
导读:AI大模型日报,爬虫+LLM自动生成,一文览尽每日AI大模型要点资讯!
目前采用“文心一言”(ERNIE 4.0)、“零一万物”(Yi-Large)生成了今日要点以及每条资讯的摘要。欢迎阅读!
《AI大模型日报》今日要点:豆包大模型在评测中显示性能较上一代提升19%,尤其在中文能力上超越GPT-4。Snowflake通过收购AI观测平台TruEra,增强其AI数据云功能与可信度,助力企业确保AI应用准确高效。昆仑万维旗下天工AI凭借卓越技术,DAU超过100万,成为用户活跃的AI内容创作平台。中国电信发布支持30种方言的语音识别大模型,推动方言文化保护。博世团队提出参考神经算子,高效解决工业偏微分方程问题,显著降低学习复杂度。此外,CVPR 2024线上分享会公布日程,聚焦计算机视觉领域最新成果。陈丹琦团队推出SimPO方法,通过微调8B模型超越Claude3 Opus,为大型语言模型优化提供新思路。港大与字节跳动提出多模态大模型新范式Groma,模拟人类先感知后认知过程,提升交互性与指向性。马斯克则计划建造世界最大超算中心,投入10万块H100训练Grok以追赶GPT-4。同时,OpenAI在领导层股权争议和安全团队解散挑战后,迎来AI安全领域资深专家加盟,致力于加强AGI的安全准备工作。
标题: 豆包大模型披露评测成绩,较上一代“云雀”提升19%
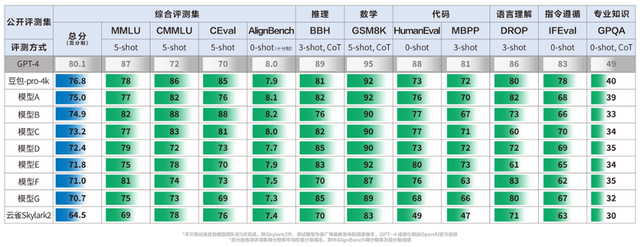
**摘要: **科技记者报道:豆包大模型在火山引擎原动力大会上发布,以低价策略进入市场,并在内部测试中显示出较上一代云雀模型提升19%的性能。在11个主流公开评测集上,豆包模型总分76.8分,优于其他国产模型,并在代码能力、专业知识和指令遵循方面有显著提升。尽管GPT-4在这些评测集上仍保持领先,豆包模型在中文能力上超越GPT-4。第三方评测结果预计将在未来一到两个月内公布。
**网址: **豆包大模型披露评测成绩,较上一代"云雀"提升19% | 量子位
标题: 速递|Snowflake 宣布收购 AI 观测平台 TruEra!
**摘要: **Snowflake 宣布收购 AI 观测平台 TruEra,旨在增强其 AI 数据云的功能和可信度。TruEra 提供评估和监控 LLM 应用和 ML 模型的能力,帮助企业确保 AI 应用的准确性和高效性。此次收购将整合 TruEra 的技术团队,包括三位联合创始人,并进一步提升 Snowflake 在 AI 和 ML 数据治理方面的能力。Snowflake 表示,此次收购是其在生成式 AI 和机器学习能力上持续投资的一部分,以帮助客户最大化数据价值。
**网址: **速递|Snowflake 宣布收购 AI 观测平台 TruEra!|Snowflake|ai|snowflake|truera|唱片|迷你专辑|音乐专辑_手机网易网
标题: 昆仑万维宣布天工AI每日活跃用户(DAU)超过100万
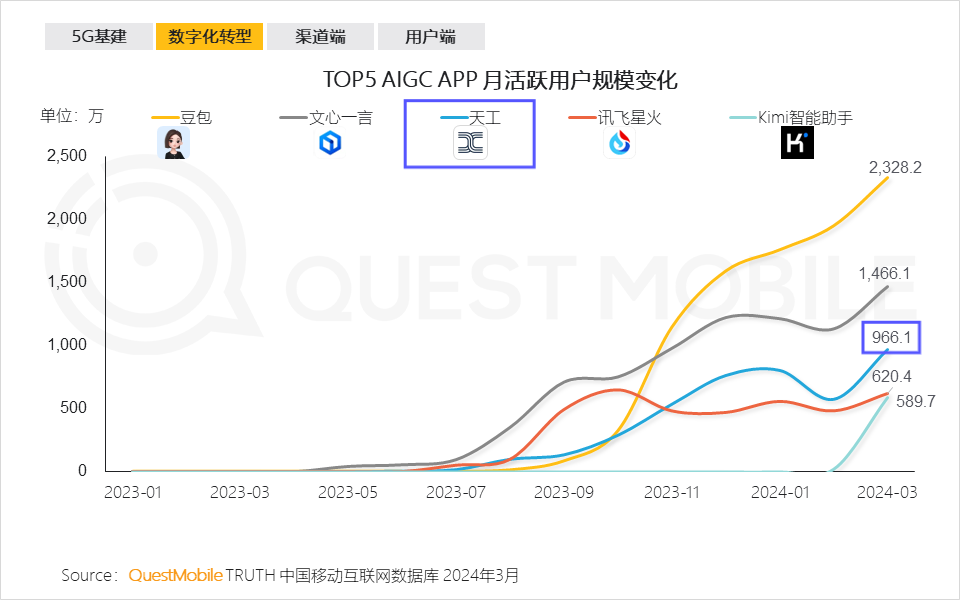
**摘要: **昆仑万维旗下天工AI用户活跃度创新高,DAU超100万。受益于前瞻AI战略与领先产品能力,天工AI聚焦用户体验,优化产品,打造贴近用户场景的AI产品。据QuestMobile数据,3月月活跃用户近千万,成为国内AIGC APP月活跃用户第三。4月17日发布天工3.0与天工SkyMusic,模型技术强大,AI音乐领域领跑全球。4月访问量激增122.58%,增速榜单全国第二。天工AI以用户体验为中心,推出AI搜索研究/增强模式、AI PPT等功能,用户活跃度与留存数据屡创新高。智能体平台吸引用户创建UGC智能体,成为国内领先的AI智能体平台。自2023年4月17日推出以来,天工AI凭借卓越技术与领先产品性能,迅速获得用户青睐。下一步,昆仑万维将推动AI技术应用落地,优化模型技术与用户体验,打造用户首选的人工智能内容创作平台,赋能用户生成高质量AI UGC内容,为我国AI产业发展贡献力量。
**网址: **昆仑万维宣布天工AI每日活跃用户(DAU)超过100万 | 机器之心
标题: 换了30多种方言,我们竟然没能考倒中国电信的语音大模型
**摘要: **中国电信人工智能研究院(TeleAI)近日发布了业内首个支持30种方言自由混说的“星辰超多方言语音识别大模型”,该模型可同时识别理解粤语、上海话、四川话、温州话等各地方言,是国内支持最多方言的语音识别大模型。该模型通过构建超30种、超30万小时的高质量方言数据库,解决了方言数据稀疏的问题,并自主研发了星辰语音识别大模型。团队首创“蒸馏 + 膨胀”联合训练算法,实现了80层模型稳定训练,并通过超大规模语音预训练和多方言联合建模,使单一模型支持30种方言自由混说语音识别。该模型在国际权威赛事中斩获冠军,并在多项基准测试中表现出色,打破了单一模型只能识别特定单一方言的困境。星辰超多方言语音识别大模型已在多个场景中应用,包括智能客服系统,并有望在更广泛的社会生活场景中发挥价值,同时推动对方言文化的保护。
**网址: **换了30多种方言,我们竟然没能考倒中国电信的语音大模型 | 机器之心
标题: 博世团队提出参考神经算子,学习偏微分方程解对几何变形的平滑依赖

**摘要: **科技记者报道: 博世人工智能中心(BCAI)的研究人员开发了一种名为参考神经算子(RNO)的新型神经网络架构,旨在更高效地解决工业应用中常见的偏微分方程问题。传统的神经算子方法需要大量数据来训练模型,以确保解的准确性,这在仿真成本高昂的工程设计优化领域尤其困难。RNO 通过学习解对几何形状微小变化的依赖性,显著提高了数据利用效率。 RNO 方法的核心在于其能够预测参考解在几何形状微小扰动下的变化。这种方法不仅降低了学习复杂度,还在准确度上大幅领先基准模型,实现了高达80%的误差减少。RNO 的分层架构包括编码器、积分算子层和解码器,通过预测解的变化量而非直接预测解本身,降低了学习难度。 研究人员通过一系列实验验证了RNO的有效性,包括与多种基线模型的比较。RNO在所有测试问题上的表现均优于其他模型,尤其是在处理复杂几何形状变化的数据集时,展现了良好的泛化能力和处理自由形式变形的能力。这一创新方法为工程设计优化领域提供了高效、灵活的工具,特别是在单次仿真成本高昂的场景中。
**网址: **博世团队提出参考神经算子,学习偏微分方程解对几何变形的平滑依赖 | 机器之心
标题: 大模型时代的计算机视觉!CVPR 2024线上分享会全日程公布

**摘要: **自从 OpenAI 发布 ChatGPT 以来,科技界对大型语言模型和人工智能生成内容(AIGC)的关注度显著提升。在计算机视觉(CV)领域,研究热点也在不断变化。为了快速了解 AI 领域的最新科研成果与发展趋势,参加顶级会议论文分享会是一个有效途径。CVPR(计算机视觉与模式识别会议)作为 CV 领域的顶级会议,今年共收到 11532 份论文投稿,其中 2719 篇被接收,录用率为 23.6%。为了促进国内 CV 社区的学术交流,机器之心计划于 2024 年 6 月 1 日举办「CVPR 2024 线上论文分享会」,邀请 AI 社区成员参与。分享会将包括 Keynote 演讲和论文分享环节,并邀请顶级专家和论文作者就 CV 热门主题进行交流。
**网址: **大模型时代的计算机视觉!CVPR 2024线上分享会全日程公布 | 机器之心
标题: 陈丹琦团队新作:微调8B模型超越Claude3 Opus,背后是RLHF新平替
**摘要: **科技记者报道:陈丹琦团队推出新方法SimPO,这是一种简化的RLHF(Reinforcement Learning with Human Feedback)替代方案,旨在提升大型语言模型的性能。SimPO通过微调8B模型,成功超越了Claude 3 Opus,并在多项测试中表现出色。与DPO(Direct Preference Optimization)相比,SimPO不仅性能更优,而且资源消耗更低,训练时间和GPU使用量大幅减少。 SimPO的核心在于简化训练流程,摆脱了对参考模型的依赖,并通过长度归一化的对数概率来构建奖励函数,鼓励模型生成简洁且高质量的回复。此外,SimPO还引入了奖励差异项来加强优化信号,使模型能够更清晰地区分正负样本。 在AlpacaEval 2和Arena-Hard等基准测试中,SimPO调整后的模型表现超越了其他优化方法,包括DPO。同时,SimPO的开销也大幅减少,训练时间和GPU消耗均有所降低。 尽管SimPO展现出巨大潜力,但作者也指出了一些不足,如未明确考虑安全性和诚实性,以及在某些需要密集推理的任务上表现下降。未来,团队计划通过集成正则化策略等方法来改进SimPO。 SimPO的成果已开源,并迅速被大模型微调平台Llama-Factory引进。这项技术的创新性应用为大型语言模型的优化提供了新的思路。
**网址: **陈丹琦团队新作:微调8B模型超越Claude3 Opus,背后是RLHF新平替 | 量子位
标题: 港大字节提出多模态大模型新范式,模拟人类先感知后认知

**摘要: **香港大学和字节跳动商业化团队的研究人员提出了一种名为Groma的新范式,旨在提升多模态大模型的感知定位能力。Groma通过区域性图像编码来增强模型对图像中物体位置的识别,从而在视觉任务中实现更准确的定位。这种新方法允许模型将文本内容与图像区域直接关联起来,显著提升了对话的交互性和指向性。Groma的核心思路是将定位功能转移到多模态大模型的vision tokenizer中,利用vision tokenizer的空间理解能力来发现并定位潜在的物体,而无需外接专家模型。研究人员采用超过8M的数据来预训练Region Proposer,以提高定位的鲁棒性和准确性。实验结果显示,Groma在多个基准测试中表现优异,包括Grounding Benchmarks和VQA Benchmark。这种先感知后认知的模型设计不仅符合人类的视觉过程,还避免了重新训练大语言模型的计算开销。字节跳动正持续加大对顶尖人才和前沿技术的投入力度,参与行业顶尖的技术挑战和攻坚。
**网址: **港大字节提出多模态大模型新范式,模拟人类先感知后认知 | 量子位
标题: 马斯克烧几十亿美元造最大超算中心,10万块H100训练Grok追赶GPT-4o

**摘要: **科技巨头间的AI竞赛愈演愈烈,马斯克不甘落后,宣布将建造世界最大的超算中心。他的xAI公司发布了Grok 1.5,并计划推出Grok 2,但受限于算力不足。马斯克表示,训练Grok 2需要约2万个基于Hopper架构的英伟达H100 GPU,而Grok 3及更高版本将需要10万个H100芯片。特斯拉财报显示,公司受到算力限制,马斯克计划部署8.5万个H100 GPU。他希望在2025年秋季前让这台超级计算机运行起来,并与Oracle合作共建。这个「超级计算工厂」一旦完工,规模将至少是当前最大GPU集群的4倍。然而,Meta、微软和OpenAI也在积极扩建算力,竞争激烈。英伟达成为关键供应商,其H100和即将推出的B100 GPU将助力科技巨头升级算力。马斯克还指出,除了芯片短缺,电力供应将成为未来AI发展的主要限制因素。
**网址: **马斯克烧几十亿美元造最大超算中心,10万块H100训练Grok追赶GPT-4o|英伟达|马斯克|电力_新浪新闻
标题: AI初创集体跳槽OpenAI,Ilya出走后安全团队重整旗鼓!

**摘要: **OpenAI面临领导层股权争议和AI安全团队解散的双重挑战。据报道,高级领导层对股权回收条款知情并签署,而安全团队的解散和未兑现的资源承诺引发了外界对OpenAI安全承诺的质疑。然而,随着Indent的CEO Fouad Matin及其团队加入OpenAI,致力于AGI安全准备,公司似乎正在重整旗鼓。Matin在AI安全和产品设计方面有着丰富的经验,他的加入可能会为OpenAI的安全工作带来新的活力。
**网址: **AI初创集体跳槽OpenAI,Ilya出走后安全团队重整旗鼓!|AI_新浪新闻
版权归原作者 常政 所有, 如有侵权,请联系我们删除。