
本文总计 3500 字,预计阅读需要 20-25分钟
数据科学家和分析师经常使用 Python和Pandas 进行数据探索和转换 Pandas 库提供了DataFrame 实现,当数据量适合单机内存时是非常方便的。但是对于更大的数据集 Apache Spark 等分布式系统的强大功能将变得非常有用。
在本文中,我将展示如何使用 Apache Spark 和 AWS 堆栈(EMR、S3、EC2)完成使用 Stack Overflow 数据集分析:包括从从 Stack Exchange 存档下载数据、上传到 S3、对数据进行基本预处理直到使用 Spark 进行最终分析,包括一些使用 Matplotlib 和 Pandas 绘制的精美图表,选择 Stack Exchange的原因是他很大,单机情况下处理会变得很困难,从而更好的展示Spark 分布式处理的强大功能
使用 Spark 和 Python 生态系统对大数据集进行数据分析一种非常常见的模式。这个模式有三个步骤,首先,用 Spark 读取数据,然后做一些处理来减少数据大小——这可能是一些过滤、聚合,甚至数据采样,最后将减少的数据集转换为 Pandas DataFrame 和继续在 Pandas 中进行分析,这样就可以使用的 Matplotlib 绘制图表和其他的一些可以用于单机数据处理的Python包。
文章假设读者对AWS有一定的了解,例如有账户,能够生成EC2密钥对等等。另外要强调一下,EC2、EMR 和 S3 等这些服务需要信用卡信息,亚马逊会向您收取使用费用。因此如果需要使用的话请确保在完成后终止 EC2 实例和 EMR 集群,并在不再需要数据后从 S3 中删除数据(包括日志、Notebook和其他可能在此过程中创建的文件)。
本文的操作步骤如下:
- 从 Stack Exchange 存档下载数据转储(它是一个 7z 压缩的 XML 文件)
- 解压下载的文件
- 将文件上传到 S3(AWS 上的分布式对象存储)
- 将 XML 文件转换为 Apache Parquet 格式(再次将 Parquet 保存在 S3 上)
- 分析数据集
对于步骤 1-3,我们将使用一个具有更大磁盘的 EC2 实例。对于第 4 步和第 5 步,我们将使用 Spark 3.0 和 JupyterLab 在 AWS 上部署 EMR 集群。
为了方便使用,这里使用 Spark 进行的分析的部分是可以独立运行的,所以如果不使用 AWS,也可以在其他地方运行 并且可以将数据发送到自有的存储系统,并仍然可以使用下面的查询代码。
数据集
Stack Overflow 在程序员中非常流行,你可以在那里提问,也可以回答其他用户的问题。这个数据集本身可以在 Stack Exchange 存档中找到,并且在知识共享许可 cc-by-sa 4.0 下可用。
数据由很多文件组成包括:帖子、用户、评论、投票、标签、历史和 链接 等等。在本文中我们将仅使用压缩后 16.9 GB 的XML格式的Posts 数据(截至 2021 年 12 月)。解压后大小为85.6 GB。要查看单个表及其列的含义,可以查看 Stack Exchange 上的帮助。我们这里将处理的帖子包含所有问题及其答案的列表,可以根据 _Post_type_id 区分它们,其中值 1 代表问题,值 2 代表答案。
数据下载和解压
要从 Stack Exchange 下载数据,可以使用包含 200 GB 磁盘空间的 EC2 实例 t2.large。登录 AWS 控制台,转到 EC2 实例,单击启动实例并选择操作系统,例如 Ubuntu Server 18.04 LTS。接下来,需要指定实例类型, 然后单击配置实例详细信息并在添加存储选项卡中添加磁盘卷。这里需要指定磁盘的大小,我选择 200 GB,但较小的磁盘应该也可以,但是解压后数据集将有近 90 GB所以我们这里留了一些富裕。以上的操作截图如下:
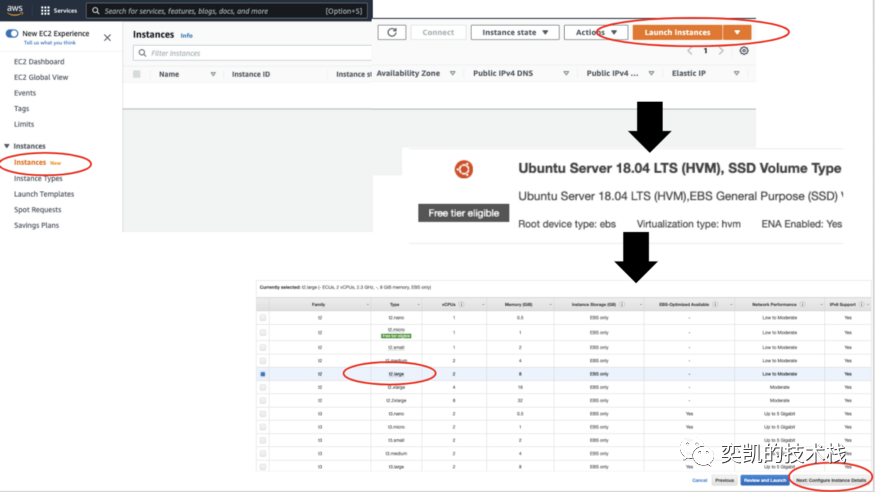
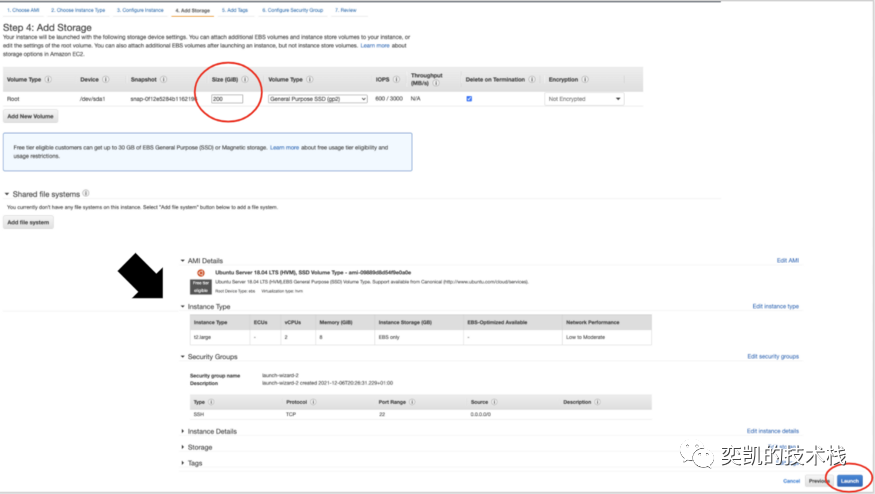
AWS 会建议你设置一些安全组来限制可以使用实例的 IP 地址,因此请查看 AWS 文档。要启动实例需要有一个 EC2 密钥对,如果还没有可以生成它。 实例运行后,可以使用密钥从终端 ssh 链接到EC2实例。
ssh-ikey.pemubuntu@<the ip address of your instance>
然后需要安装 pip3 和 p7zip(第一个是 Python3 的包管理系统,我们将用于安装 Python 包,第二个是用于解压 7z 文件):
sudo apt update
sudo apt install python3-pip
sudo apt install p7zip-full
然后安装用于数据下载和 S3 上传的 Python 包 requests 和 boto3:
pip3 install boto3
pip3 install requests
使用 vi data_download.py 创建一个新文件并复制以下 Python 代码(在 vi 编辑器中,需要按 i 键切换到插入模式):
from boto3.session import *
import os
access_key = '...'
secret_key = '...'
bucket = '...'
s3_output_prefix = '...'
session = Session(
aws_access_key_id=access_key,
aws_secret_access_key=secret_key
)
s3s = session.resource('s3').Bucket(bucket)
local_input_prefix = '/home/ubuntu'
file_name = 'Posts.xml'
input_path = os.path.join(local_input_prefix, file_name)
output_path = os.path.join(s3_output_prefix, file_name)
s3s.upload_file(input_path, output_path)
在代码中需要填写 S3 的凭据(access_key 和 secret_key)、存储桶的名称以及 s3_output_prefix。如果您没有 access_key 和 secret_key,可以生成它们。如果没有存储桶,则需要创建它(中国访问的话建议使用日本的S3,这样国内速度快,下载美国服务器的资源也快)。
还有有一个公共 API 可以查询 Stack Overflow 数据库,Python 包是stackapi,有兴趣的可以看看。
下载数据并存储在 S3 上后,上面的EC2实例就可以回收了(为了省钱),这个过程大概需要1-2个小时也就是说我们只需要花费使用2个小时的费用,这就是按需付费的好处。
数据预处理
我们现在将为分析查询准备数据进行一些基本的预处理。将格式从 XML 转换为 Apache Parquet,并将列重命名为更方便的格式。
启动 EMR 集群
我们将启动一个带有 Spark 3.0 和 JupyterHub 的 EMR 集群来进行这个预处理步骤和实际的数据分析。转到 EMR(在 AWS 服务中)并单击创建集群。经过一系列的设置 (高级选项中可以选择 EMR 版本并检查将在集群上安装哪些应用程序) 这里使用了 emr-6.1.0,我们需要的关键组件是 Hadoop、Spark、JupyterHub 和 Livy:
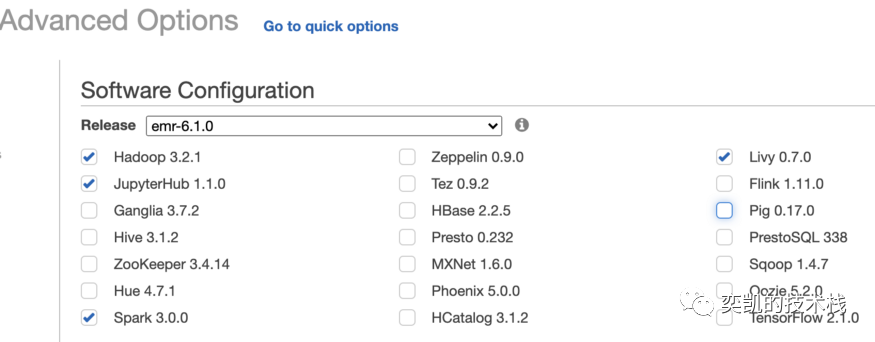
下一步需要配置集群将有多少个节点,这里可以使用默认设置,但是某些大查询等待时间可能会有点长。换句话说,拥有更大的集群会导致更快的查询,但花费成本也会更大。再下一步,为集群选择一个有意义的名称并取消选中终止保护(Termination protection)。最后点击 Create cluster 后跳转到新的页面会看到集群正在启动。
然后就可以单击 Notebooks 并创建一个 Notebook,为笔记本选择一个名称并选择此笔记本将附加到的已创建集群。几秒钟后可以单击“在 JupyterLab 中打开”按钮,这将打开 Jupyter:
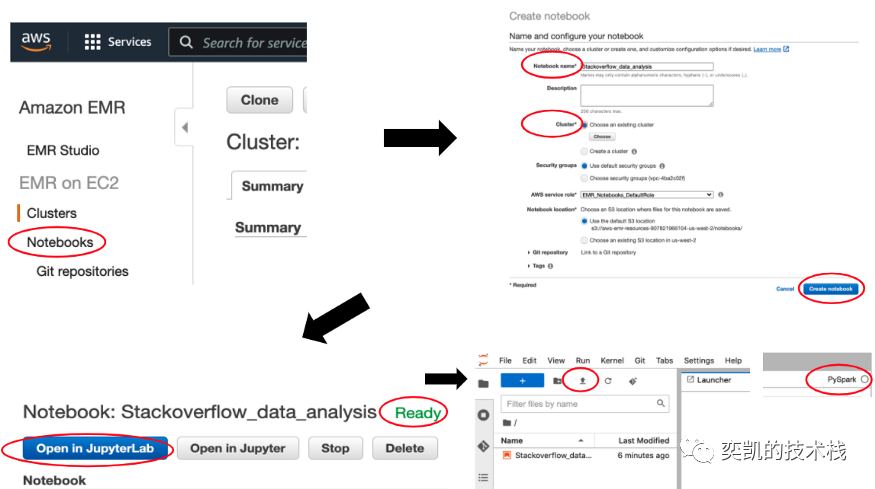
在 JupyterLab 中可以打开和新建Notebook,还可以使用菜单中的上传按钮在此处上传其他Notebook。
对于数据预处理和分析,可以上传这两个文件:
Stackoverflow-Data-Analysis/data-prepare/data-prepare.ipynbStackoverflow-Data-Analysis/data-analysis/Posts-General-Analysis.ipynb
在Notebook中需要确保使用正确的内核,您可以在右上角看到(上面的屏幕截图)。这里需要使用 PySpark 内核。
转换为 Parquet 格式
现在 EMR 集群和 Jupyter 都已经顺利启动了,我们就可以开始处理数据了。
第一步是将格式从原始 XML 转换为 Apache Parquet,这对于 Spark 中的分析查询更加方便。要在 Spark SQL 中读取 XML,我们将使用 spark-xml 包,它允许我们指定格式 xml 并将数据读入 DataFrame
posts_input_path = 's3://...'
posts_output_path = 's3://...'
(
spark
.read
.format('xml')
.option('samplingRatio', 0.01)
.option('rowTag', 'row')
.load(posts_input_path)
.select(
col('_Id').alias('id'),
(col('_CreationDate').cast('timestamp')).alias('creation_date'),
col('_Title').alias('title'),
col('_Body').alias('body'),
col('_commentCount').alias('comments'),
col('_AcceptedAnswerId').alias('accepted_answer_id'),
col('_AnswerCount').alias('answers'),
col('_FavoriteCount').alias('favorite_count'),
col('_OwnerDisplayName').alias('owner_display_name'),
col('_OwnerUserId').alias('user_id'),
col('_ParentId').alias('parent_id'),
col('_PostTypeId').alias('post_type_id'),
col('_Score').alias('score'),
col('_Tags').alias('tags'),
col('_ViewCount').alias('views')
)
.write
.mode('overwrite')
.format('parquet')
.option('path', posts_output_path)
.save()
)
作为此 ETL 过程的一部分,我们还将所有列重命名,并将 creation_date 列转换为 TimestampType。将数据转换为 Parquet 后,大小从 85.6 GB 减少到 30 GB,这是由于 Parquet 的压缩以及我们没有在最终 Parquet 中包含所有列。我们可以在此处进行的另一个步骤是根据creation_year 甚至是creation_month 对数据进行分区, 如果我们只想分析数据的一部分,这会加快处理速度。
数据分析
现在我们可以进行数据分析并可能发现其一些有趣的部分。我们将回答有关数据集的 5 个分析问题:
1、计算计数
让我们统计以下的数据:
- 有多少问题
- 有多少答案
- 有多少问题已接受答案
- 有多少用户提出或回答了一个问题
posts_path = 's3://...'
posts_all = spark.read.parquet(posts_path)
posts = posts_all.select(
'id',
'post_type_id',
'accepted_answer_id',
'user_id',
'creation_date',
'tags'
).cache()
posts.count()
questions = posts.filter(col('post_type_id') == 1)
answers = posts.filter(col('post_type_id') == 2)
questions.count()
answers.count()
questions.filter(col('accepted_answer_id').isNotNull()).count()
posts.filter(col('user_id').isNotNull()).select('user_id').distinct().count()
在上面的代码中,我们首先读取所有帖子,但只选择了需要进一步分析的特定列进行缓存。然后根据 post_type_id 将帖子分成两个 DataFrame,因为值 1 代表问题,值 2 代表答案。帖子总数为 53 949 886,其中 21 641 802 问题,32 199 928 答案(数据集中还有其他类型的帖子)。当过滤accepted_answer_id 不为空的问题时,我们得到有接受答案的问题数量:11 138 924。对 user_id 列上的数据集进行去重后,我们得到提出或回答问题的用户总数为 5 404 321。
2、计算响应时间
我们在此处将响应时间定义为从提出问题到有答案被接受所经过的时间。在下面的代码中可以看到需要将问题与答案连接起来,以便我们可以将问题的创建日期与其接受的答案的创建日期进行比较:
response_time = (
questions.alias('questions')
.join(answers.alias('answers'), col('questions.accepted_answer_id') == col('answers.id'))
.select(
col('questions.id'),
col('questions.creation_date').alias('question_time'),
col('answers.creation_date').alias('answer_time')
)
.withColumn('response_time', unix_timestamp('answer_time') - unix_timestamp('question_time'))
.filter(col('response_time') > 0)
.orderBy('response_time')
)
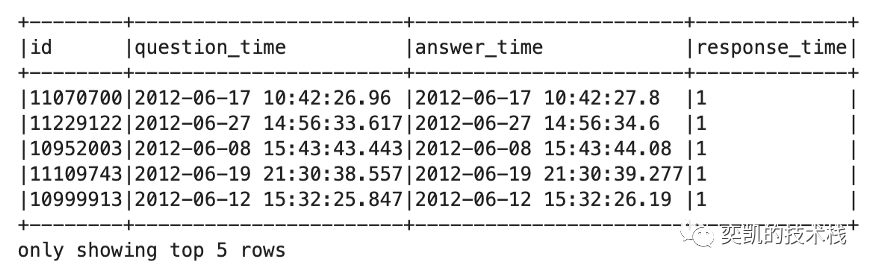
response_time.show(truncate=False)
当按响应时间对数据进行排序时,我们可以看到最快的被接受的答案在一秒内出现,您可能想知道某人怎么可能这么快地回答问题。检查了其中一些问题,我发现这些问题和回答都是由同一用户回答的,因此显然他/她知道答案并将其与问题一起发布(作弊刷回答数的)。
将响应时间从几秒转换为几小时并汇总,我们可以得到发布后每小时回答了多少问题。
hourly_data = (
response_time
.withColumn('hours', ceil(col('response_time') / 3600))
.groupBy('hours')
.agg(count('*').alias('cnt'))
.orderBy('hours')
.limit(24)
).toPandas()
hourly_data.plot(
x='hours', y='cnt', figsize=(12, 6),
title='Response time of questions',
legend=False,
kind='bar',
xlabel='Hour',
ylabel='Number of answered questions'
)
我们将时间限制为 24 小时,以查看问题发布后第一天的行为。正如图表现实,大多数问题都在第一个小时内得到解答:
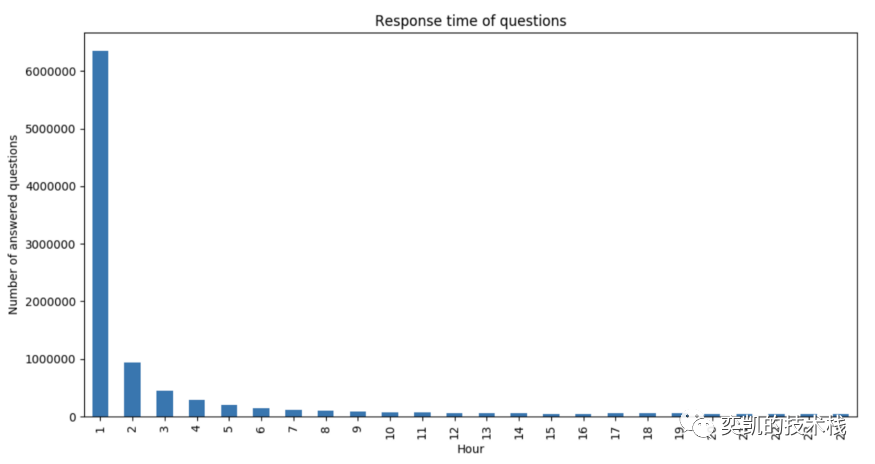
大部分问题能在1小时内得到答案,Stack Overflow还是真的管用
3、查看问题/答案的数量如何随时间变化
使用 Spark 聚合计算:看看每个时间单位的问题和答案的数量如何随时间演变的。window() 函数可以进行分组,它需要两个参数,第一个是具有时间含义的列名,第二个是我们想要要分组的时间维度。这里选择时间单位为一周。在聚合操作中可以使用 when 条件计算答案和问题,如下所示:
posts_grouped = (
posts
.filter(col('user_id').isNotNull())
.groupBy(
window('creation_date', '1 week')
)
.agg(
sum(when(col('post_type_id') == 1, lit(1)).otherwise(lit(0))).alias('questions'),
sum(when(col('post_type_id') == 2, lit(1)).otherwise(lit(0))).alias('answers')
)
.withColumn('date', col('window.start').cast('date'))
.orderBy('date')
).toPandas()
posts_grouped.plot(
x='date',
figsize=(12, 6),
title='Number of questions/answers per week',
legend=True,
xlabel='Date',
ylabel='Number of answers',
kind='line'
)
按窗口分组后会创建一个 StructType,它有两个 StructFields,start 和 end,所以这里为了绘图,我们使用 start 字段,它是每周开始的时间。
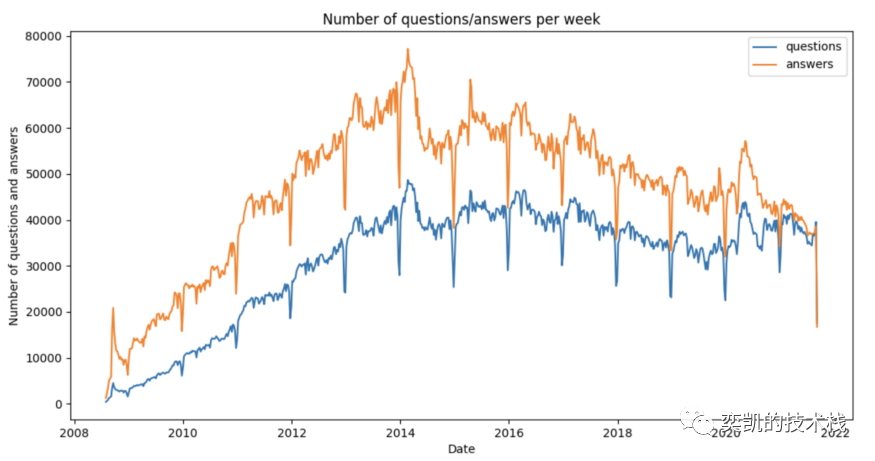
4、计算标签的数量
每个问题都有一些标签,这些标签代表了不同的主题标签以<tag1><tag2><…>形式存储为字符串,因此为了分析它们,需要将这个字符串转换为这些标签的数组并去掉尖括号。首先使用 split 函数拆分字符串,然后使用高阶函数 TRANSFORM ,使用 regexp_replace 从数组中的每个元素中删除尖括号。为了计算所有标签的总数,需要分解这个数组并对其进行去重:
tags = (
questions
.withColumn('tags', split('tags', '><'))
.selectExpr(
'*',
"TRANSFORM(tags, value -> regexp_replace(value, '(>|<)', '')) AS tags_arr"
)
)
tags.withColumn('tag', explode('tags_arr')).select('tag').distinct().count()
(
tags
.withColumn('tag', explode('tags_arr'))
.groupBy('tag')
.agg(count('*').alias('tag_frequency'))
.orderBy(desc('tag_frequency'))
).show(n=10)
结果显示 61 662 个不同的标签。要查看哪些标签使用次数最多,只需按标签对分解的数据集进行分组,计算每个标签的总数并排序。从下面的结果中中可以看出最常用的标签是 javascript:

5、查看一些特定标签的统计
将标签列转换为数组后,现在可以过滤此数组并查看特定标签。例如:人们用标签 apache-spark 或 apache-spark-sql 提出了多少问题。使用带有两个参数的函数 array_contains,第一个是数组列,第二个是我们想要找出它是否包含在数组中的特定元素。该函数返回 True 或 False,因此可以直接在过滤器中使用它, 像这样过滤问题后根据creation_date 再按一周分组:
spark_tag = (
tags
.filter(array_contains(col('tags_arr'), 'apache-spark') | array_contains(col('tags_arr'), 'apache-spark-sql'))
.groupBy(
window('creation_date', "1 week")
)
.agg(
count('*').alias('tag_frequency')
)
.withColumn('date', col('window.start').cast('date'))
.orderBy('date')
).toPandas()
spark_tag.plot(
x='date',
figsize=(12, 6),
title='spark/spark-sql tag frequency per week',
legend=False,
xlabel='Date',
ylabel='Number of questions with spark tag',
kind='line'
)
最后的图表显示,在 Stack Overflow 上,人们从 2014 年开始对 Spark 感兴趣,并且在 2017 年和 2018 年每周提出的问题最多:
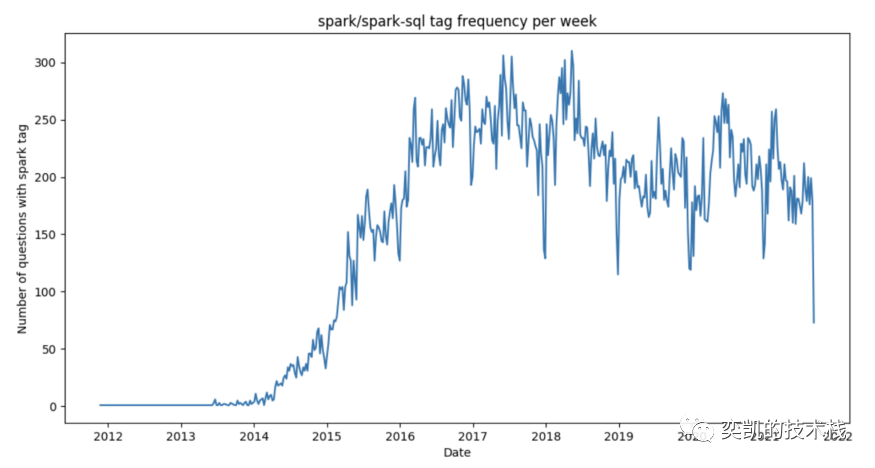
总结
Stack Overflow 数据集承载了很多有趣的信息,我说的不仅仅是答案形式的内容,还包括问题、答案、评论和用户之间的一些有趣的关系。在本文中只使用 Spark 分析了数据集中的帖子数据,这只展示了冰山一角,在以后的一些帖子中,我们将应用一些更高级的分析工具,例如机器学习和 使用 Spark 进行图处理以发现数据的更多属性。
作者:David Vrba
本文代码: