
解释说明:目前很多主流的网络模型主要包含backbone+其他结构(分类,回归),那么如何在训练自己的网络模型时使用别人已经训练好的网络模型权重呢??本文以Resnet50为例,构建一个基于resnet50的网络模型预训练过程。
1. Torchvision中封装的主流网络模型
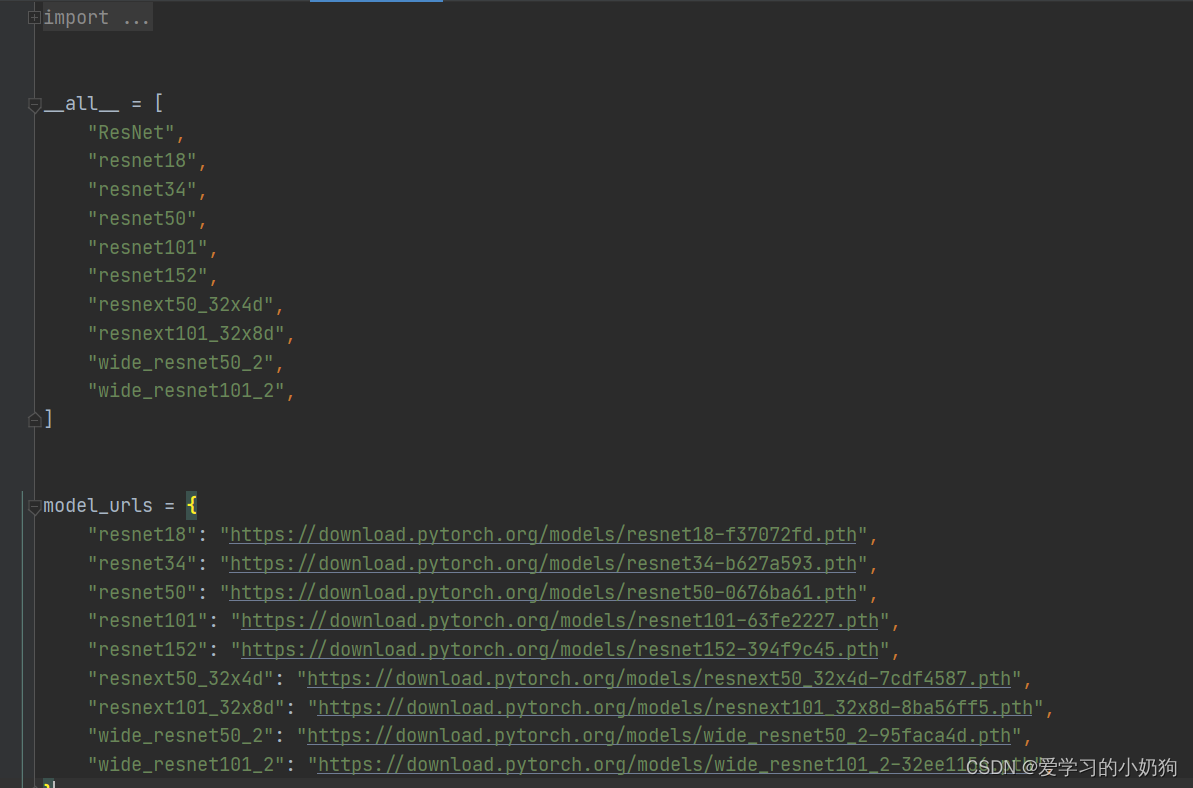
- torchvision中封装了Resnet系列、vgg系列、inception系列等网络模型,切内部给出了每个网络模型预训练权重的url路径
- 如下图所示,为torchvison官方封装的Resnet系列网络
2. 如何使用预训练权重
解释说明:根据自己的理解,使用预训练权重过程主要包含以下几个步骤
- 创建自己的网络模型:前文说道,网络模型主要包含backbone+其他部分(分类、回归等),因此对于任意一个网络模型而言,只要对backbone做预训练处理就行了(即网络backbone部分载入官方训练好的权重,只训练后续的其他部分)
- 从torch官方中载入训练权重字典
- 将torch官方的预训练权重中需要的部分载入进自己的网络模型
模型权重载入完毕后,这是需要根据个人需要,训练时候选择更新网络全部参数还是冻结部分参数值更新后续的其他部分
下面开始撸代码
2.1 创建自己的网络模型
解释说明:这里我创建了一个基于resnet50网络的模型(这个网络是干什么的在此不做解释),网络结构如下
import torch
from torch.nn import Sequential, Conv2d, MaxPool2d, ReLU, BatchNorm2d
from torch import nn
from torch.utils import model_zoo
CLASS_NUM =20# 使用其他训练集需要更改classBottleneck(nn.Module):# 定义基本块def__init__(self, in_channel, out_channel, stride, downsample):super(Bottleneck, self).__init__()
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.in_channel = in_channel
self.out_channel = out_channel
self.bottleneck = Sequential(
Conv2d(in_channel, out_channel, kernel_size=1, stride=stride[0], padding=0, bias=False),
BatchNorm2d(out_channel),
ReLU(inplace=True),
Conv2d(out_channel, out_channel, kernel_size=3, stride=stride[1], padding=1, bias=False),
BatchNorm2d(out_channel),
ReLU(inplace=True),
Conv2d(out_channel, out_channel *4, kernel_size=1, stride=stride[2], padding=0, bias=False),
BatchNorm2d(out_channel *4),)if self.downsample isFalse:# 如果 downsample = True则为Conv_Block 为False为Identity_Block
self.shortcut = Sequential()else:
self.shortcut = Sequential(
Conv2d(self.in_channel, self.out_channel *4, kernel_size=1, stride=stride[0], bias=False),
BatchNorm2d(self.out_channel *4))defforward(self, x):
out = self.bottleneck(x)
out += self.shortcut(x)
out = self.relu(out)return out
classoutput_net(nn.Module):# no expansion# dilation = 2# type B use 1x1 conv
expansion =1def__init__(self, in_planes, planes, stride=1, block_type='A'):super(output_net, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=2, bias=False, dilation=2)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion * planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion * planes)
self.downsample = nn.Sequential()
self.relu = nn.ReLU(inplace=True)if stride !=1or in_planes != self.expansion * planes or block_type =='B':
self.downsample = nn.Sequential(
nn.Conv2d(
in_planes,
self.expansion * planes,
kernel_size=1,
stride=stride,
bias=False),
nn.BatchNorm2d(self.expansion * planes))defforward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.downsample(x)
out = self.relu(out)return out
classResNet50(nn.Module):def__init__(self, block):super(ResNet50, self).__init__()
self.block = block
self.layer0 = Sequential(
Conv2d(3,64, kernel_size=7, stride=2, padding=3, bias=False),
BatchNorm2d(64),
ReLU(inplace=True),
MaxPool2d(kernel_size=3, stride=2, padding=1))
self.layer1 = self.make_layer(self.block, channel=[64,64], stride1=[1,1,1], stride2=[1,1,1], n_re=3)
self.layer2 = self.make_layer(self.block, channel=[256,128], stride1=[2,1,1], stride2=[1,1,1], n_re=4)
self.layer3 = self.make_layer(self.block, channel=[512,256], stride1=[2,1,1], stride2=[1,1,1], n_re=6)
self.layer4 = self.make_layer(self.block, channel=[1024,512], stride1=[2,1,1], stride2=[1,1,1], n_re=3)
self.layer5 = self._make_output_layer(in_channels=2048)
self.avgpool = nn.AvgPool2d(2)# kernel_size = 2 , stride = 2
self.conv_end = nn.Conv2d(256,int(CLASS_NUM +10), kernel_size=3, stride=1, padding=1, bias=False)
self.bn_end = nn.BatchNorm2d(int(CLASS_NUM +10))defmake_layer(self, block, channel, stride1, stride2, n_re):
layers =[]for num_layer inrange(0, n_re):if num_layer ==0:
layers.append(block(channel[0], channel[1], stride1, downsample=True))else:
layers.append(block(channel[1]*4, channel[1], stride2, downsample=False))return Sequential(*layers)def_make_output_layer(self, in_channels):
layers =[]
layers.append(
output_net(
in_planes=in_channels,
planes=256,
block_type='B'))
layers.append(
output_net(
in_planes=256,
planes=256,
block_type='A'))
layers.append(
output_net(
in_planes=256,
planes=256,
block_type='A'))return nn.Sequential(*layers)defforward(self, x):# print(x.shape) # 3*448*448
out = self.layer0(x)# print(out.shape) # 64*112*112
out = self.layer1(out)# print(out.shape) # 256*112*112
out = self.layer2(out)# print(out.shape) # 512*56*56
out = self.layer3(out)# print(out.shape) # 1024*28*28
out = self.layer4(out)# 2048*14*14
out = self.layer5(out)# batch_size*256*14*14
out = self.avgpool(out)# batch_size*256*7*7
out = self.conv_end(out)# batch_size*30*7*7
out = self.bn_end(out)
out = torch.sigmoid(out)
out = out.permute(0,2,3,1)# bitch_size*7*7*30return out
defresnet50():
model = ResNet50(Bottleneck)return model
通过下面代码,分别载入自己的网络模型和torch官方的网络模型,看看模型结构有什么不同
from torchvision import models
import torch
from new_resnet import resnet50
# 获取torch官方restnet50的预训练网络权重参数# pretrained表示是否在内部直接载入resnet50的权重,在这里我们不载入(下载太慢了,我们先现在到本地然后自己手动载入)
resnet = models.resnet50(pretrained=False)
state_dict = torch.load(r"resnet50-0676ba61.pth")
resnet.load_state_dict(state_dict)
new_state_dict = resnet.state_dict()# 获取自己创建的resnet50无训练的空权重
net = resnet50()
op = net.state_dict()print(len(new_state_dict.keys()))# 输出torch官方网络模型字典长度print(len(op.keys()))# 输出自己网络模型字典长度
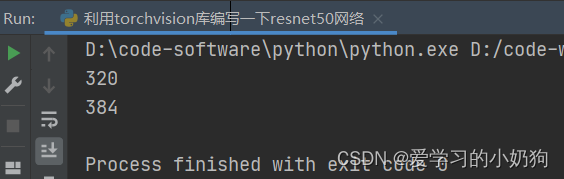
从图中可以看出,torch官方网络模型主要有320个key,我们创建的网络模型有384个key
分别输出两种key有什么不同
from torchvision import models
import torch
from new_resnet import resnet50
# 获取torch官方restnet50的预训练网络权重参数# pretrained表示是否在内部直接载入resnet50的权重,在这里我们不载入(下载太慢了,我们先现在到本地然后自己手动载入)
resnet = models.resnet50(pretrained=False)
state_dict = torch.load(r"resnet50-0676ba61.pth")
resnet.load_state_dict(state_dict)
new_state_dict = resnet.state_dict()# 获取自己创建的resnet50无训练的空权重
net = resnet50()
op = net.state_dict()print(len(new_state_dict.keys()))print(len(op.keys()))for i in new_state_dict.keys():# 查看网络结构的名称 并且得出一共有320个keyprint(i)for j in op.keys():# 查看网络结构的名称 并且得出一共有384个keyprint(j)
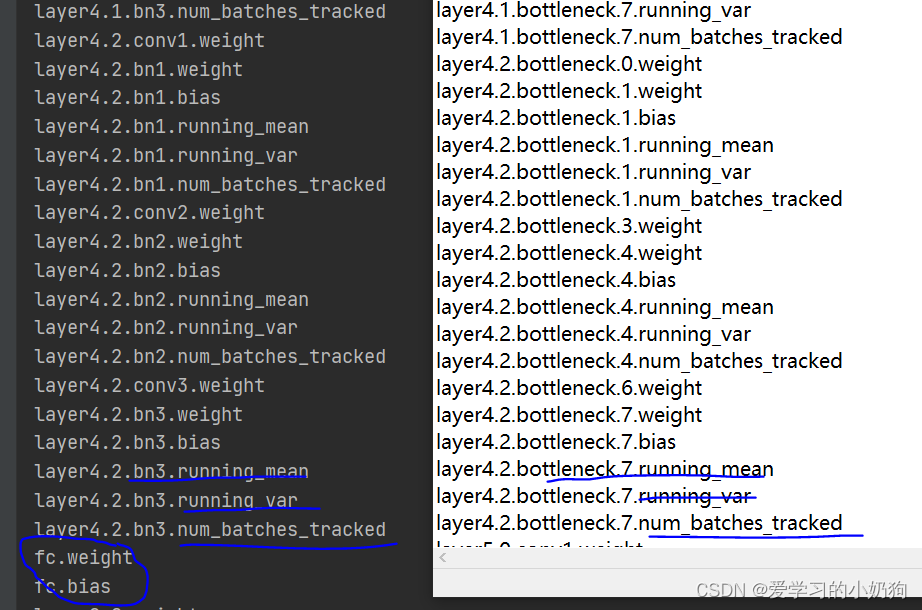
从图中可以看出,我们创建的网络模型和torch官方的网络模型在前318层的结构都是一样的(即网络的backbone),官方的网络模型主要使用两层全连接层做分类,因此我们预训练是不需要这两层参数的,我们只要前面的backbone参数。
2.2 权重参数的载入
两种载入方式,通过2.1可以知道,网络的backbone结构是一样的,在318层后是不一样的。通过观察网络的key可以发现,torch官方的resnet网络模型的key名字和我们自己创建的基于resnet50网络模型的key名字不一样,因此参数的载入主要有两种:
- 当权重字典中的key名字一样时
from torchvision import modelsimport torchfrom new_resnet import resnet50# 获取torch官方restnet50的预训练网络权重参数# pretrained表示是否在内部直接载入resnet50的权重,在这里我们不载入(下载太慢了,我们先现在到本地然后自己手动载入)resnet = models.resnet50(pretrained=False)state_dict = torch.load(r"resnet50-0676ba61.pth")resnet.load_state_dict(state_dict)new_state_dict = resnet.state_dict()# 获取自己创建的resnet50无训练的空权重net = resnet50()op = net.state_dict()# 将new_state_dict里不属于op的键剔除掉pretrained_dict ={k: v for k, v in new_state_dict.items()if k in op}# 更新现有的model_dictop.update(pretrained_dict)# 加载真正需要的state_dictnet.load_state_dict(op) - 当权重字典中的key名字不一样时
from torchvision import modelsimport torchfrom new_resnet import resnet50# 获取torch官方restnet50的预训练网络权重参数# pretrained表示是否在内部直接载入resnet50的权重,在这里我们不载入(下载太慢了,我们先现在到本地然后自己手动载入)resnet = models.resnet50(pretrained=False)state_dict = torch.load(r"resnet50-0676ba61.pth")resnet.load_state_dict(state_dict)new_state_dict = resnet.state_dict()# 获取自己创建的resnet50无训练的空权重net = resnet50()op = net.state_dict()# 无论名称是否相同都可以使用for new_state_dict_num, new_state_dict_value inenumerate(new_state_dict.values()):for op_num, op_key inenumerate(op.keys()):if op_num == new_state_dict_num and op_num <=317:# 320个key中不需要最后的全连接层的两个参数 op[op_key]= new_state_dict_valuenet.load_state_dict(op)# 更改了state_dict的值记得把它导入网络中
从上面两种方式可以看出,第二种方式更适合我们。综上所述,参数的载入构成主要分为
- 构建自己的网络模型,并转换成参数字典格式
- 创建官方的网络模型,并载入字典格式
- 将官方的网络模型字典于自己的网络模型字典做比较,确定需要载入的具体参数数量。
- 载入过后一定要导入网络中,即 net.load_state_dict(op)
2.2 训练方式选取(冻结or不冻结训练)
解释说明:预训练参数载入后,我们可以选取在网络模型训练过程过程中,我们是选取让这部分参数参与参数更新,还是不参与参数更新。
- 如果参与参数更新的话直接进行后续的网络训练就行了,无处理操作
- 若不参与网络的更新,需要将参与网络更新的bool值设为False. 通过key.requires_grad获取当前字典参数的参与更新状态的bool值。对应的,在训练时候,optimizer里面只能更新requires_grad = True的参数,于是
from torchvision import modelsimport torchfrom new_resnet import resnet50# 获取torch官方restnet50的预训练网络权重参数# pretrained表示是否在内部直接载入resnet50的权重,在这里我们不载入(下载太慢了,我们先现在到本地然后自己手动载入)resnet = models.resnet50(pretrained=False)state_dict = torch.load(r"resnet50-0676ba61.pth")resnet.load_state_dict(state_dict)new_state_dict = resnet.state_dict()# 获取自己创建的resnet50无训练的空权重net = resnet50()op = net.state_dict()# 无论名称是否相同都可以使用for new_state_dict_num, new_state_dict_value inenumerate(new_state_dict.values()):for op_num, op_key inenumerate(op.keys()):if op_num == new_state_dict_num and op_num <=317:# 320个key中不需要最后的全连接层的两个参数 op[op_key]= new_state_dict_valuenet.load_state_dict(op)# 更改了state_dict的值记得把它导入网络中for i, p inenumerate(net.parameters()):# 将前100层参数冻结if i <100: p.requires_grad =Falseoptimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, net.parameters()), lr=0.001)
本文转载自: https://blog.csdn.net/qq_28384023/article/details/126781759
版权归原作者 爱学习的小奶狗 所有, 如有侵权,请联系我们删除。
版权归原作者 爱学习的小奶狗 所有, 如有侵权,请联系我们删除。