.tokens)print('--直接解码预测:', answer)
#找到原始文本中对应的位置
raw_start = paragraph_tokenized.token_to_chars(origin_start)[0]
raw_end = paragraph_tokenized.token_to_chars(origin_end)[1]
answer = paragraph[raw_start:raw_end]print('--原始文本预测:',answer)
- 选用更强力的预训练模型。huggingface地址我采用的luhua/chinese_pretrain_mrc_macbert_larg
- 使用warm up学习率。
total_steps=num_epoch*len(train_loader)
warmup_steps=100
optimizer =AdamW(model.parameters(), lr=learning_rate)
scheduler =get_cosine_schedule_with_warmup(optimizer, warmup_steps, total_steps)
- 调小batch size因为新采用的模型太大了,大的batch size会导致内存爆炸,我的batch size设置为8,调小学习率,我的学习率设置为1e-5。
- 将验证集中的数据也拿来训练,增加训练的数据量。
- 对不同seed 或不同参数得到的模型做Ensemble。 上述技巧记载了我一步步的调试过程,每当我采取上述的一个方法,都会对实验结果带来提升,这令我非常欣喜,这让我感到机器学习虽然有很大的未知性,不可解释性,但也是有其有规律的地方的,只要往正确的方向上走,就会对实验结果有所提升。当然了,找到正确的前进方向将一直是我研究的目标。 这是我在家最后一篇博客,这周是开学前最后一周,明天就将出发去学校了,终于赶在最后时刻将暑假三个月跑代码,写代码,调代码所得到的感悟总结下来了。 希望开学之后我不必再自己给自己找任务来做了。
本文转载自: https://blog.csdn.net/qq_43613342/article/details/127044475
版权归原作者 失败人生自救指南 所有, 如有侵权,请联系我们删除。
版权归原作者 失败人生自救指南 所有, 如有侵权,请联系我们删除。