
详解FPGA:人工智能时代的驱动引擎观后感
本书大目录
第一章 延续摩尔定律
第二章 拥抱大数据的洪流
第三章 FPGA在人工智能时代的独特优势
第四章 更简单也更复杂——FPGA开发的新方法
第五章 站在巨人肩上——FPGA发展新趋势
文章目录
第一章 延续摩尔定律
在学这一章节的时候,我抱着几个问题去书里寻找答案
1.1. 为什么会诞生FPGA呢?
由于最一开始的硬件芯片是逻辑门器件(或门、与门、异或门或查找表LUT等)固化在芯片上,不能进行修改,就行《三体》里的人型计算机,在确定好各个逻辑位置后,就不再改变,会一直按照当前设计的功能进行运行。这时就会有人提出为什么给这个芯片设计一个可以修改的功能,这就有了通过某种方式对逻辑门器件进行排列组合进行修改,这个想法就是FPGA最开始诞生的影子。
1.2. GPU,CPU,和很多专用芯片都可以编程,FPGA与之有何不同?
FPGA是对逻辑门器件进行编程,而专用芯片是基于当前硬件基础进行编程。例如FPGA在编程中只需要少量器件,就可以将其他不用的器件关闭,而其他芯片则不能控制硬件底层的编程。
1.3. FPGA有什么优势?(为什么要用到FPGA?)
原因1: 由于上一点所说的,FPGA可以控制底层逻辑门器件的编程,所以在专用器件流片之前,可以用FPGA进行逻辑和功能测试(有软件层面的IC验证和硬件层面的FPGA验证),直到满足专业器件功能且尽量用到最少器件的时候,再进行流片,这样会大大减小流片的成本以及元器件数量减小带来的成本。
原因2: EEPROM和闪存发明,使现场可编程(FP)成为了可能。这样以来就不需要将芯片返厂进行原本的紫外线设置光擦除修改电路,而是直接烧写即可修改芯片逻辑门器件的排列组合。
原因3: 在摩尔定律逐渐逼近极限,想要进一步延续低成本、低功耗、高速率的发展趋势,就需要不断通过FPGA创造和设计新颖的芯片架构和系统。又由于FPGA的异构计算,可以将乘法器、DSP单元、片上存储器等专业逻辑单元添加至FPGA,使其具有更多的应用场景。可以和GPU、ASIC搏一搏,虽然由于FPGA的查找表这样的逻辑单元,导致速度比不过GPU。但是低功耗可以遥遥领先GPU。
原因4:FPGA处于软硬件之间,硬件可以往通信基带领域(和能力有限的常规芯片比);软件可以应用在数字图像处理、算法硬件化这种运算量大的领域发展(和运算能力强的GPU比)。
1.4. 赛灵思ACAP(2020)
ACAP并不是FPGA,而是整合了硬件可编程逻辑单元、软件可编程处理器,以及软件可编程加速引擎的下一代计算平台,是赛灵思“发明FPGA以来最卓越的工程成就”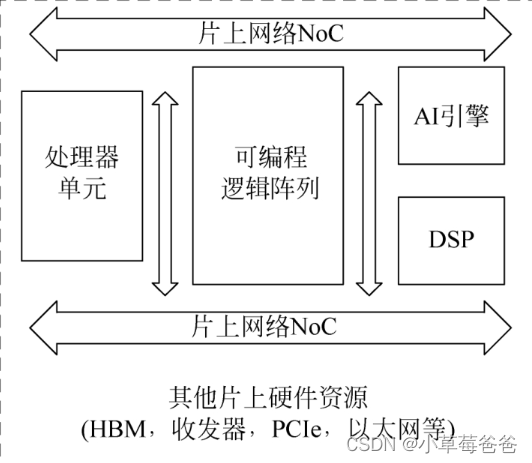
创新点1:采用来AI加速引擎,可以用来加速神经网络的计算时间和其他常见应用的数学计算和信号处理
创新点2:片上网络NoC,不仅减少布线压力,而且编译时只对修改部分进行编译,大大减小编译时长。
创新点3:可编程逻辑结构CLB面积增大四倍,因为内部连接比全局布线更快;查找表LUT增加一个输出。
创新点4:采用第四代3D硅片堆叠技术SSI,采用更多的互联通道,延时下降30%
ACAP官网介绍:
1.5. 英特尔Agilex FPGA(2019)
在这个大背景下,10nm Agilex FPGA应运而生。它既包含了传统FPGA灵活的可编程性,又结合了现代FPGA基于异构架构的敏捷性,因此能够同时适用于众多应用领域,并针对不同的应用场景进行配置和快速迭代。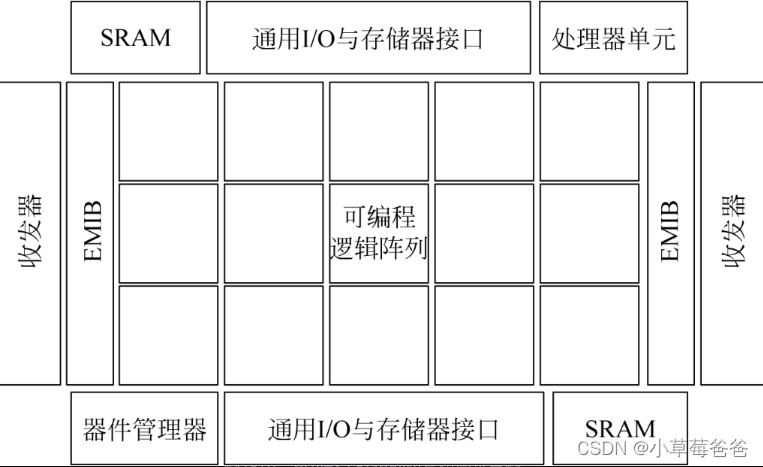
创新点1: 与现有的英特尔FPGA相似,Agilex也使用了EMIB技术提供多个异构硅片之间的高速互连,特别是可编程逻辑部分与不同速度的收发器Tile之间的连接。
创新点2: 由于架构将逻辑阵列分为很多单元,因此时延较大。为了减小延时,Agilex对最小逻辑单元ALM做了不少架构升级。
创新点3:由于英特尔CPU很牛,所以FPGA的一个主要应用场景是在数据中心里作为CPU的硬件加速器,用来加速各类应用,如深度学习的模型训练、金融计算、网络功能卸载等。目前CPU的硬件加速器都是GPU。
Agilex FPGA官网介绍:
https://www.intel.cn/content/www/cn/zh/products/details/fpga/agilex.html
第二章 拥抱大数据的洪流
这一章主要介绍了FPGA在处理大数据中扮演什么角色。首先引出了微软Cataplut项目,告诉大家:微软2014已经用FPGA对必应搜索引擎进行硬件加速了,得到95%的吞吐量提升,大家都看一看瞧一瞧,FPGA也可以应用在互联网公司和软件公司啦!
2.1. 硬件加速
至于硬件加速,CPU、GPU、FPGA开始了对话:
CPU:这个我熟,给我来个并行的软件,我可以搞个上千核,给你要多快有多快
GPU:这个你就比不过我了,我天生就是并行运算的,信我就立马给你来个4090试一试
FPGA:你们都out了,有没有听过“暗硅效应”?人家说了虽然你们可以不断增加处理器核心数量,但是所需要的能耗太高了,再加上摩尔定律到头了,晶体管能效发展也停滞了。哪有那么多能耗可以让你们一直工作。
CPU、GPU:那你咋办?
FPGA:第一:我有异构计算,可以适应你们原来的外设。第二:我可编程,所以可以对专门问题进行定制计算,用尽可能少的器件来满足和你们一样的功能。这样我就可以根据给定的任务,动态分配我的资源啦!第三:还是我可编程,当出现故障时,可以快速地调试分析和逻辑验证。
ASCI:这回我占FPGA这边,而且我除了灵活性差点,只能针对某个特定的任务。其他我和FPGA很像,甚至高性能和低功耗比FPGA兄还要好。承让了!
FPGA:hh,但你的高性能还不是由巨大的研发成本换来的,而且灵活性差会让你跟不上时代,核心算法和协议不断地变化,就意味着不停地给你砸钱造新的啦!
所以基于这一点,可以利用FPGA硬件加速的各个优势进行赚钱:卖FPGA芯片和EDA开发工具,这两个东西一卖,就让客户自己开发,利用EDA工具把FPGA芯片开发成可以快速完成算法和应用实现的硬件平台。
重要原话:在软件层面,FPGA厂商除了提供传统的开发套件之外,现在还会提供与FPGA加速卡配套的驱动、各类软件库、编程接口(API),甚至还有下文会提到的完整的软件开发栈以及软硬件参考设计。通过提供这些完整的开发环境,大大简化了FPGA的开发难度,使得软件开发人员也能在短时间内完成算法模型的FPGA实现。FPGA厂商的主要目的,是在不断提供原厂软硬件解决方案的同时,也在不断吸收第三方的IP与应用,从而构建一个完整的FPGA生态系统。
总得而言,未来会把FPGA会提供厂商一整套完善得产品和服务,打造成一个体系。就比如英特尔一开始卖CPU的,为啥收购阿特尔,也许正是看中了FPGA加速功能,可以将FPGA作为很nice的硬件加速单元。不仅如此,赛灵思也在针对大型数据中心应用制作加速卡。
在2018年10月底的赛灵思开发者大会上,浪潮和华为都发布了自己的新FPGA加速卡产品,分别叫作浪潮F37X和华为FX系列
2.2.Cataplut项目的三个阶段
从FPGA片上逻辑架构、FPGA加速卡结构以及与其他硬件资源互联方式、多FPGA之间的资源分配、主要性能指标出发
第一个阶段到第二个阶段:单板多FPGA到单板单FPGA,改善同构性和故障率。
第三阶段:
1.FPGA直接通过网络接口与数据中心网络相连,而不需要经过原来的第二层Torus网络,这样极大地扩展了系统的灵活性
2.FPGA之间可以通过网络进行互连和通信,这使得CPU可以控制和使用“远程”的FPGA
3.引入了名为Elastic Router的模块,主要用来控制多个用户可配置区域(Role)与外界网络的通信。为了实现对池化FPGA资源的统一管理和分配,微软还提出了一种硬件即服务(Hardware as a Service,HaaS)的使用模型,这个模型也成为了FPGA虚拟化的代表性技术之一。
2.3 FPGA提供云服务
原来标题是“FPGA即服务”,但总的意思就是除了Cataplut项目自产自销,又多了一条路,就是把FPGA做成云服务提供给互联网公司,这里就比如亚马逊云服务部门(AWS)一开始用的是GPU,现状也第一次尝试了FPGA云服务了。
思政课一学到第一次***,就必定有四五点意义,AWS使用FPGA作为计算加速服务也有:
- 亚马逊作为大品牌,可以将FPGA作为标准实力,就可以提供各广大的开发人员和终端用户
- 提供了基于云端的标准化FPGA开发工具,给之后工作做好铺垫
- FPGA的逻辑接口定下来了,之后只需要专注算法,不用管其他的了
- 为各种FPGA设计和IP提供一个统一的应用市场和交易平台,为所有AWS用户提供更多的选择和更加方便的使用。 后面值得说的是,阿里云2018年也发不了FPGA计算实例F3,腾讯云也推出了基于赛灵思FPGA的云服务,所以FPGA在提供云服务方面也有搞头。
2.4 下一代电信网络:SDN、NFV与FPGA
FPGA不仅仅在硬件加速、服务器、提供云服务有搞头,在电信网络提供商眼里也是转型动力。就是当前正在蓬勃发展的网络功能虚拟化(Network Function Virtualization,NFV)和软件定义网络(Software Defined Network,SDN)这两项技术
2.5 FPGA虚拟化
这个就比较容易理解了:如果FPGA做大做强,代替了GPU,也做上服务器和典型网络的供应商了,但不可能让客户的人全部要掌握FPGA的开发,全部都要会在EDA工具上设计吧。那就需要FPGA向上兼容,让客户可以更方便地调用FPGA资源。
文中列出了FPGA虚拟化需要注意的要素:最重要的多租户架构(让相同FPGA为不同用户服务)、资源管理(让不理解FPGA架构的用户也可以利用资源:可以将具体的FPGA逻辑资源进行抽象,同时为使用者提供相应的驱动、API,以及监控FPGA任务调度和资源使用的方法。)、灵活性(可以用C这样的高级语言达到相同的作用)、独立性(逻辑分隔)、课扩展性、高性能、安全性、稳定性、开发效率。
第三章 FPGA在人工智能时代的独特优势
优势说白了就在两点,一点是深度学习的加速计算;第二点是定制化硬件设计,这一点的具体好处是适应AI技术的迭代、设计最小满足功能的架构以降低功耗和成本。
3.1. 实时AI处理:微软脑波项目
3.1.1. FPGA资源池化
理解:深度网络的项目中应用一般有两个途径:一个是在具有运算能力的设备上训练好模型,再将模型网络代入DSP、集成芯片上应用;另一种是直接在应用芯片上训练模型,并将新数据集代入模型得出结果。第一种的缺点是不能实时改变模型参数,每次都需要训练完再将网络参数输入到应用芯片。而第二种就不需要怎么麻烦,但是它对应用芯片的运算要求不较高,比如DSP之类是实现不了的。
这里就可以引出FGPA这种又有并行运算,又有较低的功耗。
第一部分主要讲了FPGA资源池化:
为什么需要资源池化?
资源池化是将FPGA的硬件资源分割成很多零碎的单元。
FPGA资源池化有什么好处?
1.,FPGA池化打破了CPU和FPGA的界限。在传统的FPGA使用模型中,FPGA往往作为硬件加速单元,用于卸载和加速原本在CPU上实现的软件功能,因此与CPU紧耦合,严重依赖于CPU的管理,同时与CPU泾渭分明。
2.在FPGA应用中,可以将深度网络处理(DNN模型)分解成若干个小部分,每个小部分可以在一个FPGA实现,然后每一个部分通过高速数据中心网络互联。
第二部分介绍了脑波项目系统架构。下段是原文:
脑波项目的主要目标是利用Catapult的基础设施与大规模的池化FPGA资源,为没有硬件设计经验的用户提供深度神经网络的自动部署和硬件加速,同时满足系统和模型的实时性和低成本的要求。
为了实现这个目标,脑波项目提出了一个完整的软硬件解决方案,主要包含以下三点:
(1)根据资源和需求对训练好的DNN模型进行自动区域划分的完整工具链;
(2)对划分好的子模型进行FPGA和CPU映射的系统架构;
(3)在FPGA上实现并优化的深度学习处理器NPU软核和指令集。
第三部分说了该项目的“低延时”和“高带宽”的原因
(1)因为FPGA资源池化,所以数据可以分给很多单板上,让单板分别处理,处理完之后,可以利用板内快速网络进行数据传输。主要就极大突破了困扰DNN加速应用已久的内存带宽瓶颈。
(2)脑波项目采用了自定义的窄精度数据位宽。
第四部分:脑波项目的主要目标是利用Catapult的基础设施与大规模的池化FPGA资源,为没有硬件设计经验的用户提供深度神经网络的自动部署和硬件加速,同时满足系统和模型的实时性和低成本的要求。
为了实现这个目标,脑波项目提出了一个完整的软硬件解决方案,主要包含以下三点:
(1)根据资源和需求对训练好的DNN模型进行自动区域划分的完整工具链;
(2)对划分好的子模型进行FPGA和CPU映射的系统架构;
(3)在FPGA上实现并优化的NPU软核和指令集。
3.1.2.AI加速引擎:FPGA与深度神经网络的近似算法
我的理解是:虽然GPU处理AI很牛批。但是如果将深度数据网络做个近似,变得简单一点,用低精度定点数代替浮点数,网络剪枝,网络结构优化和压缩等。这样以来,在考虑功耗和成本的基础上,就可以使用FPGA啦
3.1.3.FPGA在AI时代的布局
告诉我们赛灵思(AMD)、英特尔,包括新起的Achronix。这几家FPGA公司都着眼于AI啦
3.1.4.FPGA在AI时代未来的发展方向
这一节告诉我们,有哪些具体的发展方向:
(1).FPGA的架构正在集成越来越多AI相关的硬件资源,以及专门针对AI加速的FPGA架构创新(例如矩阵运算和乘加运算)
(2).AL融入FPGA中有两种方法,一种是以IP核形式集成在FPGA,一种是将AI当作子系统与FPGA异构集成。
(3).最后一点是 上面2.5 的FPGA虚拟化,一句话概括就是让软件工程师都可以用自己熟悉的语言在FPGA平台上进行算法开发
第四章 更简单也更复杂——FPGA开发的新方法
第五章 站在巨人肩上——FPGA发展新趋势
收藏
IP核
版权归原作者 小草莓爸爸 所有, 如有侵权,请联系我们删除。