
LoFTR: Detector-Free Local Feature Matching with Transformers
LoFTR:基于Transformer实现局部特征匹配
发表时间:[Submitted on 1 Apr 2021]
发表期刊/会议:Computer Vision and Pattern Recognition
论文地址:https://arxiv.org/abs/2104.00680
代码地址:https://zju3dv.github.io/loftr/
0 摘要
本文提出一种新的图像局部特征匹配方法(关键点匹配);
与传统方法(特征检测-描述符-匹配)不同,本文首先在粗粒度上进行像素级密集匹配然后再细粒度进行优化。
本文在Transformer中使用自注意层(self attention layer)和交叉注意层(cross attention layer)来获取两个图像的特征描述符;
在室内数据集和室外数据集上实验,表明,LoFTR很大程度上优于现在的方法。
1 简介
现有的匹配方法大多数包含三个阶段:特征检测-特征描述-特征匹配;
由于纹理稀疏、纹理重复、视点变化、光照变化等原因,特征检测器可能无法提取足够的特征点(第一阶段就效果不好,后面就不用说了);
最近一些工作通过建立像素级密集匹配来解决这个问题,由于CNN感受野小,效果并不好。
图1:LoFTR方法与SuperGlue方法比较。
LoFTR能够在没有纹理的墙壁和地板上找到更多的关键点。基于特征检测的方法SuperGlue找不到可匹配的关键点。
基于以上结果,本文提出一种新的不用检测器的局部特征匹配方法LoFTR,此方法采用self attention和cross attention来处理从CNN中提取的密集局部特征。
- 利用CNN提取低分辨率特征;
- 特征经过LoFTR模块得到重构特征: - Transformer encoder;- Positional Encoding;- Self attention;- Cross attention;
- 用得到的特征进行粗粒度匹配;
- 对得到的粗粒度用阈值筛选,使用基于相关性的方法细化到像素级;
- 在细粒度(像素级)再次进行匹配;
2 相关工作
基于检测器的局部特征匹配方面的工作:典型如SIFT、ORB;
无检测器局部特征匹配方面的工作:如SIFT FLOW、NCNet;
Transformer方面的相关工作;
3 方法
3.1 局部特征提取
CNN具有局部性和平移等变性归纳偏置,适合提取局部特征。使用FPN(也是CNN的一种)来从图像对
I
A
I^A
IA和
I
B
I^B
IB中提取多级特征:
F ^ A \widehat{F}^A FA和 F ^ B \widehat{F}^B FB分别代表用FPN提取的细粒度特征(原图的1/2,降低计算成本);F ~ A \widetilde{F}^A FA和 F ~ B \widetilde{F}^B FB分别代表用FPN提取的粗粒度特征(原图的1/8,降低计算成本);
图2.1:LoFTR第一步,CNN提取局部特征。
补充:CNN中的归纳偏置
归纳偏置其实就是一种先验知识,一种提前做好的假设。
在CNN中的归纳偏置一般包括两类:①locality(局部性)和②translation equivariance(平移等变性)
① locality:假设相同的区域会有相同的特征,靠得越近的东西相关性能也就越强。局部性可以控制模型的复杂度。
②translation equivariance:由于卷积核是一样的所以不管图片中的物体移动到哪里,只要是同样的输入进来遇到同样的卷积核,那么输出就是一样的。利用平移等变形可以很好的提高模型的泛化能力。
参考论文:https://arxiv.org/abs/2010.08515
3.2 LoFTR模块
提取到特征
F
~
A
\widetilde{F}^A
FA和
F
~
B
\widetilde{F}^B
FB后,通过LoFTR模块来提取位置特征和上下文特征。经过LoFTR模块后的特征用
F
~
t
r
A
\widetilde{F}^A_{tr}
FtrA和
F
~
t
r
B
\widetilde{F}^B_{tr}
FtrB来表示。
步骤(如图2.2所示):
- 1.提取到的特征flatten为向量,加上位置编码;
- 2.self-attention;
- 3.cross-attention;
- 4.重复step2和step3 N c N_c Nc次;
- 5.得到 F ~ t r A \widetilde{F}^A_{tr} FtrA和 F ~ t r B \widetilde{F}^B_{tr} FtrB;
其实就是完全套到Transformer里;
self-attention:自己人问自己人(图A问图A),不要匹配重复了(见图3(b));
cross-attention:自己人问其他人(图A问图B),能不能匹配上(见图3(b));
图3(b):可视化结果。
Feature Visualization:将得到的特征经过PCA降维后,在RGB空间可视化。可以看出,两张图像同种颜色为图一区域,证明特征提取的好。
流程展示: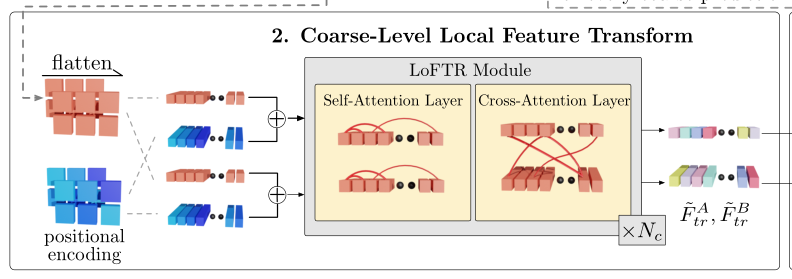
图2.2:LoFTR模块。
3.3 粗粒度匹配
- 计算特征向量之间的匹配概率 P c ( i , j ) P_c(i,j) Pc(i,j);
- 根据阈值 θ c θ_c θc和相互最近邻算法(MNN)来过滤可能的异常值;
假设:
经过Transformer得到区域60 × 80个(非像素级的);
F
~
t
r
A
\widetilde{F}^A_{tr}
FtrA特征向量长度:60 × 80 = 4800;
特征之间的得分矩阵S计算如下(向量内积),S大小为4800;

softmax表示对得分矩阵S进行归一化,得分矩阵进行内积, P c ( i , j ) 大小为 4800 × 4800 P_c(i,j)大小为4800 × 4800 Pc(i,j)大小为4800×4800;
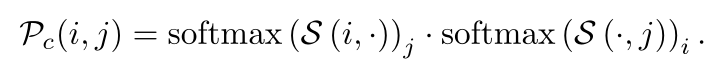
置信度大于阈值 θ c θ_c θc并且是相互最近邻(MNN);

如下图所示:

图2.3:计算粗粒度匹配。
- 输入图像大小为 H × W,降采样8倍,图像大小变为 ( 1 8 × H ) × ( 1 8 × W ) (\frac{1}{8}×H)×(\frac{1}{8}×W) (81×H)×(81×W);
- flatten成特征向量后长度为 ( 1 8 ) 2 × H × W (\frac{1}{8})^2×H×W (81)2×H×W,故 P c P_c Pc矩阵边长为 ( 1 8 ) 2 × H × W (\frac{1}{8})^2×H×W (81)2×H×W, P c P_c Pc矩阵大小为 ( ( 1 8 ) 2 × H × W ) 2 ((\frac{1}{8})^2×H×W)^2 ((81)2×H×W)2;
代码:
defforward(self, feat_c0, feat_c1, data, mask_c0=None, mask_c1=None):
N, L, S, C = feat_c0.size(0), feat_c0.size(1), feat_c1.size(1), feat_c0.size(2)# normalize# 两个特征
feat_c0, feat_c1 =map(lambda feat: feat / feat.shape[-1]**.5,[feat_c0, feat_c1])print("feat_c0 shape",feat_c0.shape)print("feat_c1 shape", feat_c1.shape)if self.match_type =='dual_softmax':# 计算矩阵S# torch.einsum "nlc,nsc->nls" 矩阵乘法
sim_matrix = torch.einsum("nlc,nsc->nls", feat_c0,
feat_c1)/ self.temperature
if mask_c0 isnotNone:
sim_matrix.masked_fill_(~(mask_c0[...,None]* mask_c1[:,None]).bool(),-INF)# 计算矩阵P_c
conf_matrix = F.softmax(sim_matrix,1)* F.softmax(sim_matrix,2)
3.4 细粒度匹配
步骤:
- 根据粗粒度匹配结果在对应1 / 2图像的对应区域上裁取 w × w w × w w×w大小的块(比如5 × 5的块,这里是像素级了);
- 将这两个 w × w w × w w×w的块放入上述LoFTR模块中,得到新特征向量 F ^ t r A ( i ^ ) \widehat{F}^A_{tr}(\widehat{i}) FtrA(i)和 F ^ t r B ( j ^ ) \widehat{F}^B_{tr}(\widehat{j}) FtrB(j),分别是以点 i ^ \widehat{i} i和 j ^ \widehat{j} j为中心;
- 计算 F ^ t r A ( i ^ ) \widehat{F}^A_{tr}(\widehat{i}) FtrA(i)的中心点向量与 F ^ t r B ( j ^ ) \widehat{F}^B_{tr}(\widehat{j}) FtrB(j)每个向量的相关性(翻译一下:计算图A中心点和图B25个点的相关性)并归一化,得到5 × 5的矩阵;
- 计算概率分布的期望,得到B图上与 i ^ \widehat{i} i点最匹配的点 j ^ ′ \widehat{j}' j′,表示为 M f = ( i ^ , j ^ ′ ) M_f = {(\widehat{i},\widehat{j}')} Mf=(i,j′);

图2.4:细粒度匹配。
代码
classFineMatching(nn.Module):"""FineMatching with s2d paradigm"""def__init__(self):super().__init__()defforward(self, feat_f0, feat_f1, data):
M, WW, C = feat_f0.shape
# 得到w
W =int(math.sqrt(WW))
scale = data['hw0_i'][0]/ data['hw0_f'][0]
self.M, self.W, self.WW, self.C, self.scale = M, W, WW, C, scale
# M:粗粒度匹配到的数量# corner case: if no coarse matches foundif M ==0:assert self.training ==False,"M is always >0, when training, see coarse_matching.py"# logger.warning('No matches found in coarse-level.')
data.update({'expec_f': torch.empty(0,3, device=feat_f0.device),'mkpts0_f': data['mkpts0_c'],'mkpts1_f': data['mkpts1_c'],})return# 中心点
feat_f0_picked = feat_f0_picked = feat_f0[:, WW//2,:]
sim_matrix = torch.einsum('mc,mrc->mr', feat_f0_picked, feat_f1)
softmax_temp =1./ C**.5# heatmap: w * w
heatmap = torch.softmax(softmax_temp * sim_matrix, dim=1).view(-1, W, W)# compute coordinates from heatmap# 求期望
coords_normalized = dsnt.spatial_expectation2d(heatmap[None],True)[0]# [M, 2]# 热图
grid_normalized = create_meshgrid(W, W,True, heatmap.device).reshape(1,-1,2)# [1, WW, 2]# compute std over <x, y>
var = torch.sum(grid_normalized**2* heatmap.view(-1, WW,1), dim=1)- coords_normalized**2# [M, 2]
std = torch.sum(torch.sqrt(torch.clamp(var,min=1e-10)),-1)# [M] clamp needed for numerical stability# for fine-level supervision
data.update({'expec_f': torch.cat([coords_normalized, std.unsqueeze(1)],-1)})# compute absolute kpt coords
self.get_fine_match(coords_normalized, data)@torch.no_grad()defget_fine_match(self, coords_normed, data):
W, WW, C, scale = self.W, self.WW, self.C, self.scale
# mkpts0_f and mkpts1_f
mkpts0_f = data['mkpts0_c']
scale1 = scale * data['scale1'][data['b_ids']]if'scale0'in data else scale
mkpts1_f = data['mkpts1_c']+(coords_normed *(W //2)* scale1)[:len(data['mconf'])]
data.update({"mkpts0_f": mkpts0_f,"mkpts1_f": mkpts1_f
})
4 代码
4.1 LoFTR pipeline
classLoFTR(nn.Module):def__init__(self, config):super().__init__()# Misc
self.config = config
# Modules# FPN: resnet as backbone
self.backbone = build_backbone(config)# 位置编码
self.pos_encoding = PositionEncodingSine(
config['coarse']['d_model'],
temp_bug_fix=config['coarse']['temp_bug_fix'])# LoFTR module
self.loftr_coarse = LocalFeatureTransformer(config['coarse'])# 粗粒度匹配
self.coarse_matching = CoarseMatching(config['match_coarse'])# 细粒度匹配前的数据预处理
self.fine_preprocess = FinePreprocess(config)# LoFTR module(与粗粒度的配置不同)
self.loftr_fine = LocalFeatureTransformer(config["fine"])# 细粒度匹配
self.fine_matching = FineMatching()defforward(self, data):"""
Update:
data (dict): {
'image0': (torch.Tensor): (N, 1, H, W)
'image1': (torch.Tensor): (N, 1, H, W)
'mask0'(optional) : (torch.Tensor): (N, H, W) '0' indicates a padded position
'mask1'(optional) : (torch.Tensor): (N, H, W)
}
"""# 1. Local Feature CNN
data.update({'bs': data['image0'].size(0),'hw0_i': data['image0'].shape[2:],'hw1_i': data['image1'].shape[2:]})# input.shape: (640,480)if data['hw0_i']== data['hw1_i']:# faster & better BN convergence# backbone cat 拼接两张图像 提取特征
feats_c, feats_f = self.backbone(torch.cat([data['image0'], data['image1']], dim=0))# feats_c.shape: torch.Size([2,256,60,80]) 1 / 8# feats_f.shape: torch.Size([2,128,240,320]) 1 / 2# 两张特征图分开(feat_c0, feat_c1),(feat_f0, feat_f1)= feats_c.split(data['bs']), feats_f.split(data['bs'])else:# handle different input shapes(feat_c0, feat_f0),(feat_c1, feat_f1)= self.backbone(data['image0']), self.backbone(data['image1'])
data.update({'hw0_c': feat_c0.shape[2:],'hw1_c': feat_c1.shape[2:],'hw0_f': feat_f0.shape[2:],'hw1_f': feat_f1.shape[2:]})# 2. coarse-level loftr module# add featmap with positional encoding, then flatten it to sequence [N, HW, C]# 位置编码
feat_c0 = rearrange(self.pos_encoding(feat_c0),'n c h w -> n (h w) c')
feat_c1 = rearrange(self.pos_encoding(feat_c1),'n c h w -> n (h w) c')
mask_c0 = mask_c1 =None# mask is useful in trainingif'mask0'in data:
mask_c0, mask_c1 = data['mask0'].flatten(-2), data['mask1'].flatten(-2)# 经过LoFTR module编码
feat_c0, feat_c1 = self.loftr_coarse(feat_c0, feat_c1, mask_c0, mask_c1)# 3. match coarse-level 粗粒度匹配
self.coarse_matching(feat_c0, feat_c1, data, mask_c0=mask_c0, mask_c1=mask_c1)# 4. fine-level refinement 细粒度匹配数据处理
feat_f0_unfold, feat_f1_unfold = self.fine_preprocess(feat_f0, feat_f1, feat_c0, feat_c1, data)if feat_f0_unfold.size(0)!=0:# at least one coarse level predicted
feat_f0_unfold, feat_f1_unfold = self.loftr_fine(feat_f0_unfold, feat_f1_unfold)# 5. match fine-level 细粒度匹配
self.fine_matching(feat_f0_unfold, feat_f1_unfold, data)defload_state_dict(self, state_dict,*args,**kwargs):for k inlist(state_dict.keys()):if k.startswith('matcher.'):
state_dict[k.replace('matcher.','',1)]= state_dict.pop(k)returnsuper().load_state_dict(state_dict,*args,**kwargs)
4.2 局部特征提取FPN(对应3.1)
就是一些卷积什么的…
defbuild_backbone(config):if config['backbone_type']=='ResNetFPN':if config['resolution']==(8,2):return ResNetFPN_8_2(config['resnetfpn'])classResNetFPN_8_2(nn.Module):"""
ResNet+FPN, output resolution are 1/8 and 1/2.
Each block has 2 layers.
"""def__init__(self, config):super().__init__()# Config
block = BasicBlock
initial_dim = config['initial_dim']
block_dims = config['block_dims']# Class Variable
self.in_planes = initial_dim
# Networks
self.conv1 = nn.Conv2d(1, initial_dim, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(initial_dim)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(block, block_dims[0], stride=1)# 1/2
self.layer2 = self._make_layer(block, block_dims[1], stride=2)# 1/4
self.layer3 = self._make_layer(block, block_dims[2], stride=2)# 1/8# 3. FPN upsample
self.layer3_outconv = conv1x1(block_dims[2], block_dims[2])
self.layer2_outconv = conv1x1(block_dims[1], block_dims[2])
self.layer2_outconv2 = nn.Sequential(
conv3x3(block_dims[2], block_dims[2]),
nn.BatchNorm2d(block_dims[2]),
nn.LeakyReLU(),
conv3x3(block_dims[2], block_dims[1]),)
self.layer1_outconv = conv1x1(block_dims[0], block_dims[1])
self.layer1_outconv2 = nn.Sequential(
conv3x3(block_dims[1], block_dims[1]),
nn.BatchNorm2d(block_dims[1]),
nn.LeakyReLU(),
conv3x3(block_dims[1], block_dims[0]),)for m in self.modules():ifisinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')elifisinstance(m,(nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight,1)
nn.init.constant_(m.bias,0)def_make_layer(self, block, dim, stride=1):
layer1 = block(self.in_planes, dim, stride=stride)
layer2 = block(dim, dim, stride=1)
layers =(layer1, layer2)
self.in_planes = dim
return nn.Sequential(*layers)defforward(self, x):# ResNet Backbone
x0 = self.relu(self.bn1(self.conv1(x)))
x1 = self.layer1(x0)# 1/2
x2 = self.layer2(x1)# 1/4
x3 = self.layer3(x2)# 1/8# FPN
x3_out = self.layer3_outconv(x3)# 上采样
x3_out_2x = F.interpolate(x3_out, scale_factor=2., mode='bilinear', align_corners=True)
x2_out = self.layer2_outconv(x2)
x2_out = self.layer2_outconv2(x2_out+x3_out_2x)
x2_out_2x = F.interpolate(x2_out, scale_factor=2., mode='bilinear', align_corners=True)
x1_out = self.layer1_outconv(x1)
x1_out = self.layer1_outconv2(x1_out+x2_out_2x)return[x3_out, x1_out]
4.3 位置编码
# 正弦位置编码classPositionEncodingSine(nn.Module):def__init__(self, d_model, max_shape=(256,256), temp_bug_fix=True):super().__init__()
pe = torch.zeros((d_model,*max_shape))# 256 * 256# 1 1 1...# 2 2 2...# ...# 256 256 256...
y_position = torch.ones(max_shape).cumsum(0).float().unsqueeze(0)# # 256 * 256# 1 2 3 ...256# 1 2 3 ...256# 1 2 3 ...256
x_position = torch.ones(max_shape).cumsum(1).float().unsqueeze(0)# div_term: torch.Size([64])if temp_bug_fix:
div_term = torch.exp(torch.arange(0, d_model//2,2).float()*(-math.log(10000.0)/(d_model//2)))else:# a buggy implementation (for backward compatability only)
div_term = torch.exp(torch.arange(0, d_model//2,2).float()*(-math.log(10000.0)/ d_model//2))
div_term = div_term[:,None,None]# [C//4, 1, 1]# pe torch.Size([256, 256, 256])
pe[0::4,:,:]= torch.sin(x_position * div_term)
pe[1::4,:,:]= torch.cos(x_position * div_term)
pe[2::4,:,:]= torch.sin(y_position * div_term)
pe[3::4,:,:]= torch.cos(y_position * div_term)
self.register_buffer('pe', pe.unsqueeze(0), persistent=False)# [1, C, H, W]defforward(self, x):"""
Args:
x: [N, C, H, W]
"""return x + self.pe[:,:,:x.size(2),:x.size(3)]
版权归原作者 不存在的c 所有, 如有侵权,请联系我们删除。