
0. 摘要
WGAN-GP(Wasserstein GAN with gradient penalty)相比GAN(Generative Adversarial Network)有以下几个优点:
- 更好的损失函数:WGAN-GP使用了Wasserstein距离来度量生成器和判别器之间的距离,相比于GAN中使用的交叉熵损失函数,Wasserstein距离更加稳定,可以避免GAN中出现的训练不稳定和模式崩溃等问题。
- 更好的梯度约束:WGAN-GP在判别器的损失函数中引入了梯度惩罚项,可以约束判别器的梯度范数,避免梯度爆炸和消失的问题,并且可以提高GAN的稳定性。
- 避免模式崩溃:WGAN-GP相比GAN可以避免模式崩溃的问题,即GAN中生成器只生成少数几个样本,而忽略其他的样本情况。
- 生成样本多样性:WGAN-GP可以生成更多样化的样本,因为它能够生成更多种不同的样本,而不是只生成一种样本。
综上所述,WGAN-GP相比GAN在训练稳定性、损失函数、梯度约束、避免模式崩溃和生成样本多样性等方面都有所改进和提升,因此在实际应用中更为常用和有效。
1. 基础知识
本章内容参考了交叉熵、相对熵(KL散度)、JS散度和Wasserstein距离(推土机距离)。
1.1 信息量
“信息量”一词通常指的是一段信息中所包含的有用信息的多少。在信息论中,它被定义为一个事件的信息量与其概率的对数之积。
信息量的单位通常是比特(bit),也可以是其他单位,如字节(byte)、纳特(nat)等。在计算机科学中,常用比特作为信息量的单位,它表示一个二进制位的信息量。
信息量的大小取决于事件的概率,当一个事件的概率较小时,它的信息量较大。例如,如果一个事件的概率是1/2,那么它的信息量为1比特,因为需要1个比特的信息才能表示这个事件的结果。而如果一个事件的概率是1/100,那么它的信息量为7比特,因为需要7个比特的信息才能表示这个事件的结果。
信息量的概念在通信、数据压缩、密码学等领域都有广泛应用。在这些领域中,我们经常需要考虑如何最大限度地压缩数据或传输数据,而信息量的概念可以帮助我们衡量数据的复杂度和传输的难度,从而设计更加高效的算法。
举例说明
假设有一枚硬币,正反两面的概率均为0.5。当我们投掷这枚硬币时,出现正面的概率为0.5,出现反面的概率也为0.5。因此,如果我们想要表示这个事件的结果,只需要1个比特的信息即可,因为一个二进制位可以表示正反两种情况。
现在,假设我们有一个有100面的骰子,每个面的概率均为1/100。当我们投掷这个骰子时,出现任意一个面的概率都为1/100。因此,如果我们想要表示这个事件的结果,需要7个比特的信息才能表示,因为需要用7个二进制位来表示1~100中的任意一个数字。
可以看到,当事件的概率越小,需要的信息量就越大。在这个例子中,硬币的概率是0.5,而骰子的概率是1/100,因此需要的信息量也不同。这个原理同样适用于其他事件,当事件的概率越小,我们需要用更多的信息来表示它的结果,因此信息量也就越大。
1.2 熵
在信息论中,熵是一个随机变量的不确定性度量,也可以理解为信息的缺乏程度。信息论熵的定义通常是基于信息熵公式,即随机变量的熵等于该变量所有可能取值的概率乘以对数概率的累加和的负值。信息熵可以用于评估信源的信息量和传输信道的容量,是信息论中最基本的概念之一。
信息熵公式
信息熵公式是一个随机变量的熵定义,用于计算随机变量的不确定程度。假设随机变量X的取值集合为{x1, x2, ..., xn},它们的概率分别为p1, p2, ..., pn,则随机变量X的信息熵公式为:
当一个事件发生的概率为p(x),那么它的信息量是 −log(p(x))。如果把这个事件的所有可能性罗列出来,就可以求得该事件信息量的期望,信息量的期望就是熵,即上式。
同时,对于二项式分布问题(0-1分布),比如投掷硬币只有正面和反面两种可能,熵的计算方法可以简化为如下算式:
其中log2表示以2为底的对数。公式中,每个p(xi) * log2 p(xi)表示随机变量X取值为xi的信息量,它的单位通常是比特(bit)。整个公式的负数和表示随机变量X的总不确定程度或混乱程度,它的单位也通常是比特(bit)。
需要注意的是,信息熵公式只适用于离散随机变量,对于连续随机变量需要使用其他的熵定义。在信息论中,信息熵公式是一个非常重要的概念,它被广泛应用于数据压缩、密码学、通信等领域。
1.3 相对熵
相对熵(Kullback-Leibler divergence),也称为KL散度,是信息论中一个重要的概念,用于度量两个概率分布之间的距离或差异程度。
假设有两个离散概率分布P和Q,它们的取值集合分别为{x1, x2, ..., xn},它们的概率分别为p1, p2, ..., pn和q1, q2, ..., qn。则P相对于Q的KL散度定义如下:
KL散度的含义是,用Q分布来近似P分布时,每个样本的信息熵损失的期望,也可以理解为将P分布编码成Q分布时的额外信息量。KL散度是一种非对称的度量方式,即Dkl(P||Q) ≠ Dkl(Q||P)。
在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布,那么KL散度就可以计算两个分布的差异,也就是Loss损失值。
从KL散度公式中可以看到Q的分布越接近P(Q分布越拟合P),那么散度值越小,即损失值越小。
因为对数函数是凸函数,所以KL散度的值为非负数。
需要注意的是,KL散度不是真正的距离度量,因为不满足对称性和三角不等式。但是它在信息论和统计学中有广泛应用,例如在模型选择、分类器评估、数据压缩等领域中都有重要作用。
1.4 交叉熵
交叉熵(cross-entropy)是信息论中一个重要的概念,用于度量两个概率分布之间的距离或差异程度。交叉熵常被用于衡量一个概率分布与真实分布之间的差异。
假设有两个离散概率分布P和Q,它们的取值集合分别为{x1, x2, ..., xn},它们的概率分别为p1, p2, ..., pn和q1, q2, ..., qn。则P相对于Q的交叉熵定义如下:
其中log2表示以2为底的对数。交叉熵可以看作是在用Q分布来对P分布进行编码时,每个样本的信息熵的期望值。当P分布与Q分布越接近时,交叉熵越小,反之,交叉熵越大。
将KL散度公式进行变形(如下),可以看到等式的前一项是p的熵,等式的后一项是交叉熵。

1.5 JS散度
JS散度(Jensen-Shannon divergence)是一种度量两个概率分布之间距离的方法,它是对KL散度的改进和扩展。JS散度可以衡量两个概率分布之间的相似性,相比于KL散度,它更加平滑和对称。
假设有两个概率分布P和Q,它们的取值集合为{x1, x2, ..., xn}。则JS散度可以通过以下公式计算:
其中,M是P和Q的中间分布,通常定义为M = 0.5 * (P + Q),即P和Q的平均分布。KL表示KL散度。所以公式也可以表示为:
JS散度与KL散度类似,都是非负的,但是相比于KL散度,JS散度更加平滑和对称。此外,JS散度还具有一些其他的优良性质,例如它满足三角不等式和对称性。
1.6 其它相关概念
- 支撑集(support)其实就是函数的非零部分子集,比如ReLU函数的支撑集就是(0,+∞),一个概率分布的支撑集就是所有概率密度非零部分的集合。
- 流形(manifold)是高维空间中曲线、曲面概念的拓广,我们可以在低维上直观理解这个概念,比如我们说三维空间中的一个曲面是一个二维流形,因为它的本质维度(intrinsic dimension)只有2,一个点在这个二维流形上移动只有两个方向的自由度。同理,三维空间或者二维空间中的一条曲线都是一个一维流形。
- 测度(measure)是高维空间中长度、面积、体积概念的拓广,可以理解为“超体积”。
- 联合分布是指两个或多个随机变量同时出现的概率分布。例如,两个骰子的点数就是一个联合分布。在实际应用中,联合分布常常用于描述多个变量之间的关系和相互作用。
- 边缘分布是指从联合分布中得到单个变量的概率分布。例如,如果有两个随机变量X和Y,它们的联合分布是已知的,那么从联合分布中可以得到X的边缘分布和Y的边缘分布。
- 独立分布是指两个或多个随机变量之间没有任何关联关系。也就是说,它们的出现不会相互影响。例如,抛掷两个骰子,它们的点数是独立分布的。
2. WGAN理论分析
本章内容参考 令人拍案叫绝的Wasserstein GAN 和 WGAN中对KL散度和JS散度的描述 。
2.1 WGAN的改变
Wasserstein GAN(下面简称WGAN)成功地解决了GAN的几点问题:
- 彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
- 基本解决了collapse mode的问题,确保了生成样本的多样性
- 训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高(如图2-1所示)
- 以上一切好处不需要精心设计的网络架构,最简单的多层全连接网络就可以做到

图2-1 WGAN生成器训练进程
虽然作者整整花了两篇论文,说明了改进点,又再从这个改进点出发推了一堆公式定理,最终给出了改进的算法实现流程,而改进后相比原始GAN的算法实现流程却只改了四点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
算法流程图见图2-2。

图2-2 伪代码
2.2 原始GAN中存在的问题
假设 Pr 表示真实样本分布,Pg 是由生成器产生的样本分布。原始GAN中:
判别器损失函数:
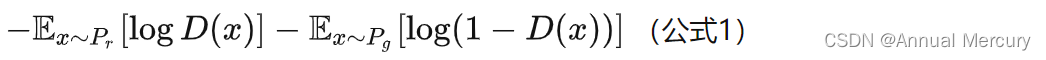
生成器损失函数:

Goodfellow后来又提出了一个改进的生成器损失函数:

最优判别器:
首先从公式1可以得到,在生成器G固定参数时最优的判别器D应该是什么。对于一个具体的样本x,它可能来自真实分布也可能来自生成分布,它对公式1损失函数的贡献是

对判别器进行求导,并令D(x)的导数为0,则:
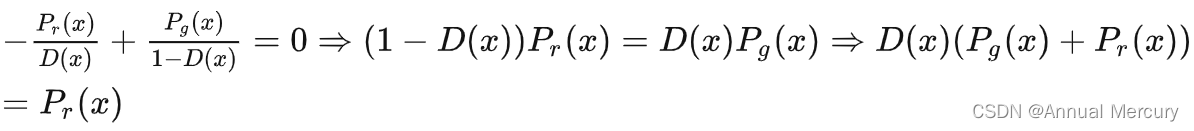
化简得最优判别器为:

从公式4中很容易理解判别器。如果 Pr(x)=0 且 Pg(x)≠0,最优判别器就应该给出概率0;如果Pr(x)≠0 且 Pg(x)=0,最优判别器可以给出概率值1;如果 Pr(x)=Pg(x) ,说明该样本是真是假的可能性五五开,此时最优判别器也应该给出概率0.5,也代表判别器无法分出真假。
2.2.3 第一种生成器损失函数
问题总结:判别器越好,生成器梯度消失越严重
生成器损失函数:
首先给公式2添加一个不依赖生成器的项(真实分布损失:):

最小化这个损失函数等价于最小化公式2,而且它刚好是判别器损失函数的反。代入最优判别器即公式4,再进行简单的变换可以得到:
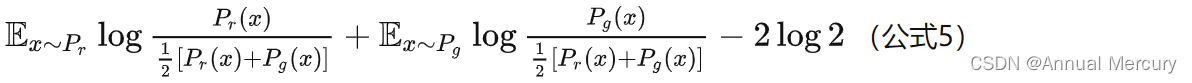
已知JS散度(见公式6):
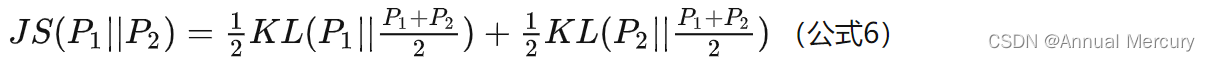
所以公式5就可以继续写成:

公式7即为生产器损失函数1在判别器最优条件下的值。
根据原始GAN定义的判别器loss,我们可以得到最优判别器的形式;而在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布 Pr 与生成分布 Pg 之间的JS散度。我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化 Pr 和 Pg 之间的JS散度。
问题就出在这个JS散度上。我们会希望如果两个分布之间越接近它们的JS散度越小,我们通过优化JS散度就能将 Pr “拉向” Pg,最终以假乱真。这个希望在两个分布有所重叠的时候是成立的,但是如果两个分布完全没有重叠的部分,或者它们重叠的部分可忽略,那它们的JS散度就变成了log2。
因为对于任意一个x只有四种可能:

表2-1 JS散度的四种情况分析
第一种情况对计算JS散度无贡献第二种情况由于重叠部分可忽略所以贡献也为0第三种情况对公式6右边第一个项的贡献是 第四种情况与第三种情况类似最终结果
换句话说,无论 Pg 跟 Pr 是远在天边,还是近在眼前,只要它们俩没有一点重叠或者重叠部分可忽略,JS散度就固定是常数log2,而这对于梯度下降方法意味着——梯度为0!此时对于最优判别器来说,生成器肯定是得不到一丁点梯度信息的;即使对于接近最优的判别器来说,生成器也有很大机会面临梯度消失的问题。
实际上,Pr 与 Pg 不重叠或重叠部分可忽略的可能性非常大。比较严谨的答案是:当 Pr 与 Pg 的支撑集(support)是高维空间中的低维流形(manifold)时,Pr 与Pg 重叠部分测度(measure)为0的概率为1。
结论:
在(近似)最优判别器下,最小化生成器的loss等价于最小化 Pr 与 Pg 之间的JS散度,而由于 Pr 与 Pg 几乎不可能有不可忽略的重叠,所以无论它们相距多远JS散度都是常数log2,最终导致生成器的梯度(近似)为0,梯度消失。
2.2.4 第二种生成器损失函数
问题总结:最小化第二种生成器loss函数,会等价于最小化一个不合理的距离衡量,导致两个问题,一是梯度不稳定,二是collapse mode即多样性不足。
生成器损失函数:
上文推导已经得到在最优判别器(公式4)下
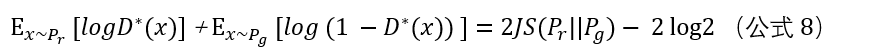
我们可以把KL散度(注意下面是先g后r)变换成含最优判别器(公式4)的形式:

由公式3,8,9可得最小化目标的等价变形
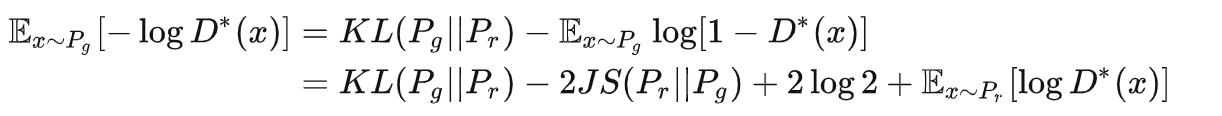
注意上式最后两项不依赖于生成器G,最终得到最小化公式3等价于最小化

这个等价最小化目标存在两个严重的问题。
第一,它同时要最小化生成分布与真实分布的KL散度,却又要最大化两者的JS散度,一个要拉近,一个却要推远!这在直观上非常荒谬,在数值上则会导致梯度不稳定,这是后面那个JS散度项的毛病。
第二,即便是前面那个正常的KL散度项也有毛病。因为KL散度不是一个对称的衡量,KL(Pg||Pr) 与 KL(Pr||Pg) 是有差别的。以前者为例
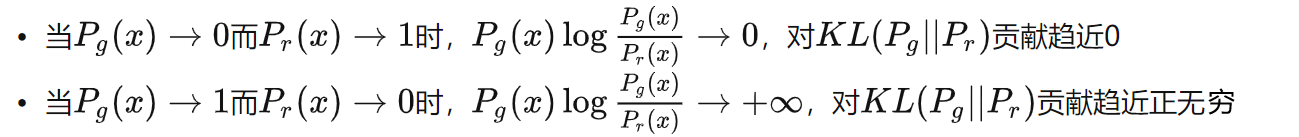
换言之,KL(Pg||Pr) 对于上面两种错误的惩罚是不一样的,第一种错误对应的是“生成器没能生成真实的样本”,惩罚微小;第二种错误对应的是“生成器生成了不真实的样本” ,惩罚巨大。第一种错误对应的是缺乏多样性,第二种错误对应的是缺乏准确性。这一放一打之下,生成器宁可多生成一些重复但是很“安全”的样本,也不愿意去生成多样性的样本,因为那样一不小心就会产生第二种错误,得不偿失。这种现象就是大家常说的collapse mode。
结论:
在原始GAN的(近似)最优判别器下,第一种生成器loss面临梯度消失问题,第二种生成器loss面临优化目标荒谬、梯度不稳定、对多样性与准确性惩罚不平衡导致mode collapse这几个问题。
2.3 GAN到WGAN的一个过渡方案
原始GAN问题的根源可以归结为两点,一是等价优化的距离衡量(KL散度、JS散度)不合理,二是生成器随机初始化后的生成分布很难与真实分布有不可忽略的重叠。
WGAN前作其实已经针对第二点提出了一个解决方案,就是对生成样本和真实样本加噪声,直观上说,使得原本的两个低维流形“弥散”到整个高维空间,强行让它们产生不可忽略的重叠。而一旦存在重叠,JS散度就能真正发挥作用,此时如果两个分布越靠近,它们“弥散”出来的部分重叠得越多,JS散度也会越小而不会一直是一个常数,于是(在第一种原始GAN形式下)梯度消失的问题就解决了。在训练过程中,我们可以对所加的噪声进行退火(annealing),慢慢减小其方差,到后面两个低维流形“本体”都已经有重叠时,就算把噪声完全拿掉,JS散度也能照样发挥作用,继续产生有意义的梯度把两个低维流形拉近,直到它们接近完全重合。以上是对原文的直观解释。
在这个解决方案下我们可以放心地把判别器训练到接近最优,不必担心梯度消失的问题。而当判别器最优时,对公式8取反可得判别器的最小loss为
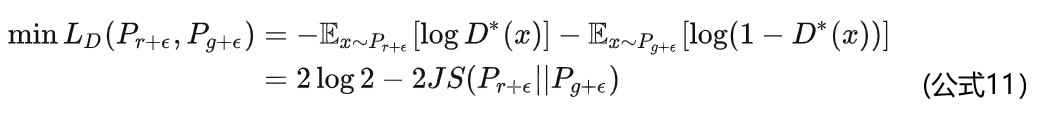
其中 Pr+ϵ 和 Pg+ϵ 分别是加噪后的真实分布与生成分布。反过来说,从最优判别器的loss可以反推出当前两个加噪分布的JS散度。两个加噪分布的JS散度可以在某种程度上代表两个原本分布的距离,也就是说可以通过最优判别器的loss反映训练进程。
但这并不成立,因为加噪JS散度的具体数值受到噪声的方差影响,随着噪声的退火,前后的数值就没法比较了,所以它不能成为 Pr 和 Pg 距离的本质性衡量。
总结:
加噪方案是针对原始GAN问题的第二点根源提出的,解决了训练不稳定的问题,不需要小心平衡判别器训练的火候,可以放心地把判别器训练到接近最优,但是仍然没能够提供一个衡量训练进程的数值指标。但是WGAN本作就从第一点根源出发,用Wasserstein距离代替JS散度,同时完成了稳定训练和进程指标的问题
2.4 Wasserstein距离
Wasserstein距离又叫Earth-Mover(EM)距离,定义如下:
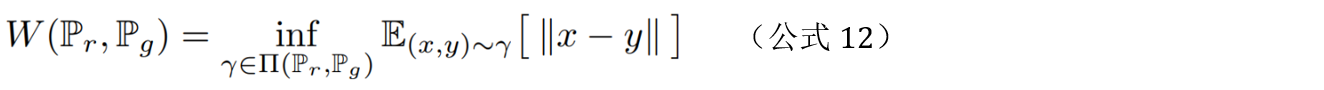
Π(Pr,Pg)是 Pr 和 Pg 分布组合起来的所有可能的联合分布的集合。对于每一个可能的联合分布γ,可以从中采样(x,y)∼γ得到一个样本x和y,并计算出这对样本的距离||x−y||,所以可以计算该联合分布γ下,样本对距离的期望值E(x,y)∼γ[||x−y||]。在所有可能的联合分布中能够对这个期望值取到的下界infγ∼Π(Pr,Pg)E(x,y)∼γ[||x−y||]就是Wasserstein距离。
举例说明
以 28×28×1 的黑白手写数字图片为例。
为了方便说明,假设每个像素点的像素取值都是独立的(真实情况下非但不相互独立,而且依赖程度非常之高),这样我们就可以把 28×28×1 的图片展开成一个784维的向量V,也就是说这组黑白手写数字图片服从某一个784维随机变量的分布。
图2-3 黑白手写数字图片示例
每个像素点都有独立的概率分布,所以每对样本的 Pr 和 Pg 分别包含784个概率分布,每个分布都是0-1分布(二项式分布)。Π(Pr,Pg) 的集合里一共有784个联合分布,分别是对应像素位置组成的联合分布。其第一个像素的联合分布如表2-2,类似地其它像素位置也有对应的联合分布。
表2-2 第1个像素的联合分布
Pg(1,1)\Pr(1,1)01边缘分布01/41/41/2101/21/2边缘分布1/43/41
假设我们根据表2-2的联合分布输出的一对样本的第一个像素点的值为 (x,y)=(1,0),由此可以计算该像素点的距离为 ||x-y||=1。但这离我们需要求的Wasserstein距离还差得远。
这个样本对距离(第一个像素点)的期望值:
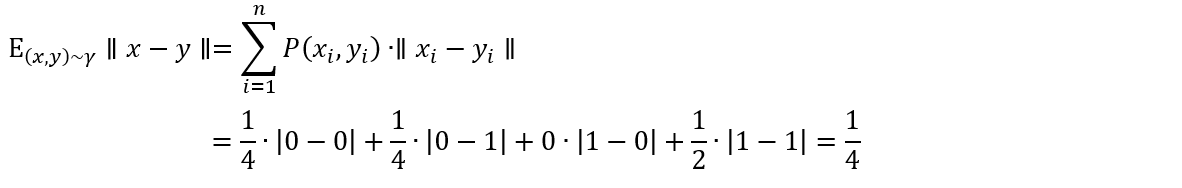
最后,在所有的联合分布下的距离期望值中,找到下界(最小值),即为Wasserstein距离。
直观上可以把E(x,y)∼γ[||x−y||]理解为在γ这个路径规划下把土堆 Pg 挪到土堆 Pr 所需要的消耗。而Wasserstein距离就是在最优路径规划下的最小消耗。所以Wesserstein距离又叫Earth-Mover距离。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近;而JS散度在此情况下是常量,KL散度可能无意义。WGAN本作通过简单的例子展示了这一点。考虑如下二维空间中的两个分布 P1和 P2,P1 在线段AB上均匀分布,P2 在线段CD上均匀分布,通过控制参数 θ 可以控制着两个分布的距离远近。

此时容易得到(读者可自行验证)

总结:
KL散度和JS散度是突变的,要么最大要么最小,Wasserstein距离却是平滑的,如果我们要用梯度下降法优化 θ 这个参数,前两者根本提供不了梯度,Wasserstein距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则KL和JS既反映不了远近,也提供不了梯度,但是Wasserstein却可以提供有意义的梯度。
2.5 从Wasserstein距离到WGAN
Wasserstein距离定义(公式12)中的 infγ~Π(Pr,Pg) 无法直接求解,这可能和数据分布有关。
WGAN的作者用一个已有的定理把它变换为如下形式:
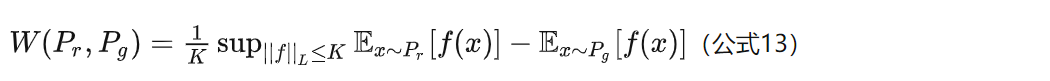
具体的证明过程在WGAN论文的附录中。
式子中存在一个概念--Lipschitz连续:是在一个连续函数 上面额外施加了一个限制,要求存在一个常数 K≥0 使得定义域内的任意两个元素 x1 和 x2 都满足

此时称函数 的Lipschitz常数为 K。
简单理解,比如说 的定义域是实数集合,那上面的要求就等价于
的导函数绝对值不超过 K。再比如说log(x)就不是Lipschitz连续,因为它的导函数没有上界。Lipschitz连续条件限制了一个连续函数的最大局部变动幅度。
公式13的意思就是在要求函数 的Lipschitz常数||
||L不超过 K 的条件下,对所有可能满足条件的
取到
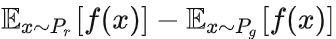 的上界,然后再除以 K。特别地,我们可以用一组参数 w 来定义一系列可能的函数 fw,此时求解公式13可以近似变成求解如下形式:
的上界,然后再除以 K。特别地,我们可以用一组参数 w 来定义一系列可能的函数 fw,此时求解公式13可以近似变成求解如下形式:
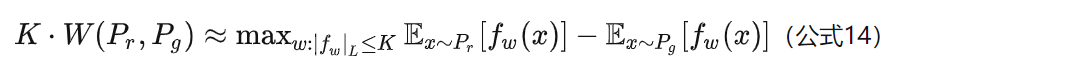
回到深度学习上,可以把 用一个带参数 w 的神经网络来表示。由于神经网络的拟合能力足够强大,这样定义出来的一系列 fw 虽然无法囊括所有可能,但是也足以高度近似公式13要求的那个
 了。
了。
最后,还不能忘了满足公式14中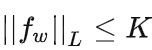 这个限制。我们其实不关心具体的 K 是多少,只要它不是正无穷就行,因为它只是会使得梯度变大 K 倍,并不会影响梯度的方向。所以作者采取了一个非常简单的做法,就是限制神经网络 fθ 的所有参数 wi 的不超过某个范围[−c,c],比如wi∈[−0.01,0.01],此时关于输入样本 x 的导数 ∂fw/∂x 也不会超过某个范围,所以一定存在某个不知道的常数 K 使得 fw 的局部变动幅度不会超过它,Lipschitz连续条件得以满足。具体在算法实现中,只需要每次更新完 w 后把它clip回这个范围就可以了。
这个限制。我们其实不关心具体的 K 是多少,只要它不是正无穷就行,因为它只是会使得梯度变大 K 倍,并不会影响梯度的方向。所以作者采取了一个非常简单的做法,就是限制神经网络 fθ 的所有参数 wi 的不超过某个范围[−c,c],比如wi∈[−0.01,0.01],此时关于输入样本 x 的导数 ∂fw/∂x 也不会超过某个范围,所以一定存在某个不知道的常数 K 使得 fw 的局部变动幅度不会超过它,Lipschitz连续条件得以满足。具体在算法实现中,只需要每次更新完 w 后把它clip回这个范围就可以了。
** 我们可以构造一个含参数 w、最后一层不是非线性激活层的判别器网络 fw,在限制 w 不超过某个范围的条件下,使得**
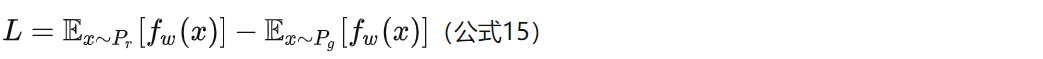
尽可能取到最大,此时 L 就会近似真实分布与生成分布之间的Wasserstein距离(忽略常数倍数K)。注意原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN中的判别器 fw 做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。
接下来生成器要近似地最小化Wasserstein距离,可以最小化 L,由于Wasserstein距离的优良性质,我们不需要担心生成器梯度消失的问题。再考虑到 L 的第一项与生成器无关,就得到了WGAN的两个loss。

公式15是公式17的反,可以指示训练进程,其数值越小,表示真实分布与生成分布的Wasserstein距离越小,GAN训练得越好。
上文说过,WGAN与原始GAN第一种形式相比,只改了四点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
前三点都是从理论分析中得到的,已经介绍完毕;第四点却是作者从实验中发现的,属于trick,相对比较“玄”。作者发现如果使用Adam,判别器的loss有时候会崩掉,当它崩掉时,Adam给出的更新方向与梯度方向夹角的cos值就变成负数,更新方向与梯度方向南辕北辙,这意味着判别器的loss梯度是不稳定的,所以不适合用Adam这类基于动量的优化算法。作者改用RMSProp之后,问题就解决了,因为RMSProp适合梯度不稳定的情况。
2.6 WGAN代码展示
以下是一个简单的WGAN的PyTorch代码实现:
import torch
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.autograd import Variable
# 超参数设置
batch_size = 100
num_epochs = 200
learning_rate = 0.00005
clip_value = 0.01
# 数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
mnist_data = dsets.MNIST(root='./data/', train=True, transform=transform, download=True)
data_loader = torch.utils.data.DataLoader(dataset=mnist_data, batch_size=batch_size, shuffle=True)
# 定义判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv1 = nn.Conv2d(1, 64, 4, 2, 1)
self.conv2 = nn.Conv2d(64, 128, 4, 2, 1)
self.bn2 = nn.BatchNorm2d(128)
self.conv3 = nn.Conv2d(128, 256, 4, 2, 1)
self.bn3 = nn.BatchNorm2d(256)
self.conv4 = nn.Conv2d(256, 512, 4, 2, 1)
self.bn4 = nn.BatchNorm2d(512)
self.conv5 = nn.Conv2d(512, 1, 4, 1, 0)
def forward(self, x):
x = nn.functional.leaky_relu(self.conv1(x), 0.2, inplace=True)
x = nn.functional.leaky_relu(self.bn2(self.conv2(x)), 0.2, inplace=True)
x = nn.functional.leaky_relu(self.bn3(self.conv3(x)), 0.2, inplace=True)
x = nn.functional.leaky_relu(self.bn4(self.conv4(x)), 0.2, inplace=True)
x = self.conv5(x)
return x
# 定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.fc1 = nn.Linear(100, 512 * 7 * 7)
self.conv1 = nn.ConvTranspose2d(512, 256, 4, 2, 1)
self.bn1 = nn.BatchNorm2d(256)
self.conv2 = nn.ConvTranspose2d(256, 128, 4, 2, 1)
self.bn2 = nn.BatchNorm2d(128)
self.conv3 = nn.ConvTranspose2d(128, 64, 4, 2, 1)
self.bn3 = nn.BatchNorm2d(64)
self.conv4 = nn.ConvTranspose2d(64, 1, 4, 2, 1)
def forward(self, x):
x = nn.functional.relu(self.fc1(x))
x = x.view(-1, 512, 7, 7)
x = nn.functional.relu(self.bn1(self.conv1(x)))
x = nn.functional.relu(self.bn2(self.conv2(x)))
x = nn.functional.relu(self.bn3(self.conv3(x)))
x = torch.tanh(self.conv4(x))
return x
# 初始化生成器和判别器
D = Discriminator()
G = Generator()
# 定义损失函数和优化器
criterion = nn.MSELoss()
d_optimizer = torch.optim.RMSprop(D.parameters(), lr=learning_rate)
g_optimizer = torch.optim.RMSprop(G.parameters(), lr=learning_rate)
# 训练模型
for epoch in range(num_epochs):
for i, (images, _) in enumerate(data_loader):
# 训练判别器
real_images = Variable(images)
real_labels = Variable(torch.ones(batch_size, 1))
fake_labels = Variable(torch.zeros(batch_size, 1))
z = Variable(torch.randn(batch_size, 100))
fake_images = G(z)
real_outputs = D(real_images)
fake_outputs = D(fake_images)
d_loss = -torch.mean(real_outputs) + torch.mean(fake_outputs)
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# 截断参数
for p in D.parameters():
p.data.clamp_(-clip_value, clip_value)
# 训练生成器
z = Variable(torch.randn(batch_size, 100))
fake_images= G(z)
outputs = D(fake_images)
g_loss = -torch.mean(outputs)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
# 打印损失
if (i + 1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}'.format(epoch + 1, num_epochs, i + 1, len(mnist_data) // batch_size,d_loss.item(), g_loss.item()))
# 保存生成的图片
if (epoch + 1) % 10 == 0:
fake_images = G(z)
torchvision.utils.save_image(fake_images.data[:25], './images/fake_images-{}.png'.format(epoch + 1), nrow=5, normalize=True)
这个WGAN的实现中,判别器使用了5个卷积层,生成器使用了4个反卷积层。训练过程中,用MSE损失函数作为判别器的损失函数,用Wasserstein距离作为GAN的损失函数。在训练判别器的过程中,需要进行参数截断,以确保Wasserstein距离的连续性。最后,保存了每个epoch生成的25张图片。
3. WGAN-GP分析
3.1 WGAN-GP与WGAN的区别
WGAN-GP和WGAN都是改进版的生成对抗网络(GAN),其中WGAN-GP是在WGAN的基础上进行了一些改进,主要是引入了梯度惩罚(gradient penalty)来替代原来WGAN中的权重剪裁(weight clipping)。
具体来说,WGAN使用权重剪裁来约束判别器的参数,以使其保持Lipschitz连续性,从而避免GAN中的模式崩溃问题。但是,这种方法可能会导致一些不稳定的训练问题,例如模式崩溃和梯度消失。WGAN-GP通过使用梯度惩罚来代替权重剪裁,可以更有效地解决这些问题。
梯度惩罚的方式是在损失函数中添加一个额外的正则化项,该项惩罚判别器在输入样本处的梯度的模长偏离1。这可以强制判别器保持Lipschitz连续性,同时避免权重剪裁可能导致的不稳定性问题。
总的来说,WGAN-GP相对于WGAN,可以更加稳定地训练生成器和判别器,并且生成的样本质量更高。
3.2 WGAN-GP方法介绍
WGAN-GP的目标函数如下所示:
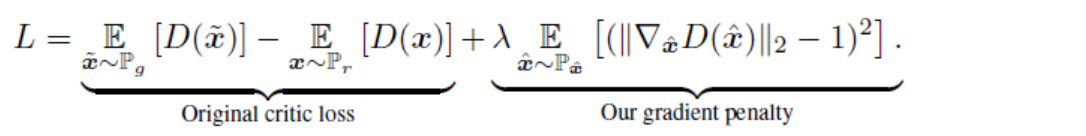
可以看到,WGAN-GP相对于WGAN的改进很小,除了增加了一个正则项,其他部分都和WGAN一样。 这个正则项就是WGAN-GP中GP(gradient penalty),即梯度约束。这个约束的意思是:critic相对于原始输入的梯度的L2范数要约束在1附近(双边约束)。为什么这个约束是合理的,这里作者给了一个命题,并且在文章补充材料中给出了证明,这个证明大家有兴趣可以自己去看,这里只想简单介绍一下这个命题。这个命题说的是在最优的优化路径上(把生成分布推向真实分布的“道路”上),critic函数对其输入的梯度值恒定为1。有了这个知识后,我们可以像搞传统机器学习一样,将这个知识加入到目标函数中,以学习到更好的模型。
这里需要说明一下,WGAN-GP作者加的这个约束能保证critic也是一个Lipschiz连续函数。因为critic对任意输入x的梯度都是一个含参数w的表达式,而这个梯度的L2 norm大小约束在1附近,那w也不超过某个常数。因而从保证Lipschiz连续的条件上,GP的作用跟weight clip是一样的。
下面我们对比下改动前后的损失函数。
WGAN损失函数:

WGAN-GP损失函数:

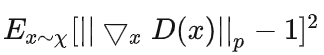 计算思路:放弃对整个样本空间的 D(x) 求导,只需要对真实样本空间,生成样本空间的中间值求导即可。
计算思路:放弃对整个样本空间的 D(x) 求导,只需要对真实样本空间,生成样本空间的中间值求导即可。
具体方法:

梯度惩罚项如此计算的原因:
由公式可知,判别器的梯度的数值空间是整个样本空间,维度过高,难以计算,作者提出没有必要对整个真实样本空间和生成空间进行采样,只需要从每一批次的样本中采样就可以了。
WGAN-GP具体算法步骤如下:

图3-1 WGAN-GP伪代码
3.3 WGAN中存在的问题(CP和GP问题详解)
Lipschitz限制即要求判别器D(x)梯度的Lp_norm不大于一个有限的常熟k。其作用在于当输入样本稍微变化后,判别器给出的分数不会发生太剧烈的变化,以此保证判别器不会对两个略微不同的样本给出天差地别的分数。
weight clipping
判别器的梯度是Lp范数 限制在K以内。
WGAN中这步是通过weight clipping的方式实现的,即每当更新完一次判别器的参数之后,就检查判别器的所有参数的绝对值有没有超过一个阈值,比如0.01,有的话就把这些参数clip回 [-0.01, 0.01] 范围内。
然而这就导致了参数数值分布集中在最大最小两个极端上,这就使得判别器倾向于学习简单的映射函数(几乎所有参数都是正负0.01,都已经可以直接视为一个二值神经网络了)。判别器的性能就会变差。这才就有了WGAN-GP中的Gradient penalty。
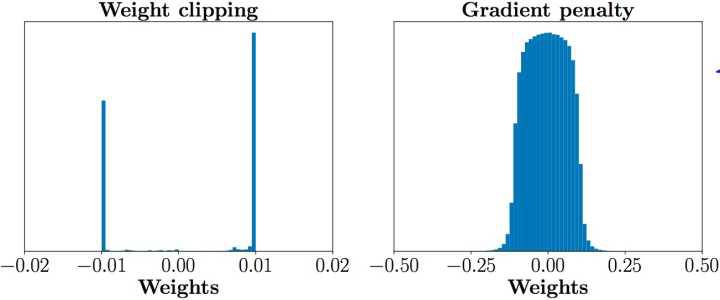
图3-2 WGAN与WGAN-GP判别器优化后的参数对比

图3-3 WGAN与WGAN-GP梯度对比
Gradient penalty

WGAN-GP中设置了一个额外的Loss来限制判别器的梯度,公式如上。文中k取值为1。
作者提出,我们没必要在整个样本空间上施加Lipschitz限制,只要重点抓住生成样本集中区域、真实样本集中区域以及夹在它们中间的区域就行了。具体来说,我们先随机采一对真假样本,还有一个0-1的随机数:

interpolates就是随机插值采样得到的图像,gradients就是loss中的梯度惩罚项,限制判别器的loss中所求的就是interpolates的梯度的梯度。将该公式与WGAN中原本的判别器的损失函数加权合并,就得到新的判别器loss:
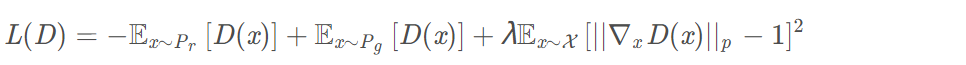
3.4 WGAN-GP代码展示
下面是一个简单的WGAN-GP的PyTorch实现,包括生成器和判别器的网络结构以及训练循环和梯度惩罚的代码。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.autograd import grad
# 定义生成器网络
class Generator(nn.Module):
def __init__(self, z_dim, img_channels, img_size):
super(Generator, self).__init__()
self.img_size = img_size
self.net = nn.Sequential(
nn.Linear(z_dim, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512, img_size*img_size*img_channels),
nn.Tanh()
)
def forward(self, x):
x = self.net(x)
x = x.view(x.shape[0], -1, self.img_size, self.img_size)
return x
# 定义判别器网络
class Discriminator(nn.Module):
def __init__(self, img_channels, img_size):
super(Discriminator, self).__init__()
self.img_size = img_size
self.net = nn.Sequential(
nn.Conv2d(img_channels, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 1, 4, 1, 0, bias=False),
)
def forward(self, x):
x = self.net(x)
x = x.view(x.shape[0], -1)
return x
# 定义超参数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
lr = 0.0002
batch_size = 64
z_dim = 100
img_channels = 1
img_size = 28
n_critic = 5
lambda_gp = 10
# 加载MNIST数据集
transform = transforms.Compose([
transforms.Resize(img_size),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
# 初始化生成器和判别器
generator = Generator(z_dim, img_channels, img_size).to(device)
discriminator = Discriminator(img_channels, img_size).to(device)
# 定义优化器
optimizer_G = optim.Adam(generator.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=lr, betas=(0.5, 0.999))
# 定义训练循环
for epoch in range(num_epochs):
for i, (real_images, _) in enumerate(train_loader):
real_images = real_images.to(device)
batch_size = real_images.shape[0]
# 训练判别器
for _ in range(n_critic):
z = torch.randn(batch_size, z_dim).to(device)
fake_images = generator(z)
critic_real = discriminator(real_images)
critic_fake = discriminator(fake_images)
gradient_penalty = compute_gradient_penalty(discriminator, real_images, fake_images, device)
loss_D = critic_fake.mean() - critic_real.mean() + lambda_gp * gradient_penalty
optimizer_D.zero_grad()
loss_D.backward(retain_graph=True)
optimizer_D.step()
# 训练生成器
z = torch.randn(batch_size, z_dim).to(device)
fake_images = generator(z)
critic_fake = discriminator(fake_images)
loss_G = -critic_fake.mean()
optimizer_G.zero_grad()
loss_G.backward()
optimizer_G.step()
# 定义梯度惩罚函数
def compute_gradient_penalty(discriminator, real_images, fake_images, device):
alpha = torch.rand(real_images.shape[0], 1, 1, 1).to(device)
interpolates = (alpha * real_images + (1 - alpha) * fake_images).requires_grad_(True)
d_interpolates = discriminator(interpolates)
gradients = grad(outputs=d_interpolates, inputs=interpolates,
grad_outputs=torch.ones(d_interpolates.size()).to(device),
create_graph=True, retain_graph=True, only_inputs=True)[0]
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty
# 训练完成后,使用生成器生成一些样本进行测试
num_samples = 16
z = torch.randn(num_samples, z_dim).to(device)
generated_images = generator(z).detach()
generated_images = generated_images.cpu().numpy()
# 将生成的图像可视化
import matplotlib.pyplot as plt
fig, axes = plt.subplots(nrows=4, ncols=4, figsize=(5, 5), sharex=True, sharey=True)
for i, ax in enumerate(axes.flatten()):
ax.imshow(generated_images[i][0], cmap='gray')
ax.axis('off')
plt.tight_layout()
plt.show()
这个代码实现了一个基本的WGAN-GP模型,其中包括一个生成器和一个判别器网络,以及训练循环和梯度惩罚函数。您可以根据自己的需求添加其他功能,例如数据增强,模型保存和恢复等。
版权归原作者 Annual Mercury 所有, 如有侵权,请联系我们删除。