
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
深度神经网络已被证明在对大量标记数据进行监督学习的训练中是非常有效的。但是大多数现实世界的数据并没有被标记,并且进行全部标记也是不太现实的(需要大量的资源、时间和精力)。为了解决这个问题半监督学习 ( semi-supervised learning) 具有巨大实用价值。SSL 是监督学习和无监督学习的结合,它使用一小部分标记示例和大量未标记数据,模型必须从中学习并对新示例进行预测。基本过程涉及使用现有的标记数据来标记剩余的未标记数据,从而有效地帮助增加训练数据。图 1 显示了 SSL 的一般过程。
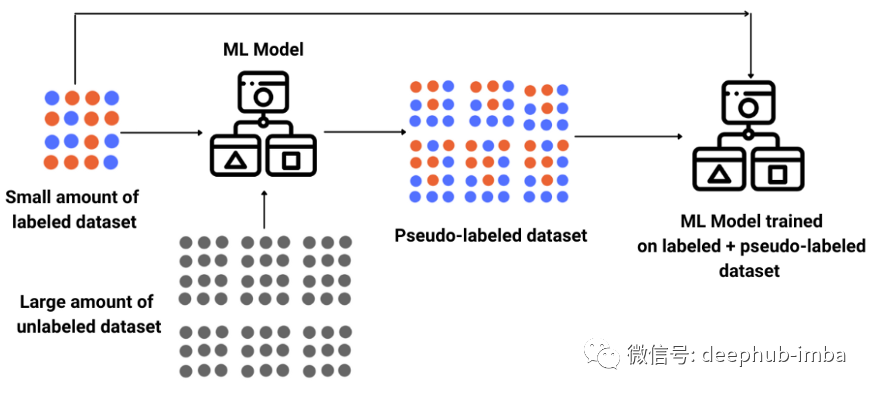
根据系统的目标函数,有几种类型的半监督系统,例如半监督分类、半监督聚类和半监督回归。在本文中,我们主要回顾图像的单标签分类。
SSL 中有两种主要的学习范式,transductive learning 和 inductive learning。
- transductive learning不会为整个输入空间构建分类器。所以此类系统没有单独的训练和测试阶段并仅限于对其进行训练的目标对象进行预测。
- inductive learning可以预测输入空间中的任何对象。这个分类器可以使用未标记的数据进行训练,但是一旦训练完成,它对之前未见对象的预测是相互独立的。
大多数基于图的方法都是transductive learning ,而大多数其他类型的 SSL 方法都是 inductive learning。
如果对数据的分布做出某些假设,SSL的性能可能会得到很大的改进。
- 自训练假设:具有高置信度的预测被认为是准确的
- 协同训练假设:实例 x 有两个条件独立的视图,每个视图都足以完成分类任务。
- 生成模型假设:当混合分量的数量、先验 p(y) 和条件分布 p(x|y) 正确时,可以假设数据来自混合模型。
- 聚类假设:同一簇中的两个点x1和x2应该被分成相同类。
- 低密度分割(Low-density separation):以低密度区域作为边界,而不是高密度区域(非黑既白)。
- 流形假设:如果两点x1和x2位于低维流形的局部邻域内,它们具有相似的类别标签。
半监督学习
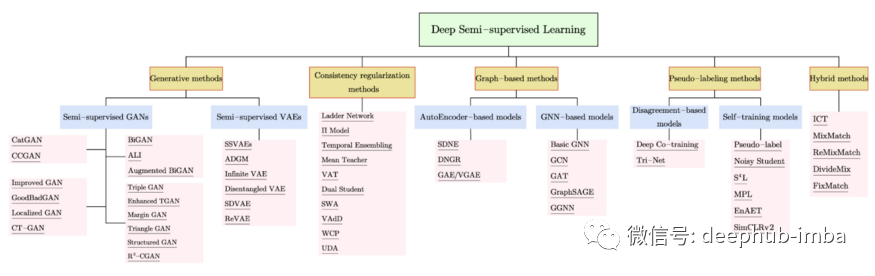
以下部分根据图 2 中的分类总结了一些最重要的半监督学习方法。
生成模型
GAN 是一种无监督模型。它包括一个在未标记数据上训练的生成模型,以及一个确定生成器质量的判别分类器。生成模型可以学习数据的隐含特征,然后根据相同的分布生成一组新的数据。换句话说,能够从数据分布P(x)生成数据的生成模型,必须学习可转移到目标为“y”的监督任务P(x|y)的特征。
半监督 GANS
GAN能够从未标记样本中了解真实数据的分布,这有利于SSL。在如何将GAN用于SSL方面有四个主要步骤。
- 重用鉴别器的特性
- 使用gan生成的样本来正则化分类器
- 使用GAN生成的样本作为额外的训练数据
- 学习新的训练推理模型
例如下面两个GAN的分支:
- CatGAN:Categorical Generative Adversarial Network (CatGAN) 修改了 GAN 的目标函数,以合并观察到的样本与其预测的分类分布之间的互信息。它的目标是训练一个鉴别器,通过将 y 标记到每个 x 来将样本区分为 K 个类别,而不是学习二元鉴别器值函数。
- CCGAN:Context-Conditional Generative Adversarial Networks (CCGAN) 使用对抗性损失来利用未标记图像数据的方法,例如图像修复。上下文信息由图像的周围部分提供。生成器经过训练以在缺失的图像片段中生成像素。
半监督 VAE
变分自动编码器 (VAE) 结合了深度自动编码器和生成潜在变量模型。VAE 是一个两阶段网络,一个编码器用于构建后验 P(z|x) 的变分逼近 Q(z|x),以及一个解码器来参数化似然。VAE 训练有两个目标——输入和重建版本之间的重建目标,以及遵循高斯分布的潜在空间的变分目标学习。
VAE 可以通过两个步骤用作半监督学习模型。首先使用未标记和标记数据训练 VAE 以提取潜在表示。第二步将标签向量补充到VAE的潜在表示中。标签向量包含标记数据点的真实标签,用于为未标记数据构建额外的潜在变量。
例如:
- SSVAE:Semi-supervised Sequential Variational Autoencoder由一个Seq2Seq结构和一个序列分类器组成。在Seq2Seq结构中,输入序列首先由一个递归神经网络进行编码,然后由另一个递归神经网络在潜变量和分类标签条件下进行解码。
- Infinite VAE:Mixture of an infinite number of autoencoders能够根据数据复杂性进行缩放,以更好地捕获其内在结构。使用无标记数据对无监督生成模型进行训练,然后将该模型与现有的有标记数据结合训练出判别模型。
基于图的方法
基于图的半监督学习(graph-based semi-supervised learning, GSSL)的主要思想是从原始数据中提取一个图,其中每个节点代表一个训练样本,边缘代表样本对的相似性度量。这个图包含了有标记的和未标记的样本,目标是将标记的数据从已标记的节点传播到未标记的节点。GSSL方法主要分为基于autocoder的方法和基于gnn的方法。
- Structural deep network embedding(SDNE):这是一种基于自动编码器的方法,由非监督部分和监督部分组成。第一个是自动编码器,设计用于生成每个节点的嵌入结果来重建邻域。第二部分利用拉普拉斯特征映射,在相关顶点相距较远时惩罚模型。
- 基本GNN:图神经网络 (GNN) 是一种分类器,它首先经过训练以预测标记节点的类标签。然后基于 GNN 模型的最终隐藏状态应用于未标记的节点。它利用了神经消息传递的优势,其中通过使用神经网络在每对节点之间交换和更新消息。
伪标签方法
伪标签方法分两步工作。第一步,在有限的标记数据集上训练模型。第二步利用相同的模型在未标记的数据上创建伪标签,并将高置信度的伪标签作为目标添加到现有的标记数据集中,从而创建额外的训练数据。
主要有两种模式,一种是集成多个不同网络来提高整个框架的性能,另一种是自训练。基于集成的方法训练多个学习者,并专注于利用训练过程中的不同结果。自训练算法利用模型自己的置信度预测为未标记数据生成伪标签。
- Pseudo-label(伪标签):这是一种简单有效的 SSL 方法,它允许网络同时使用标记和未标记的数据进行训练。模型使用交叉熵损失用标记数据进行训练并使用训练后的模型预测未标记的样本。将预测的最大置信度做伪标签。
- Noisy Student:这是一种半监督方法,用于使用相等或更大的学生模型进行知识蒸馏。教师模型首先在标记图像上进行训练用来生成未标记示例的伪标签。然后,对标记和伪标记样本的组合训练得到更大的学生模型。这些组合实例使用数据增强技术和模型噪声进行增强。通过该算法的多次迭代,学生模型成为新的教师模型并对未标记的数据进行重新标记,如此循环往复。
- SimCLRv2:这是 SimCLR的 SSL 版本。SimCLRv2 可以概括为三个步骤:与任务无关的无监督预训练,对标记样本进行监督微调,以及使用特定任务的未标记样本进行自训练或蒸馏。在预训练步骤中,SimCLRv2 通过最大化对比学习损失函数来学习表征。该损失函数是在成对样本上计算的基于距离的损失,理论是同一样本的增强视图在嵌入空间中应该更接近,而其余的应该远离。
混合方法
混合方法结合了上述方法的思想,如伪标签、熵最小化等等以提高性能。
- MixMatch:该方法将一致性正则化和熵最小化结合在一个统一的损失函数中。首先介绍了有标签数据和无标签数据的数据增强。每个未标记样本增强K次,然后平均不同增强的预测。为了减少熵,在提供最终标签之前,猜测的标签被锐化,然后将Mixup正则化应用于标记和未标记数据。
- FixMatch:该方法将一致性正则化和伪标记进行了简化。对于每一幅未标记图像,采用弱增强和强增强两种方法得到两幅图像。这两个增强都通过模型得到预测。然后将一致性正则化作为弱增强图像的一个one-hot伪标签与强增强图像的预测之间的交叉熵作为损失进行训练。
总结
SSL 方法与任何其他机器学习方法一样,也有其自身的一系列挑战:
- SSL 在内部如何工作目前还是黑盒,各种技术(如数据增强、训练方法和损失函数)究竟扮演什么角色也没有具体的确定。
- 上述 SSL 方法通常只有在训练数据集满足设计假设的理想环境中才能发挥最佳效果,但实际上,数据集的分布是未知的,不一定满足这些理想条件,可能会产生意想不到的结果。
- 如果训练数据高度不平衡,则模型倾向于偏爱多数类,并且在某些情况下完全忽略少数类。
- 与仅使用标记数据学习的模型相比,使用未标记数据可能会导致更差的泛化性能。
深度半监督学习已经在各种任务中取得了显著成果,并因其重要的实际应用而引起了研究界的广泛关注。我们将拭目以待,看看未来为我们准备了什么!
Based on:https://arxiv.org/pdf/2103.00550.pdf
论文作者::Xiangli Yang, Zixing Song, Irwin King, Fellow, IEEE, Zenglin Xu, Senior Member, IEEE*