
文章目录
前言
yolov5已经很成熟了,作为一个拥有发展系列的检测器,它拥有足够的精度和满足现实中实时性要求,所以许多项目和比赛都能用的上,自己也拿来参加过比赛。
本博客的讲解代码来源:https://github.com/ultralytics/yolov5
1.项目介绍
YOLOv5针对不同大小的输入和网络深度宽度,主要分成了(n, s, m, l, x)和(n6, s6, m6, l6, x6),这些都在yolov5的项目代码的配置文件中有对应。其中随着版本的更新,里面也多了好多其他模块。这里,我主要用的是v6.0版本。
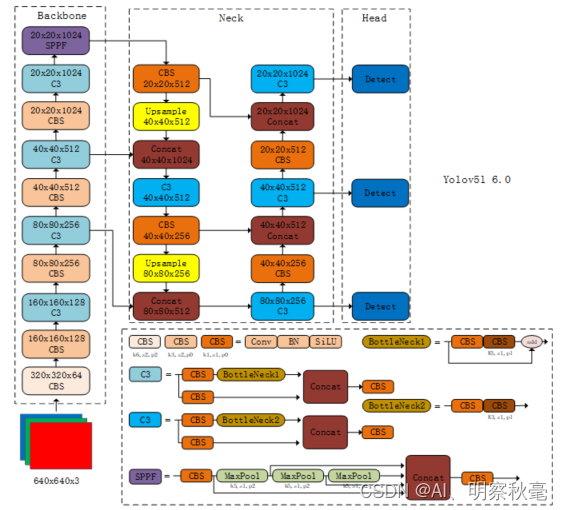
2.yolov5的网络结构
这里主要结合代码介绍下yolov5sv6.0的网络结构部分,其他大小的框架都差不多。
如下图所示,这里给出了我参考一些yolov5图根据6.0代码所画的yolov5l网络
- 修改:yolov5s->yolov5l(注意这里的结构是yolov5l的,因为配置文件的宽度和深度对应的比例因子是1的时候是yolov5l,yolov5s是乘以了0.5比例的的)
结构图: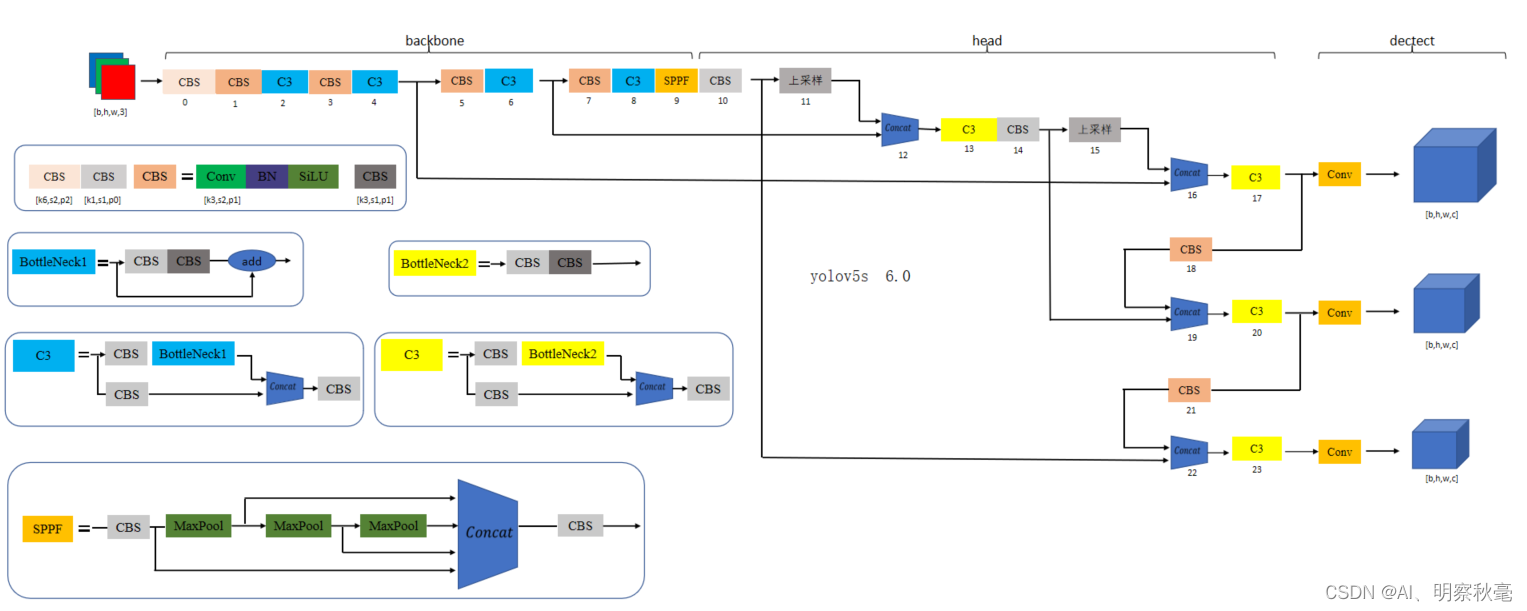
1.yolov5s的配置文件
相关参数
# YOLOv5 by Ultralytics, GPL-3.0 license# Parametersnc:4# number of classes,检测的类别depth_multiple:0.33# model depth multiple, 决定下面的 number:nwidth_multiple:0.50# layer channel multiple,解决网络的深度和宽度anchors:-[10,13,16,30,33,23]# P3/8 # anchor尺寸设置-[30,61,62,45,59,119]# P4/16-[116,90,156,198,373,326]# P5/32 # 可以自己手动设置,也可以自动聚类
backbone
里面的-1表示自身的特征层的位置
# YOLOv5 v6.0 backbonebackbone:# [from, number, module, args[C,K,S,P]] P:会根据公式自动推导,配置文件也看不太出。#分别对应:[输入位置,叠加层数,使用模块名称,[输出通道数,卷积核大小,步距,padding]][[-1,1, Conv,[64,6,2,2]],# 0-P1/2[-1,1, Conv,[128,3,2]],# 1-P2/4[-1,3, C3,[128]],[-1,1, Conv,[256,3,2]],# 3-P3/8[-1,6, C3,[256]],[-1,1, Conv,[512,3,2]],# 5-P4/16[-1,9, C3,[512]],[-1,1, Conv,[1024,3,2]],# 7-P5/32[-1,3, C3,[1024]],[-1,1, SPPF,[1024,5]],# 9,总共]
head
里面的[-1, 6]表示自身特征层和第6个位置上的特征层。如[[-1, 6], 1, Concat, [1]],表示和backbone里显示的P4那层特征层相cat。
# YOLOv5 v6.0 headhead:[[-1,1, Conv,[512,1,1]],[-1,1, nn.Upsample,[None,2,'nearest']],[[-1,6],1, Concat,[1]],# cat backbone P4[-1,3, C3,[512,False]],# 13[-1,1, Conv,[256,1,1]],[-1,1, nn.Upsample,[None,2,'nearest']],[[-1,4],1, Concat,[1]],# cat backbone P3[-1,3, C3,[256,False]],# 17 (P3/8-small)[-1,1, Conv,[256,3,2]],[[-1,14],1, Concat,[1]],# cat head P4[-1,3, C3,[512,False]],# 20 (P4/16-medium)[-1,1, Conv,[512,3,2]],[[-1,10],1, Concat,[1]],# cat head P5[-1,3, C3,[1024,False]],# 23 (P5/32-large)[[17,20,23],1, Detect,[nc, anchors]],# Detect(P3, P4, P5)]
2.网络模型的初始化和训练过程
根据配置文件,初始化网络模型:
代码路径:yolov5-master/models/yolo.py
defparse_model(d, ch):# model_dict, input_channels(3)
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10}{'module':<40}{'arguments':<30}")
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na =(len(anchors[0])//2)ifisinstance(anchors,list)else anchors # number of anchors,每一个predict head上的anchor数 = 3
no = na *(nc +5)# number of outputs = anchors * (classes + 5)# layers: 保存每一层的层结构 save: 记录下所有层结构中from中不是-1的层结构序号 c2: 保存当前层的输出channel
layers, save, c2 =[],[], ch[-1]# layers, savelist, ch out# from(当前层输入来自哪些层), number(当前层次数 初定), module(当前层类别), args(当前层类参数 初定)for i,(f, n, m, args)inenumerate(d['backbone']+ d['head']):# from, number, module, args
m =eval(m)ifisinstance(m,str)else m # eval stringsfor j, a inenumerate(args):try:
args[j]=eval(a)ifisinstance(a,str)else a # eval stringsexcept NameError:pass
n = n_ =max(round(n * gd),1)if n >1else n # depth gain:控制深度 如v5s: n*0.33 n: 当前模块的次数(间接控制深度)if m in(Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x,ACConv,CAM_Module):
c1, c2 = ch[f], args[0]# c1: 当前层的输入的channel数 c2:当前层的输出的channel数(初定) ch:记录着所有层的输出channelif c2 != no:# if not output,最后一层
c2 = make_divisible(c2 * gw,8)# 通道数调整(64*0.5,8)
args =[c1, c2,*args[1:]]# if m in[BottleneckCSP, C3, C3TR, C3Ghost, C3x]:
args.insert(2, n)# number of repeats
n =1elif m is nn.BatchNorm2d:
args =[ch[f]]elif m is Concat:
c2 =sum(ch[x]for x in f)elif m is Detect:
args.append([ch[x]for x in f])ifisinstance(args[1],int):# number of anchors
args[1]=[list(range(args[1]*2))]*len(f)elif m is Contract:
c2 = ch[f]* args[0]**2elif m is Expand:
c2 = ch[f]// args[0]**2else:
c2 = ch[f]
顺序执行网络的训练过程:
m_ = nn.Sequential(*(m(*args)for _ inrange(n)))if n >1else m(*args)# module
t =str(m)[8:-2].replace('__main__.','')# module type
np =sum(x.numel()for x in m_.parameters())# number params:计算参数量
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f}{t:<40}{str(args):<30}')# print
save.extend(x % i for x in([f]ifisinstance(f,int)else f)if x !=-1)# append to savelist
layers.append(m_)if i ==0:
ch =[]
ch.append(c2)return nn.Sequential(*layers),sorted(save)
3.backbone
backbone:特征提取网络。由yolov3的Darknet53变为yolov4的CSPDarknet53,yolov5里较小改动。
根据配置文件解析整个backbone的结构:
- Conv:conv+bn+SiLU,就是如上图所示的CBS。yolov5s里用了三种不同stride和padding的conv组成CBS。**[k,s,p]表示卷积核,stride步距和padding填充,注意网络过程中这三者的变化**。
- 第0层: [-1, 1, Conv, [64, 6, 2, 2]]:输入图片先经过一个6x6,步距为2,padding为2的Conv模块。输出通道由3变为64,分辨率变为原来的1/4,长宽各减少了两倍。这个模块就是为了在卷积过程中降低分辨率的。
网络结构代码路径:yolov5-master/models/common.py
class Conv(nn.Module):# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1,act=True):# ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self,x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self,x):
return self.act(self.conv(x))
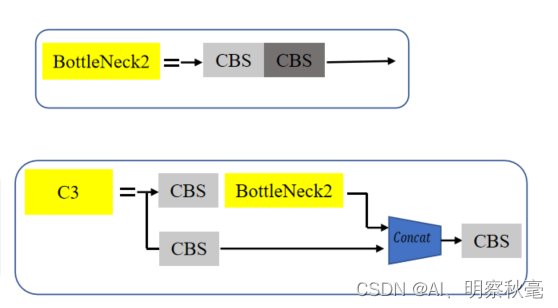
- 第1层:[-1, 1, Conv, [128, 3, 2]]:经过一个3x3,步距为2,padding为1的Conv模块。输出通道由64变为128,分辨率变为原来的1/4,长宽各减少了两倍。 +第2层: [-1, 3, C3, [128]]:经过一个C3模块,输出通道为128,BottleNeck1x3。C3其实就是为了适配yolo的Darknet对CSPNet的改进。通过用两个CBS模块来将通道数划分成两个部分,其中一个部分不变,另一个部分还要通过多个BottleNeck去堆叠。接着将两个分支的信息在通道方向进行Concat拼接,最后再通过CBS的模块进一步融合。 C3结构如下:
CSPNet的优点:
1.Strengthening learning ability of a CNN:现有的CNN在轻量化后,其精度大大降低,因此希望加强CNN的学习能力,使其在轻量化的同时保持足够的准确性。
2.Removing computational bottlenecks:希望能够均匀分配CNN中各层的计算量,这样可以有效提升各计算单元的利用率,从而减少不必要的能耗。
3.Reducing memory costs:在减少内存使用方面,采用cross-channel pooling,在特征金字塔生成过程中对特征图进行压缩。
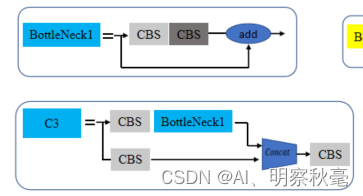
classC3(nn.Module):# CSP Bottleneck with 3 convolutionsdef__init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):# ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()
c_ =int(c2 * e)# hidden channels,1/2
self.cv1 = Conv(c1, c_,1,1)
self.cv2 = Conv(c1, c_,1,1)
self.cv3 = Conv(2* c_, c2,1)# optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0)for _ inrange(n)))defforward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)),1))
- 第3层:[-1, 1, Conv, [256, 3, 2]]:经过一个3x3,步距为2,padding为1的Conv模块。输出通道由128变为256,分辨率变为原来的1/4,长宽各减少了两倍。
- 第4层:[-1, 6, C3, [256]]:经过一个C3模块,输出通道为256,BottleNeck1x6。
- 第5层: [-1, 1, Conv, [512, 3, 2]]:经过一个3x3,步距为2,padding为1的Conv模块。输出通道由256变为512,分辨率变为原来的1/4,长宽各减少了两倍。
- 第6层:[-1, 9, C3, [512]]:经过一个C3模块,输出通道为512,BottleNeck1x9。
- 第7层: [-1, 1, Conv, [1024, 3, 2]]:经过一个3x3,步距为2,padding为1的Conv模块。输出通道由512变为1024,分辨率变为原来的1/4,长宽各减少了两倍。
- 第8层:[-1, 3, C3, [1024]]:经过一个C3模块,输出通道为1024,BottleNeck1x3。
- 第9层:[-1, 1, SPPF, [1024, 5]]:通过最大池化层进行感受野的扩张。和SPP不同的是,这里SPPF并没有使用三个使用不同核(5,9,13)大小的maxpool并行结构,而是使用了三个核大小为5x5的maxpool串行结构来达到和SPP同样的计算结果。但是速度却几乎是SPP的两倍快。详细对比和代码可以看看这篇博客https://blog.csdn.net/qq_37541097/article/details/123594351?spm=1001.2014.3001.5502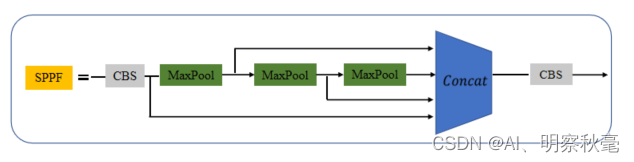
classSPPF(nn.Module):# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocherdef__init__(self, c1, c2, k=5):# equivalent to SPP(k=(5, 9, 13))super().__init__()
c_ = c1 //2# hidden channels
self.cv1 = Conv(c1, c_,1,1)
self.cv2 = Conv(c_ *4, c2,1,1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k //2)defforward(self, x):
x = self.cv1(x)with warnings.catch_warnings():
warnings.simplefilter('ignore')# suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)return self.cv2(torch.cat((x, y1, y2, self.m(y2)),1))
4.head
1.三层预测
head:yolov5配置文件里写的head,其实就是对应通用检测模块里的neck。就是为了更好的检测不同尺度目标大小设计的特征金字塔结构。结构如下图所示: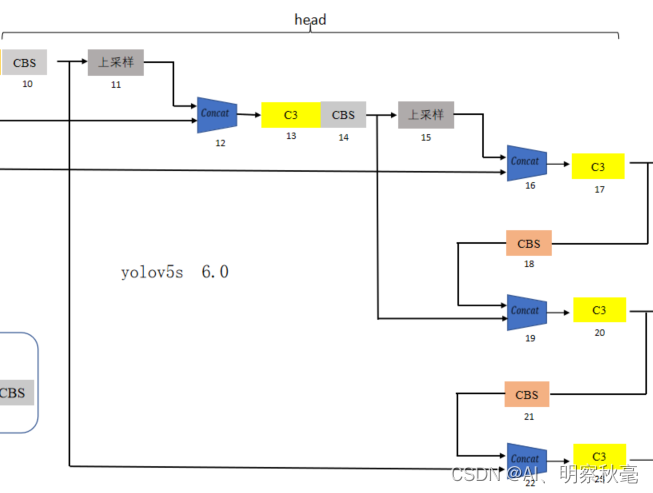
- 第10层:[-1, 1, Conv, [512, 1, 1]]:经过一个1x1,步距为1,padding为0的Conv模块。输出通道由1024变为512,分辨率不变。
- 第11层:[-1, 1, nn.Upsample, [None, 2, ‘nearest’]]:上采样层,采样因子为2,模式为邻近插值。
- 第12层:[[-1, 6], 1, Concat, [1]]:concat在索引[-1,6]进行通道上的拼接,当前层上采样后与索引为6的层进行自上而下特征层“融合”,通道变为2倍。上采样,分辨率长宽变为原来的2倍。
- 第13层:[-1, 3, C3, [512, False]]:经过一个C3模块,输出通道为512,BottleNeck2x3。
- 第14层:[-1, 1, Conv, [256, 1, 1]]:经过一个1x1,步距为1,padding为0的Conv模块。输出通道由512变为256,分辨率不变。
- 第15层:[-1, 1, nn.Upsample, [None, 2, ‘nearest’]]:上采样层,采样因子为2,模式为邻近插值。
- 第16层:[[-1, 4], 1, Concat, [1]]:concat在索引[-1,4]进行通道上的拼接,当前层经过上层的上采样后与索引为4的层进行自上而下(FPN)特征层“融合”,通道变为2倍。上采样,分辨率长宽变为原来的2倍。
- 第17层:[-1, 3, C3, [256, False]]:经过一个C3模块,输出通道为256,BottleNeck2x3。作为预测的head:P3层。
- 第18层:[-1, 1, Conv, [256, 3, 2]]:经过一个3x3,步距为2,padding为1的Conv模块。输出通道由512变为256,分辨率变为原来的1/4,长宽各减少了两倍。
- 第19层:[[-1, 14], 1, Concat, [1]]:concat在索引[-1,14]进行通道上的拼接,当前层经过上层的分辨率减低后与索引为14的层进行自下而上(PANet)特征层“融合”,通道变为2倍。分辨率长宽变为原来的1/2。
- 第20层:[-1, 3, C3, [512, False]]:经过一个C3模块,输出通道为512,BottleNeck2x3。作为预测的head:P4层。
- 第21层:[-1, 1, Conv, [512, 3, 2]]:经过一个3x3,步距为2,padding为1的Conv模块。输出通道512不变,分辨率变为原来的1/4,长宽各减少了两倍。
- 第22层:[[-1, 10], 1, Concat, [1]]:concat在索引[-1,10]进行通道上的拼接,当前层经过上层的分辨率减低后与索引为10的层进行自下而上(PANet)特征层“融合”,通道变为2倍。分辨率和上一层一致。
- 第23层:[-1, 3, C3, [1024, False]]:经过一个C3模块,输出通道为1024,BottleNeck2x3。作为预测的head:P5层。
2.4层预测
Yolov5l6,m6,n6,x6都是用四层来预测输出的。
# yolov5l6:# YOLOv5 v6.0 backbonebackbone:# [from, number, module, args][[-1,1, Conv,[64,6,2,2]],# 0-P1/2[-1,1, Conv,[128,3,2]],# 1-P2/4[-1,3, C3,[128]],[-1,1, Conv,[256,3,2]],# 3-P3/8[-1,6, C3,[256]],[-1,1, Conv,[512,3,2]],# 5-P4/16[-1,9, C3,[512]],[-1,1, Conv,[768,3,2]],# 7-P5/32[-1,3, C3,[768]],[-1,1, Conv,[1024,3,2]],# 9-P6/64[-1,3, C3,[1024]],[-1,1, SPPF,[1024,5]],# 11]# YOLOv5 v6.0 headhead:[[-1,1, Conv,[768,1,1]],# [-1, 1, Conv, [768, 1, 1]],[-1, 1, CAM_Module, [768, 1, 1]],[-1,1, nn.Upsample,[None,2,'nearest']],[[-1,8],1, Concat,[1]],# cat backbone P5[-1,3, C3,[768,False]],# 15[-1,1, Conv,[512,1,1]],[-1,1, nn.Upsample,[None,2,'nearest']],[[-1,6],1, Concat,[1]],# cat backbone P4[-1,3, C3,[512,False]],# 19[-1,1, Conv,[256,1,1]],[-1,1, nn.Upsample,[None,2,'nearest']],[[-1,4],1, Concat,[1]],# cat backbone P3[-1,3, C3,[256,False]],# 23 (P3/8-small)[-1,1, Conv,[256,3,2]],[[-1,20],1, Concat,[1]],# cat head P4[-1,3, C3,[512,False]],# 26 (P4/16-medium)[-1,1, Conv,[512,3,2]],[[-1,16],1, Concat,[1]],# cat head P5[-1,3, C3,[768,False]],# 29 (P5/32-large)[-1,1, Conv,[768,3,2]],[[-1,12],1, Concat,[1]],# cat head P6[-1,3, C3,[1024,False]],# 32 (P6/64-xlarge)[[23,26,29,32],1, Detect,[nc, anchors]],# Detect(P3, P4, P5, P6)]
通过在backbone里多加一层768通道的特征层,会使最顶层的分辨率继续按1/4减小,长宽减小一半。
然后经过自上而下和自下而上的特征层匹配coancat融合,会多出一个P6预测层。多用一个预测层会有什么好处呢:能够检测更大的目标物体,提取的目标特征语义信息更丰富,自上而下的传递的语义信对各个层更好。
5.detect
通过卷积预测输出相应通道数的特征层用于分类和回归。
c = (5+num_cls)x3:(四个坐标偏移值+1个置信度+预测的类别数)x每个像素所给3个anchors。
Conv:这里的就是普通的1x1卷积。
补充个更直观点的图
总结
这里对Yolov5的网络结构部分进行了总结,后续有时间,再对其他部分做总结。
版权归原作者 AI、明察秋毫 所有, 如有侵权,请联系我们删除。