

本文旨在探究将PyTorch Lightning应用于激动人心的强化学习(RL)领域。在这里,我们将使用经典的倒立摆gym环境来构建一个标准的深度Q网络(DQN)模型,以说明如何开始使用Lightning来构建RL模型。
- 在本文中,我们将讨论:
- 什么是lighting以及为什么要将它应用于RL
- 标准DQN模型简介
- 使用Lightning构建DQN的步骤
- 结果和结论
本文代码将在文章最后发布。
什么是lighting?

Lightning是一个最近发布的Pythorch库,它可以清晰地抽象和自动化ML模型所附带的所有日常样板代码,允许您专注于实际的ML部分(这些也往往是最有趣的部分)。
除了自动化样板代码外,Lightning还可以作为一种样式指南,用于构建干净且可复制的ML系统。
这非常吸引人,原因如下:
- 通过抽象出样板工程代码,可以更容易地识别和理解ML代码。
- Lightning的统一结构使得在现有项目的基础上进行构建和理解变得非常容易。
- Lightning 自动化的代码是用经过全面测试、定期维护并遵循ML最佳实践的高质量代码构建的。
DQN

在我们进入代码之前,让我们快速回顾一下DQN的功能。DQN通过学习在特定状态下执行每个操作的值来学习给定环境的最佳策略。这些值称为Q值。
最初,智能体对其环境的理解非常差,因为它没有太多的经验。因此,它的Q值将非常不准确。然而,随着时间的推移,当智能体探索其环境时,它会学习到更精确的Q值,然后可以做出正确的决策。这允许它进一步改进,直到它最终收敛到一个最优策略(理想情况下)。
我们感兴趣的大多数环境,如现代电子游戏和模拟环境,都过于复杂和庞大,无法存储每个状态/动作对的值。这就是为什么我们使用深度神经网络来近似这些值。
智能体的一般生命周期如下所述:
- 智能体获取环境的当前状态并将其通过网络进行运算。然后,网络输出给定状态的每个动作的Q值。
- 接下来,我们决定是使用由网络给出智能体所认为的最优操作,还是采取随机操作,以便进一步探索。
- 这个动作被传递到环境中并得到反馈,告诉智能体它处于的下一个状态是什么,在上一个状态中执行上一个动作所得到的奖励,以及该步骤中的事件是否完成。
- 我们以元组(状态, 行为, 奖励, 下一状态, 已经完成的事件)的形式获取在最后一步中获得的经验,并将其存储在智能体内存中。
- 最后,我们从智能体内存中抽取一小批重复经验,并使用这些过去的经验计算智能体的损失。
这是DQN功能的一个高度概述。
轻量化DQN

启蒙时代是一场支配思想世界的智力和哲学运动,让我们看看构成我们的DQN的组成部分
模型:用来逼近Q值的神经网络
重播缓冲区:这是我们智能体的内存,用于存储以前的经验
智能体:智能体本身就是与环境和重播缓冲区交互的东西
Lightning模块:处理智能体的所有训练
模型
对于这个例子,我们可以使用一个非常简单的多层感知器(MLP)。这意味着我们没有使用任何花哨的东西,像卷积层或递归层,只是正常的线性层。这样做的原因是由于卡倒立摆环境的简单性,任何比这更复杂的东西都是过度复杂的。
classDQN(nn.Module):
"""
Simple MLP network
Args:
obs_size: observation/state size of the environment
n_actions: number of discrete actions available in the environment
hidden_size: size of hidden layers
"""
def__init__(self, obs_size: int, n_actions: int, hidden_size: int = 128):
super(DQN, self).__init__()
self.net = nn.Sequential(
nn.Linear(obs_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, n_actions)
)
defforward(self, x):
return self.net(x.float())
重播缓冲区
重播缓冲区的构建相当直接,我们只需要某种类型的数据结构来存储元组。我们需要能够对这些元组进行采样并添加新的元组。本例中的缓冲区基于Lapins重播缓冲区,因为它是迄今为止我发现的最简洁并且最快的实现。代码如下
# Named tuple for storing experience steps gathered in training
Experience = collections.namedtuple(
'Experience', field_names=['state', 'action', 'reward',
'done', 'new_state'])
classReplayBuffer:
"""
Replay Buffer for storing past experiences allowing the agent to learn from them
Args:
capacity: size of the buffer
"""
def__init__(self, capacity: int) -> None:
self.buffer = collections.deque(maxlen=capacity)
def__len__(self) -> None:
return len(self.buffer)
defappend(self, experience: Experience) -> None:
"""
Add experience to the buffer
Args:
experience: tuple (state, action, reward, done, new_state)
"""
self.buffer.append(experience)
defsample(self, batch_size: int) -> Tuple:
indices = np.random.choice(len(self.buffer), batch_size, replace=False)
states, actions, rewards, dones, next_states = zip(*[self.buffer[idx] for idx in indices])
return (np.array(states), np.array(actions), np.array(rewards, dtype=np.float32),
np.array(dones, dtype=np.bool), np.array(next_states))
但我们还没有完成。如果您在知道它的结构是基于创建数据加载器的思想创建的,然后使用它将小批量的经验传递给每个训练步骤这些原理之前使用过Lightning;那么对于大多数ML系统(如监督模型),这一切如何生效的是很清楚的。但是当我们在生成数据集时,它又是如何生效的呢?
我们需要创建自己的可迭代数据集,它使用不断更新的重播缓冲区来采样以前的经验。然后,我们有一小批经验被传递到训练步骤中用于计算我们的损失,就像其他任何模型一样。除了包含输入和标签之外,我们的小批量包含(状态, 行为, 奖励, 下一状态, 已经完成的事件)
classRLDataset(IterableDataset):
"""
Iterable Dataset containing the ReplayBuffer
which will be updated with new experiences during training
Args:
buffer: replay buffer
sample_size: number of experiences to sample at a time
"""
def__init__(self, buffer: ReplayBuffer, sample_size: int = 200) -> None:
self.buffer = buffer
self.sample_size = sample_size
def__iter__(self) -> Tuple:
states, actions, rewards, dones, new_states = self.buffer.sample(self.sample_size)
for i in range(len(dones)):
yield states[i], actions[i], rewards[i], dones[i], new_states[i]
您可以看到,在创建数据集时,我们传入重播缓冲区,然后可以从中采样,以允许数据加载器将批处理传递给Lightning模块。
智能体
智能体类将处理与环境的交互。智能体类主要有三种方法:
get_action:使用传递的ε值,智能体决定是使用随机操作,还是从网络输出中执行Q值最高的操作。
play_step:在这里,智能体通过从get_action中选择的操作在环境中执行一个步骤。从环境中获得反馈后,经验将存储在重播缓冲区中。如果环境已完成该步骤,则环境将重置。最后,返回当前的奖励和完成标志。
reset:重置环境并更新存储在代理中的当前状态。
classAgent:
"""
Base Agent class handeling the interaction with the environment
Args:
env: training environment
replay_buffer: replay buffer storing experiences
"""
def__init__(self, env: gym.Env, replay_buffer: ReplayBuffer) -> None:
self.env = env
self.replay_buffer = replay_buffer
self.reset()
self.state = self.env.reset()
defreset(self) -> None:
""" Resents the environment and updates the state"""
self.state = self.env.reset()
defget_action(self, net: nn.Module, epsilon: float, device: str) -> int:
"""
Using the given network, decide what action to carry out
using an epsilon-greedy policy
Args:
net: DQN network
epsilon: value to determine likelihood of taking a random action
device: current device
Returns:
action
"""
if np.random.random() < epsilon:
action = self.env.action_space.sample()
else:
state = torch.tensor([self.state])
if device notin ['cpu']:
state = state.cuda(device)
q_values = net(state)
_, action = torch.max(q_values, dim=1)
action = int(action.item())
return action
@torch.no_grad()
defplay_step(self, net: nn.Module, epsilon: float = 0.0, device: str = 'cpu') -> Tuple[float, bool]:
"""
Carries out a single interaction step between the agent and the environment
Args:
net: DQN network
epsilon: value to determine likelihood of taking a random action
device: current device
Returns:
reward, done
"""
action = self.get_action(net, epsilon, device)
# do step in the environment
new_state, reward, done, _ = self.env.step(action)
exp = Experience(self.state, action, reward, done, new_state)
self.replay_buffer.append(exp)
self.state = new_state
if done:
self.reset()
return reward, done
Lightning模块
现在我们已经为DQN建立了核心类,我们可以开始考虑训练DQN智能体。这就是lighting要介入的地方。我们将通过构建一个lighting模块,以一种干净和结构化的方式布置我们所有的训练逻辑。
Lightning提供了很多接口和可重写的函数,以获得最大的灵活性,但是我们必须实现4个关键方法才能使项目运行。就是下面的:
- forward()
- configure_optimizers
- train_dataloader
- train_step
有了这4种方法的填充,我们可以使我们遇到的任何ML模型都得到很好的训练。任何需要超过这些方法的东西都可以很好地与Lightning中剩余的接口和回调配合。有关这些可用接口的完整列表,请查看Lightning文档。现在,让我们看看我们的轻量化模型。
初始化
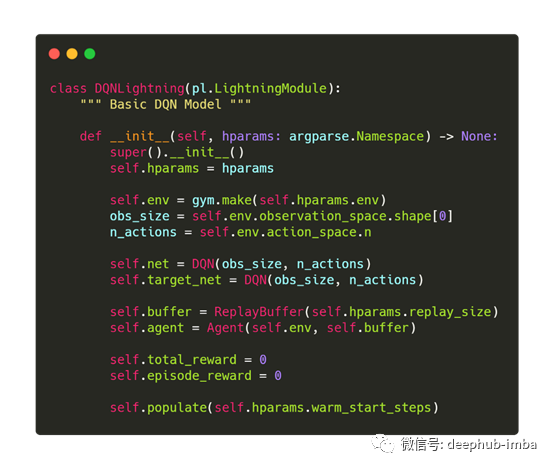
首先,我们需要初始化我们的环境、网络、智能体和重播缓冲区。我们还调用populate函数,它将以随机方式填充重播缓冲区(populate函数在下面的完整代码示例中显示)。
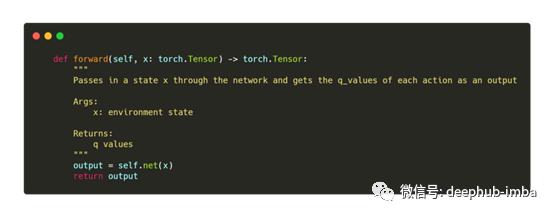
前向传递
我们在这里所做的就是封装我们的DQN网络的前向传递函数。
损失函数
在开始训练智能体之前,我们需要定义损失函数。这里使用的损失函数是基于Lapan的实现。
这是一个简单的均方误差(MSE)损失,将我们的DQN网络的当前状态动作值与下一个状态的预期状态动作值进行比较。在RL中我们没有完美的标签可以学习;相反,智能体从它期望的下一个状态的值的目标值中学习。
然而,通过使用同一个网络来预测当前状态的值和下一个状态的值,结果会成为一个不稳定的运动目标。为了对抗这种情况,我们使用目标网络。此网络是主网络的副本,并定期与主网络同步。这提供了一个临时固定的目标,允许代理计算更稳定的损失函数。
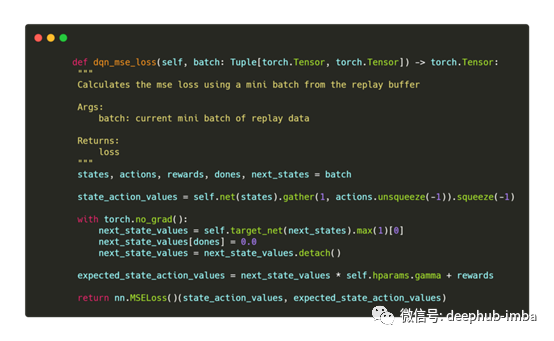
如您所见,状态操作值使用主网络计算,而下一个状态值(相当于我们的目标/标签)使用目标网络。
优化器
这是另外一个简单的补充,只是告诉lighting什么优化器将在反向传递期间使用。我们将使用标准的Adam优化器。

训练数据加载器
接下来,我们需要向Lightning提供我们的训练数据加载器。如您所料,我们初始化了先前创建的IterableDataset。然后像往常一样把这个传递给数据加载器。Lightning将在培训期间处理提供的批次,并将这些批次转换为Pythorch张量,并将它们移动到正确的设备。

训练步骤
最后我们有了训练的步骤。在这里,我们输入了每个训练迭代要执行的所有逻辑。
在每次训练迭代过程中,我们希望智能体通过调用前面定义的agent.play_step()并传入当前设备和ε值,在环境中执行一步。这将返回该步骤的奖励,以及本次迭代是否在该步骤中完成。我们将步骤奖励添加到整个事件中,以便跟踪智能体在该事件中的成功程度。
接下来,我们使用lighting提供的当前小批量,计算我们的损失。
如果我们已经到了本次迭代的结尾,用done标志表示,我们将用session reward更新当前的total_reward变量。
在步骤的最后,我们检查是否是同步主网络和目标网络的时间。通常在只更新一部分权重的情况下使用软更新,但对于这个简单的示例来说,完全更新就足够了。
最后,我们需要返回一个Dict,其中包含Lightning将用于反向传播的损耗,一个Dict包含我们要记录的值(注意:这些值必须是张量),另一个Dict包含我们要在进度条上显示的任何值。
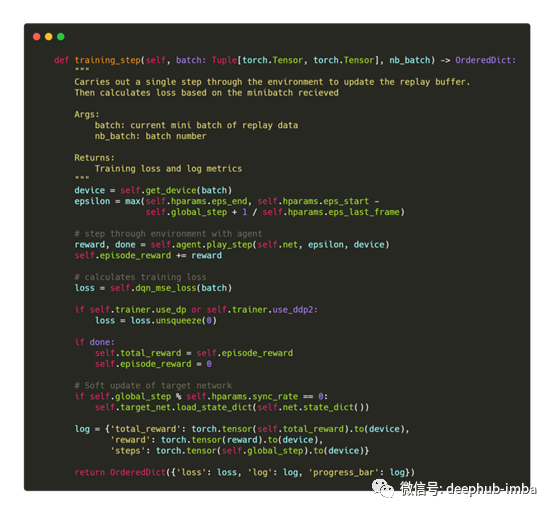
就这样,我们现在有了运行DQN智能体所需的一切。
运行智能体
现在要做的就是初始化并适应我们的lighting模型。在我们的主python文件中,我们将设置种子,并提供一个arg解析器,其中包含我们要传递给模型的任何必要的超参数。
然后在我们的主方法中,我们用指定的参数初始化dqnlighting模型。接下来是Lightning训练器的设置。
在这里,我们设置教练过程使用GPU。如果您没有访问GPU的权限,请从培训器中删除“GPU”和“distributed_backend”参数。这种模式训练非常快,即使是使用CPU,所以为了在运行过程中观察Lightning,我们将关闭早停机制。
最后,因为我们使用的是可迭代数据集,所以需要指定val_check_interval。通常,此间隔是根据数据集的长度自动设置的。然而,可迭代数据集没有一个长度函数。因此,我们需要自己设置这个值,即使我们没有执行验证步骤。

最后一步是调用我们的模型上的trainer.fit(),并观看它的训练。
结果
大约1200代后,您将看到智能体的总奖励达到最大得分200。为了看到正在绘制的奖励指标,调用
tensorboard --logdir lightning_logs
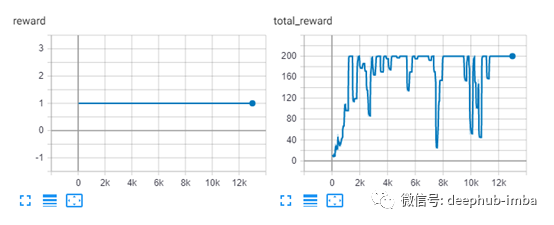
在左边的图中你可以看到每一步的奖励。由于环境的性质,这将始终是1,因为智能体每一步都会得到+1的奖励,极点从没有下降(这就是全部奖励)。在右边的图中我们可以看到每一步的总奖励。智能体很快就达到了最高奖励,然后在好的状态和不好的状态之间波动。
结论
现在您已经看到了在强化学习项目中利用PyTorch Lightning的力量是多么简单和实用。
这是一个非常简单的例子,只是为了说明lighting在RL中的使用,所以这里有很多改进的空间。如果您想将此代码作为模板,并尝试实现自己的代理,下面是一些我会尝试的事情。
降低学习率或许更好。通过在configure_optimizer方法中初始化学习率调度程序来使用它。
- 提高目标网络的同步速率或使用软更新而不是完全更新
- 在更多步骤的过程中使用更渐进的ε衰减。
- 通过在训练器中设置max_epochs来增加训练的代数。
- 除了跟踪tensorboard日志中的总奖励,还跟踪平均总奖励。
- 使用test/val Lightning hook添加测试和验证步骤
- 最后,尝试一些更复杂的模型和环境
- 我希望这篇文章是有帮助的,将有助于启动您使用lighting启动自己的项目。快乐编码!
作者:Donal Byrne
Deephub翻译组:tensor-zhang
关注微信公众号 'deephub-imba' 发送 20200407 获取本文完整代码
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********