

Q-learning 是强化学习中的一种常见的算法,近年来由于深度学习革命而取得了很大的成功。本教程不会解释什么是深度 Q-learning,但我们将通过 Q-learning 算法来使得代理学习如何玩 tic-tac-toe 游戏。尽管它很简单,但我们将看到它能产生非常好的效果。
要理解本教程,不必有任何关于强化学习的知识,但最好有一定的微积分和线性代数基础。首先,我们将通过一些必要的背景知识来快速了解强化学习,然后我们将介绍 Q-learning 算法,最后我们将介绍如何通过它来使得一个代理学会玩 tic-tac-toe。
强化学习简介
强化学习是指代理在不同状态的环境中,根据某种奖励函数来优化其行为的一门学科。在本教程中,环境是 tic-tac-toe 游戏,它有明确定义的动作,代理必须决定选择哪些动作才能赢得游戏。此外,代理人赢得游戏将获得一定奖励,这鼓励它在游戏中学习更好的策略。
强化学习的一个常见框架是(有限)马尔可夫决策过程(MDP, Markov Decision Process)。它帮助我们定义一组动作和状态,代理基于这些动作和状态进行决策。
MDP 通常包括有:
- 一组有限的动作 A(在游戏面板上所有可以放置标记的位置)
- 一组有限的状态 S(游戏面板上的所有可能情形)
- 一种奖励函数 R(s,a)
- 转移函数 T(s,a,s')
转换函数给出了在执行动作 a 时从状态 s 移动到 s' 的概率。当我们不确定动作是否总是产生期望结果时,转移函数十分必要。但是需要注意的是,对于 tic-tac-toe 游戏,我们确切地知道每个动作会做什么,所以我们不会使用转移函数。
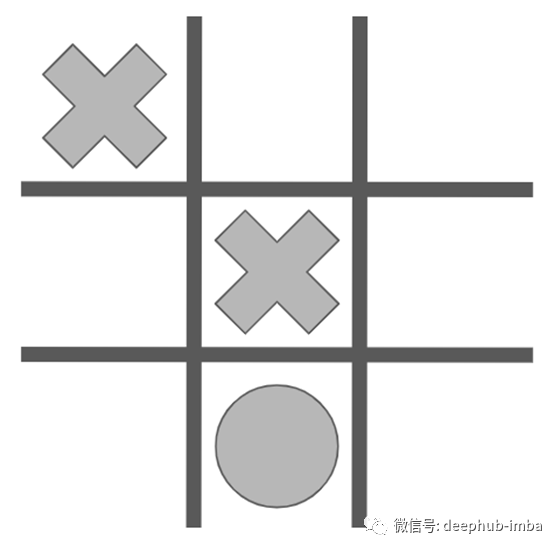
在本例中,当前玩家可以执行六个可能的操作
MDP框架帮助我们将问题形式化,这样我们就可以根据当前状态确定哪些操作将在游戏期间使代理的总回报最大化。本教程中奖励函数 R(s,a) 将非常简单:
- 如果代理在状态 s 执行一个操作 ,最终赢得游戏,那么 R(s,)=1.
- 如果代理在状态 s 执行一个操作 ,最终输了游戏,那么 R(s,)=-1.
- 否则,R(s,)=0.
在强化学习中,我们通常找到一个最优策略,代理通过该策略决定选择哪些动作。本教程中我们使用 Q-learning,简单地将策略表示为当代理处于s状态时执行动作 a 使函数 Q(s,a) 最大化:
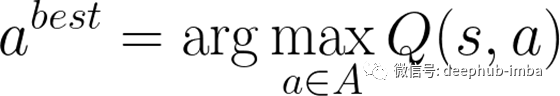
Q-learning 中的状态更新
Q(s,a) 即代理在 s 状态下选择动作 a,则在游戏最后给出对应的奖励或惩罚。由于代理希望将其报酬最大化,因此它会选择使 Q 最大化的动作。
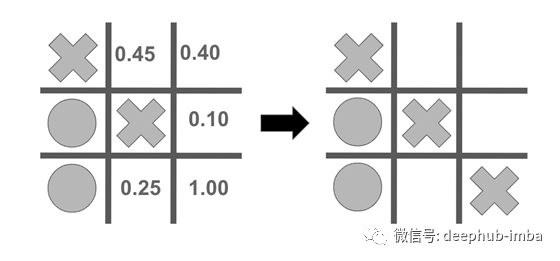
在场景中,首先计算当前玩家X所有动作的Q值,然后选择Q值最大的动作
要计算 Q(s,a),代理必须探索所有可能的状态和动作,同时从奖励函数 R(s,a) 获得反馈。在 tic-tac-toe 游戏中,我们通过让代理与对手进行多场比赛来迭代更新 Q(s,a),用于更新 Q 的方程如下:
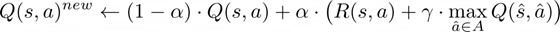
- 在当前状态 s 下执行动作 a
- 考虑执行动作后的所有状态,计算其中的最大 Q 值。是执行动作 a 之后的新状态, 是下一个状态中的最佳动作
- 学习率 α 决定我们覆盖旧值的程度,本例中将使用 α=0.1
- 折现因子 γ 决定了在当前时间步 t 中,未来的奖励应加权多少。通常选择 γ=0.9
Q-learning 算法实现
为了得到一个经过充分训练的代理,我们需要获得 Q(s,a) 的值,这将通过让两个代理互相比赛来完成。首先,引入一个概率 ε,即每个代理选择一个随机动作,否则,它将根据 Q(s,a) 选择最佳动作。这样,我们就保证了学习的平衡,使代理有时探索新的行为,而其他时候则利用代理已经学习到的信息来执行动作。
训练阶段可以通过以下伪代码进行描述:
Initialise: Q(s,a) = 0, startingstates,
startingplayerP, iterationsN
fort = 0 : N
Withprobabilityε : Ppicksrandomactiona
Else, pickactionathatmaximiseQ(s,a)
ObservenewstateŝandrewardR(s,a)
Ifcurrentplayerisouragent,
updateQ(s,a) = (1-α)Q(s,a) +α[R(s,a) +γ*max(Q(ŝ,â))]
s = ŝ
Switchturn, P = theotherplayer
值得注意的是,迭代次数 N 必须相对较大,本例中进行了大约 500000 次迭代。此外,Q(s,a) 可以通过 Python dict 的数据格式进行存储;如果我们将 (s,a) 表示为整数,则可以通过二维数组的数据格式进行存储。最后,可以随时间改变概率 ε,以强调在早期迭代中更多的随机探索,从而加快学习速度。
在用上述算法训练代理之后,可以保存 Q(s,a) 并在想要进行比赛时加载它。然后,代理只需遵循最优策略,选择使 Q(s,a) 最大化的动作来赢得比赛。虽然由于 tic-tac-toe 游戏并不复杂,代理并没有获得高级智能,但是尝试这个方法可以学习如何实现 Q-learning 并了解它是如何工作的。
结语
本文首先介绍了马尔可夫决策过程以及如何在强化学习中应用它。然后使用状态、行动、奖励函数来对 tic-tac-toe 游戏进行建模。除此之外,我们还定义了函数 Q(s,a),该函数通过在状态 s 中选择动作 a 来量化预期的奖励,并通过重复玩游戏来计算 Q(s,a)。
作者:Rickard Karlsson
deephub翻译组:oliver lee
本文完整代码:https://github.com/RickardKarl/bill-the-bot
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********