
机器学习分为有无监督学习,无监督学习和强化学习。而自监督学习(Self-Supervised Learning)是无监督学习的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。 自监督学习有一个非常强的动机:目前,大部分神经网络的训练仍然使用的是有监督范式,需要耗费大量的标注数据,标注这些数据是非常耗时费力的。而自监督的提出就是为了打破对人工标注的依赖,即使在没有标注数据的情况下,也可以高效地训练网络。众所周知,神经网络的训练需要任务来进行驱动,所以自监督学习的核心就是来合理构造有利于模型学习的任务。目前来说构造这些任务的方法大致可以划分为三个方面:
- 基于 pretext task ( 代理任务 )
- 基于 contrastive learning ( 对比学习 )
- 基于 mask image modeling ( 掩码图像模型 )
本系列第二弹就来学习下代理任务(pretext task), Pretext可以理解为是一种为达到特定训练任务而设计的间接任务。**Pretex task的好处就是简化了原任务的求解,在深度学习里就是避免了人工标记样本,实现无监督的语义提取,因此自监督的代理任务方式也属于无监督学习的范围,**下面就举几个在视觉任务里常用的pretext task几伪标签的产生方式,看看能否给你的特定任务设计代理任务带来启发。
1.图像相对位置预测
论文地址:paper
Context 信息蕴含着大量的监督信息, 目前自然语言处理大量使用这样的监督信息来完成大规模的自监督训练。无独有偶,视觉领域也可以利用图片的 context 信息来完成自监督训练。作者从一张图片中随机抽取两个 patches,然后让模型来预测一个 patch 相对于另外一个 patch 的位置。作者认为: **模型只有很好地理解到图片中的各种场景,物体,以及各部分之间的相互关系,模型才能够很好地完成这个相对位置预测任务。**
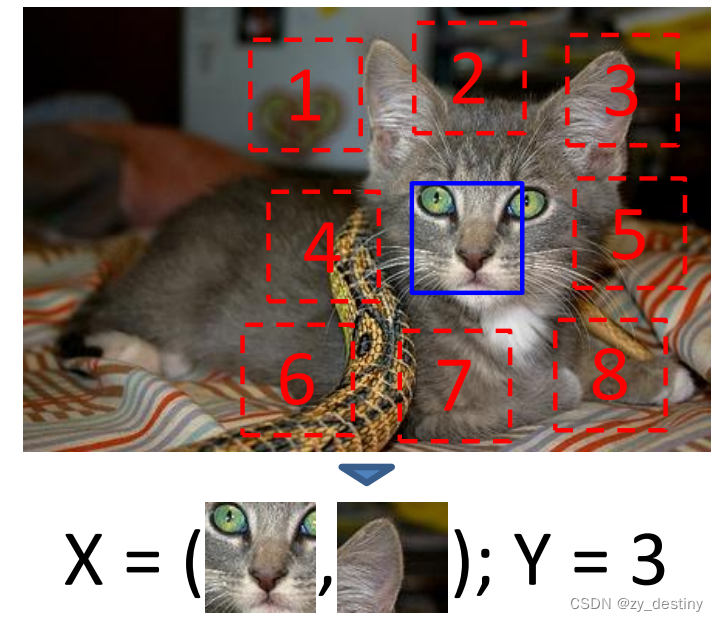

具体做法如上图所示,从红色框中随机选取一个,然后让模型预测其相对于蓝色方框的位置。具体网络结构就是先让两个网络分别提取两个 patches 的特征,然后再在最后面进行融合。
预测两个 patches 的相对位置简单合理,但是如何去规避无效解是模型设计中需要考虑的重点。经过作者长期的探索,以下两种情况容易导致无效解:
- low-level 特征,例如边界样式和纹理的连续性可以使得模型直接预测两个 patches 的相对位置,而不用去理解其内容。
- 色差的影响。由于不同颜色的光的波长不一样,凸透镜会将不同颜色的光投影到不同的位置上。通常情况下,绿色的光相较于蓝色和红色的光更靠近中心一点。那么,模型可以学习到不同 patch 相较于凸透镜中心的位置关系。利用这样的信息,模型也可以学习到两个 patches 之间的相对位置关系,而不用去理解其内容。
针对上面两种情况作者分别提出了解决方案:
- 采样 patch 的时候中间留有 gap(不进行连续采样),同时对这个 gap 具体数值选取也进一步引入了随机波动。
- 针对色差问题,作者提出随机抛弃掉每个 patch RGB 三个通道中的两个通道,并用高斯噪声对丢弃掉的两个通道进行填充。
通过以上设计,模型取得了不错的效果。
2.图片着色
论文地址:paper
主要通过构造一个图片着色任务来让模型学习图片的语义信息。因为作者认为: **只有很好地理解到了各种场景的独立的语义信息,以及他们之间的联系,模型才能够很好完成这项任务。**
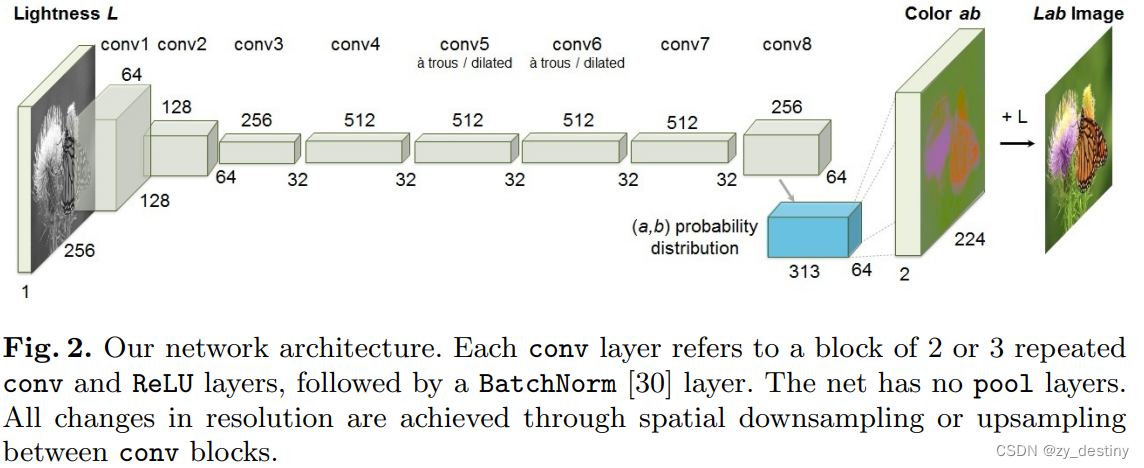
本文具体做法如上图所示,作者将图片转换到 CIE Lab 颜色空间,然后将 L 通道喂入模型,然后让模型去预测 a, b 通道的数值。但是,如何设计损失函数非常有考究。
** 如果直接通过回归的方式来完成 a, b 通道的预测,那么最终的着色效果是不太理想的,最终的图片偏灰度图。**
因为图片中每个物体可能有多个可能的着色效果,所以作者将其转换成一个分类问题,并进一步提出 class rebalancing 来平衡不同像素点对模型训练的影响。

3.上下文编码
论文地址:paper
与上面讲到的颜色重建 类似,Context Encoders 也是通过设计重建原图来使模型学习到图片的语义信息。但是与 Colorization 不同,Context Encoders 是从空间维度对图片进行重建,而 Colorization 是从图片的通道维度进行重建。作者认为:**模型只有很好地理解到整张图片的语义信息,才能够很好地完成这个重建任务。**


具体做法,如上图所示: 作者 mask 掉一部分图片信息,再将 mask 过的图片喂入网络,然后让 mask 掉的部分对预测的部分进行监督,并使用 L2 loss 驱动模型学习。到此为止,通过对图片进行重建来进行自监督学习的整个流水线已经搭建完成。但是作者发现,仅仅使用 L2 loss 容易使得模型的重建结果非常模糊,而没有很好地重建出图片的高频信号。这是因为,回归平均值对 L2 loss 来说更易于优化。
为了解决上述问题,作者进而提出添加了一个对抗损失函数,这个函数的引入使得重建的图片更加 sharp,进而提高了模型对图片语义的理解能力。
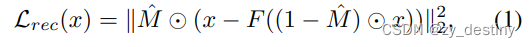
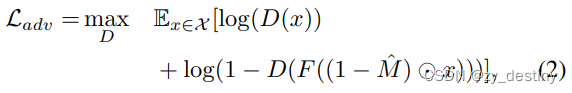

作者探索了如何来 mask 图片,最终发现采用 Central region 的模型的泛化能力不是特别好,而采用 Random block 和 Random region 的模型取得不错且相似的结果。

4.旋转预测
论文地址:paper

作者希望通过让模型去识别图片的旋转角度,让模型具有理解图片语义信息的能力。为了完成这个任务,作者认为:**模型只有很好地识别并提取图片中的主要物体,并理解其和图片中其他景物的语义信息,才能够完成这个旋转角度识别任务。**其具体操作如下:

首先定义多种旋转操作,将旋转后的图片喂入网络,然后对模型进行分类任务训练,让模型输出当前图片被施加了何种旋转操作。通过这样一个简单的任务,作者发现,模型具备了提取图片中主要物体,并理解图片语义信息的能力。除此之外,作者继续分析了该方法成功的原因:
- 1)相较于其他操作,旋转操作没有遗留任何明显的 low-level 线索让模型轻易完成这个旋转识别任务。所以,模型必须得去理解图片的语义信息。
- 2)识别旋转角度是一个定义非常完善的任务。因为,大多数情况下图片中的物体总是呈现直立的状态,所以理想情况下,模型可以清楚地识别图片被旋转了多大的角度。除非,物体是类似于圆形的形状。
通过上面四个例子,我们可以发现,基于 pretext task 的自监督学习算法都具有以下两个特点:
1)一个定义良好的代理任务,例如识别旋转角度和相对位置。
2)合理的限制条件,例如引入何种条件才能够避免模型得到无效解。
所以,当你为你的目标任务绞尽脑汁时,不妨慢下来,看看能否“曲线救国”。
整理不易,欢迎一键三连!!!系列更新,点关注不迷路~
本文转载自: https://blog.csdn.net/qq_38308388/article/details/129881228
版权归原作者 zy_destiny 所有, 如有侵权,请联系我们删除。
版权归原作者 zy_destiny 所有, 如有侵权,请联系我们删除。