
异常检测是对罕见的观测数据进行识别,这些观测数据具有与其他数据点截然不同的极值。这类的数据被称为异常值,需要被试别和区分。造成这些异常现象的原因有很多:数据的可变性、数据收集过程中获得的错误,或者发生了一些新的、罕见的情况。
管理这些离群值很有挑战性的,因为通常不可能理解问题是否与错误的数据收集有关还是因为其他原因。根据我们的目标需要决定移除还是保留这个异常值。如果异常点是由于新事件的发生而产生的,移除异常点意味着丢失信息。因为在这一种情况下,由于其稀有性,离群值包含了重要的新信息。
检测欺诈性金融交易、制造环境中的故障机器或恶意网络活动可以被认为是异常检测的应用。因此,异常检测的目标是建立一个能解释数据异常的模型。对这些反常行为的研究可用于银行和工业等公司的相关决策。
本文介绍的是使用孤立森林算法来检测异常。在2008年周志华老师提出了这种基于树的无监督非参数算法。实际上,它是由许多针对给定数据集的树组成的。孤立是这个算法的关键字,因为它将异常从其余的观察中隔离出来。这个隔离程序通过将区域随机分割成更小的块来分割所有的数据点。在我解释了这个算法的基础之后,我将使用Iris数据集展示使用scikit-learn的孤立森林应用。
孤立森林的工作原理
孤立森林与随机森林非常相似,它是基于给定数据集的决策树集成而建立的。然而,也有一些区别。孤立森林将异常识别为树上平均路径较短的观测结果。每个孤立树都应用了一个过程:
- 随机选择两个特征。
- 通过在所选特征的最大值和最小值之间随机选择一个值来分割数据点。
观察值的划分递归地重复,直到所有的观察值被孤立。
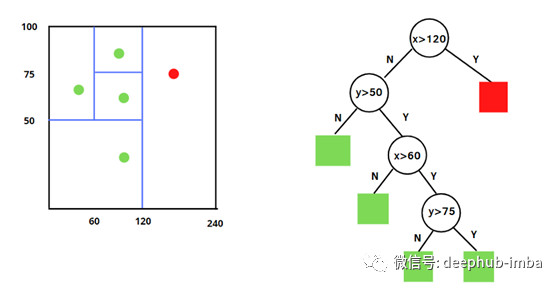
上面我分别展示了四次分割后的过程示例。在本例中我只需要检查两个特征x和y以及四个观察结果。第一个条件是区分正常观测和异常观测的条件。如果x大于120,则该观测值是一个异常值,用红色表示。然后,根据平均路径长度来区分正常和异常数据点:较短的路径表示异常,较长的路径表示正常的观测。
异常分数
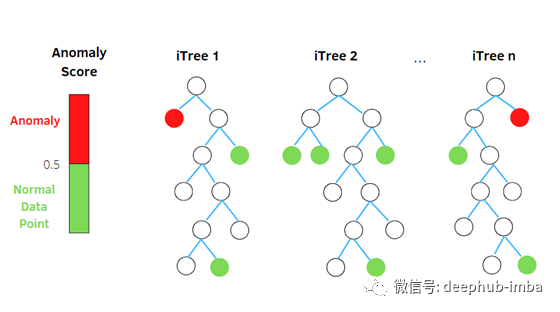
孤立森林需要一个异常值来了解一个数据点的异常程度。它的值在0和1之间。异常评分定义为:
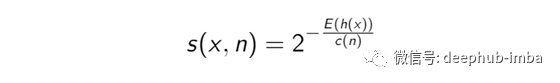
其中E(h(x))是根节点到外部节点x的路径长度h(x)的平均值,而c(n)是给定n的h(x)的平均值,用于规范化h(x)。有三种可能的情况:
- 当观测的得分接近1时,路径长度非常小,那么数据点很容易被孤立。我们有一个异常。
- 当观测值小于0.5时,路径长度就会变大,然后我们就得到了一个正常的数据点。
- 如果所有的观察结果都有0.5左右的异常值,那么整个样本就没有任何异常。
然后,孤立森林可以通过计算每棵树的异常得分,并在孤立树之间进行平均,从而在比正常观测更少的步骤中隔离异常。事实上,得分较高的异常值路径长度较低。
注:scikit-learn的隔离森林引入了异常分数的修改。异常值由负的分数表示,而正的分数意味着是正常的。
sklearn实现
让我们从sklearn开始这个示例:
import plotly.express as px
from sklearn.datasets import load_iris
from sklearn.ensemble import IsolationForest
导入库之后,我们将使用load_iris函数来读取iris数据集。我们的目标是检查数据集中的异常情况。
data = load_iris(as_frame=True)
X,y = data.data,data.target
df = data.frame
df.head()
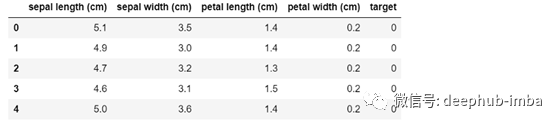
每个样本都有四个特征:萼片和花瓣的长度和宽度。这些特征将由孤立森林算法检测,以检查观测是否异常。
第二步是定义模型。有一些相关的超参数可以实例化类[2]:
- contamination是数据集中异常的比例。在本例中,我们把它固定为0。05。
- max_samples是从特征矩阵x中考虑的最大样本数。我们将使用所有样本。
- max_features是模型训练过程中可以考虑的最大特征数。我们将使用所有这四个特性。
- n_estimators是所考虑的孤立树的数量。我们将使用100个进行估计。
iforest = IsolationForest(n_estimators=100, max_samples='auto',
contamination=0.05, max_features=4,
bootstrap=False, n_jobs=-1, random_state=1)
定义了模型之后,就可以在数据上拟合模型并返回x的标签。这个任务是使用函数fit_predict完成的。下面的代码:
pred= iforest.fit_predict(X)
df['scores']=iforest.decision_function(X)
df['anomaly_label']=pred
我们可以使用函数decision_function找到异常分数,同时我们可以存储在预测中获得的标签。当标签等于-1时,它表示我们有异常。如果标签是1,就是正常的。
df[df.anomaly_label==-1]
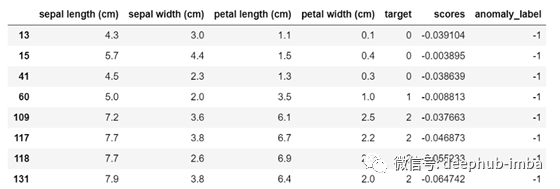
如果我们通过anomaly_label = -1来过滤数据集,我们可以观察到所有的分数在接近零的地方都是负的。在相反的情况下,当异常标签等于1时,我们发现所有的正分数。
df[df.anomaly_label==1]
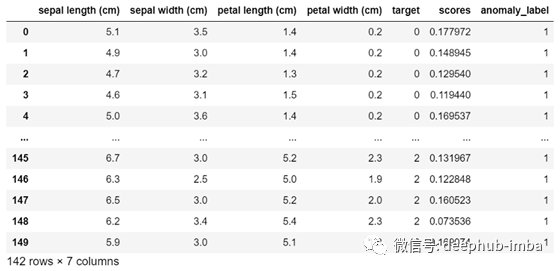
为了突出异常分数与通过预测得到的标签之间的这种关系,我们可以显示直方图。在创建直方图之前,我添加了一个表示异常状态的列:
df['anomaly']=df['anomaly_label'].apply(lambda x: 'outlier' if x==-1 else 'inlier')
fig=px.histogram(df,x='scores',color='anomaly')
fig.show()
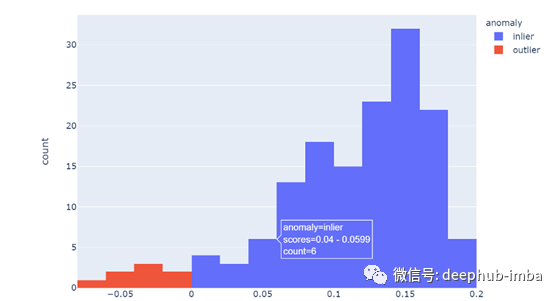
更明显的是,负分数的点是异常值。你不觉得吗?通过移动鼠标,您还可以看到带有特定异常分数的观察次数以及如何对观察进行分类。异常值的另一种有用表示是3D散点图,它拥有两个以上特征的视图。以下是如何创建散点图:
fig = px.scatter_3d(df,x='petal width (cm)',
y='sepal length (cm)',
z='sepal width (cm)',
color='anomaly')
fig.show()
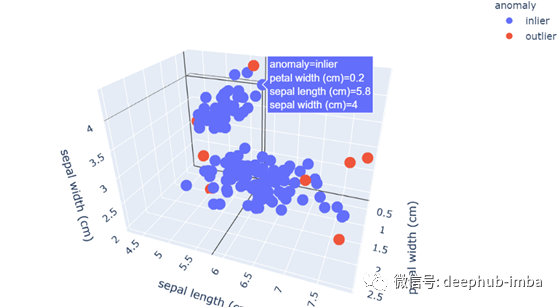
从这个散点图中,我们可以观察到作为离群点的红点具有数据集中特征的极值。
总结
我希望本指南能帮助您对异常检测和孤立森林的问题有一个概述。我想指定contamination超参数在这个算法中有相关的作用。当您修改它时,模型将返回相同比例的离群值,您需要仔细选择它。典型的值在0到0.5之间,但它也取决于数据集。
我也建议你使用plotly库显示图形,就像我在本教程中做的那样。它们比用seaborn和matplotlib获得的要详细得多。如果你需要完整代码,在这里查看https://github.com/eugeniaring/Isolation_Forest/blob/main/iForest.ipynb
引用
[1] Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008, December). Isolation forest. In Data Mining, 2008. ICDM’08. Eighth IEEE International Conference on (pp. 413–422). IEEE.
作者:Eugenia Anello
原文地址:https://betterprogramming.pub/anomaly-detection-with-isolation-forest-e41f1f55cc6
deephub翻译组