

项目地址:Datamining_project: 数据挖掘实战项目代码
一、背景和挖掘目标
在企业的客户关系管理中,对客户分类,区分不同价值的客户。针对不同价值的客户提供个性化服务方案,采取不同营销策略,将有限营销资源集中于高价值客户,实现企业利润最大化目标。
在竞争激烈的航空市场里,很多航空公司都推出了优惠的营销方式来吸引更多的客户。在此种环境下,如何将公司有限的资源充分利用,提示企业竞争力,为企业带来更多的利益。
1、RFM****模型缺点分析
广泛用于分析客户价值的是RFM****模型,它是通过三个指标(最近消费时间间隔(Recency)、消费频率(Frequency)、消费金额(Monetary))来进行客户细分,识别出高价值的客户。如果分析航空公司客户价值,此模型不再适用,存在一些缺陷和不足:

在模型中,消费金额表示在一段时间内,客业产品金额的总和。因航空票价受到运输距离、舱位等级等多种因素影响,同样消费金额的不同旅客对航空公司的价值是不同的。因此这个指标并不适合用于航空公司的客户价值分析。
传统模型分析是利用属性分箱方法进行分析如图,但是此方法细分的客户群太多,需要一一识别客户特征和行为,提高了针对性营销的成本。
2、原始数据情况


# 导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import preprocessing
import warnings
warnings.filterwarnings('ignore') # 忽略警告
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
data = pd.read_csv('air_data.csv', sep=',',encoding='ANSI') # encoding='gbk'
data
3、挖掘目标
- 借助航空公司客户数据,对客户进行分类;
- 对不同的客户类别进行特征分析,比较不同类客户的客户价值;
- 对不同价值的客户类别提供个性化服务,制定相应的营销策略。
二、分析方法与过程
1、初步分析:提出适用航空公司的LRFMC模型
- 因消费金额指标在航空公司中不适用,故选择客户在一定时间内累积的飞行里程M和客户乘坐舱位折扣系数的平均值C两个指标代替消费金额。此外,考虑航空公司会员加入时间在一定程度上能够影响客户价值,所以在模型中增加客户关系长度L,作为区分客户的另一指标,因此构建出LRFMC模型。
- 采用聚类的方法对客户进行细分,并分析每个客户群的特征,识别其客户价值。
2、总体流程

** 第一步:数据抽取**
- 以2014-03-31为结束时间,选取宽度为两年的时间段作为分析观测窗口,抽取观测窗口内有乘机记录的所有客户的详细数据形成历史数据。对于后续新增的客户详细信息,利用其数据中最大的某个时间点作为结束时间,采用上述同样的方法进行抽取,形成增量数据。
- 根据末次飞行日期,从航空公司系统内抽取2012-04-01至2014-03-31内所有乘客的详细数据,总共62988条记录。
第二步:探索性分析
- 原始数据中存在票价为空值,票价为空值的数据可能是客户不存在乘机记录造成。
- 票价最小值为0、折扣率最小值为0、总飞行公里数大于0的数据。其可能是客户乘坐0折机票或者积分兑换造成。
explore = data.describe(percentiles = [], include = 'all').T #包括对数据的基本描述,percentiles参数是指定计算多少的分位数表(如1/4分位数、中位数等);T是转置,转置后更方便查阅
explore['null'] = len(data)-explore['count'] #describe()函数自动计算非空值数,需要手动计算空值数

explore = explore[['null', 'max', 'min']]
explore.columns = [u'空值数', u'最大值', u'最小值'] #表头重命名

describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、freq(最高频数)、mean(平均值)、std(方差)、min(最小值)、50%(中位数)、max(最大值)。
explore.to_csv("resultfile.csv") #导出结果
第三步:数据预处理
- 数据清洗:从业务以及建模的相关需要方面考虑,筛选出需要的数据。
丢弃票价为空的数据。丢弃票价为0、平均折扣率不为0、总飞行公里数大于0的数据。
- 属性规约:原始数据中属性太多,根据LRFMC模型,选择与其相关的六个属性,删除不相关、弱相关或冗余的属性。
- 数据变换: 属性构造、数据标准化。
data = pd.read_csv('air_data.csv', sep=',',encoding='ANSI') # encoding='gbk'
data = data[data['SUM_YR_1'].notnull()*data['SUM_YR_2'].notnull()] #票价非空值才保留
#只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。
index1 = data['SUM_YR_1'] != 0
index2 = data['SUM_YR_2'] != 0
index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) #该规则是“与”
data = data[index1 | index2 | index3] #该规则是“或”
data.to_csv("data_cleaned.csv") #导出结果

属性构造:因原始数据中并没有直接给出LRFMC五个指标,需要构造这五个指标。
L = LOAD_TIME - FFP_DATE
会员入会时间距观测窗口结束的月数 = 观测窗口的结束时间 - 入会时间[单位:月
R = LAST_TO_END
客户最近一次乘坐公司飞机距观测窗口结束的月数 = 最后一次乘机时间至观察窗口末端时长[单位:月]
F = FLIGHT_COUNT
客户在观测窗口内乘坐公司飞机的次数 = 观测窗口的飞行次数[单位:次]
M = SEG_KM_SUM
客户在观测时间内在公司累计的飞行里程 = 观测窗口总飞行公里数[单位:公里]
C = AVG_DISCOUNT
客户在观测时间内乘坐舱位所对应的折扣系数的平均值 = 平均折扣率[单位:无]
数据标准化:因五个指标的取值范围数据差异较大,为了消除数量级数据带来的影响,需要对数据进行标准化处理。
#标准差标准化
import pandas as pd
datafile = 'zscoredata.xls' #需要进行标准化的数据文件;
zscoredfile = 'zscoreddata.xls' #标准差化后的数据存储路径文件;
#标准化处理
data = pd.read_excel(datafile)
data = (data - data.mean(axis = 0))/(data.std(axis = 0)) #简洁的语句实现了标准化变换,类似地可以实现任何想要的变换。
data.columns=['Z'+i for i in data.columns] #表头重命名。
data.to_excel(zscoredfile, index = False) #数据写入
data
第四步:构建模型
构建航空客户价值分析模型:客户K-Means****聚类、客户价值分析、模型应用。
1、客户K-Means聚类
采用K-Means聚类算法对客户数据进行分群,将其聚成五类(需要结合业务的理解与分析来确定客户的类别数量)。
import pandas as pd
from sklearn.cluster import KMeans #导入K均值聚类算法
inputfile = 'zscoreddata.xls' #待聚类的数据文件
k = 5 #需要进行的聚类类别数
#读取数据并进行聚类分析
data = pd.read_excel(inputfile) #读取数据
#调用k-means算法,进行聚类分析
kmodel = KMeans(n_clusters = k ) #n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data) #训练模型
kmodel.cluster_centers_ #查看聚类中心
kmodel.labels_ #查看各样本对应的类别
r1 = pd.Series(kmodel.labels_).value_counts() # 统计各类的个数
r2 = pd.DataFrame(kmodel.cluster_centers_) # 获取聚类中心
r = pd.concat([r2,r1],axis=1) # 合并
r.columns = list(['L','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']) + ['类别数目'] # 加上列名
r

给df_data加上一列按照df_data索引,标签为值值的列。参考:http://t.csdn.cn/IOW5W
df_data = pd.read_excel('zscoreddata.xls')
r2 = pd.concat([df_data,pd.Series(kmodel.labels_,index=df_data.index)],axis=1)
r2.columns = list(['L','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']) + ['聚类类别'] # 加列名
r2
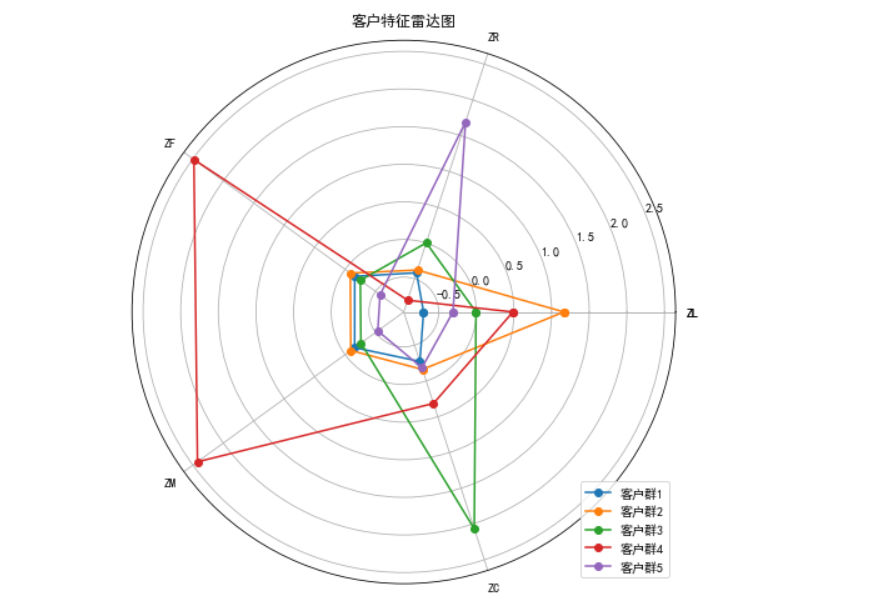
**2、客户价值分析 **
对聚类结果进行特征分析,其中客户群1在F、M属性最大,在R属性最小;客户群2在L属性上最大;客户群3在R属性上最大,在F、M属性最小;客户群4在L、C属性上最小;客户群5在C属性上最大。
# 根据r2绘制雷达图
labels = np.array(['ZL','ZR','ZF','ZM','ZC'])
labels = np.concatenate((labels,[labels[0]]))
N = len(r2)
angles = np.linspace(0, 2 * np.pi, N, endpoint=False)
data = pd.concat([r2,r2.loc[:,0]],axis=1)
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(111, polar=True) # 参数polar, 以极坐标的形式绘制图形
# 画线
j=0
for i in range(0,5):
j=i+1
ax.plot(angles,data.loc[i,:],'o-',label="客户群"+str(j))
# 添加属性标签
ax.set_thetagrids(angles*180/np.pi,labels)
plt.title(u'客户特征雷达图')
plt.legend(loc='lower right')
plt.show()
根据业务定义五个等级的客户类别:重要保持客户、重要发展客户、重要挽留客户、一般客户、低价值客户。
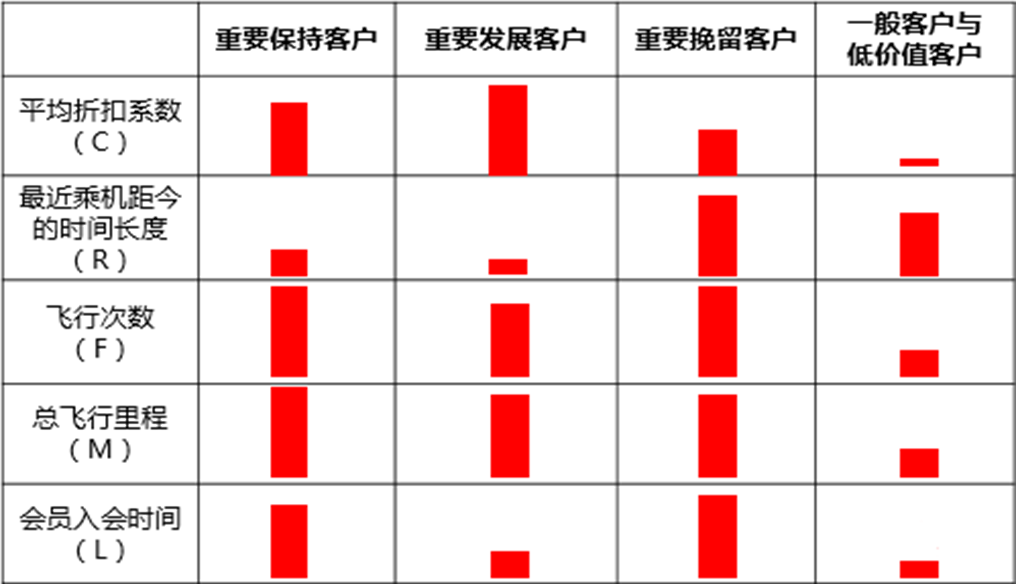
客户群价值排名:根据每种客户类型的特征,对各类客户群行客户价值排名,获取高价值客户信息。
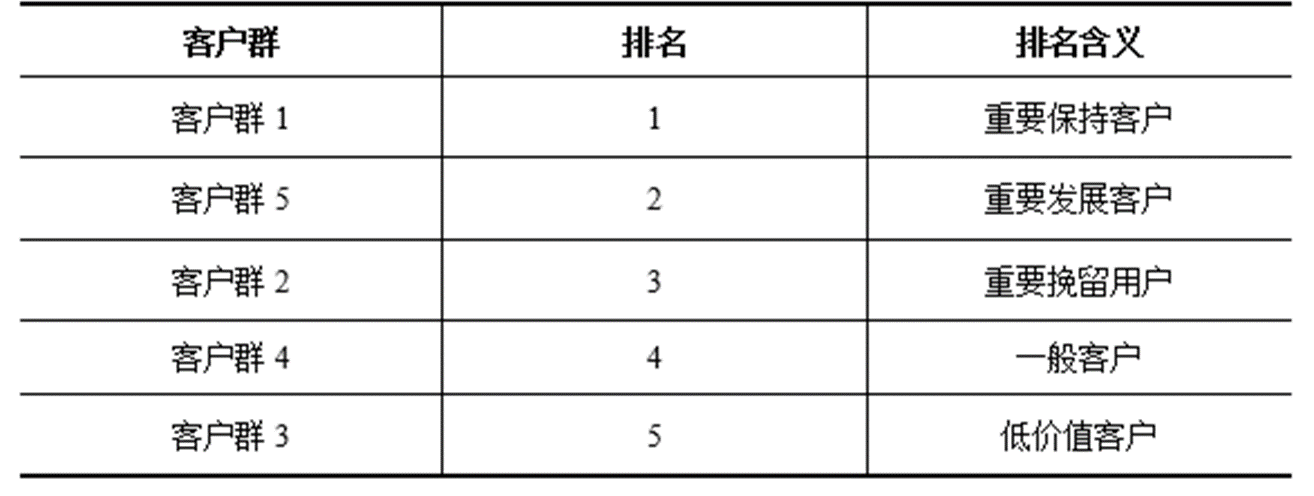
3、模型应用:根据各个客户群的特征,可采取一些营销手段和策略。
a)会员的升级与保级。
b)首次兑换。
c)交叉销售。
总结和思考
- 在国内航空市场竞争日益激烈的背景下,客户流失问题是影响公司利益的重要因素之一。如何如何改善流失问题,继而提高客户满意度、忠诚度,维护自身的市场和利益?
- 客户流失分析可以针对目前老客户进行分类预测。针对航空公司客户信息数据附件(见:/示例程序/air_data.csv)可以进行老客户以及客户类型的定义(例如:将其中将飞行次数大于6次的客户定义为老客户,已流失客户定义为:第二年飞行次数与第一年飞行次数比例小于50%的客户等)。
- 选取客户信息中的关键属性如:会员卡级别,客户类型(流失、准流失、未流失),平均折扣率,积分兑换次数,非乘机积分总和,单位里程票价,单位里程积分等。通过这些信息构建客户的流失模型,运用模型预测未来客户的类别归属(未流失、准流失,或已流失)。
版权归原作者 Lingxw_w 所有, 如有侵权,请联系我们删除。