

我们要做什么
- 步骤1:定义和确定ML的目标
- 步骤2:设定技术先决条件
- 步骤3:获取数据
- 步骤4:准备数据并应用ML进行拟合
- 步骤5:评价并分析结果
步骤一:定义和确定ML目标
免责声明:本练习未考虑诸如交易和佣金之类的费用。作者对使用本文承担的风险或利益*概不负责**。
苹果的价格可能随着时间的推移一直在上涨,但也可能像最近几周一样下跌。
我们想要的是检测第二天价格会上升或下降,以便我们可以在前一天买入或卖空。
我们还希望变化率高于0.5%,这样才值得交易。

价格随时间的变化
以上是价格随着时间的变化图像,绿点是价格上涨超过0.5%的天数,红点是价格下降超过0.5%的天数。
让我们定义我们的目标变量:
Positive POC:“变化”增加了0.5%以上
**Negative POC:**“变化”下降超过0.5%
我们通过建立ML模型可以预测股票新闻预测第二天的上涨,并具有以下表现:
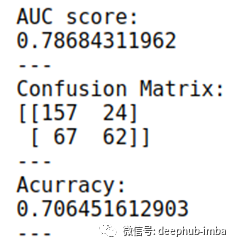

这意味着,根据观察结果,该模型预测,第二天价格将上涨0.5%或更多(82倍),正确率是是72%(62倍)。
该比率(精确度:TP / TP&FP)是一项重要指标,因为在此实验中,每当预测“上升”(或预测下降)时,我们都会“投资”,因此我们优先考虑正确的频率——即使我们失去了一些机会。
现在,让我们建立一个模型来预测“牛市”和“熊市”时期的上升和下降。
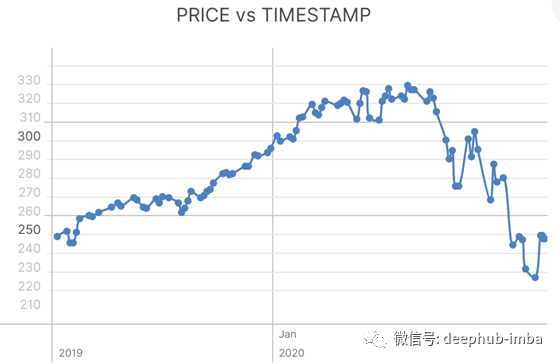
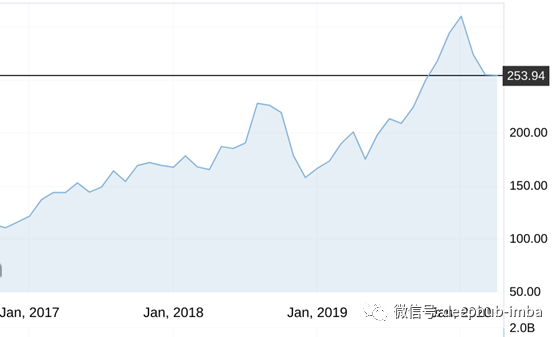
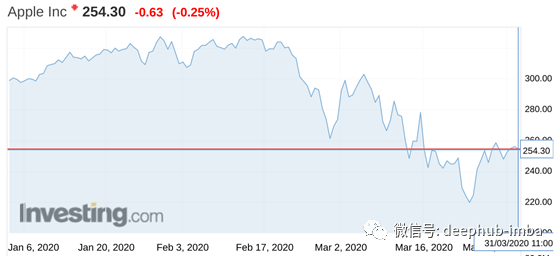
最近几个月受油和Covid-19影响的苹果价格
步骤二:先决条件
- 已安装Python 2.6+或3.1+
- 安装Pandas,sklearn和openblender(使用pip)
$pipinstallpandasOpenBlenderscikit-learn
步骤:获取数据
让我们从每日的Apple Stock数据集中获取信息
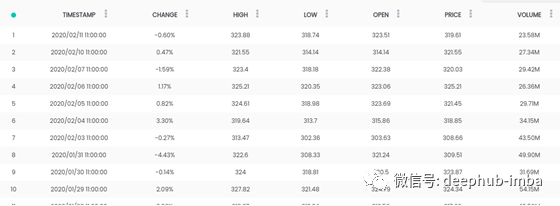
数据中有当天的百分比变化。
让我们通过OpenBlender API获取数据。
在Python上,运行以下代码:
# Import the librariesfrom sklearn.ensemble import RandomForestRegressor
fromsklearn.metricsimportaccuracy_score
fromsklearn.metricsimportroc_auc_score
fromsklearnimportmetrics
importpandasaspd
importOpenBlender
importjson
%matplotlibinline# Specify the action
action = 'API_getObservationsFromDataset'# Specify your Token
token = 'YOUR_TOKEN_HERE'
# Specify the 'Apple Inc. Price' id_datasetparameters = {
'token' : token,
'id_dataset':'5d4c39d09516290b01c8307b',
'consumption_confirmation' : 'on',
'date_filter':{"start_date":"2017-01-01T06:00:00.000Z",
"end_date":"2020-03-29T06:00:00.000Z"}
}# Pull the data into a Pandas Dataframe
df = pd.read_json(json.dumps(OpenBlender.call(action, parameters)['sample']), convert_dates=False, convert_axes=False).sort_values('timestamp', ascending=False)
df.reset_index(drop=True, inplace=True)
注意:要获取秘钥,您需要在openblender.io(免费)上创建一个帐户,您可以在个人资料图标的“帐户”标签中找到该秘钥。
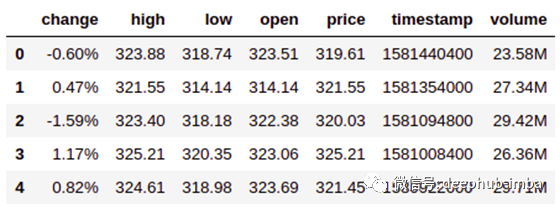
#Let's take a look
df.head()
要混合商业新闻,我们需要:
- 收集有用的新闻数据,这些数据(从统计角度而言)与我们的目标相关
- 将其融合到我们的数据中,使商业新闻的数据与第二天的价格“变化”保持一致(这样,模型就可以学习预测第二天的价格)
- 将其转换为数值特征,以便可以使用ML模型。
让我们看一下《华尔街日报》新闻数据集:
还有《今日美国》的Twitter新闻。

注意:之所以选择这些是因为它们很有代表性,但是您可以搜索到其他数百个数据集。
现在,我们创建一个文本矢量化程序,它是OpenBlender上的一个模型,可以将标记(矢量化文本)作为特征提取,就像它是另一个数据集一样:
action = 'API_createTextVectorizerPlus'parameters = {
'token' : token,
'name' : 'Wall Street and USA Today Vectorizer',
'sources':[
{'id_dataset':"5e2ef74e9516294390e810a9",
'features' : ["text"]},
{'id_dataset' : "5e32fd289516291e346c1726",
'features' : ["text"]}
],
'ngram_range' : {'min' : 1, 'max' : 2},
'language' : 'en',
'remove_stop_words' : 'on',
'min_count_limit' : 2
}response = OpenBlender.call(action, parameters)
response
通过上面的代码,我们指定了以下内容:
- name: 我们将其命名为“ Wall Street and USA Today Vectorizer”
- sources: 需要数据集的ID和来源列(在这种情况下,两者都只有一个,并且都命名为“文本”)
- ngram_range: 将被标记化的单词集的最小和最大长度
- language: 英语
- remove_stop_words: 它从源中消除了停用词
- min_count_limit: 单词的最小重复次数(一次出现很少有帮助)
现在,如果我们注意OpenBlender的界面,我们可以看到矢量化器:
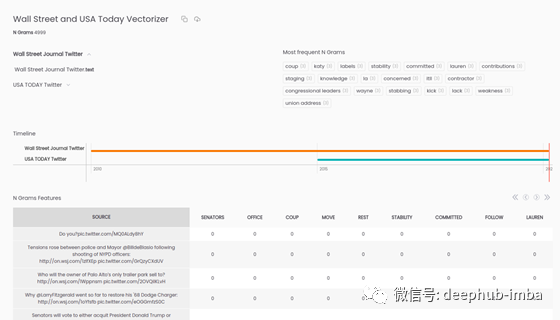
它生成了4999个n-gram,在最多2个单词的二进制特征中,如果提到n-gram,则为“ 1”,否则为“ 0”。
步骤三:准备数据集
现在,我们希望矢量化数据在24小时的时间段中压缩并与第二天的Apple股票价格保持一致。
您需要添加矢量转换器的id(它是由API返回的,也可以在Open Blender中获取。)
*注意:要下载所有矢量化数据,您需要支付约6美元的费用,在OpenBlender中将权限升级为“随用随付”。您仍然可以继续减少一小部分数据,以缩短日期间隔。
action = 'API_getObservationsFromDataset'interval = 60*60*24# One dayparameters = {
'token' : token,
'id_dataset':'5d4c39d09516290b01c8307b',
'date_filter':{"start_date":"2017-01-01T06:00:00.000Z",
"end_date":"2020-03-29T06:00:00.000Z"},
'aggregate_in_time_interval' : {
'time_interval_size' : interval,
'output' : 'avg',
'empty_intervals' : 'impute'
},
'blends' :
[{"id_blend" : "5e46c8cf9516297ce1ada712",
"blend_class" : "closest_observation",
"restriction":"None",
"blend_type":"text_ts",
"specifications":{"time_interval_size" : interval}
}],
'lag_feature' : {'feature' : 'change', 'periods' : [-1]}
}df = pd.read_json(json.dumps(OpenBlender.call(action, parameters)['sample']), convert_dates=False, convert_axes=False).sort_values('timestamp', ascending=False)
df.reset_index(drop=True, inplace=True)
这是与以前相同的调用,但带有一些新参数:
- aggregate_in_time_interval: 按24小时的平均间隔汇总数据,并估算是否存在没有观察到的间隔
- blends: 按时间加入汇总的24小时内的新闻数据
- lag_feature: 我们希望“change”功能与过去24小时内发生的新闻保持一致
让我们看一下数据的前几行:
print(df.shape)
df.head()
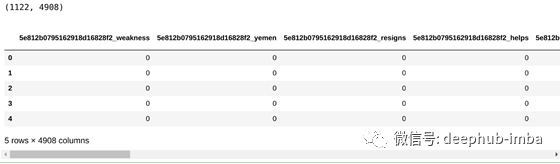
我们有1122个观测值和4908个特征。它们中的大多数是来自矢量化器的n-gram,而且我们还有原始的Apple Stock数据集。
“ lag-1_change”仅将“ change”值与“previous day data”对齐,这正是我们所需要的。最后一个观察结果是NaN,因为这就是“tomorrow”发生的情况。
现在,让我们按照之前的定义创建目标函数:
# Where ‘change’ decreased more than 0.5%
df['negative_poc'] = [1ifval<0.5else0forvalindf['lag-1_change']]# Where ‘change’ increased more than 0.5%
df['positive_poc'] = [1ifval>0.5else0forvalindf['lag-1_change']]df[['lag-1_change', 'positive_poc', 'negative_poc']].head()
步骤三:应用ML并进行拟合
我们需要2种模型,一种模型将预测价格是否会上涨(高于0.5%),另一种模型将预测当量下降,然后将两者合并到交易策略中。
另外,我们希望通过时间序列进行训练和测试,以便模型可以学习更多的信息。
最后,我们想模拟一下,如果我们以**$ 1,000美元**开始,最终会得到什么。
# First we create separeate dataframes for positive and negativedf_positive = df.select_dtypes(['number']).iloc[::-1]
forremin ['negative_poc']:
df_positive = df_positive.loc[:, df_positive.columns!= rem]df_negative = df.select_dtypes(['number']).iloc[::-1]
forremin ['positive_poc']:
df_negative = df_negative.loc[:, df_negative.columns!= rem]
给定一个数据集和一个目标,下面的函数将返回应用ML的结果以及具有预测与结果的表格。
defgetMetricsFromModel(target, df):
# Create train/test sets
X = df.loc[:, df.columns!= target]
X = X.loc[:, X.columns!= 'lag-1_change'].values
y = df.loc[:,[target]].values
# Create X and y.
div = int(round(len(X) *0.89))
real_values = df[div:].loc[:,['lag-1_change']].values
X_train = X[:div]
y_train = y[:div] X_test = X[div:]
y_test = y[div:]
# Perform ML
rf = RandomForestRegressor(n_estimators = 1000, random_state = 1)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
# Get Metrics
print("AUC score:")
auc = roc_auc_score(y_test, y_pred)
print(auc)
print('---') preds = [1ifval>0.6else0forvaliny_pred]
print('Confusion Matrix:')
conf_matrix = metrics.confusion_matrix(y_test, preds)
print(metrics.confusion_matrix(y_test, preds))
print('---')
print('Acurracy:')
acc = accuracy_score(y_test, preds)
print(acc)
print('---')
df_compare = pd.DataFrame({'real_values' : real_values.ravel(), 'y_test' : y_test.ravel(), 'preds' : y_pred})
returnauc, conf_matrix, acc, df_compare
我们希望通过300个观察值在时间上进行迭代学习,并在接下来的50天中进行预测,因此我们对每次跳跃进行重新训练。
在执行此操作时,我们希望从两个模型(负面/正面)中收集建议。
df_compare_acc = None
foriinrange(0, df_positive.shape[0] -450, 50):
print(i)
print(i+450)
print('-')
auc, conf_matrix, acc, df_compare_p = getMetricsFromModel('positive_poc', df_positive[i : i+450])
auc, conf_matrix, acc, df_compare_n = getMetricsFromModel('negative_poc', df_negative[i : i+450])
df_compare = df_compare_p[['y_test', 'real_values']]
df_compare.rename(columns={'y_test':'price_rised_5'}, inplace=True)
df_compare['F_p'] = df_compare_p['preds']
df_compare['price_dropped_5'] = df_compare_n['y_test']
df_compare['F_n'] = df_compare_n['preds']
df_compare
ifdf_compare_accisNone:
df_compare_acc = df_compare
else:
df_compare_acc = pd.concat([df_compare_acc, df_compare], ignore_index=True)
让我们看一下结果。
df_compare_acc
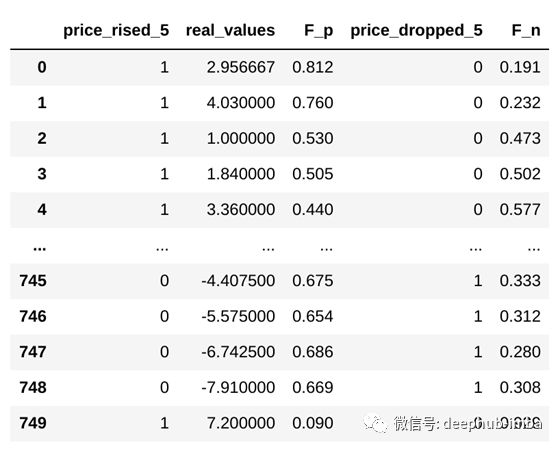
real_values = 价格的实际变化百分比
price_rised_5 = 如果变化> 0.5
F_p = 预测在(0,1)范围内上升
price_dropped_5 = 如果变化> -0.5
F_n =预测在(0,1)范围内变化
我们的组合模型将很简单,如果一种模型推荐而另一种模型不反对,则我们购买/做空:
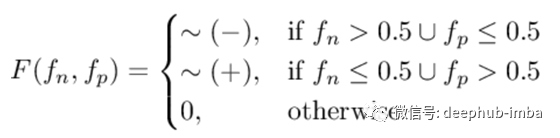
# This function will run a simulation on all the tested data
# given an invested 'starting_sum' and will return its
# trayectory.def runSimulation(include_pos, includle_neg, starting_sum):
sum_lst = []
actual_sum = starting_sum
forindex, rowindf_compare_acc.iterrows(): ifrow['F_p'] >0.5androw['F_n'] <0.5andinclude_pos:
actual_sum = actual_sum+ (actual_sum* (row['real_values'] /100)) ifrow['F_n'] >0.5androw['F_p'] <0.5andincludle_neg:
actual_sum = actual_sum- (actual_sum* (row['real_values'] /100)) sum_lst.append(actual_sum)
returnsum_lst
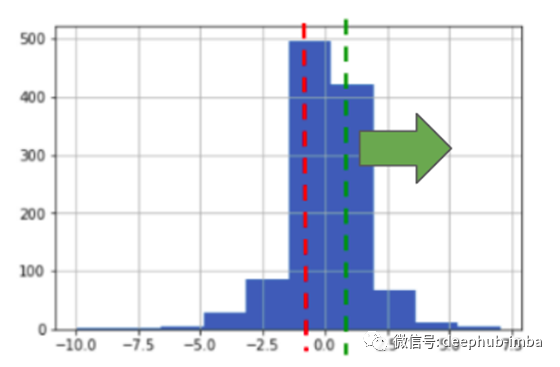
首先,我们仅使用“积极”预测运行模型。
sum_lst = runSimulation(True, False, 1000)
df_compare_acc['actual_sum'] = sum_lst
print(sum_lst[len(sum_lst)-1])
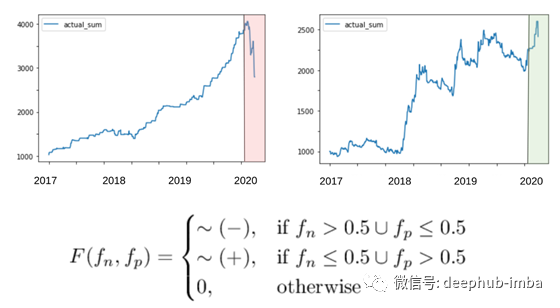
df_compare_acc.plot(y = ['actual_sum'])
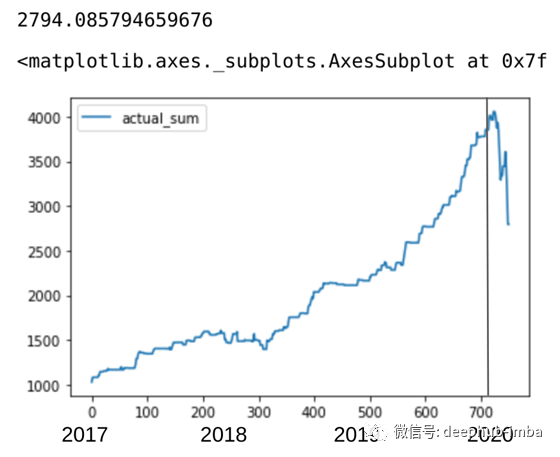
在目前的COVID /石油/经济衰退情况下,这些年来,它绝对暴跌,几乎损失了一半的收益。
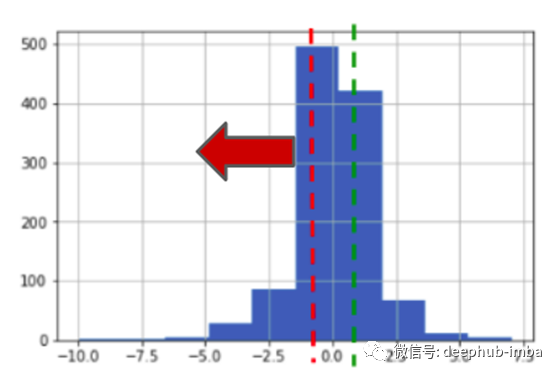
仅使用消极预测进行尝试。
sum_lst = runSimulation(False, True, 1000)
df_compare_acc['actual_sum'] = sum_lst
print(sum_lst[len(sum_lst)-1])
df_compare_acc.plot(y = ['actual_sum'])
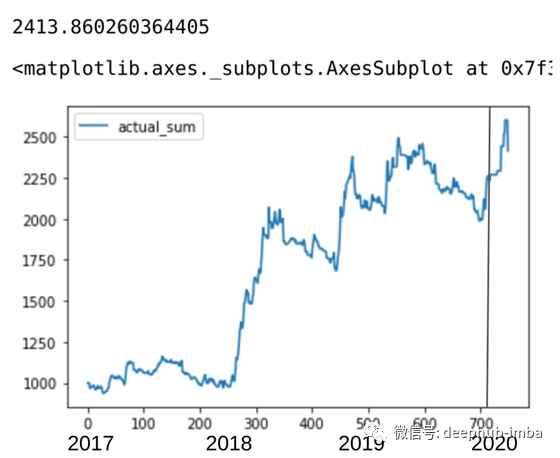
它的表现要比积极预测的表现差,但在某些情况下确实表现良好。
现在,让我们一起运行。
sum_lst = runSimulation(True, True, 1000)
df_compare_acc['actual_sum'] = sum_lst
print(sum_lst[len(sum_lst)-1])
df_compare_acc.plot(y = ['actual_sum'])
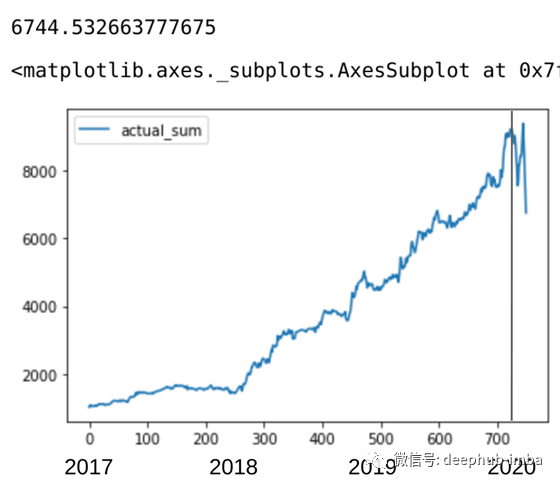
这是迄今为止表现最好的模型,在3年期结束时的回报率为574.4%,但这些天仍然非常不稳定。
至此,自1月20日结束以来,预测已下跌近25%,而苹果价格仅暴跌了20%。
下面需要做的是根据情况将积极预测或消极预测放在优先位置。
我们还会发布后续文章,其中包含模型的结果,该模型会根据增加或减少最大化回报的时间而在积极/消极预测之间进行切换。
作者:Federico Riveroll
deephub翻译组:孟翔杰
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********