
目录
1🌲 二叉树的概念及结构
1.1 二叉树的概念
一棵二叉树是结点的一个有限集合,该集合有两种可能:
- 为空
- 由一个根结点和两棵分别名为左子树和右子树的二叉树组成
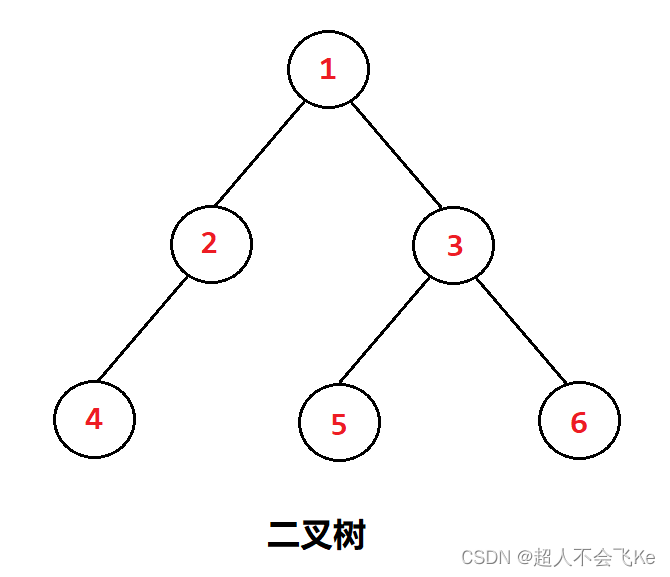
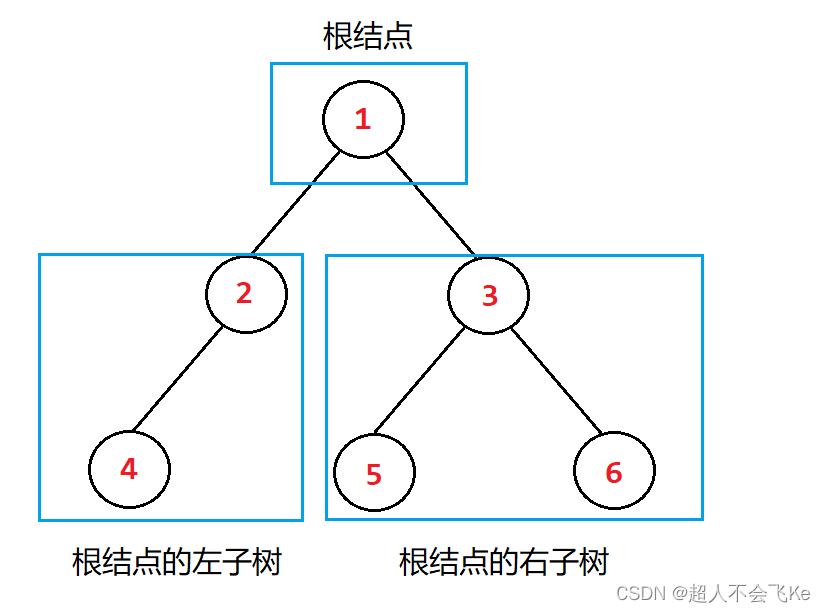
从上图我们得出结论:
- 二叉树中没有度大于2的结点
- 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
⭕对于二叉树层数的描述,一般地,我们定义二叉树的结点在第一层,那么空树的层次就是0,更加符合逻辑。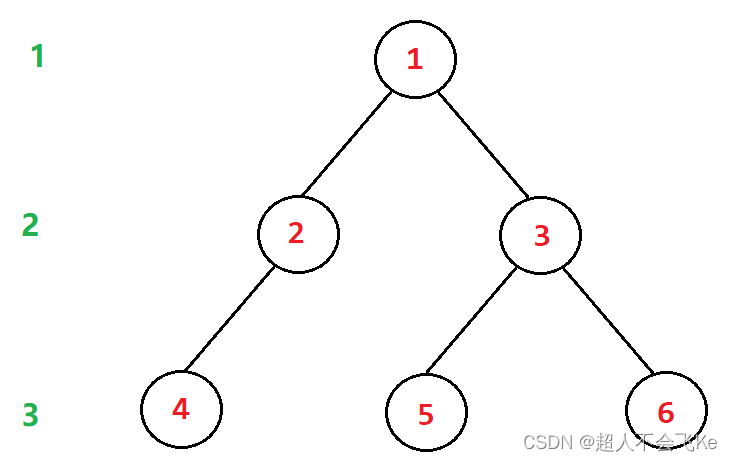
1.2 特殊的二叉树
- 满二叉树: 一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是 说,如果一个二叉树的层数为K,且结点总数是 ,则它就是满二叉树。
- 完全二叉树: 完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K 的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对 应时称之为完全二叉树。 通俗地理解,完全二叉树最后一层的结点必须是从左到右连续的,其他层的结点都是满的。 要注意的是满二叉树是一种特殊的完全二叉树。
⭕满二叉树一定是完全二叉树,二叉树不一定是满二叉树。
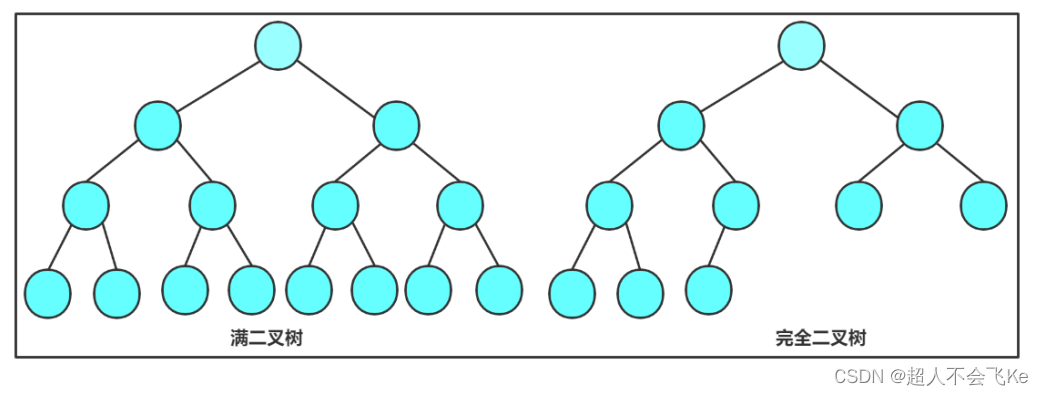
1.3 二叉树的性质
- 若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有 2i-1 个结点
- 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是 2h-1 (计算方法:20 +21+22+…+2h-1 = 2h-1)
- 对任何一棵二叉树,,如果度为0的叶结点个数为n0,度为2的分支结点个数为n2,则有 n0 = n2 + 1
- 完全二叉树中,假设总结点数为n,度为1的结点数为n1,则 当n为偶数时,n1 = 1,n为奇数时,n1 = 0
- 若规定根节点的层数为1,具有n个结点的满二叉树的深度, h = log(n+1) (ps:log(n+1)是log以2为底,n+1为对数)
- 若一颗二叉树的结点个数为n,则: n = n0+n1+n2,n-1 = 0n0 + 1n1 + 2*n2
- 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对于序号为i的结点有:
若i>0,i位置节点的双亲序号:**(i-1)/2**;i=0,i为根节点编号,无双亲节点
若2i+1<n,**左孩子序号:2i+1**,2i+1>=n否则无左孩子
若2i+2<n,**右孩子序号:2i+2**,2i+2>=n否则无右孩子
🔪小试牛刀
1️⃣某二叉树共有 399 个结点,其中有 199 个度为 2 的结点,则该二叉树中的叶子结点数为( )
A 不存在这样的二叉树
B 200
C 198
D 199

2️⃣在具有 2n 个结点的完全二叉树中,叶子结点个数为( )
A n
B n+1
C n-1
D n/2

3️⃣一棵完全二叉树的节点数位为531个,那么这棵树的高度为( )
A 11
B 10
C 8
D 12

1.4 二叉树的存储结构
💡 二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构
⭕图示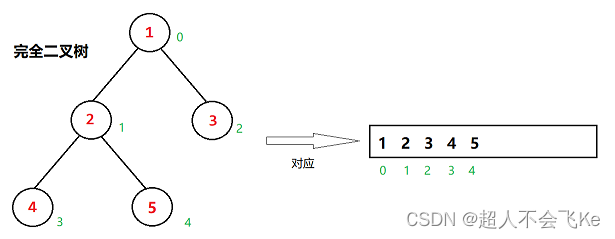
2. 链式结构
二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是
链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所
在的链结点的存储地址 。
⭕图示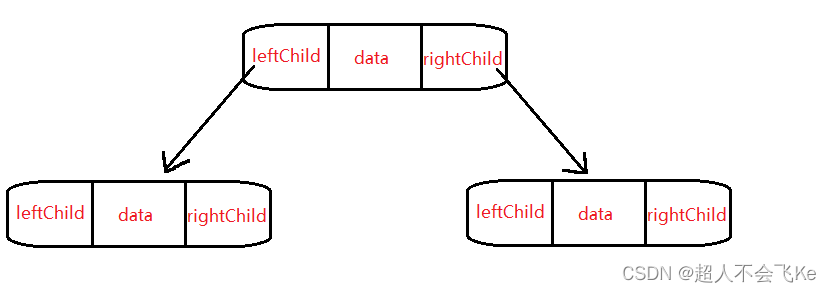
💬代码
typedefint DataType;structBinaryTreeNode{structBinaryTreeNode* leftChild;//指向当前结点左孩子structBinaryTreeNode* rightChild;//指向当前结点右孩子
DataType val;//当前结点数据域};
2🌲 二叉树的顺序结构及实现
2.1 二叉树的顺序结构
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
2.2 什么是堆?
堆是一种特殊的二叉树。
- 堆总是一颗完全二叉树
- 堆中某个节点的值总是不大于或不小于其父节点的值
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
⭕如图:
1. 小根堆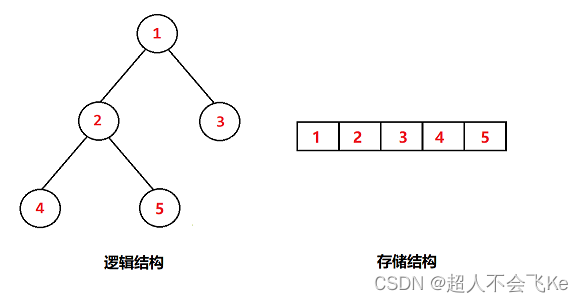
2. 大根堆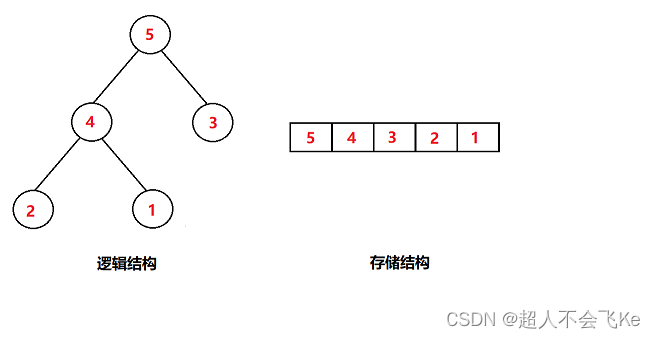
2.3 堆的实现
2.3.1 堆的向下、向上调整算法
1️⃣向下调整算法
💡在确保某个节点的左右子树都是一个堆的情况,我们可以对该节点进行向下调整。使其与它的左右子树合并成为一个新的堆。下面我们给出一个数组,逻辑上看它是一颗完全二叉树。
int a[]={27,15,19,18,28,34,65,49,25,37};
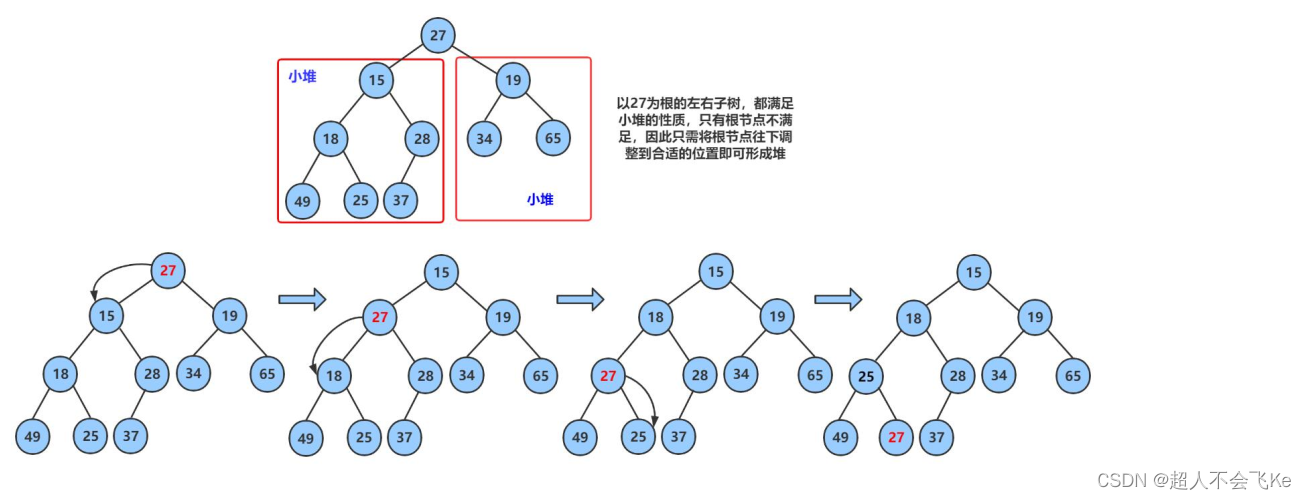
不仅是根节点可以进行向下调整,其他任何满足左右子树都是一个堆的节点都可以进行向下调整。
💬代码实现
voidSwap(int& a,int& b){int tmp = a;
a = b;
b = tmp;}// 向下调整算法voidAdjustDown(HeapDataType* a,int n,int parent){assert(a);int TheChild = parent *2+1;//while(TheChild < n)//孩子的范围必须在数组下标范围内{//找到最小(最大)孩子if(TheChild +1< n && a[TheChild +1]< a[TheChild])//根据建立大小堆改变符号{
TheChild++;}//判断:最小(最大)孩子和父亲是否交换if(a[TheChild]< a[parent]){Swap(a[parent], a[TheChild]);//移动父亲和孩子的下标
parent = TheChild;
TheChild = parent *2+1;}else//不用交换,则终止调整,跳出循环{break;}}}
1️⃣向上调整算法(堆的插入)
💡堆的向上调整算法主要运用于堆的插入。将一个元素插入一个堆,并且插入后依然还是一个堆,需要用到向上调整算法。向上调整会让插入元素找到自己适当的位置,使得插入后的堆成为一个新的堆。下面我们给出一个数组,逻辑上看它是一颗完全二叉树。
int a[]={15,18,19,25,28,34,65,49,27,37};
⭕插入的步骤图解如下 :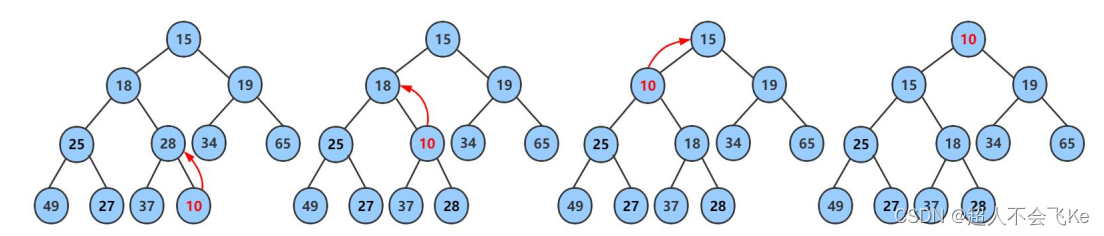
📍主要分为两步:
- 先将元素插到堆的末尾,既最后一个元素后面
- 向上调整,恢复堆结构
第一步很简单,只需将元素插入数组的最后一个位置即可。不过,插入前记得给数组扩容,否则将导致溢出。
⭕ 这里我们主要关注向上调整算法如何实现
💬代码实现
voidAdjustUp(int* a,int child){assert(a);int parent =(child -1)/2;while(child >0){if(a[child]< a[parent]){Swap(a[child], a[parent]);
child = parent;
parent =(child -1)/2;}else{break;}}}
2.3.2 堆的创建
💭了解了关于堆的两种算法,是时候应该建个堆出来玩玩了!那么,如何创建一个堆呢?我们试着用堆的向下、向上调整算法分别实现。
⭕下面我们给出一个数组,这个数组逻辑上可以看做一颗完全二叉树,但是还不是一个堆,现在我们通过算
法,把它构建成一个堆
(下面的建堆均默认为建大根堆)
。
int a[]={1,5,3,8,7,6};
💡根据向下调整的思想我们知道,若一颗完全二叉树的根节点左右都是堆,那么将该根节点向下调整后便能得到一个新的堆。我们可以想象下面这样的一棵树🌴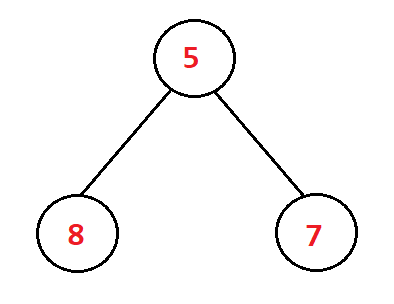
或是这样🌴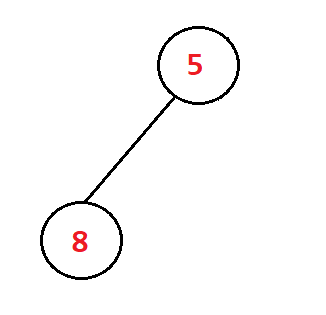
这是一颗很简单的树,左右子树都只有一个节点,甚至可以没有节点。那我们可以直接把左右子树都看成是一个堆(只有一个节点,符合堆的性质)。由此,我们只要将该树的根节点进行向下调整,整棵树就会变成一个新的堆了。
就像这样: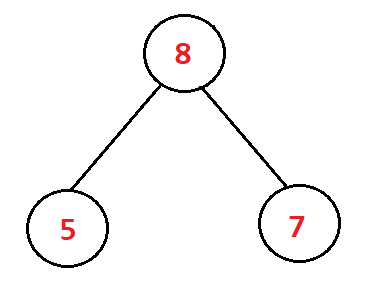
或是这样:
由特殊到普遍,每一颗二叉树不都是由多颗这样的小树构成的吗?
💡因此,我们不妨大事化小,从最后一个节点的父节点开始,按节点顺序从右到左从下到上依次向下调整。由于最下方的树向下调整一次后就变成堆了,我们再往上操作时,每棵树的根节点的左右子树都是堆,每次向下调整都是一个建堆的过程。最后每个节点都向下调整后,建堆完成。
⭕如图,由于树的最底层没有子树,因此无需调整。我们从最底层的上一层的最右边的节点(也就是最后一个节点的父节点)开始依次进行向下调整,直到整棵树的根节点调整完,堆就建出来了。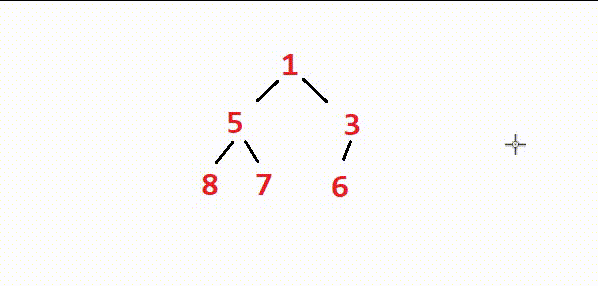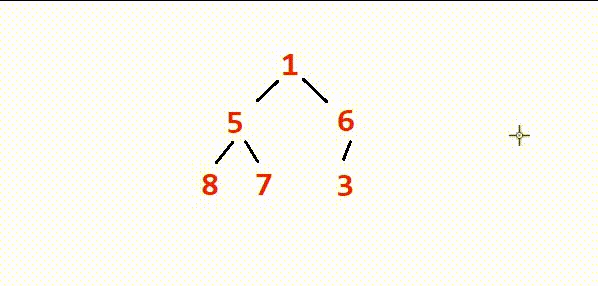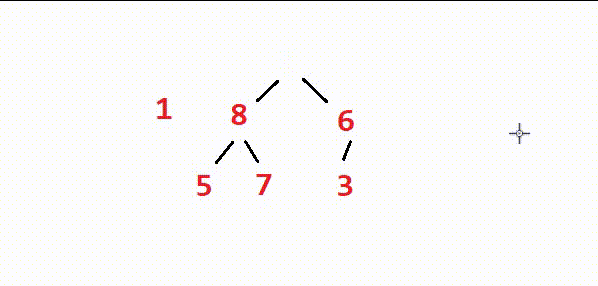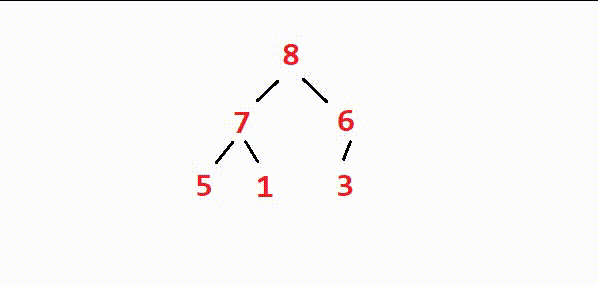
💬代码实现
//a {1,5,3,8,7,6}voidHeapCreat(HeapDataType* a,int n){assert(a);//找到第一个调整的节点int aN =((n -1)-1)/2;//第一个调整的节点往前的每个节点都要向下调整while(aN >=0){AdjustDown(a, n, aN);--aN;}}
⭕通过调试可以看到,a就被建成一个大根堆了。
2.3.3 堆创建的时间复杂度
💭因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果):
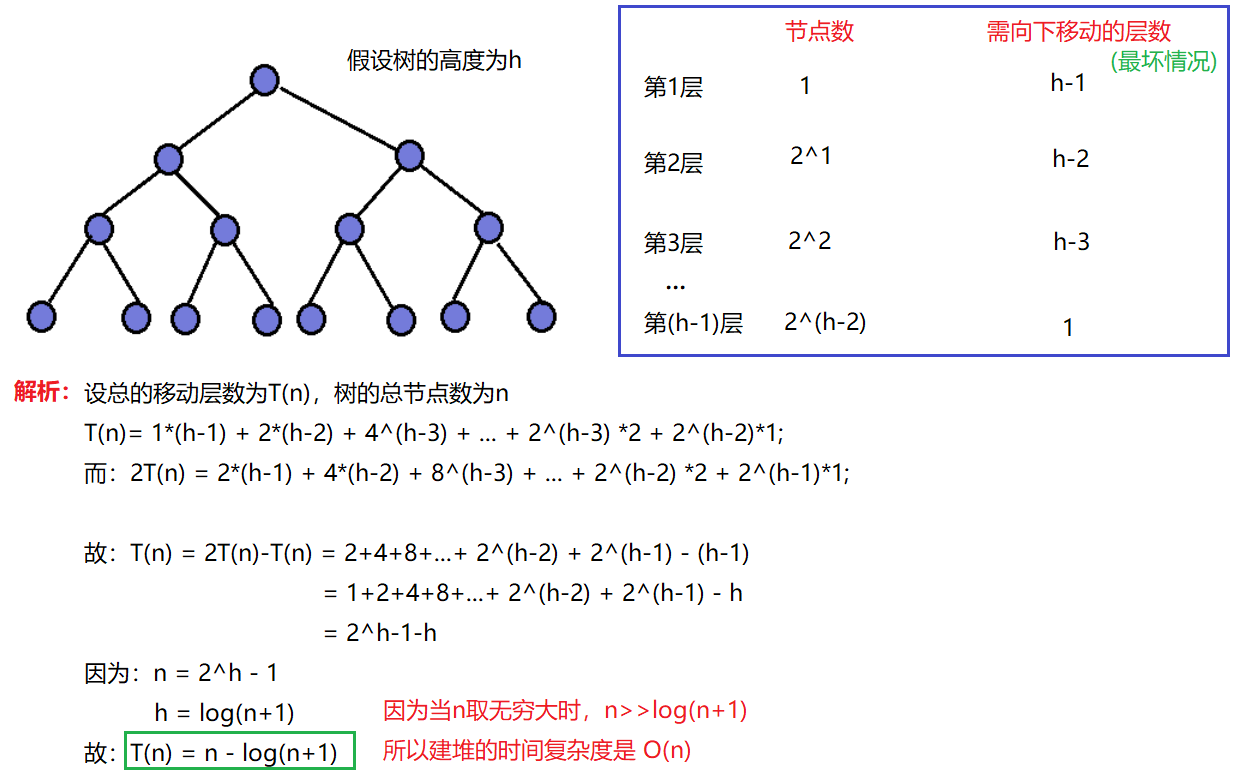
💭上面讨论的是用向下调整法建堆。如果用向上调整来建堆呢?我们先讨论向上调整建堆的时间复杂度。和向下调整建堆一样,我们先列出向上调整每一层的节点数和节点需要移动的层数

🔎可以看到,使用向上调整法建堆,随着节点数的增多,需向上调整的层数也随之增多,那么要是用上面的方法计算时间复杂度,向上调整法建堆的时间复杂度将会非常大。而向下调整建堆恰恰相反,随着节点数的增多,需向下调整的层数随之减少,所以其时间复杂度会相对小。因此,我们不必再讨论向上调整建队,而是选择用向下调整建堆,提高效率。
2.3.4 堆的删除
堆的删除是删除堆顶元素,且删除后堆的结构不能被破坏。这里的逻辑其实很简单,只需要将堆顶元素与堆的最后一个元素交换位置,然后删除最后一个元素,并从根节点开始向下调整即可。
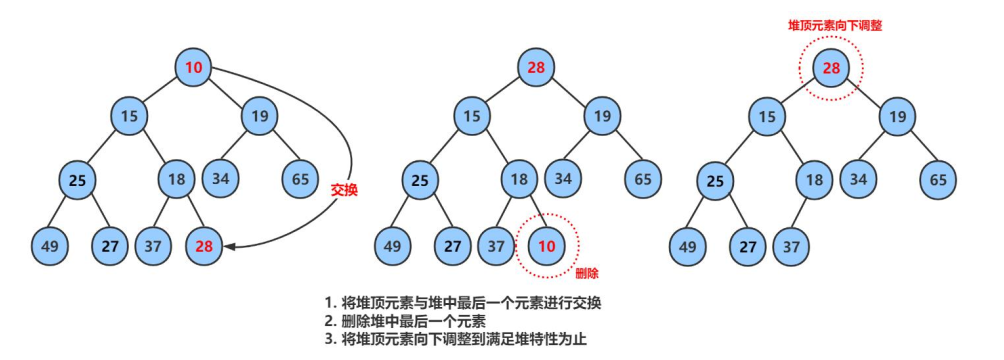
2.3.5 堆的总体代码实现
下面用C语言实现一下堆,及总结其各种接口
🍖Heap.h
#include<stdio.h>#include<stdlib.h>#include<assert.h>#include<stdbool.h>typedefint HeapDataType;typedefstruct{
HeapDataType* arr;int size;int capacity;}HP;voidHeapInit(HP* php);//堆的初始化voidHeapDestroy(HP* php);//堆的销毁voidHeapPrint(HP* php,int n);//打印堆//voidHeapPush(HP* php, HeapDataType x);//堆的插入voidHeapPop(HP* php);//堆的删除//
HeapDataType HeapTop(HP* php);//取堆顶的元素size_tHeapSize(HP* php);//取堆的元素个数
bool HeapIsEmpty(HP* php);//判断堆是否为空//voidAdjustDown(HeapDataType* arr,int n,int parent);voidAdjustUp(HeapDataType* arr,int child);voidSwap(HeapDataType* p1, HeapDataType* p2);
🍖Heap.c
#include"Heap.h"voidHeapInit(HP* php)//堆的初始化{assert(php);
php->capacity = php->size =0;
php->arr =NULL;}voidHeapDestroy(HP* php)//堆的销毁{assert(php);
php->capacity = php->size =0;free(php->arr);
php->arr =NULL;}voidHeapPrint(HP* php,int n)//打印堆{assert(php);for(int i =0;i < n;i++){printf("%d ", php->arr[i]);}printf("\n");}
bool HeapIsEmpty(HP* php)//判断堆是否为空{assert(php);return php->size ==0;}voidSwap(HeapDataType* p1, HeapDataType* p2)//交换数据{
HeapDataType tmp =*p1;*p1 =*p2;*p2 = tmp;}voidAdjustUp(HeapDataType* arr,int child)//向上调整{assert(arr);int parent =(child -1)/2;while(child >0){if(arr[parent]> arr[child])//1.{Swap(&arr[parent],&arr[child]);
child = parent;
parent =(child -1)/2;}else{break;}}}voidAdjustDown(HeapDataType* arr,int n,int parent)//向下调整{assert(arr);int TheChild = parent *2+1;while(TheChild < n){if(TheChild +1< n && arr[TheChild +1]> arr[TheChild])//根据建大堆还是小堆来确定符号{
TheChild++;}if(arr[TheChild]> arr[parent])//{Swap(&arr[TheChild],&arr[parent]);
parent = TheChild;
TheChild = parent *2+1;}else{break;}}}voidHeapPush(HP* php, HeapDataType x)//堆的插入{assert(php);//在尾部插入数据if(php->capacity == php->size){int newcapacity =(php->capacity ==0?4:2* php->capacity);
HeapDataType* tmp =(HeapDataType*)realloc(php->arr,sizeof(HeapDataType)* newcapacity);if(tmp ==NULL){perror("realloc fail");exit(-1);}//
php->arr = tmp;
php->capacity = newcapacity;}
php->arr[php->size]= x;
php->size++;//向上调整int child = php->size -1;AdjustUp(php->arr, child);}voidHeapPop(HP* php)//堆的删除{assert(php);assert(!HeapIsEmpty(php));//交换堆顶和最后一个数据并删除Swap(&php->arr[0],&php->arr[php->size -1]);
php->size--;//向下调整AdjustDown(php->arr, php->size,0);}
HeapDataType HeapTop(HP* php)//取堆顶的元素{assert(php);assert(!HeapIsEmpty(php));//return php->arr[0];}size_tHeapSize(HP* php)//取堆的元素个数{assert(php);return php->size;}
2.4 堆的应用
基于堆的特性,我们可以在不同的地方应用堆这个结构
2.4.1 堆排序
🍦堆排序就是运用堆进行排序,是一种比较高效的算法。实现堆排序分为两个步骤
- 建堆(升序建大堆,降序建小堆)
- 利用堆删除的思想进行排序
两个步骤都需要用到向下调整算法,因此掌握向下调整对堆排序的实现尤其重要。
⭕实现方法:
给定一个数组,要求将其排为升序:
int a[]={17,4,20,3,5,16};
⭕图示过程如下: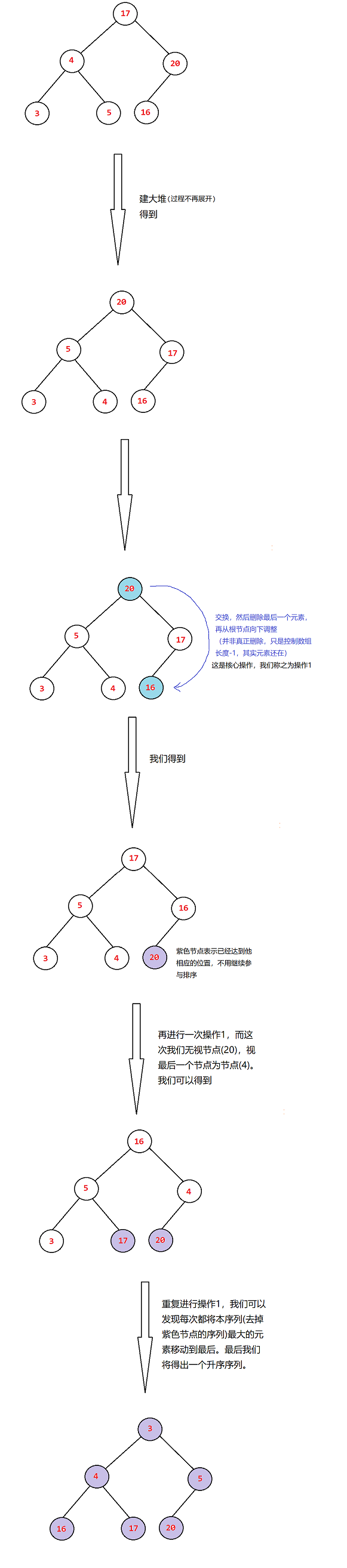
💬代码实现:
voidHeapSort(HeapDataType* a,int n){// 1.建堆HeapCreat(a, n);// 2.交换并删除int len = n;// len表示可更新的序列长度while(len >1){Swap(a[0], a[len -1]);//--len;//AdjustDown(a, len,0);}}
⭕堆排序的时间复杂度
建堆的时间复杂度是O(N)。交换后重建堆一共需要n-1次循环,每次循环的比较次数为log(i),则相加为:log2+log3+…+log(n-1)+log(n)≈log(n!)。由数学知识可以证明log(n!)和nlog(n)是同阶函数
因此,堆排序的时间复杂度为O(NlogN)
2.4.2 Top-K问题
TOP-K问题: 即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
例如:点外卖时搜索附件评分排名前十的饭店、找出游戏中段位排名前五的玩家…这些情况下往往数据量巨大,如果将所有数据排序后再取前K项,效率会非常慢,甚至数据都可能无法一次性全部加载到内存中。
💡然而,利用堆的特性,我们可以高效地解决Top-K问题,基本思路如下:
(假设我们要从N个数据中取出前K个最大元素)
- 取数据的前K个元素建一个小堆(求前K大建小堆,求前K小建大堆)
- 后(N-K)个数据依次与堆顶元素比较,比堆顶元素大就替换堆顶元素,并向下调整重构堆
💭ps:求前K个最小元素只需第一步改为建一个大堆,第二步比较条件换一下符合即可。
最后,堆中留存的元素就是前K个最大元素
💡该思路的原理是:假设前K个元素就是前K个最大元素,用他们建成一个小堆后,假设堆里的K个元素就是前K个最大元素,堆顶元素就是最小元素。我们再取后(N-K)个元素依次与堆顶元素比较,若是大于堆顶元素(最小元素),说明该堆顶元素并不属于前K个最大元素,则将其替换并向下调整,得到新的堆,新的前K个最大元素。堆顶元素还是最小元素。这样反复地比较、替换、调整,最后便能得到真正的前K个最大元素。
💬代码实现
voidPrintTopK(HeapDataType* a,int k,int n){// 1.建堆int* tmp =(int*)malloc(sizeof(HeapDataType)* k);if(tmp ==NULL){perror("malloc fail");exit(-1);}int i =0;for(i =0;i < k;i++){
tmp[i]= a[i];}HeapCreat(tmp, k);// 2.比较、替换、调整for(i = k;i < n;i++){if(a[i]> tmp[0]){
tmp[0]= a[i];AdjustDown(tmp, k,0);}}// 打印for(i =0;i < k;i++){printf("%d\n", tmp[i]);}}voidTestTopk(){int n =10000;int* a =(int*)malloc(sizeof(int)* n);srand(time(0));for(size_t i =0; i < n;++i){
a[i]=rand()%1000000;}
a[5]=1000000+1;
a[1231]=1000000+2;
a[531]=1000000+3;
a[5121]=1000000+4;
a[115]=1000000+5;
a[2335]=1000000+6;
a[9999]=1000000+7;
a[76]=1000000+8;
a[423]=1000000+9;
a[3144]=1000000+10;PrintTopK(a,10, n);}
⭕运行结果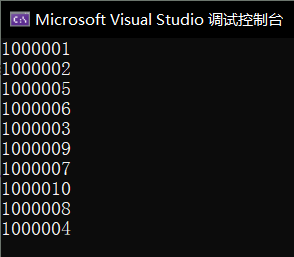
⭕复杂度解析
- 🏠 空间复杂度:O(K)
- 🕞 时间复杂度: O( K+(N-K)logK )
建堆时间复杂度O(N),后面(N-K)次循环,每次向下调整logK次
3🌲 二叉树的链式结构及实现
二叉树的链式结构在OJ题中十分常见。在对链式二叉树进行各种操作时,最最最核心的思想就是——递归。为了方便我们学习,先手动创建一颗链式二叉树,后续再用递归的方法建立链式二叉树。
typedefint BTDataType;typedefstructBinaryTreeNode{
BTDataType data;structBinaryTreeNode* left;structBinaryTreeNode* right;}BTNode;//
BTNode*BuyNode(BTDataType x){
BTNode* tmp =(BTNode*)malloc(sizeof(BTNode));if(tmp ==NULL){perror("malloc fail");exit(-1);}//
tmp->data = x;
tmp->left = tmp->right =NULL;}//
BTNode*CreatBinaryTree(){
BTNode* node1 =BuyNode(1);
BTNode* node2 =BuyNode(2);
BTNode* node3 =BuyNode(3);
BTNode* node4 =BuyNode(4);
BTNode* node5 =BuyNode(5);
BTNode* node6 =BuyNode(6);
node1->left = node2;
node1->right = node4;
node2->left = node3;
node4->left = node5;
node4->right = node6;return node1;}
🌲建出来的树如图所示: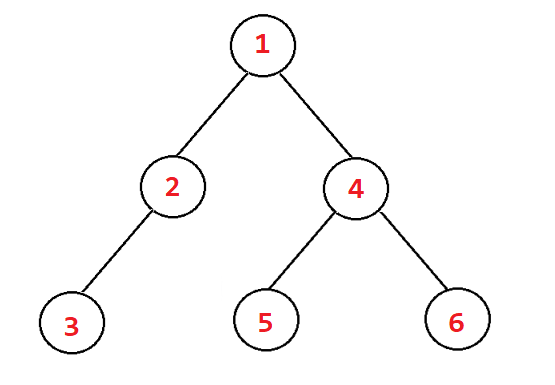
3.1 二叉树的遍历
3.1.1 前序、中序、后序遍历
🎈所谓二叉树遍历(Traversal)是按照某种特定的规则,依次对二叉树中的节点进行相应的操作,并且每个节点只操作一次。访问结点所做的操作依赖于具体的应用问题。 遍历是二叉树上最重要的运算之一,也是二叉树上进行其它运算的基础。
- 前序遍历(Preorder Traversal) —— 访问根结点的操作发生在遍历其左右子树之前。
- 中序遍历(Inorder Traversal) —— 访问根结点的操作发生在遍历其左右子树之中间。
- 后序遍历(Postorder Traversal) —— 访问根结点的操作发生在遍历其左右子树之后。
实现遍历的核心思想恰恰是递归思想
所谓递归,乃大事化小、小事化了,讲究分而治之的思想。
💬代码实现
//前序遍历voidPreOrder(BTNode* root){if(root ==NULL){return;}printf("%d->", root->data);PreOrder(root->left);PreOrder(root->right);}
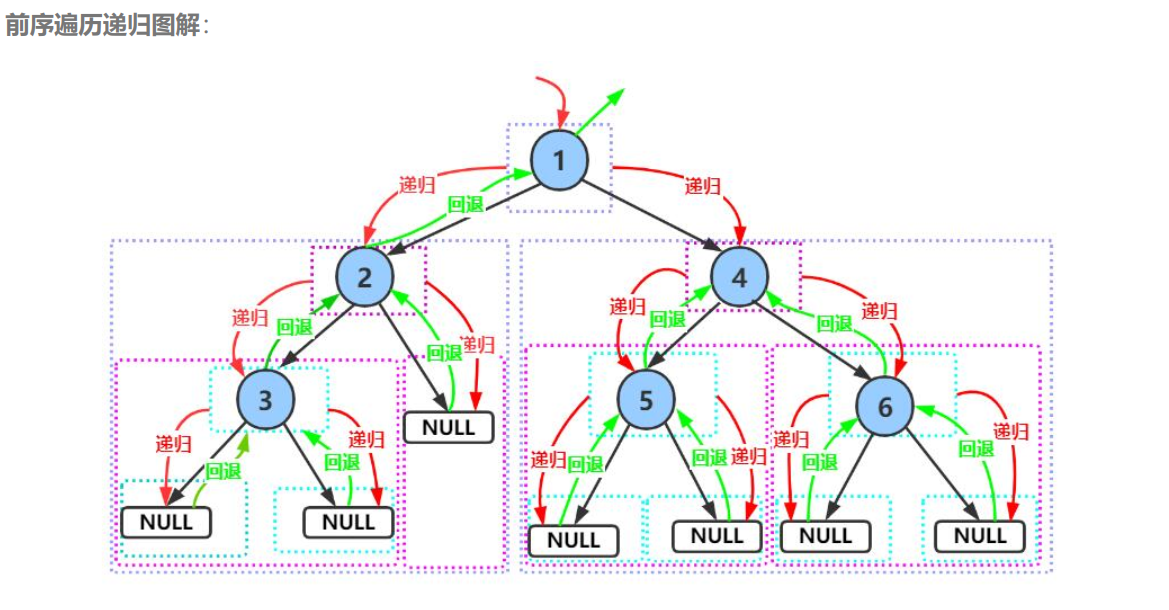
📃前序遍历递归展开图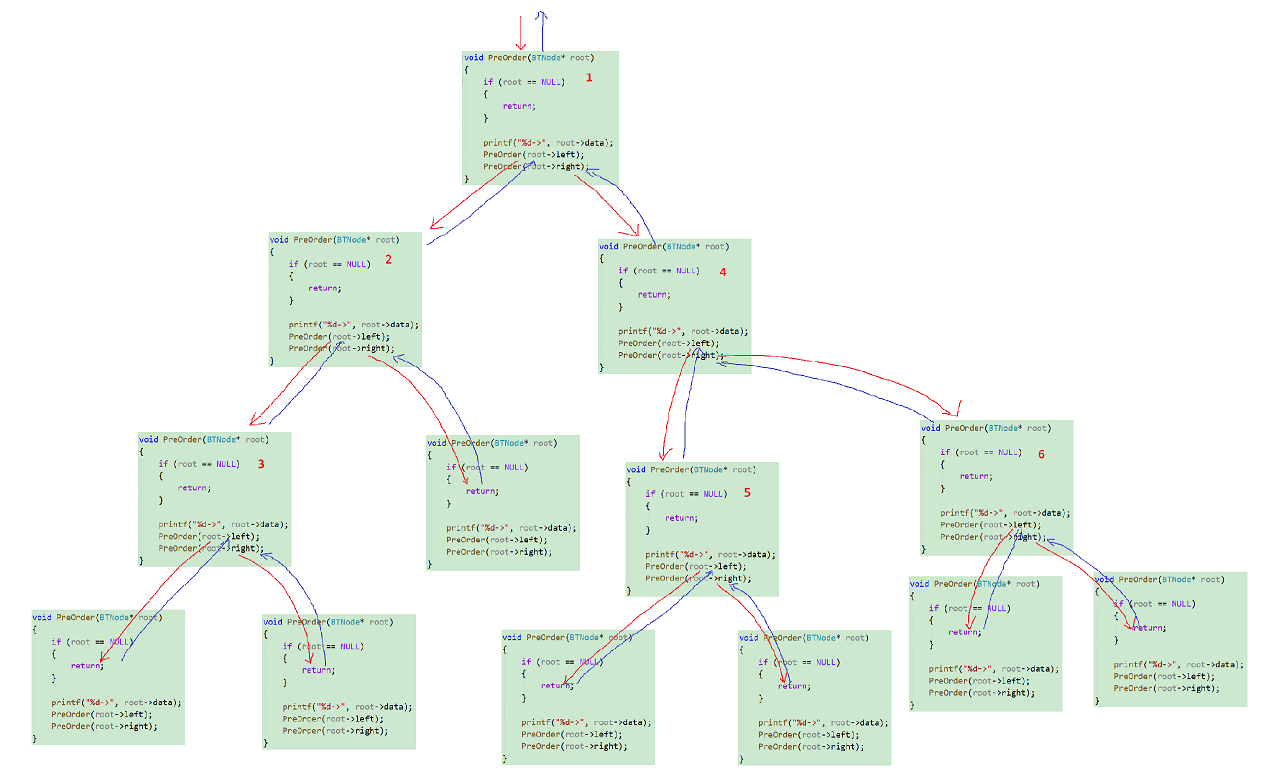
💨中序遍历和后序遍历的图解与前序遍历思路一致,不再展开。
//中序遍历voidInOrder(BTNode* root){if(root ==NULL){return;}InOrder(root->left);printf("%d ", root->data);InOrder(root->right);}//前序遍历voidPostOrder(BTNode* root){if(root ==NULL){return;}PostOrder(root->left);PostOrder(root->right);printf("%d ", root->data);}
⭕输出结果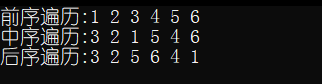
3.1.2 层序遍历
🏯除了前序、中序、后序遍历外,我们还可以对二叉树进行层序遍历。设二叉树根节点所在层数为第一层,层序遍历就是先从根节点出发,然后从左到又访问第二层(也就是根节点的子节点)的节点,接着再从左到右访问第三层的节点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
💡层序遍历需要用到另一个简单的数据结构 —— 队列
总体思路如下:
- 根节点入队
- 反复访问队头元素,每次访问结束后使其出队,并使他的左右节点依次入队
ps:队头元素为NULL时直接出队,更新队头元素
⭕过程如图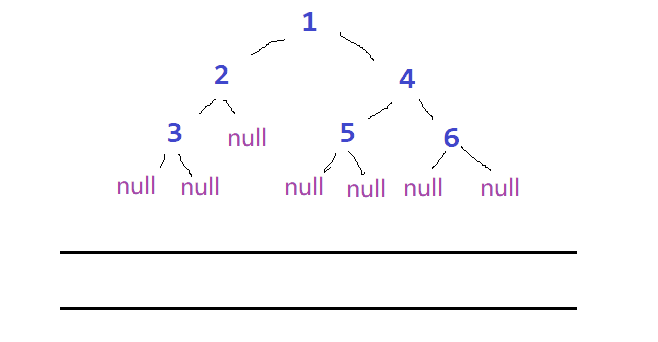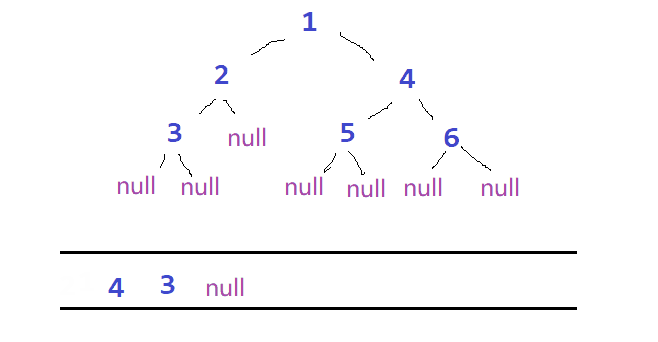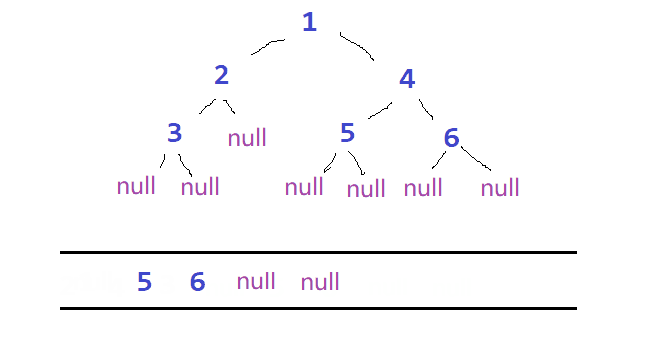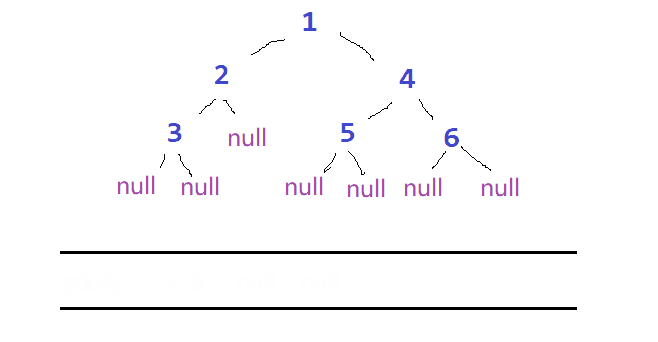
💬代码实现
//typedef BTNode* QueueDataType;//入队的是指向二叉树节点的指针voidLevelOrder(BTNode* root){
Queue q;QueueInit(&q);//QueuePush(&q, root);// 1. 根节点入队while(!QueueIsEmpty(&q))//队列为空时,停止循环{// 操作
QueueDataType head =QueueFront(&q);printf("%d ", head->data);// 弹出队头QueuePop(&q);// 压入队头的左右子节点if(head->left){QueuePush(&q, head->left);}if(head->right){QueuePush(&q, head->right);}}//QueueDestroy(&q);}
版权归原作者 超人不会飞Ke 所有, 如有侵权,请联系我们删除。