

Kaggle的数据科学黑客大会最有趣和最具挑战性的一件事是:在公共和私有的排行榜中,努力保持同样的排名。当我的结果在一个私有的排行榜进行验证时,我就失去了共有的排名。

你有没有想过是什么原因导致了这些排名的高差异?换句话说,为什么一个模型在私有排行榜上评估时会失去稳定性?
在本文中,我们将讨论可能的原因。我们还将学习交叉验证和执行它的各种方法。
模型的稳定性?
总是需要验证你的机器学习模型的稳定性。换句话说,你不能把这个模型与你的训练数据相匹配,并预测它的未来日期,然后希望它每次都能准确地给出结果。我之所以强调这一点是因为每次模型预测未来的日期,它都是基于看不见的数据,这些数据可能与训练数据不同。如果训练模型不能从你的训练数据中捕捉趋势,那么它可能会在测试集上过度拟合或不拟合。换句话说,可能会有高的方差或偏差。
让我们通过一个例子来进一步了解模型的稳定性。
在这个例子中,我们试图找出一个人购买汽车与否的关系,这取决于他的收入。为此,我们采取了以下步骤:
我们用一个线性方程建立了买车与否和个人收入之间的关系。假设你有2010年到2019年的数据,并试图预测2020年。您已经根据可用的列车数据训练了您的模型。

在第一个图中,我们可以说,该模型捕捉到了训练数据的每一个趋势,包括噪音。该模型的精度非常高,误差极小。这被称为过拟合,因为模型已经考虑了数据点的每一个偏差(包括噪声),而且模型太敏感,只能捕获当前数据集中出现的每一个模式。正是由于这个原因,可能会产生高偏差。
在第二个图中,我们只是找到了两个变量之间的最优关系,即低训练误差和更一般化的关系。
在第三个图中,我们发现该模型在列车数据上表现不佳,精度较低,误差%较大。因此,这种模式不会有很好的表现。这是不合适的典型例子。在这种情况下,我们的模型无法捕捉训练数据的潜在趋势。
在Kaggle的许多机器学习比赛中常见的做法是在不同的模型上进行迭代,以寻找一个性能更好的模型。然而,很难区分分数的提高是因为我们更好地捕捉了变量之间的关系,还是我们只是过度拟合了训练数据。为了更多地了解这一点,机器学习论坛上的许多人使用了各种验证技术。这有助于实现更一般化的关系,并维护模型的稳定性。
交叉验证是什么?
交叉验证是一种在机器学习中用于评估机器学习模型性能的统计验证技术。它使用数据集的子集,对其进行训练,然后使用未用于训练的数据集的互补子集来评估模型的性能。它可以保证模型正确地从数据中捕获模式,而不考虑来自数据的干扰。
交叉验证使用的标准步骤:
- 它将数据集分为训练和测试两部分。
- 它在训练数据集上训练模型。
- 它在测试集中评估相同的模型。
- 交叉验证技术可以有不同的风格。
交叉验证中使用的各种方法
Train_Test_Split
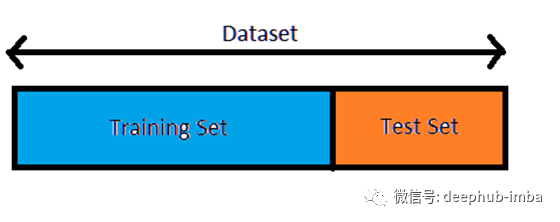
这是一种基本的交叉验证技术。在这种技术中,我们使用数据的一个子集作为模型训练的训练数据,并在另一组被称为测试集的数据上评估模型的性能,如图所示。误差估计然后告诉我们的模型在看不见的数据或测试集上的表现。这是一种简单的交叉验证技术,也被称为验证方法。这种技术存在差异大的问题。这是因为不确定哪些数据点会出现在测试集或训练集&这会导致巨大的方差,而且不同的集合可能会产生完全不同的结果。
n次交叉验证/ k次交叉验证
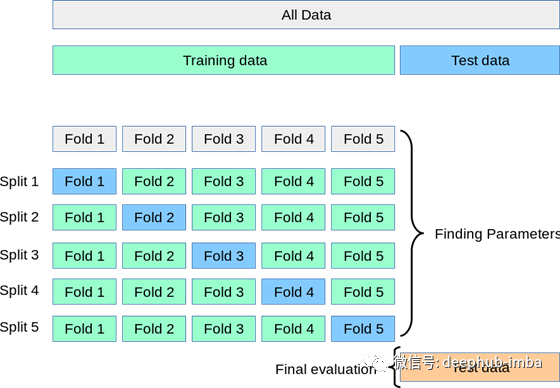
总有需要大量的数据来训练模型,将测试数据集的一部分可以离开不理解的模型数据的模式可能会导致错误,也可能导致增加欠拟合模型的测试数据。为了克服这个问题,有一种交叉验证技术,它为模型的训练提供了充足的数据,也为验证留下了充足的数据。K折叠交叉验证正是这样做的。
n次交叉验证涉及的步骤:
- 基于N- fold分割你的整个数据集。
- 对于数据集中的每n次折叠,在数据集的N-1次折叠上构建模型。然后,对模型进行检验,检验n次折叠的有效性
- 在预测中记录每次迭代的错误。重复这个步骤,直到每一个n -fold都作为测试集
- 你的N个记录错误的平均值被称为交叉验证错误,它将作为模型的性能度量。
例如:
假设数据有100个数据点。基于这100个数据点,你想预测下一个数据点。然后可以使用100条记录进行交叉验证。假设折叠次数(N) = 10。
- 100个数据点被分成10个桶,每个桶有10条记录。
- 在这里,根据数据和N值创建了10个折叠。现在,在10次折叠中,9次折叠会被用作你的训练数据并在10次折叠
- 测试你的模型。迭代这个过程,直到每次折叠都成为您的测试。计算你在所有折叠上选择的度规的平均值。这个度量将有助于更好地一般化模型,并增加模型的稳定性。
交叉验证(LOOCV)
在这种方法中,我们将现有数据集中的一个数据点放在一边,并在其余数据上训练模型。这个过程迭代,直到每个数据点被用作测试集。这也有它的优点和缺点。让我们来看看它们:
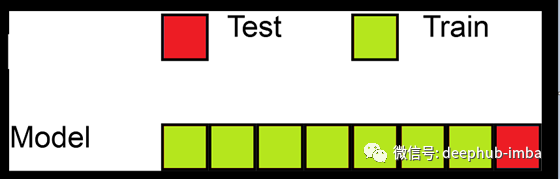
我们利用所有的数据点,因此偏差会很低
我们根据数据集中可用的数据点的数量重复n次交叉验证过程,这会导致更高的执行时间和更高的计算量。
由于我们只对一个数据点进行测试,如果该测试数据点是一个离群点,可能会导致较高的误差%,因此我们不能基于这种技术对模型进行推广。
分层n倍交叉验证
在某些情况下,数据可能有很大的不平衡。对于这类数据,我们使用了不同的交叉验证技术,即分层n次交叉验证,即每一次交叉验证都是平衡的,并且包含每个类的样本数量大致相同。分层是一种重新安排数据的技术,以确保每一褶都能很好地代表数据中出现的所有类。
例如,在关于个人收入预测的dataset中,可能有大量的人低于或高于50K。最好的安排总是使数据在每个折叠中包含每个类的几乎一半实例。
时间序列的交叉认证
将时间序列数据随机分割为折叠数是行不通的,因为这种类型的数据是依赖于时间的。对这类数据的交叉验证应该跨时间进行。对于一个时间序列预测问题,我们采用以下方法进行交叉验证。
时间序列交叉验证的折叠以向前链接的方式创建。

例如,假设我们有一个时间序列,显示了一家公司2014年至2019年6年间的年汽车需求。折叠的创建方式如下:
Train 1— [2014]
Test 1— [2015]
Train2–[2014,2015]
Test2 — [2016]….so on
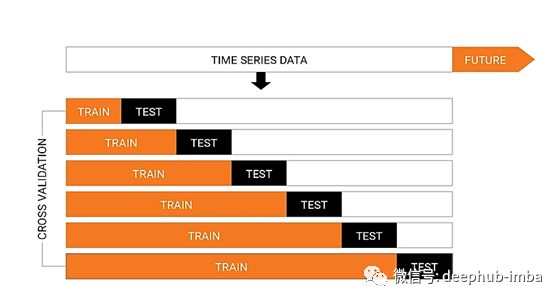
我们逐步地选择一个新的列车和测试集。我们选择一个列车集,它具有最小的观测量来拟合模型。逐步地,我们在每个折叠中改变我们的列车和测试集。
总结
在本文中,我们讨论了过拟合、欠拟合、模型稳定性和各种交叉验证技术,以避免过拟合和欠拟合。我们还研究了不同的交叉验证技术,如验证方法、LOOCV、n次交叉验证、n次分层验证等等。
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********