
1、当学习器在训练集上把训练样本自身的一些特征当作了所有潜在样本都具有的一般性质时,泛化性能可能会因此下降,这种现象一般称为 ____。(过拟合/欠拟合)
过拟合
2、对于两个样本点
(
0
,
0
)
,
(
1
,
1
)
(0,0),(1,1)
(0,0),(1,1),若我们将其投影到与拉普拉斯核函数
k
(
x
,
y
)
=
e
−
∣
∣
x
−
y
∣
∣
k(x,y)=e^{-||x-y||}
k(x,y)=e−∣∣x−y∣∣关联的RKHS中时,则两个样本投影后的点距离为 ____(保留三位小数)
1.230
d i s t ( x 1 , x 2 ) = ∥ ϕ ( x 1 ) − ϕ ( x 2 ) ∥ H k 2 = k ( x 1 , x 1 ) − 2 k ( x 1 , x 2 ) + k ( x 2 , x 2 ) dist(x_1,x_2)=\|\phi(x_1)-\phi(x_2)\|_{\mathcal{H}_k}^2=\sqrt{k(x_1,x_1)-2k(x_1,x_2)+k(x_2,x_2)} dist(x1,x2)=∥ϕ(x1)−ϕ(x2)∥Hk2=k(x1,x1)−2k(x1,x2)+k(x2,x2)
3、考虑如下三分类的例子,使用投票法集成的结果的精度为 ____ (保留3位小数)。
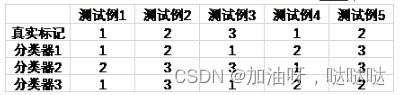
0.200
4、如果为了同时得到多个聚类簇数的聚类结果(如下图所示),最适合使用 ____(原型聚类/密度聚类/层次聚类)
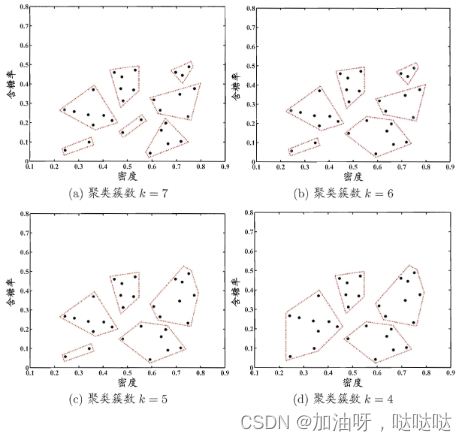
层次聚类
5、下列说法错误的是()
- 信息增益准则对可取值较多的属性有所偏好
- 基尼指数越小,数据集的纯度越高
- 决策树学习时,给定划分属性,若样本在该属性上值缺失,会随机进入一个分支
- 随着决策树学习时的深度加深,位于叶结点的样本越来越少
6、聚类算法是机器学习中一种典型的 ____(监督/无监督)学习算法。
无监督
7、在上题的例子中,每个基分类器的精度都为0.4,因而都是弱分类器,但集成后的精度下降了。这一现象表明在多分类任务中,弱学习器 ____ (能/不能) 保证集成精度不下降。
不能
8、以下关于模型评估与选择的说法,错误的是
- 模型的超参数选择需要在验证集上进行测试
- 交叉验证t检验是基于列联表的
- 训练模型时,仅仅保证训练误差为0是不够的
- 当数据集很大时,通过留一法进行模型评估的计算代价是非常高昂的
9、当多隐层神经网络使用线性激活函数时,下列哪个选项是正确的?
- 经验损失最小化具有唯一解
- 神经网络具有万有逼近性
- 神经网络的输出是权重的线性函数
- 神经网络的输出是输入的线性函数
10、以下关于聚类的说法,错误的是
- 聚类可以作为其他学习算法的前驱过程
- 原型聚类得到的每一簇都是凸的
- 聚类好坏存在绝对标准
- 密度聚类假设聚类结构可以通过本分布的紧密程度确定
11、Sigmoid函数在一点的函数值总是 ____(大于/等于/小于/无法确定) 该点的导数值。
大于
12、以下哪种方式通常不能帮助解决决策树过拟合()
- 去除训练集一半样本
- 预剪枝
- 限制最大树深度
- 后剪枝
13、考虑正类样本(-1,0),(0,1),(-1,1) 和负类样本(1,0),(0,-1),(1,-1),通过支持向量机的基本型得到的解为
- y=x-1
- 以上答案均不是
- y=x+1
- y=x
14、下列说法错误的是
- CART算法的评价指标是基尼系数
- 当样本均匀分布于所有类中时,熵最大
- ID3算法能解决过拟合问题
- 在某些情况下样本特征向量中一些分量没有值,这称为属性缺失
15、以下关于机器学习的说法错误的是
- 在聚类任务中,我们需要事先直到数据的标记信息
- 预测离散值的任务一般称为分类任务
- 同一个算法在不同数据集上,一般不能得到同样一个模型
- 学得模型后,待测试的样本我们称为“测试样本”,亦称“测试示例”
16、下列说法错误的是
- 测试数据应和训练数据一样
- 用数据建立模型的过程叫训练
- 机器学习一般有“独立同分布”假设
- 学得模型是用于新样本的能力称为“泛化”能力
17、决策树划分时,若其中一个属性为样本的编号(各样本编号不同),若基于该属性进行划分,则信息增益最 ____(大/小)
大
18、下列说法错误的是
- 决策树相比于对数几率回归更适合分线性分类问题
- 根据训练数据是狗有标记信息,学习任务可以大致划分为两类:监督学习、无监督学习
- 留一法对模型性能的估计总是比交叉验证法更准确
- 支持向量机的原问题和对偶问题都是二次规划问题
19、下列有关支持向量机,说法正确的是
- 一般情况下,支持向量机训练完后解与全部样本都有关系
- 利用SMO算法求解支持向量机时,只需要迭代更新参数一次
- 支持向量机智能处理线性可跟问题
- 通过支持向量机求解出的划分超平面是对训练样本局部扰动的“容忍”性最好的划分平面
20、如果决策树过拟合训练集,减少决策树最大深度____(是/否)为一个好主意。
是
21、下列哪一种数据集切分方式会导致划分的训练集和测试集与初始数据集分布不同?
- 自助法
- 交叉验证法
- 留出法
- 以上做法都不对
22、下列关于类别不平衡问题的描述中正确的是哪个?
- 当大类和小类一样重要时,需要针对不平衡问题做特殊处理
- 阈值移动法需要构造平衡数据集来处理类别不平衡问题
- 复制小类样本可以搞笑解决类别不平衡问题
- 过采样和欠采样都通过构造平衡数据集来处理类别不平衡问题
23、考虑如图数据集,其中 x1与x2为特征,其取值集合分别为x1={−1,0,1},x2={B,M,S},y为类别标记,其取值集合为y={0,1}。
使用所给训练数据,学习一个朴素贝叶斯分类器,考虑样本x={0,B},请计算P(y=1)P(x|y=1)的值____(保留2位有效数字)。
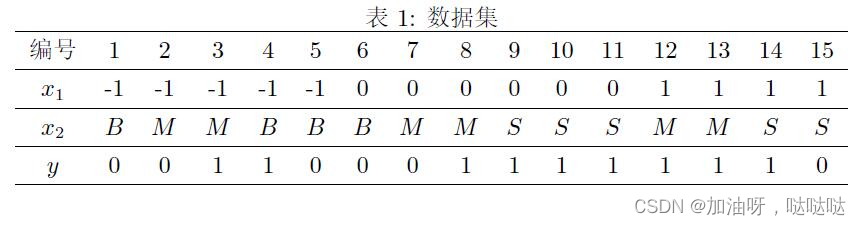
0.03
24、支持向量机原始问题目标函数最优值是对偶问题得到的目标函数最优值的 ____(上界/下界)
上界
25、朴素贝叶斯分类器采用了()假设:即对已知类别,假设所有属性相互独立。
- 独依赖
- 道德图
- 有向无环图依赖
- 属性条件独立性
26、下列关于线性模型的描述中正确的是哪个?
- 线性模型既可以处理回归任务,也可以处理分类任务
- 线性模型无法你和与输入呈指数关系的输出
- 线性模型通过投票法或加权平均法可以得到非线性模型
- 线性模型的表达能力与神经网络相同
27、下列说法错误的是
- 决策树属于生成式模型
- 贝叶斯决策论是概率框架下实施决策的基本理论
- 如果概论都能拿到真实值,那么根据贝叶斯判定准则做出的决策是理论上最好的决策
1 − R ( h ∗ ) 1-R(h^*) 1−R(h∗)反映了分类器所能达到的最好性能
28、若任务中数据的属性是连续值,此类任务称为 ____(分类/回归/不确定)。
不确定
29、使用BP算法优化神经网络,若发现损失函数剧烈波动,可能是优化步长偏 ____ (大/小)。
大
30、下列说法错误的是()
- 极大似然估计需要假设某种概论分布形式
- 对连续属性,计算条件概率 P ( x i ∣ c ) P(x_i|c) P(xi∣c)可考虑概率密度函数
- 贝叶斯学习等于贝叶斯分类器
- 朴素贝叶斯分类器中,对给定类别,模型假设所有属性间相互独立
31、设
n
∈
N
+
n \in N^+
n∈N+为一正自然数,考虑数据集
D
n
=
{
(
−
i
,
−
1
)
,
(
i
,
1
)
}
i
=
1
n
D_n=\{(-i, -1), (i, 1)\}_{i=1}^n
Dn={(−i,−1),(i,1)}i=1n。记
w
n
w_n
wn为最小二乘法在数据集
D
n
D_n
Dn 上学得的线性模型的斜率,则的
l
i
m
n
→
+
∞
n
w
n
\underset{n \rightarrow +\infty}{lim} ~nw_n
n→+∞lim nwn 值为 1.234(保留3位小数或填写"不存在")。
1.500
32、下列关于集成学习的说法中正确的是哪个?
- 已有的多样性定义可以作为优化目标直接优化
- 个体学习器犯错的样本具有一定差异性是集成学习取得好性能的要求之一
- Boosting中所有个体学习器的权重是相等的
- Bagging中不同个体学习器的数据是从统一数据集中采样得到的,因而需要其他途径使基学习器具有多样性
33、下列关于BP算法的说法中正确的是哪个?
- BP算法可以找到神经网络的全局极小解
- 只有Sigmoid激活函数的神经网络可以使用BP算法优化
- 只要模型的损失函数关于模型权重可微,就可以使用BP算法优化
- BP算法能在多项式实践内收敛
34、下列关于多元线性回归中使用正则项的说法中正确的是?
- 即便计算机具有无限精度,多元线性回归也需要使用正则项
- 使用正则化后,多元线性回归可以找到多个最优解
- 样例维度小于样例数是使用正则项的原因之一
- 使用正则项只有理论意义,实际应用中无需使用
35、下列关于神经网络万有逼近性的说法中正确的是哪个?
- 包含足够多神经元的单隐层神经网络具有万有逼近性
- 万有逼近性表明任意一个神经网络在限时任务可以逼近任意函数
- 万有逼近性保证了神经网络在显示任务中优异的表现
- 万有逼近性是神经网络独有的性质
36、当查准率和查全率均为1时,F1度量为 ____。(计算结果保留三位小数)
1.000
37、对于参数估计过程,统计学界的 ____(频率主义/贝叶斯主义)学派认为参数虽然未知,但却是客观存在的固定值,因此,可通过优化似然函数等准则来确定参数值。
频率主义
38、当西瓜收购公司去瓜摊收购西瓜时既希望把好瓜都收走又保证收到的瓜中坏瓜尽可能的少,请问他应该分别考虑什么评价指标?
- 准确率 查全率
- 查全率 查准率
- 查全率 准确率
- 查准率 查全率
39、对率回归 ____ (是/否) 可以通过极大似然估计求解。
是
40、下列哪些函数可以作为核函数?
- 以上函数均可作为核函数
- 多项式核
- 线性核
- 高斯核
版权归原作者 加油呀,哒哒哒 所有, 如有侵权,请联系我们删除。