
因素分解理论:
1919年统计学家沃伦·珀森斯(Warren Persons)在他的论文《商业环境的指标》中首次提出了确定性因素分解(time series decomposition)思想。之后,该方法广泛应用于宏观经济领域时间序列的分析和预测。
珀森斯认为尽管不同的经济变量波动特征千变万化,因果关系的影响错综复杂,但所有的序列波动都可以归纳为受到如下四个因素的综合影响:
(1)长期趋势(trend)。序列呈现出明显的长期递增或递减的变化规律。
(2)循环波动(circle)。序列呈现出从低到高,再从高到低的反复循环波动。循环周期可长可短,不一定是固定的。循环波动通常在经济学中作为经济景气周期指标。
(3)季节性变化(season)。序列呈现出和季节变化相关的稳定周期性波动,后来季节性变化的周期拓展到任意稳定周期。
(4)随机波动(irrelevance)。除了长期趋势、循环波动和季节性变化之外,其他不能用确定性因素解释的序列波动都属于随机波动。
统计学家假定序列会受到这四个因素中的全部或部分的影响,从而呈现出不同的波动特征。换言之,任何一个时间序列都可以用这四个因素的某个函数进行拟合: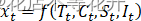。
最常用的两个函数是加法函数和乘法函数,相应的因素分解模型称为加法模型和乘法模型。
加法模型: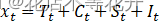
乘法模型: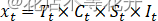
** ARIMA**模型也可以对具有季节效应的序列建模。根据季节效应提取的方式不同,又 底分为ARIMA加法模型和ARIMA乘法模型。
ARIMA加法模型是指定列中季节效应和其他效应之间是加法关系,即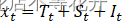
** **这时,各种效应信息的提取都非常容易。通常简单的周期步长差分即可将序列中的季节信息提取充分,简单的低阶差分即可将趋势信息提取充分,提取完季节信息和趋势信息之后的残差序列就是一个平稳序列,可以用ARMA模型拟合。
** **但更为常见的情况是,序列的季节效应、长期趋势效 应和随机波动之间存在复杂的交互影响关系,简单的季节加法模型并不足以充分提取其中的相关关系,这时通常需要采用季节乘法模型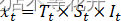
**例题:某城市1980年1月至1995年8月每月屠宰生猪数量如下表所示(行数据)。 **
** (1)绘制时序图,直观考察该序列的确定性因素特征。**
** (2)选择适当的模型对该序列进行因素分解。**
** (3)选择适当的模型对该序列进行为期5年的预测。**
数据文件可在我的资源里找到。
分析思路如下:
1、导入数据并生成时间序列
m<-read.csv("C:\\Users\\86191\\Desktop\\E6_8.csv",sep=',',header = T)
x<-ts(m$x,start = c(1980,1),frequency = 12)
2、判断该序列的平稳性与纯随机性:
(1)绘制原序列时序相关代码如下:
plot(
x,
main = "1980年-1995年每月屠宰生猪数量",
xlab = "年份",ylab="数量",
xlim = c(1979,1996),ylim=c(30000,121000),
type="o",
pch=20,
)
绘制的时序图如下:
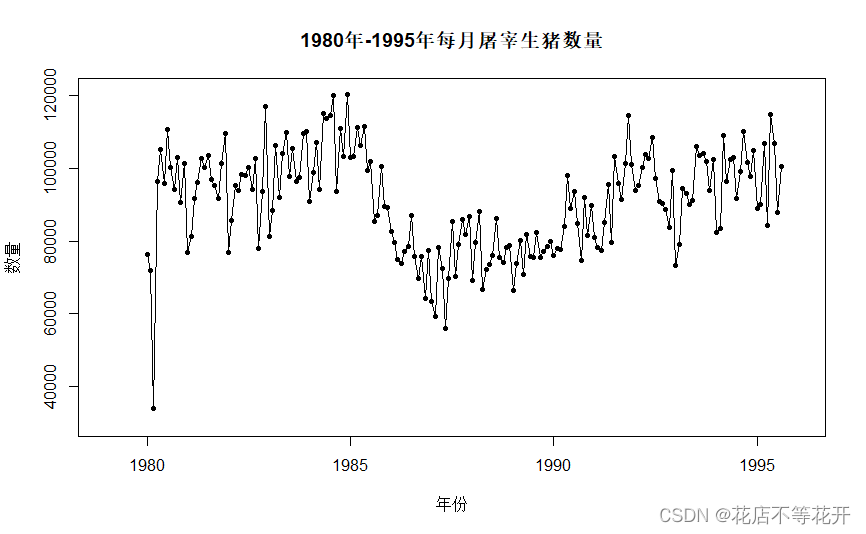
从该时序图上可以看出,该序列具有以年为周期的季节性变化、趋势和随机波动。
(2)选择适当模型对该序列进行因素分解
由于有趋势,选择因素分解乘法模型对该序列进行因素分解。
#选择因式分解加法模型对该序列进行因素分解
b<-decompose(x,type = "multiplicative")
#decompose是用来分解确定性因素的函数,additive是加法模型,multiplicative是乘法模型
plot(b)
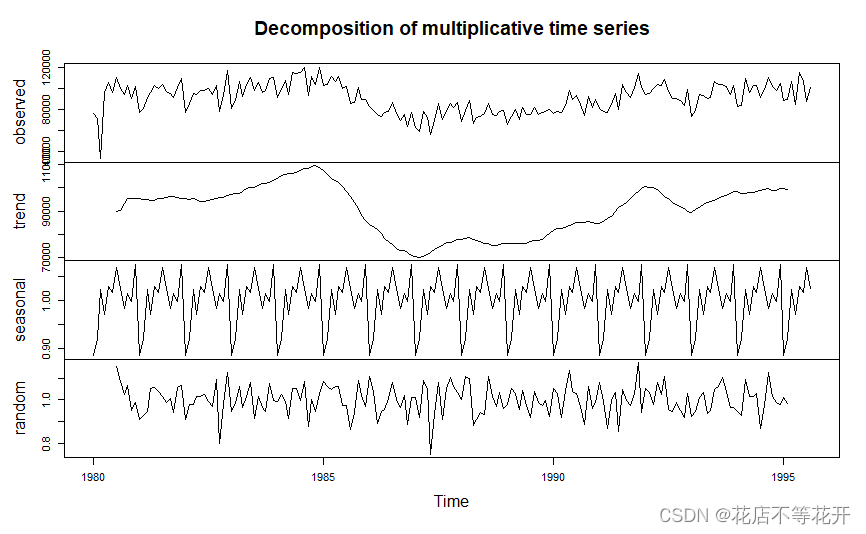 该图为因素分解拟合综合图,共分为四部分,第一部分是序列的观察值图线;第二部分是序列的趋势拟合图;第三部分是季节效应图,即以年为周期的季节性变化图形(周期图);第四部分是随机波动图,即序列的残差图。
该图为因素分解拟合综合图,共分为四部分,第一部分是序列的观察值图线;第二部分是序列的趋势拟合图;第三部分是季节效应图,即以年为周期的季节性变化图形(周期图);第四部分是随机波动图,即序列的残差图。
(3)对原序列进行差分
对原序列x作1阶差分消除循环波动因素,再作以周期为步数的12步差分消除季节效应(季节性变化)的影响,得到一个差分后的序列x_diff_12。
相关代码如下:
x_diff_12<-diff(diff(x),12)#一阶差分再12步差分
plot(
x_diff_12,
main = "1980年-1995年每月屠宰生猪数量一阶差分再12步差分时序图",
type="o",
pch=20,
)
运行结果如下:
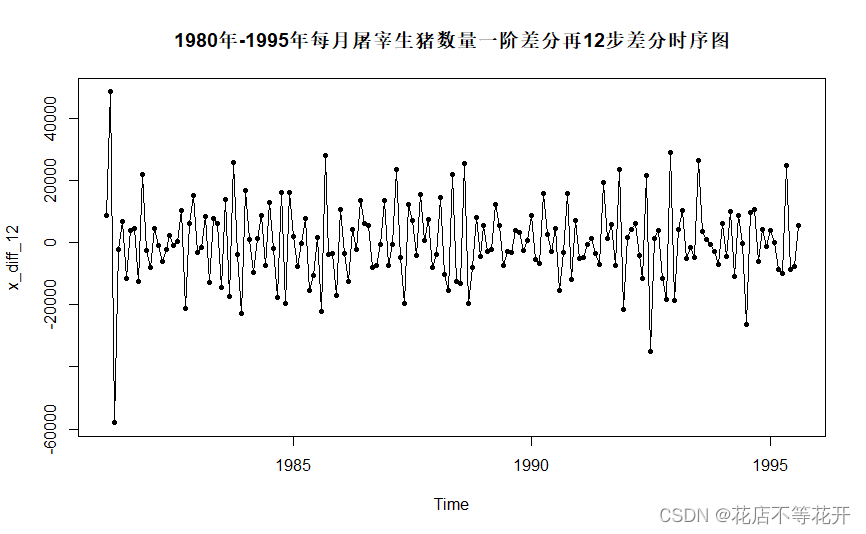
该图为某城市1980年-1995年每月屠宰生猪数量一阶差分再12步差分的时序图,从图上可以看出,此时的序列(x_diff_12)已无显著的趋势或周期且随机波动较平稳,即从图示法的角度,可认为此时的序列是平稳的。
(4)对差分后的序列进行平稳性检验与白噪声检验
由于图示法的判断带有主观因素,因此需要对差分后的序列(x_diff_12)进行ADF检验以判断此时序列是否平稳。再进行白噪声检验,以判断此时差分后的序列(x_diff_12)是否具有分析价值。
由于此时的时序图关于0对称且无明显趋势性,故不考虑无漂移项及带趋势情况,即不考虑类型c、ct,选择无漂移项自回归模型,即类型nc。
相关代码如下:
library(fBasics)
library(fUnitRoots)
for(i in 0:3) print(
adfTest(x_diff_12,
lag=i,
type="nc",
title = "1980年-1995年每月屠宰生猪数量单位根检验"))
for(k in 1:2) print(
Box.test(x_diff_12,
lag=6*k,
type="Ljung-Box"))
运行结果如下:
此为运行结果:
Title:
1980年-1995年每月屠宰生猪数量单位根检验
Test Results:
PARAMETER:
Lag Order: 0STATISTIC:
Dickey-Fuller: -20.8558P VALUE:
0.01Description:
Wed Oct 19 23:04:24 2022 by user: 86191
Title:
1980年-1995年每月屠宰生猪数量单位根检验
Test Results:
PARAMETER:
Lag Order: 1STATISTIC:
Dickey-Fuller: -18.5415P VALUE:
0.01Description:
Wed Oct 19 23:04:24 2022 by user: 86191
Title:
1980年-1995年每月屠宰生猪数量单位根检验
Test Results:
PARAMETER:
Lag Order: 2STATISTIC:
Dickey-Fuller: -9.9788P VALUE:
0.01Description:
Wed Oct 19 23:04:24 2022 by user: 86191
Title:
1980年-1995年每月屠宰生猪数量单位根检验
Test Results:
PARAMETER:
Lag Order: 3STATISTIC:
Dickey-Fuller: -8.0826P VALUE:
0.01Description:
Wed Oct 19 23:04:24 2022 by user: 86191
Warning messages:
1: In adfTest(x_diff_12, lag = i, type = "nc", title = "1980年-1995年每月屠宰生猪数量单位根检验") :
p-value smaller than printed p-value
2: In adfTest(x_diff_12, lag = i, type = "nc", title = "1980年-1995年每月屠宰生猪数量单位根检验") :
p-value smaller than printed p-value
3: In adfTest(x_diff_12, lag = i, type = "nc", title = "1980年-1995年每月屠宰生猪数量单位根检验") :
p-value smaller than printed p-value
4: In adfTest(x_diff_12, lag = i, type = "nc", title = "1980年-1995年每月屠宰生猪数量单位根检验") :
p-value smaller than printed p-value
由运行结果可知,无漂移项自回归模型的0-3阶延迟项模型下的ADF检验的p值均为0.01,但提示信息告诉我们,检验的真实的p值小于显示的p值,即真实的p值小于0.01。因此在0.05的显著性水平α下,没有充分理由接受ADF检验的原假设,从而在该序列(x_diff_12)数据下选择备择假设,即我认为差分后的序列(x_diff_12)是平稳序列。接下来再对其(x_diff_12)做白噪声检验。
相关代码如下:
for(k in 1:2) print(
Box.test(x_diff_12,
lag=6*k,
type="Ljung-Box"))
运行结果如下:
Box-Ljung test
data: x_diff_12
X-squared = 55.307, df = 6, p-value = 4.019e-10
Box-Ljung testdata: x_diff_12
X-squared = 78.048, df = 12, p-value = 9.712e-12
检验的结果显示6阶及12阶延迟下LB统计量的p值都远小于0.05的显著性水平α,因此,没有充分理由接受白噪声检验的原假设,从而在该序列(x_diff_12)数据下选择备择假设,即认为该序列具有非纯随机性,即我认为差分后的序列(x_diff_12)为非白噪声序列。
综述,ADF检验和白噪声检验的结果显示对原序列x进行1阶差分再12步差分已将原序列x中的季节信息和循环波动信息提取充分,即季节加法模型适合拟合该序列(x_diff_12)且差分后的序列(x_diff_12)为平稳非白噪声序列。
3、选择适当模型拟合序列
(1)考虑拟合模型
第二步中我们已经判断该序列(x_diff_12)是平稳非白噪声序列,现考察该序列(x_diff_12)的自相关图及偏自相关图,以给该序列(x_diff_12)拟合模型定阶。
相关代码如下:
acf(x_diff_12,60)
pacf(x_diff_12,60)
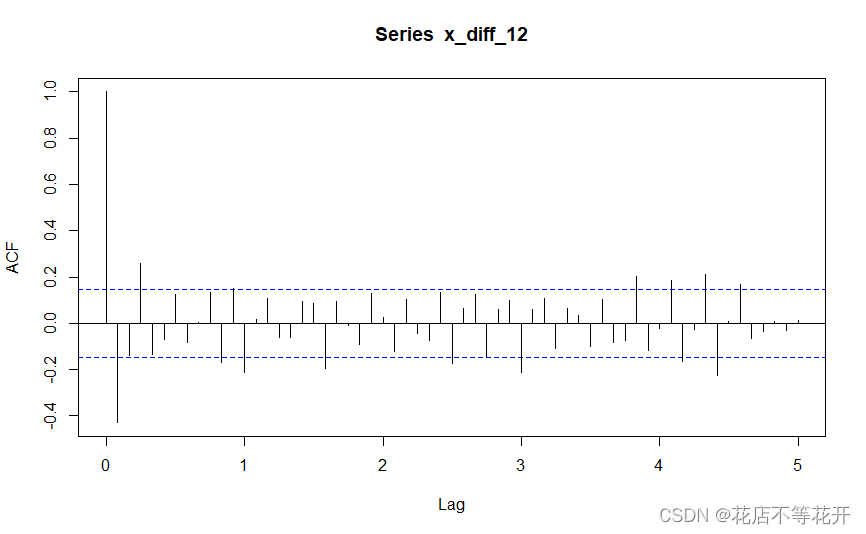
该序列(x_diff_12)的自相关图:
偏自相关图:
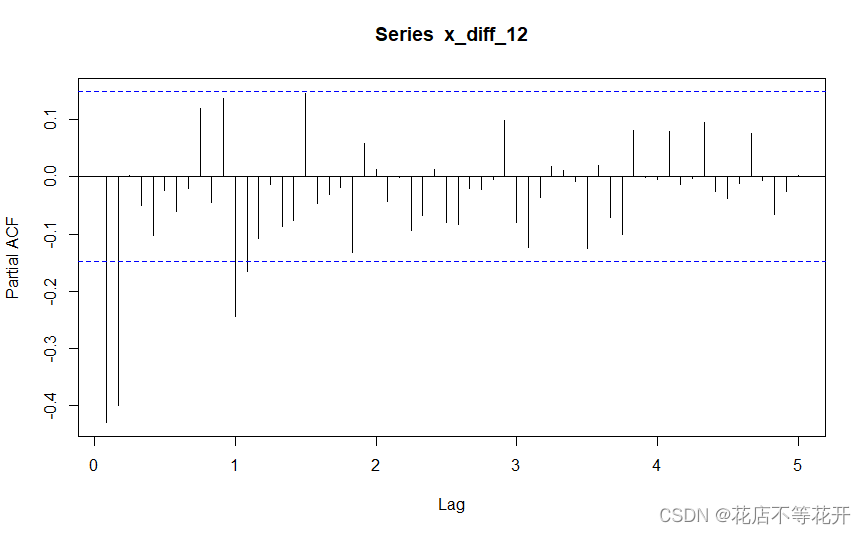
首先考虑1阶12步差分后的序列(x_diff_12)12阶以内的自相关系数和偏自相关系数特征。
从自相关图可以看出,除1阶、3阶、10阶、12阶自相关系数外,其余阶数的自相关系数都在2倍标准差范围内;从偏目相关图可以看出,1阶、2阶、12阶偏自相关系数不在2倍标准差范围内,其余阶数的偏自相关系数都在2倍标准差范围内,其中,一阶和二阶偏自相关系数显著大于2倍标准差,但三阶偏自相关系数却近似为0,因而我认为该序列(x_diff_12)的偏自相关系数的截尾趋势相较于自相关系数更显著一些,从而我考虑对差分后的序列(x_diff_12)拟合AR(2)模型。
此时,12阶以内的自相关系数和偏自相关系数的特征表明该序列具有短期相关性,符合平稳序列具有短期相关性的特征。
现考察延迟12阶之后的自相关系数和偏自相关系数特征。偏自相关图显示延迟12阶自相关系数显著非零,但延迟24阶、36阶、48阶等偏自相关系数均落入2倍标准差范围;而自相关图显示延迟36阶自相关系数非零,且36阶之后非零的自相关系数较多。因此,我认为季节自相关特征是自相关系数拖尾,而偏自相关系数截尾,这时用以12步为周期的ARMA(1,0)12模型提取差分后的序列(x_diff_12)的季节自相关信息。
(2)对拟合模型进行参数估计
由于前面已经对原序列x作了差分,所以实际是对原序列拟合季节加法模型ARIMA(2,(1,12),0),或等价表达为ARIMA(2,1,0)×(1,1,0)12,我使用条件最小二乘估计方法。
相关代码如下:
library(zoo)
library(forecast)
x_fit<-arima(x,order = c(2,1,0),seasonal=list(order=c(1,1,0),period=12),method = "CSS")
x_fit
运行结果如下:
Call:
arima(x = x, order = c(2, 1, 0), seasonal = list(order = c(1, 1, 0), period = 12),
method = "CSS")Coefficients:
ar1 ar2 sar1 -0.662 -0.4778 -0.3825s.e. 0.066 0.0670 0.0684
sigma^2 estimated as 79151147: part log likelihood = -1839.67
由运行结果可知得到该模型为:
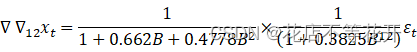 * *,
* *,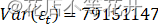
此时拟合的模型的相应参数为:
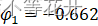 ,
,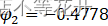 ,
,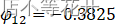
(3)拟合模型的显著性检验与参数的显著性检验
接下来对拟合模型进行模型的有效性检验,以判断拟合模型是否有效,即是否充分提取序列信息。
相关代码如下:
for(k in 1:3) print(
Box.test(x_fit$residuals,
lag=6*k,
type="Ljung-Box"))
运行结果如下:
Box-Ljung testdata: x_fit$residuals
X-squared = 1.4791, df = 6, p-value = 0.9609
Box-Ljung testdata: x_fit$residuals
X-squared = 19.479, df = 12, p-value = 0.07761
Box-Ljung testdata: x_fit$residuals
X-squared = 25.757, df = 18, p-value = 0.1054
从运行结果可以看到,延迟6阶、12阶及18阶下LB统计量的p值都大于0.05的显著性水平α,因此,我没有充分理由拒绝模型显著性检验的原假设,即在该序列(x_diff_12)数据下认为拟合模型具有有效性,即拟合模型有效。
接下来对拟合模型的参数进行显著性检验,以使拟合模型精简。
相关代码如下:
qt(0.975,185)
#ar1系数检验
t1<-0.662/0.066;t1
pt(t1,df=185,lower.tail = T)
#ar2检验
t1<-0.4778/0.0670;t1
pt(t1,df=185,lower.tail = T)
#sar1检验
t3<-0.3825/0.0684;t3
pt(t3,df=185,lower.tail = T)
运行结果如下:
qt(0.975,185)
[1] 1.97287
#ar1系数检验
t1<-0.662/0.066;t1
[1] 10.0303
pt(t1,df=185,lower.tail = T)
[1] 1
#ar2检验
t1<-0.4778/0.0670;t1
[1] 7.131343
pt(t1,df=185,lower.tail = T)
[1] 1
#sar1检验
t3<-0.3825/0.0684;t3
[1] 5.592105
pt(t3,df=185,lower.tail = T)
参数的显著性检验结果显示,参数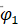 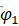,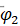 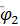及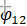 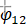的检验统计量的值分别为10.0303、7.1313、5.5921,都大于自由度为185的t分布的0.975分位点,即没有充分理由接受原假设,从而我们认为参数显著非零,即模型无需简化。参数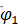, 及 此时实际p值远小于0.0001,而并非结果显示的1。
4、对该序列进行预测
接下来对原序列x进行为期五年的预测并给出预测值及置信区间
相关代码如下:
library(forecast)
x.fore<-forecast(x_fit,h=60,level = c(95))
x.fore
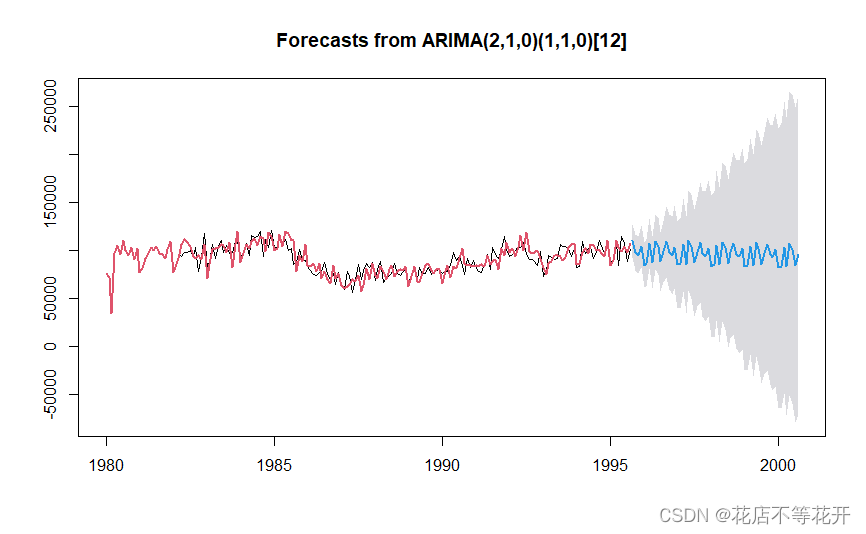
plot(x.fore)
lines(x.fore$fitted,col=2,lwd=2)
未来五年间每月的预测值及其95%的置信区间如下:
Point Forecast Lo 95 Hi 95Sep 1995 109927.10 92489.904 127364.3
Oct 1995 97867.03 79460.975 116273.1
Nov 1995 95149.31 76021.573 114277.1
Dec 1995 103911.17 81757.779 126064.6
Jan 1996 84410.65 61005.553 107815.7
Feb 1996 86315.87 61858.137 110773.6
Mar 1996 106823.32 80717.063 132929.6
Apr 1996 87532.14 60227.205 114837.1
May 1996 108938.98 80547.909 137330.0
Jun 1996 104278.74 74652.576 133904.9
Jul 1996 88135.87 57417.904 118853.8
Aug 1996 98771.89 67024.489 130519.3
Sep 1996 108853.57 71846.084 145861.1
Oct 1996 98095.13 59257.188 136933.1
Nov 1996 94925.78 54472.448 135379.1
Dec 1996 103143.10 59969.724 146316.5
Jan 1997 84948.30 39914.006 129982.6
Feb 1997 86524.90 39783.656 133266.1
Mar 1997 105616.72 56881.811 154351.6
Apr 1997 85122.50 34660.173 135584.8
May 1997 110043.22 57946.681 162139.8
Jun 1997 104051.91 50264.841 157839.0
Jul 1997 86868.32 31494.424 142242.2
Aug 1997 98261.34 41359.292 155163.4
Sep 1997 108091.28 45294.615 170888.0
Oct 1997 96834.14 31596.397 162071.9
Nov 1997 93837.62 26389.035 161286.2
Dec 1997 102263.57 31398.821 173128.3
Jan 1998 83569.05 10214.654 156923.4
Feb 1998 85271.37 9597.444 160945.3
Mar 1998 104904.81 26591.407 183218.2
Apr 1998 84870.69 4215.914 165525.5
May 1998 108447.28 25557.667 191336.9
Jun 1998 102965.17 17778.657 188151.7
Jul 1998 86179.65 -1183.669 173543.0
Aug 1998 97283.11 7812.378 186753.8
Sep 1998 107209.36 12246.931 202171.8
Oct 1998 96142.97 -1701.383 193987.3
Nov 1998 93080.34 -7443.287 193604.0
Dec 1998 101426.48 -2748.799 205601.8
Jan 1999 82923.11 -24151.914 189998.1
Feb 1999 84577.34 -25246.385 194401.1
Mar 1999 104003.60 -8827.113 216834.3
Apr 1999 83793.49 -31788.619 199375.6
May 1999 107884.24 -10350.834 226119.3
Jun 1999 102207.35 -18725.043 223139.7
Jul 1999 85269.56 -38250.436 208789.6
Aug 1999 96483.78 -29556.571 222524.1
Sep 1999 106373.19 -25259.703 238006.1
Oct 1999 95233.83 -39656.910 230124.6
Nov 1999 92196.49 -45762.893 230155.9
Dec 1999 100573.16 -41358.987 242505.3
Jan 2000 81996.67 -63213.488 227206.8
Feb 2000 83669.30 -64676.159 232014.8
Mar 2000 103174.81 -48548.736 254898.4
Apr 2000 83032.01 -71827.747 237891.8
May 2000 106926.09 -50974.836 264827.0
Jun 2000 101323.71 -59658.924 262306.3
Jul 2000 84444.16 -79513.561 248401.9
Aug 2000 95616.01 -71250.197 262482.2
预测图如下,黑色的线是观察值,红色的是拟合值,蓝色的线是预测曲线
版权归原作者 花店不等花开 所有, 如有侵权,请联系我们删除。