
参考:
本项目 https://github.com/PromtEngineer/localGPT
模型 https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML
云端知识库项目:基于GPT-4和LangChain构建云端定制化PDF知识库AI聊天机器人_Entropy-Go的博客-CSDN博客
1. 摘要
相比OpenAI的LLM ChatGPT模型必须网络连接并通过API key云端调用模型,担心数据隐私安全。基于Llama2和LangChain构建本地化定制化知识库AI聊天机器人,是将训练好的LLM大语言模型本地化部署,在没有网络连接的情况下对你的文件提问。100%私有化本地化部署,任何时候都不会有数据离开您的运行环境。你可以在没有网络连接的情况下获取文件和提问!
介绍一款尖端应用,使用户能够在没有互联网连接的情况下利用语言模型的功能。这款先进工具作为一个不可或缺的资源,帮助用户在超越传统语言模型工具(如ChatGPT)的限制之外获取信息。
这个应用的一个关键优势在于数据控制的保留。当处理需要保持在组织内部或具有最高机密性的个人文件时,这个功能尤为重要,消除了通过第三方渠道传输信息的需求。
将个人文件无缝集成到系统中非常简单,确保用户体验流畅。无论是文本、PDF、CSV还是Excel文件,用户都可以方便地提供所需查询的信息。该应用程序快速处理这些文档,有效地创建了一个全面的数据库供模型利用,实现准确而深入的回答。
这种方法的一个显著优势在于其高效的资源利用。与替代方法中资源密集型的重新训练过程不同,这个应用程序中的文档摄取要求更少的计算资源。这种效率优化可以实现简化的用户体验,节省时间和计算资源。
体验这个技术奇迹的无与伦比的能力,使用户能够在离线状态下充分发挥语言模型的潜力。迎接信息获取的新时代,提高生产力,拓展可能性。拥抱这个强大的工具,释放您的数据的真正潜力。
2. 准备工作
2.1 Meta's Llama 2 7b Chat GGML
These files are GGML format model files for Meta's Llama 2 7b Chat.
GGML files are for CPU + GPU inference using llama.cpp and libraries and UIs which support this format
2.2 安装Conda
CentOS 上快速安装包管理工具Conda_Entropy-Go的博客-CSDN博客
2.3 升级gcc
CentOS gcc介绍及快速升级_Entropy-Go的博客-CSDN博客
3. 克隆或下载项目localGPT
git clone https://github.com/PromtEngineer/localGPT.git
4. 安装依赖包
4.1 Conda安装并激活
conda create -n localGPT
conda activate localGPT
4.2 安装依赖包
如果Conda环境变量正常设置,直接pip install
pip install -r requirements.txt
否则会使用系统自带的python,可以使用Conda的安装的绝对路径执行,后续都必须使用Conda的python
whereis conda
conda: /root/miniconda3/bin/conda /root/miniconda3/condabin/conda
/root/miniconda3/bin/pip install -r requirements.txt
安装时如遇下面问题,参考2.3 gcc升级,建议升级至gcc 11
ERROR: Could not build wheels for llama-cpp-python, hnswlib, lxml, which is required to install pyproject.toml-based project
5. 添加文档为知识库
5.1 文档目录以及模板文档
可以替换成需要的文档
~localGPT/SOURCE_DOCUMENTS/constitution.pdf
注入前验证下help,如前面提到,建议直接使用Conda绝对路径的python
/root/miniconda3/bin/python ingest.py --help
Usage: ingest.py [OPTIONS]
Options:
--device_type [cpu|cuda|ipu|xpu|mkldnn|opengl|opencl|ideep|hip|ve|fpga|ort|xla|lazy|vulkan|mps|meta|hpu|mtia]
Device to run on. (Default is cuda)
--help Show this message and exit.
5.2 开始注入文档
默认使用cuda/GPU
/root/miniconda3/bin/python ingest.py
可以指定CPU
/root/miniconda3/bin/python ingest.py --device_type cpu
首次注入时,会下载对应的矢量数据DB,矢量数据DB会存放到 /root/localGPT/DB
首次注入过程
/root/miniconda3/bin/python ingest.py
2023-08-18 09:36:55,389 - INFO - ingest.py:122 - Loading documents from /root/localGPT/SOURCE_DOCUMENTS
all files: ['constitution.pdf']
2023-08-18 09:36:55,398 - INFO - ingest.py:34 - Loading document batch
2023-08-18 09:36:56,818 - INFO - ingest.py:131 - Loaded 1 documents from /root/localGPT/SOURCE_DOCUMENTS
2023-08-18 09:36:56,818 - INFO - ingest.py:132 - Split into 72 chunks of text
2023-08-18 09:36:57,994 - INFO - SentenceTransformer.py:66 - Load pretrained SentenceTransformer: hkunlp/instructor-large
Downloading (…)c7233/.gitattributes: 100%|███████████████████████████████████████████████████████████████████████████| 1.48k/1.48k [00:00<00:00, 4.13MB/s]
Downloading (…)_Pooling/config.json: 100%|████████████████████████████████████████████████████████████████████████████████| 270/270 [00:00<00:00, 915kB/s]
Downloading (…)/2_Dense/config.json: 100%|████████████████████████████████████████████████████████████████████████████████| 116/116 [00:00<00:00, 380kB/s]
Downloading pytorch_model.bin: 100%|█████████████████████████████████████████████████████████████████████████████████| 3.15M/3.15M [00:01<00:00, 2.99MB/s]
Downloading (…)9fb15c7233/README.md: 100%|████████████████████████████████████████████████████████████████████████████| 66.3k/66.3k [00:00<00:00, 359kB/s]
Downloading (…)b15c7233/config.json: 100%|███████████████████████████████████████████████████████████████████████████| 1.53k/1.53k [00:00<00:00, 5.70MB/s]
Downloading (…)ce_transformers.json: 100%|████████████████████████████████████████████████████████████████████████████████| 122/122 [00:00<00:00, 485kB/s]
Downloading pytorch_model.bin: 100%|█████████████████████████████████████████████████████████████████████████████████| 1.34G/1.34G [03:15<00:00, 6.86MB/s]
Downloading (…)nce_bert_config.json: 100%|██████████████████████████████████████████████████████████████████████████████| 53.0/53.0 [00:00<00:00, 109kB/s]
Downloading (…)cial_tokens_map.json: 100%|███████████████████████████████████████████████████████████████████████████| 2.20k/2.20k [00:00<00:00, 8.96MB/s]
Downloading spiece.model: 100%|████████████████████████████████████████████████████████████████████████████████████████| 792k/792k [00:00<00:00, 3.46MB/s]
Downloading (…)c7233/tokenizer.json: 100%|███████████████████████████████████████████████████████████████████████████| 2.42M/2.42M [00:00<00:00, 3.01MB/s]
Downloading (…)okenizer_config.json: 100%|███████████████████████████████████████████████████████████████████████████| 2.41k/2.41k [00:00<00:00, 9.75MB/s]
Downloading (…)15c7233/modules.json: 100%|███████████████████████████████████████████████████████████████████████████████| 461/461 [00:00<00:00, 1.92MB/s]
load INSTRUCTOR_Transformer
2023-08-18 09:40:26,658 - INFO - instantiator.py:21 - Created a temporary directory at /tmp/tmp47gnnhwi
2023-08-18 09:40:26,658 - INFO - instantiator.py:76 - Writing /tmp/tmp47gnnhwi/_remote_module_non_scriptable.py
max_seq_length 512
2023-08-18 09:40:30,076 - INFO - init.py:88 - Running Chroma using direct local API.
2023-08-18 09:40:30,248 - WARNING - init.py:43 - Using embedded DuckDB with persistence: data will be stored in: /root/localGPT/DB
2023-08-18 09:40:30,252 - INFO - ctypes.py:22 - Successfully imported ClickHouse Connect C data optimizations
2023-08-18 09:40:30,257 - INFO - json_impl.py:45 - Using python library for writing JSON byte strings
2023-08-18 09:40:30,295 - INFO - duckdb.py:454 - No existing DB found in /root/localGPT/DB, skipping load
2023-08-18 09:40:30,295 - INFO - duckdb.py:466 - No existing DB found in /root/localGPT/DB, skipping load
2023-08-18 09:40:32,800 - INFO - duckdb.py:414 - Persisting DB to disk, putting it in the save folder: /root/localGPT/DB
2023-08-18 09:40:32,813 - INFO - duckdb.py:414 - Persisting DB to disk, putting it in the save folder: /root/localGPT/DB
项目文件列表
ls
ACKNOWLEDGEMENT.md CONTRIBUTING.md ingest.py localGPT_UI.py README.md run_localGPT.py
constants.py DB LICENSE __pycache__ requirements.txt SOURCE_DOCUMENTS
constitution.pdf Dockerfile localGPTUI pyproject.toml run_localGPT_API.py
6. 运行知识库AI聊天机器人
现在可以和你的本地化知识库开始对话聊天了!
6.1 命令行方式运行提问
首次运行时,会下载对应的默认模型 ~/localGPT/constants.py
# model link: https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML
MODEL_ID = "TheBloke/Llama-2-7B-Chat-GGML"
MODEL_BASENAME = "llama-2-7b-chat.ggmlv3.q4_0.bin"
模型会下载到 /root/.cache/huggingface/hub/models--TheBloke--Llama-2-7B-Chat-GGML
直接运行
/root/miniconda3/bin/python run_localGPT.py
对话输入
支持英文,中文需要加utf-8进行处理
Enter a query:
对话记录
/root/miniconda3/bin/python run_localGPT.py
2023-08-18 09:43:02,433 - INFO - run_localGPT.py:180 - Running on: cuda
2023-08-18 09:43:02,433 - INFO - run_localGPT.py:181 - Display Source Documents set to: False
2023-08-18 09:43:02,676 - INFO - SentenceTransformer.py:66 - Load pretrained SentenceTransformer: hkunlp/instructor-large
load INSTRUCTOR_Transformer
max_seq_length 512
2023-08-18 09:43:05,301 - INFO - init.py:88 - Running Chroma using direct local API.
2023-08-18 09:43:05,317 - WARNING - init.py:43 - Using embedded DuckDB with persistence: data will be stored in: /root/localGPT/DB
2023-08-18 09:43:05,328 - INFO - ctypes.py:22 - Successfully imported ClickHouse Connect C data optimizations
2023-08-18 09:43:05,336 - INFO - json_impl.py:45 - Using python library for writing JSON byte strings
2023-08-18 09:43:05,402 - INFO - duckdb.py:460 - loaded in 72 embeddings
2023-08-18 09:43:05,405 - INFO - duckdb.py:472 - loaded in 1 collections
2023-08-18 09:43:05,406 - INFO - duckdb.py:89 - collection with name langchain already exists, returning existing collection
2023-08-18 09:43:05,406 - INFO - run_localGPT.py:45 - Loading Model: TheBloke/Llama-2-7B-Chat-GGML, on: cuda
2023-08-18 09:43:05,406 - INFO - run_localGPT.py:46 - This action can take a few minutes!
2023-08-18 09:43:05,406 - INFO - run_localGPT.py:50 - Using Llamacpp for GGML quantized models
Downloading (…)chat.ggmlv3.q4_0.bin: 100%|███████████████████████████████████████████████████████████████████████████| 3.79G/3.79G [09:53<00:00, 6.39MB/s]
llama.cpp: loading model from /root/.cache/huggingface/hub/models--TheBloke--Llama-2-7B-Chat-GGML/snapshots/b616819cd4777514e3a2d9b8be69824aca8f5daf/llama-2-7b-chat.ggmlv3.q4_0.bin
llama_model_load_internal: format = ggjt v3 (latest)
llama_model_load_internal: n_vocab = 32000
llama_model_load_internal: n_ctx = 2048
llama_model_load_internal: n_embd = 4096
llama_model_load_internal: n_mult = 256
llama_model_load_internal: n_head = 32
llama_model_load_internal: n_layer = 32
llama_model_load_internal: n_rot = 128
llama_model_load_internal: ftype = 2 (mostly Q4_0)
llama_model_load_internal: n_ff = 11008
llama_model_load_internal: n_parts = 1
llama_model_load_internal: model size = 7B
llama_model_load_internal: ggml ctx size = 0.07 MB
llama_model_load_internal: mem required = 5407.71 MB (+ 1026.00 MB per state)
llama_new_context_with_model: kv self size = 1024.00 MB
AVX = 1 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |Enter a query:
或者添加参数**--show_sources**,回答时显示引用章节信息
/root/miniconda3/bin/python run_localGPT.py --show_sources
对话记录:
/root/miniconda3/bin/python run_localGPT.py --show_sources
2023-08-18 10:03:55,466 - INFO - run_localGPT.py:180 - Running on: cuda
2023-08-18 10:03:55,466 - INFO - run_localGPT.py:181 - Display Source Documents set to: True
2023-08-18 10:03:55,708 - INFO - SentenceTransformer.py:66 - Load pretrained SentenceTransformer: hkunlp/instructor-large
load INSTRUCTOR_Transformer
max_seq_length 512
2023-08-18 10:03:58,302 - INFO - init.py:88 - Running Chroma using direct local API.
2023-08-18 10:03:58,307 - WARNING - init.py:43 - Using embedded DuckDB with persistence: data will be stored in: /root/localGPT/DB
2023-08-18 10:03:58,312 - INFO - ctypes.py:22 - Successfully imported ClickHouse Connect C data optimizations
2023-08-18 10:03:58,318 - INFO - json_impl.py:45 - Using python library for writing JSON byte strings
2023-08-18 10:03:58,372 - INFO - duckdb.py:460 - loaded in 72 embeddings
2023-08-18 10:03:58,373 - INFO - duckdb.py:472 - loaded in 1 collections
2023-08-18 10:03:58,373 - INFO - duckdb.py:89 - collection with name langchain already exists, returning existing collection
2023-08-18 10:03:58,374 - INFO - run_localGPT.py:45 - Loading Model: TheBloke/Llama-2-7B-Chat-GGML, on: cuda
2023-08-18 10:03:58,374 - INFO - run_localGPT.py:46 - This action can take a few minutes!
2023-08-18 10:03:58,374 - INFO - run_localGPT.py:50 - Using Llamacpp for GGML quantized models
llama.cpp: loading model from /root/.cache/huggingface/hub/models--TheBloke--Llama-2-7B-Chat-GGML/snapshots/b616819cd4777514e3a2d9b8be69824aca8f5daf/llama-2-7b-chat.ggmlv3.q4_0.bin
llama_model_load_internal: format = ggjt v3 (latest)
llama_model_load_internal: n_vocab = 32000
llama_model_load_internal: n_ctx = 2048
llama_model_load_internal: n_embd = 4096
llama_model_load_internal: n_mult = 256
llama_model_load_internal: n_head = 32
llama_model_load_internal: n_layer = 32
llama_model_load_internal: n_rot = 128
llama_model_load_internal: ftype = 2 (mostly Q4_0)
llama_model_load_internal: n_ff = 11008
llama_model_load_internal: n_parts = 1
llama_model_load_internal: model size = 7B
llama_model_load_internal: ggml ctx size = 0.07 MB
llama_model_load_internal: mem required = 5407.71 MB (+ 1026.00 MB per state)
llama_new_context_with_model: kv self size = 1024.00 MB
AVX = 1 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |Enter a query: how many times could president act, and how many years as max?
llama_print_timings: load time = 19737.32 ms
llama_print_timings: sample time = 101.14 ms / 169 runs ( 0.60 ms per token, 1671.02 tokens per second)
llama_print_timings: prompt eval time = 19736.91 ms / 925 tokens ( 21.34 ms per token, 46.87 tokens per second)
llama_print_timings: eval time = 36669.35 ms / 168 runs ( 218.27 ms per token, 4.58 tokens per second)
llama_print_timings: total time = 56849.80 msQuestion:
how many times could president act, and how many years as max?Answer:
The answer to this question can be found in Amendment XXII and Amendment XXIII of the US Constitution. According to these amendments, a person cannot be elected President more than twice, and no person can hold the office of President for more than two years of a term to which someone else was elected President. However, if the President is unable to discharge their powers and duties due to incapacity, the Vice President will continue to act as President until Congress determines the issue.
In summary, a person can be elected President at most twice, and they cannot hold the office for more than two years of a term to which someone else was elected President. If the President becomes unable to discharge their powers and duties, the Vice President will continue to act as President until Congress makes a determination.
----------------------------------SOURCE DOCUMENTS---------------------------/root/localGPT/SOURCE_DOCUMENTS/constitution.pdf:
Amendment XXII.Amendment XXIII.
Passed by Congress March 21, 1947. Ratified February 27,
Passed by Congress June 16, 1960. Ratified March 29, 1961.
SECTION 1
...
SECTION 2
....
----------------------------------SOURCE DOCUMENTS---------------------------
Enter a query: exit
6.2 Web UI方式运行提问
6.2.1 启动服务器端API
可以使用Web UI方式运行,启动服务器端API在5110端口上进行监听服务
/root/miniconda3/bin/python run_localGPT_API.py
如果执行过程遇到下面问题,还是代码中的python没有使用Conda PATH下面的python导致的。
/root/miniconda3/bin/python run_localGPT_API.py
load INSTRUCTOR_Transformer
max_seq_length 512
The directory does not exist
run_langest_commands ['python', 'ingest.py']
Traceback (most recent call last):
File "/root/localGPT/run_localGPT_API.py", line 56, in <module>
raise FileNotFoundError(
FileNotFoundError: No files were found inside SOURCE_DOCUMENTS, please put a starter file inside before starting the API!
可以修改~/localGPT/run_localGPT_API.py中的python为Conda下的路径
run_langest_commands = ["python", "ingest.py"]
修改为
run_langest_commands = ["/root/miniconda3/bin/python", "ingest.py"]
运行过程
看到 INFO:werkzeug: 表示启动成功,窗口可以保留座位debug用途
/root/miniconda3/bin/python run_localGPT_API.py
load INSTRUCTOR_Transformer
max_seq_length 512
WARNING:chromadb:Using embedded DuckDB with persistence: data will be stored in: /root/localGPT/DB
llama.cpp: loading model from /root/.cache/huggingface/hub/models--TheBloke--Llama-2-7B-Chat-GGML/snapshots/b616819cd4777514e3a2d9b8be69824aca8f5daf/llama-2-7b-chat.ggmlv3.q4_0.bin
llama_model_load_internal: format = ggjt v3 (latest)
llama_model_load_internal: n_vocab = 32000
llama_model_load_internal: n_ctx = 2048
llama_model_load_internal: n_embd = 4096
llama_model_load_internal: n_mult = 256
llama_model_load_internal: n_head = 32
llama_model_load_internal: n_layer = 32
llama_model_load_internal: n_rot = 128
llama_model_load_internal: ftype = 2 (mostly Q4_0)
llama_model_load_internal: n_ff = 11008
llama_model_load_internal: n_parts = 1
llama_model_load_internal: model size = 7B
llama_model_load_internal: ggml ctx size = 0.07 MB
llama_model_load_internal: mem required = 5407.71 MB (+ 1026.00 MB per state)
llama_new_context_with_model: kv self size = 1024.00 MB
AVX = 1 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
- Serving Flask app 'run_localGPT_API'
- Debug mode: on
INFO:werkzeug:WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.- Running on http://127.0.0.1:5110
INFO:werkzeug:Press CTRL+C to quit
INFO:werkzeug: * Restarting with watchdog (inotify)
6.2.2 启动服务器端UI
重新打开一个新的命令行终端,运行~/localGPT/localGPTUI/localGPTUI.py,启动服务器端UI在5111端口上进行监听服务
/root/miniconda3/bin/python localGPTUI.py
如需局域网访问,修改localGPTUI.py,127.0.0.1 -> 0.0.0.0
parser.add_argument("--host", type=str, default="0.0.0.0",
help="Host to run the UI on. Defaults to 127.0.0.1. "
"Set to 0.0.0.0 to make the UI externally "
"accessible from other devices.")
运行记录
/root/miniconda3/bin/python localGPTUI.py
- Serving Flask app 'localGPTUI'
- Debug mode: on
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.- Running on all addresses (0.0.0.0)
*** Running on http://127.0.0.1:5111
- Running on http://IP:5111**
端口使用情况
netstat -nltp | grep 511
tcp 0 0 127.0.0.1:5110 0.0.0.0:* LISTEN 57479/python
tcp 0 0 0.0.0.0:5111 0.0.0.0:* LISTEN 21718/python
6.2.3 浏览器访问Web UI
局域网: http://IP:5111
网页端可以进行自由对话,支持中文输入。
使用截图
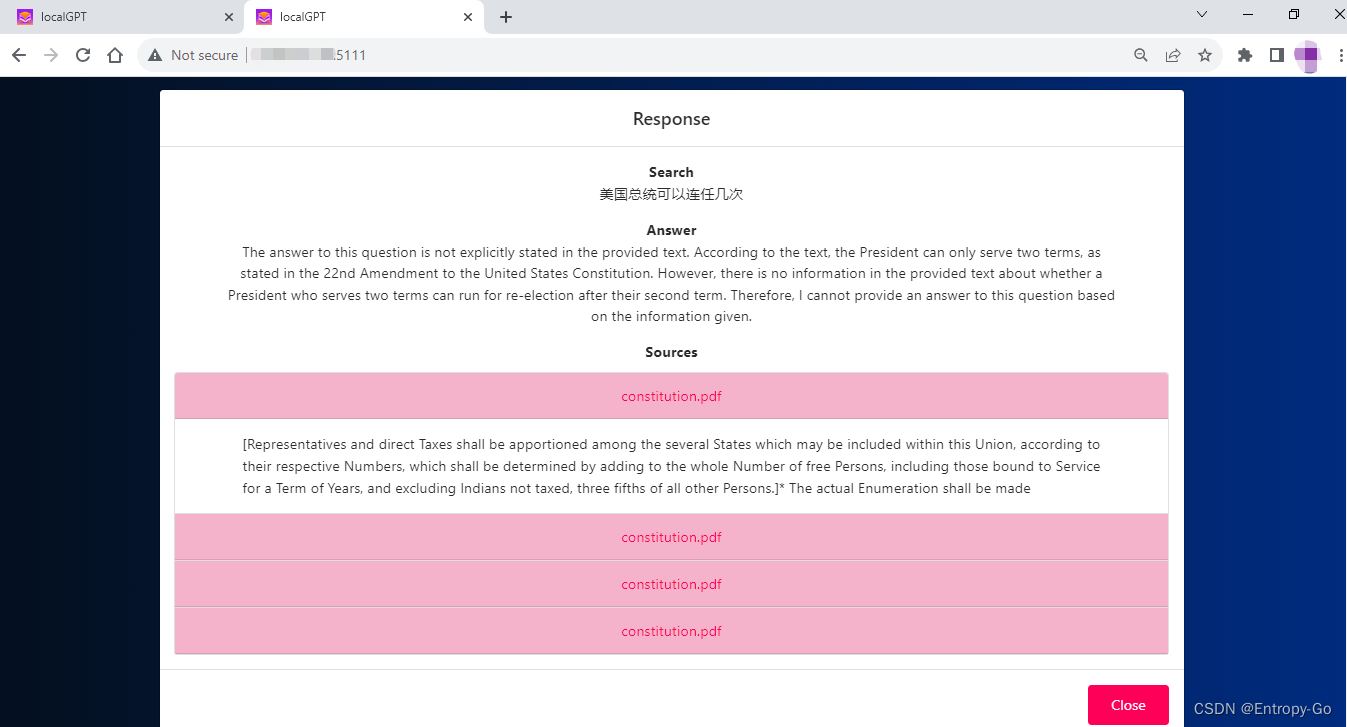
6.3 更换本地文档为知识库
6.3.1 命令行方式
直接将文档添加到 ~/localGPT/SOURCE_DOCUMENTS/
会自动触发更新适量数据库,等更新好之后,就可以正常进行提问对话。
6.3.2 Web UI方式
上传文件
要上传文档以供应用程序摄取作为其新的知识库,请单击upload按钮。
选择要用作新知识库的文档进行对话。
3.然后,系统会提示您选择将文档添加到知识库,用您刚刚选择的文档重置知识库,或者取消上传。
- 当文档被输入到矢量数据库中作为新的知识库时,会有很短的等待时间。
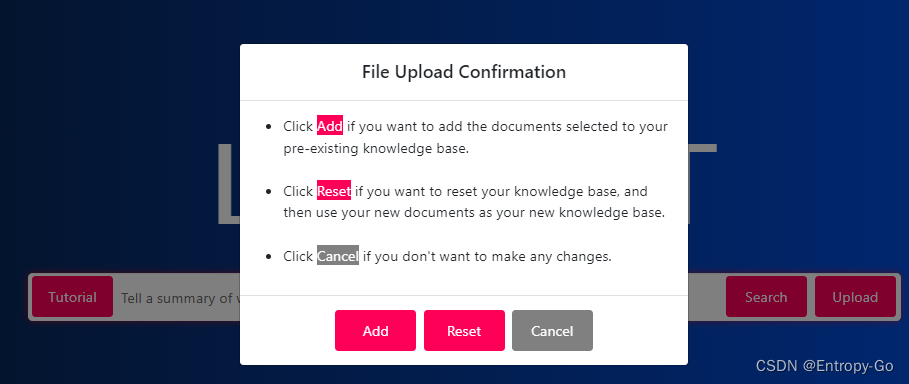
正在注入中文文档到知识库
正在生成回复
结果返回
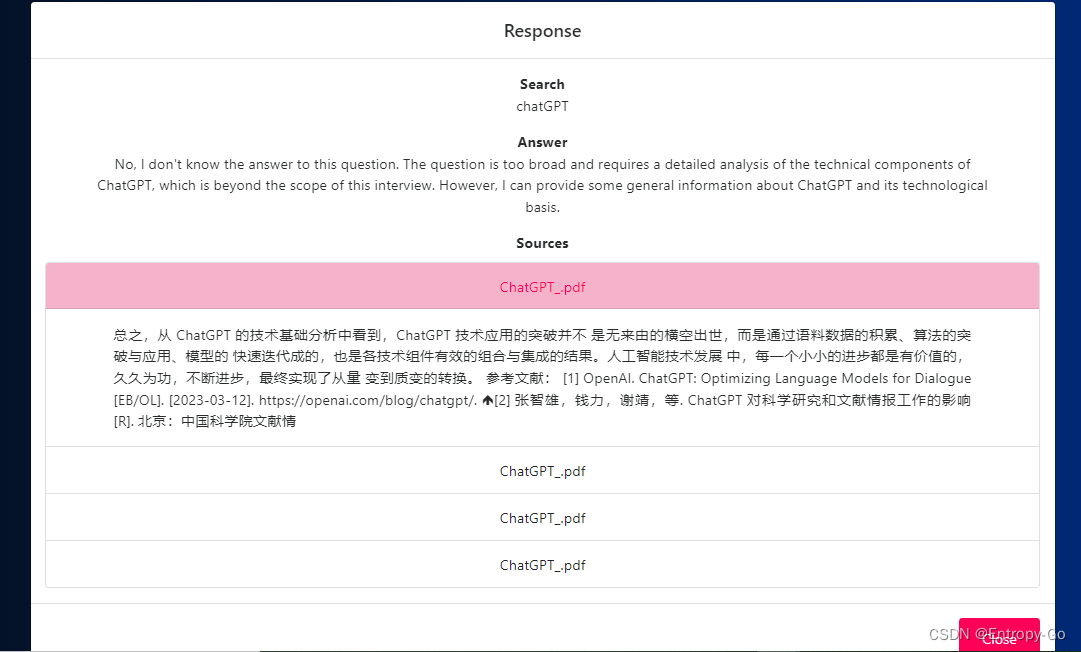
7.常见问题Troubleshooting
7.1 中文文档注入
修改run_localGPT_API.py
max_ctx_size = 4096
修改ingest.py
text_splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=200)
7.2 网页打开后,问题无回复,response.status_code = 504, 304
如果环境使用了代理,在运行服务器端UI前,先去掉代理后再运行
unset http_proxy
unset https_proxy
unset ftp_proxy
/root/miniconda3/bin/python localGPTUI.py
7.3 locaGPT如何工作的
Selecting the right local models and the power of
LangChain
you can run the entire pipeline locally, without any data leaving your environment, and with reasonable performance.
ingest.pyusesLangChaintools to parse the document and create embeddings locally usingInstructorEmbeddings. It then stores the result in a local vector database usingChromavector store.run_localGPT.pyuses a local LLM to understand questions and create answers. The context for the answers is extracted from the local vector store using a similarity search to locate the right piece of context from the docs.- You can replace this local LLM with any other LLM from the HuggingFace. Make sure whatever LLM you select is in the HF format.
7.4 怎么选择不同的LLM大语言模型
The following will provide instructions on how you can select a different LLM model to create your response:
- Open up
constants.pyin the editor of your choice. - Change the
MODEL_IDandMODEL_BASENAME. If you are using a quantized model (GGML,GPTQ), you will need to provideMODEL_BASENAME. For unquatized models, setMODEL_BASENAMEtoNONE - There are a number of example models from HuggingFace that have already been tested to be run with the original trained model (ending with HF or have a .bin in its "Files and versions"), and quantized models (ending with GPTQ or have a .no-act-order or .safetensors in its "Files and versions").
- For models that end with HF or have a .bin inside its "Files and versions" on its HuggingFace page.- Make sure you have a model_id selected. For example ->
MODEL_ID = "TheBloke/guanaco-7B-HF"- If you go to its HuggingFace repo and go to "Files and versions" you will notice model files that end with a .bin extension.- Any model files that contain .bin extensions will be run with the following code where the# load the LLM for generating Natural Language responsescomment is found.-MODEL_ID = "TheBloke/guanaco-7B-HF" - For models that contain GPTQ in its name and or have a .no-act-order or .safetensors extension inside its "Files and versions on its HuggingFace page.- Make sure you have a model_id selected. For example -> model_id =
"TheBloke/wizardLM-7B-GPTQ"- You will also need its model basename file selected. For example ->model_basename = "wizardLM-7B-GPTQ-4bit.compat.no-act-order.safetensors"- If you go to its HuggingFace repo and go to "Files and versions" you will notice a model file that ends with a .safetensors extension.- Any model files that contain no-act-order or .safetensors extensions will be run with the following code where the# load the LLM for generating Natural Language responsescomment is found.-MODEL_ID = "TheBloke/WizardLM-7B-uncensored-GPTQ"``````MODEL_BASENAME = "WizardLM-7B-uncensored-GPTQ-4bit-128g.compat.no-act-order.safetensors" - Comment out all other instances of
MODEL_ID="other model names",MODEL_BASENAME=other base model names, andllm = load_model(args*)
7.5 更多问题参考
Issues · PromtEngineer/localGPT · GitHub
版权归原作者 Entropy-Go 所有, 如有侵权,请联系我们删除。