
1.文档编写目的
在遇到将Hive中的数据同步到HBase时,一般都是通过在Hive中创建映射HBase的表,然后通过insert的方式来实现,在数据量小的时候,往往还能接受,但是如果是大批量数据,除了同步时间较长,往往还会对线上的HBase服务造成影响,因为这种方式底层还是调用的HBase的put API来实现的。为了提高HBase的数据写入,一般都会考虑使用bulkload的方式,而bulkload其实也有很多种选择:
1.编写MapReduce/Spark程序生成hfile文件,然后通过HBase命令load数据
2.通过HBase的ImportTsv工具生成hfile,然后通过HBase命令load数据
3.通过定制Phoenix的StorageHandler进行bulkload
4.使用Hive的方式生成hfile文件,然后通过HBase命令load数据
本文主要是介绍在CDP中使用Hive的方式,以下方式在CDH5或者CDH6是比较简单的,但是在CDP中因为Hive默认使用了tez引擎,所以有一些差别。
- 前置条件
1.目标HBase表必须是新建的(即不能导入到已经存在的表)
2.目标表只能有一个Column Family
3.目标表不能是稀疏的(即每一行数据的结构必须一致)
- 测试环境:
1.Redhat7.9
2.采用root用户操作
3.CM为7.4.4,CDP为7.1.7
4.集群未启用Kerberos
2.准备工作
1.进入Hive on Tez服务,在‘hive-site.xml 的 Hive 服务高级配置代码段(安全阀)’中增加以下配置参数,如果不增加,在后面set一些Hive参数无法正常执行。
<property>
<name>hive.security.authorization.sqlstd.confwhitelist.append</name>
<value>tez.*|hive.strict.checks.*|hive.mapred.*|mapreduce.*|total.*|hfile.*</value>
</property>
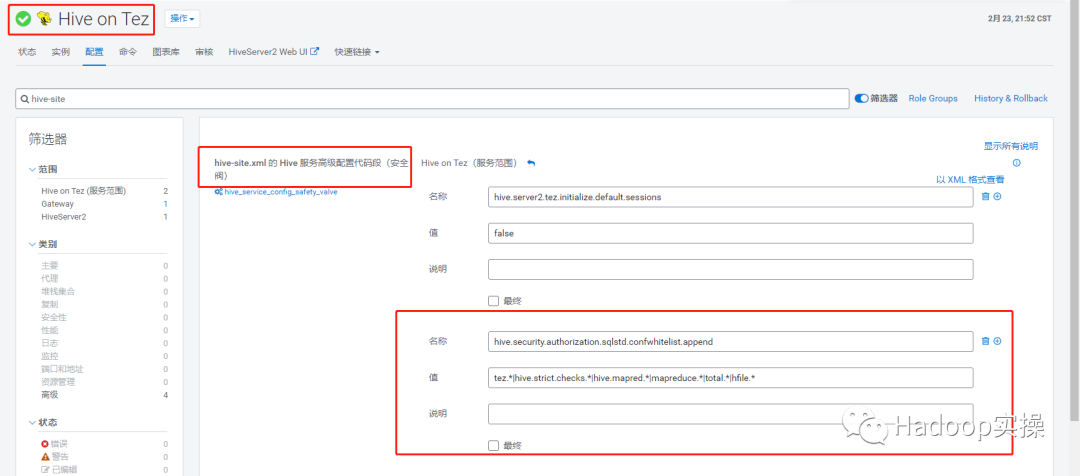
保存修改,回到CM主页,会提示重启相关服务和重新部署客户端配置操作。
2.将涉及到的一些HBase的jar包put到HDFS中,方便后面使用,如果不想这样操作,也可以通过Hive的hive.aux.jars.path配置来完成,把jar包到加入到这个配置里。
hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-common-2.2.3.7.1.7.0-551.jar /tmp
hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-server-2.2.3.7.1.7.0-551.jar /tmp
hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-client-2.2.3.7.1.7.0-551.jar /tmp
hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-protocol-2.2.3.7.1.7.0-551.jar /tmp
hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-mapreduce-2.2.3.7.1.7.0-551.jar /tmp
hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hbase-shaded-mapreduce-2.2.3.7.1.7.0-551.jar /tmp
hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/htrace-core4-4.2.0-incubating.jar /tmp
hadoop fs -put /opt/cloudera/parcels/CDH-7.1.7-1.cdh7.1.7.p0.15945976/jars/hive-hbase-handler-3.1.3000.7.1.7.0-551.jar /tmp
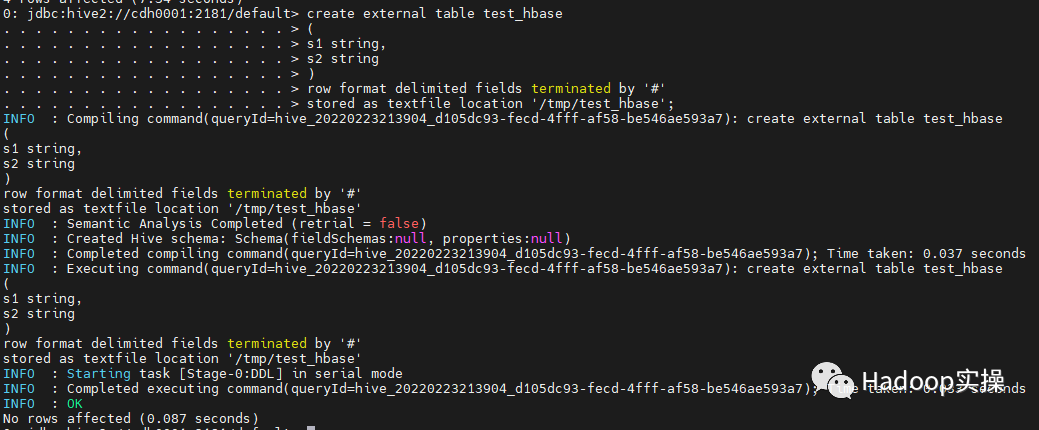
3.准备用于导入到HBase的数据,首先建立Hive外表,并插入数据。
create external table test_hbase
(
s1 string,
s2 string
)
row format delimited fields terminated by '#'
stored as textfile location '/tmp/test_hbase';
insert into test_hbase values('0000001','a'),('1000000','a'),('1000002','b'),('1000003','b'),('2000000','b'),('2000001','c'),('2000002','b'),('3000000','b'),('3100001','d'),('3100002','3'),('3100003','e'),('3100004','f'),('3100005','g'),('4000000','b'),('4000001','h'),('4100002','i'),('4000003','j');

3.生成分区键
在生成hfile文件的时候是需要对数据进行排序的,为了启动多个reduce任务对数据进行并行排序,我们需要用分区键将数据按照rowkey字段将数据划分若干个大小相同的范围。这样做还有一个好处就是会生成多个hfile文件,当hbase加载文件的时候会分配到多个regionserver节点上,达到预分区的效果,提高后续数据读取和写入的速度。
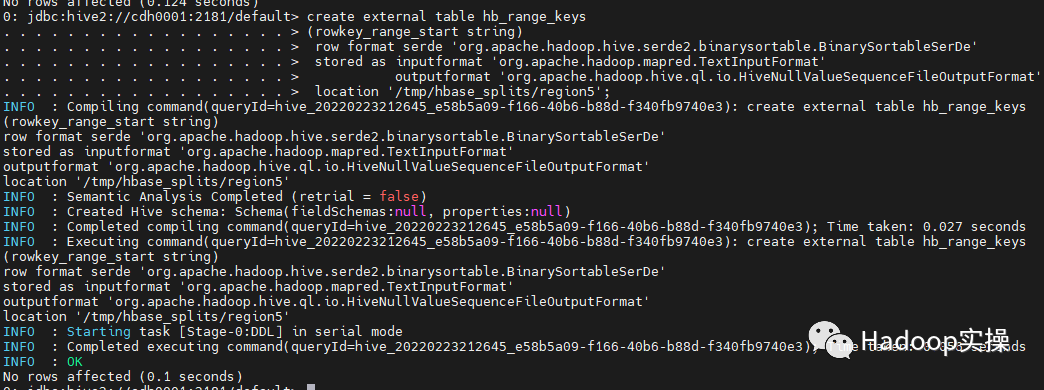
首先我们需要创建一个表用于生成数据分割文件:
create external table hb_range_keys
(rowkey_range_start string)
row format serde 'org.apache.hadoop.hive.serde2.binarysortable.BinarySortableSerDe'
stored as inputformat 'org.apache.hadoop.mapred.TextInputFormat'
outputformat 'org.apache.hadoop.hive.ql.io.HiveNullValueSequenceFileOutputFormat'
location '/tmp/hbase_splits/region5'; --指定数据存储目录,接下来的步骤会用到
接下来需要根据数据rowkey字段对数据进行范围划分:
下面是hive官方文档给的一个示例方法,通过对0.01%的样本数据排序,然后选择每第910000行数据,将数据分为了12份,这里的假设是样本中的分布与表中的整体分布相匹配。如果不是这种情况,则生成的分区键对数据范围划分不均衡导致并行排序时出现倾斜情况
insert overwrite table hb_range_keys
select transaction_id from
(select transaction_id
from transactions
tablesample(bucket 1 out of 10000 on transaction_id) s
order by transaction_id
limit 10000000) x
where (row_sequence() % 910000)=0
order by transaction_id
limit 11;
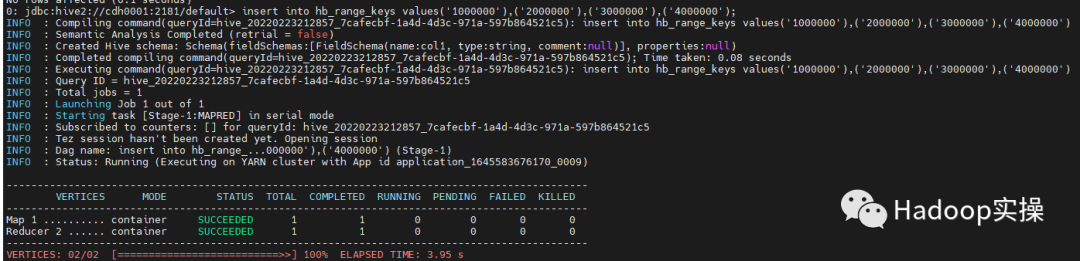
因为官方的数据Fayson并没有找到,所以为了方便造了几条数据(参考第二章插入的数据)来进行测试,所以我们直接手动指定分区键:
insert into hb_range_keys values('1000000'),('2000000'),('3000000'),('4000000');
4.生成hfile文件
1.创建表用于生成保存hfile文件,'/tmp/hbsort1/info'路径中的info是列族名称,目前只支持单个列族
create external table hbsort(
row_key string,
column1 string
)
stored as
INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.hbase.HiveHFileOutputFormat'
TBLPROPERTIES ('hfile.family.path' = '/tmp/hbsort/info');
2.接下来就是准备生成hfile文件,首先在beeline添加jar包设置相关参数,以及set一些Hive on Tez的参数:
--添加相关的jar包
add jar hdfs:/tmp/hive-hbase-handler-3.1.3000.7.1.7.0-551.jar;
add jar hdfs:/tmp/hbase-common-2.2.3.7.1.7.0-551.jar;
add jar hdfs:/tmp/hbase-server-2.2.3.7.1.7.0-551.jar;
add jar hdfs:/tmp/hbase-client-2.2.3.7.1.7.0-551.jar;
add jar hdfs:/tmp/hbase-protocol-2.2.3.7.1.7.0-551.jar;
add jar hdfs:/tmp/hbase-mapreduce-2.2.3.7.1.7.0-551.jar;
add jar hdfs:/tmp/hbase-shaded-mapreduce-2.2.3.7.1.7.0-551.jar;
add jar hdfs:/tmp/htrace-core4-4.2.0-incubating.jar;
set mapred.reduce.tasks=5; --hb_range_keys表条数+1
set hive.mapred.partitioner=org.apache.hadoop.hive.ql.exec.tez.TezTotalOrderPartitioner;
--指定上一步骤生成的分区键文件地址
set mapreduce.totalorderpartitioner.path=/tmp/hbase_splits/region5/000000_0;
set total.order.partitioner.path=/tmp/hbase_splits/region5/000000_0;
set hfile.compression=snappy;--指定snappy压缩

3.将数据写入表中生成hfile文件:
insert overwrite table hbsort
select
s1,
s2
from test_hbase
cluster by s1;
5.Load数据到HBase
1.首先将存放hfile文件的目录的属组改为fayson用户,fayson用户用于执行HBase的bulkload命令。
sudo -u hdfs hadoop fs -chown -R fayson:fayson /tmp/hbsort
2.执行HBase的bulkload命令
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /tmp/hbsort test_bulk

3.使用hbase shell查询数据已经全部导入
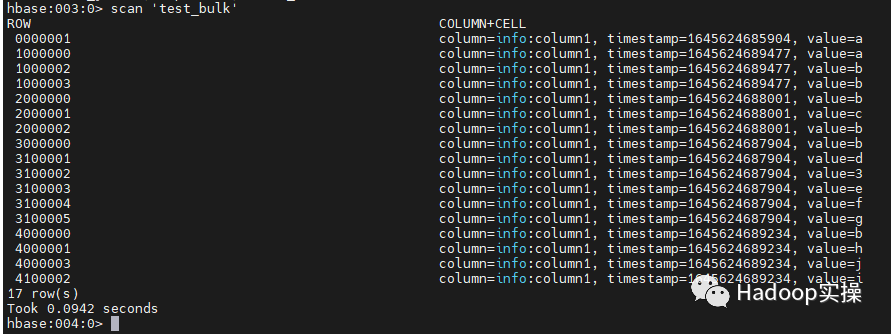
4.进入HBase Master页面确认region按照预期生成,并且startkey与endkey都正确
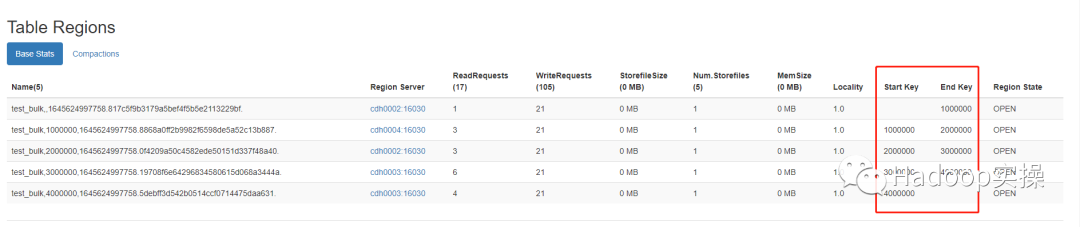
可以看到正确的生成了5个region,startkey与endkey与hb_range_keys分区键表设置的一致。
6.常见问题
1.与CDH5/6不一样,CDP中的Hive默认使用的是tez引擎,set的一些参数是不一样的,CDH5/6与Hive官网的一致如下:
set mapred.reduce.tasks=12;
set hive.mapred.partitioner=org.apache.hadoop.mapred.lib.TotalOrderPartitioner;
set total.order.partitioner.path=/tmp/hb_range_key_list;
而在CDP中则为:
set mapred.reduce.tasks=5;
set hive.mapred.partitioner=org.apache.hadoop.hive.ql.exec.tez.TezTotalOrderPartitioner;
set mapreduce.totalorderpartitioner.path=/tmp/hbase_splits/region5/000000_0;
set total.order.partitioner.path=/tmp/hbase_splits/region5/000000_0;
2.为了能在CDP的beeline中设置上面的参数需要在CM的Hive on Tez服务中增加以下参数:
<property>
<name>hive.security.authorization.sqlstd.confwhitelist.append</name>
<value>tez.*|hive.strict.checks.*|hive.mapred.*|mapreduce.*|total.*|hfile.*</value>
</property>
3.CDP中的Hive内表默认是ACID的托管表,所以本文所有Hive表建议都创建external表,否则会不支持。
4.如果嫌在beeline中add各种jar包麻烦,可以永久将这些jar添加到Hive的hive.aux.jars.path配置中。
5.注意在最后一步执行HBase的bulkload命令时,HBase中不允许存在test_bulk表,否则会导致region个数不能按预期生成。
6.执行HBase的bulkload命令时,需要保证hfile所在目录的用户属组与执行bulkload的命令的用户一致,本文使用的都是fayson。
参考文档:
https://cwiki.apache.org/confluence/display/Hive/HBaseBulkLoad#HBaseBulkLoad-AddnecessaryJARshttps://blog.csdn.net/songjifei/article/details/104706388https://blog.csdn.net/alinyua/article/details/109831892