
本文总计 1500 字,预计阅读需要 6 分钟
今天我们来围绕着AUTOMATIC1111的stable-diffusion-webui介绍如何将stable diffusion 2.0 部署到本地,还有在哪里下载基本模型和微调。
本地安装
这里我们以windows为例,linux也类似
首先,clone项目:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
然后,我们需要一个插件stable-diffusion-webui-images-browser ,把他clone到相应目录即可
git clone https://github.com/yfszzx/stable-diffusion-webui-images-browser stable-diffusion-webui/extensions/stable-diffusion-webui-images-browser
全部完成后我们进入这个网站:
https://huggingface.co/nolanaatama/chomni/tree/main
然后下载这两个文件:
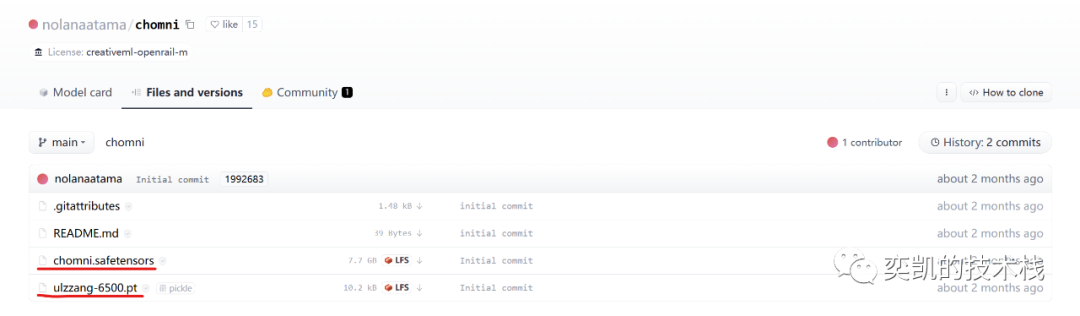
chilloutmixni.safetensors是我们的基本模型文件,复制到 stable-diffusion-webui/models/Stable-diffusion,这个模型很大,但是可以用迅雷等下载工具下,速度还可以。
ulzzang-6500.pt是embedding,复制到stable-diffusion-webui/embeddings
然后我们用conda创建一个虚拟环境,这个环境无所谓,因为webui在启动时会自动的将python复制到它的stable-diffusion-webui\venv目录,所以只要有基本的python包就可以了,这里我们根据官网要求,使用Python 3.10.6:
conda env create -n sd2 python=3.10.6
安装完成后激活
conda activate sd2
然后进入stable-diffusion-webui目录,我这里是放在了D:\git\stable-diffusion-webui,所以后面都已这个目录为例。
然后执行:
cd D:\git\stable-diffusion-webui
webui.bat
执行这步肯定会报错,如果没报错就跳过下面的内容:
我们先执行这步是为了让脚本把环境复制到venv,这样我们就可以跳过conda虚拟环境了,我们的python运行环境已经在
D:\git\stable-diffusion-webui\venv\Scripts\Python.exe
了
下面开始安装依赖:
找到:
requirements.txt
把这两行注释掉:
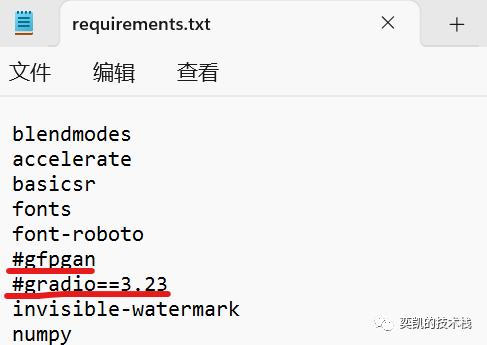
执行
D:\git\stable-diffusion-webui\venv\Scripts\Python.exe -m pip install -r requirements.txt
执行完后手动执行:
D:\git\stable-diffusion-webui\venv\Scripts\Python.exe -m pip install gradio
安装最新版的gradio,安装完成后打开
launch.py
22行改为True
然后在221行:
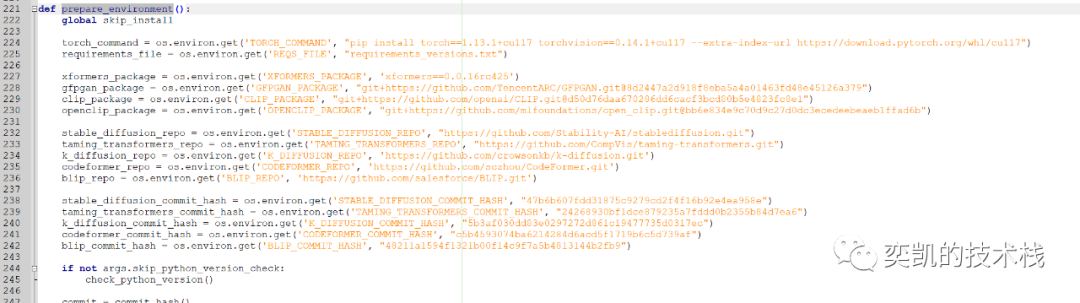
手动执行上面的每一步
比如:
D:\git\stable-diffusion-webui\venv\Scripts\Python.exe -m pip install git+https://github.com/TencentARC/GFPGAN.git@8d2447a2d918f8eba5a4a01463fd48e45126a379
一般情况下这一句就行了,因为我们的requirements注释掉了这句。
以上都完成后,执行:
D:\git\stable-diffusion-webui\venv\Scripts\Python.exe launch.py
就可以启动了,这时不需要任何的python环境了,启动时间很长,因为有一个8G的模型要放到显卡上,如果你看到下面的消息就是成功了:
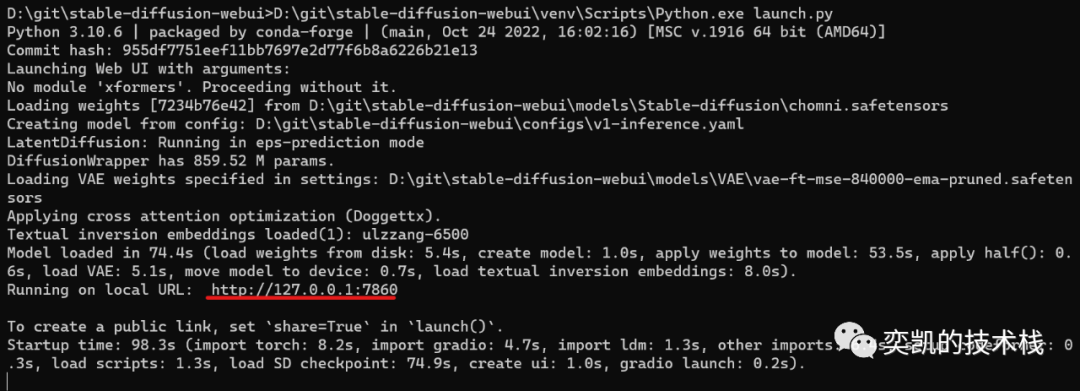
访问上面标红的地址就能看到webui了,如果报错请按照提示安装缺失的python包,一般都是在221行的那几个,手动install就可以了。
打开页面应该是这样的
这样安装就完成了。
微调模型
我们安装的仅仅是基本模型,为了我们不同的需求可以使用不同的lora来进行微调,比如这个:
https://huggingface.co/amornlnw7/koreanDollLikeness_v15/tree/main
下载
koreanDollLikeness_v15.safetensors
复制到 models\Lora 目录,这样我们可以生成漂亮小姐姐了
使用下面的配置可以生成跟我一样的图片:
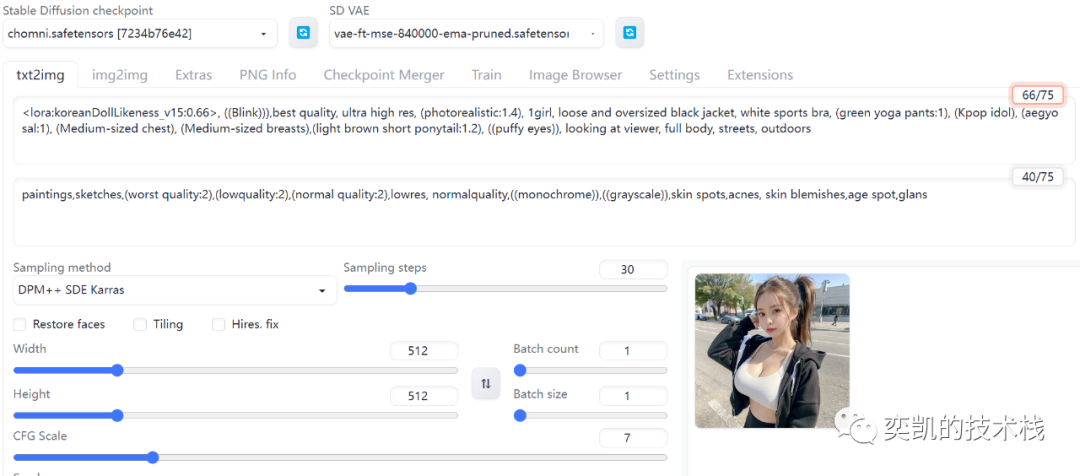
prompt
<lora:koreanDollLikeness_v15:0.66>, ((Blink))),best quality, ultra high res, (photorealistic:1.4), 1girl, loose and oversized black jacket, white sports bra, (green yoga pants:1), (Kpop idol), (aegyo sal:1), (Medium-sized chest), (Medium-sized breasts),(light brown short ponytail:1.2), ((puffy eyes)), looking at viewer, full body, streets, outdoors
negative:
paintings,sketches,(worst quality:2),(lowquality:2),(normal quality:2),lowres, normalquality,((monochrome)),((grayscale)),skin spots,acnes, skin blemishes,age spot,glans
Seed: 4019082821

图片美化
可能你生成的效果没我的好,这是为什么呢?
因为我还加了vae,把这个文件vae-ft-mse-840000-ema-pruned.safetensors放在 \models\VAE目录下
下载地址:https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main ,这样就自动使用了
SD VAE的作用主要就是优化眼睛和嘴的细节:

LORA
Low-Rank Adaptation (LoRA) 是一种有效的自适应策略,它不会引入额外的推理延迟,并在保持模型质量的同时显着减少下游任务的可训练参数数量,也就是说它的模型特别小,看看 koreanDollLikeness_v15.safetensors 就知道了。
我们可以自己训练也可以使用别人的LORA,与koreanDollLikeness_v15一样,直接把他们复制到 lora目录就可以了
在 civitai上有各种各样的LORA可以选择,这里介绍几个我觉得不错的:
墨心 MoXin:

Jim Lee (DC Comics / Marvel) Style LoRA

光头强/huaqiang lora模型
