
【自然语言处理(NLP)】基于循环神经网络实现情感分类

活动地址:CSDN21天学习挑战赛
作者简介:在校大学生一枚,华为云享专家,阿里云星级博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
任务描述
本示例教程演示如何在IMDB数据集上用RNN网络完成文本分类的任务。
IMDB数据集是一个对电影评论标注为正向评论与负向评论的数据集,共有25000条文本数据作为训练集,25000条文本数据作为测试集。 该数据集的官方地址为: http://ai.stanford.edu/~amaas/data/sentiment/
一、环境配置
导入相关包
import paddle
import numpy as np
import matplotlib.pyplot as plt
import paddle.nn as nn
print(paddle.__version__)# 查看当前版本# cpu/gpu环境选择,在 paddle.set_device() 输入对应运行设备。
device = paddle.set_device('gpu')
二、数据准备
- 由于IMDB是NLP领域中常见的数据集,飞桨框架将其内置,路径为 paddle.text.datasets.Imdb。通过 mode 参数可以控制训练集与测试集。
print('loading dataset...')
train_dataset = paddle.text.datasets.Imdb(mode='train')
test_dataset = paddle.text.datasets.Imdb(mode='test')print('loading finished')
- 构建了训练集与测试集后,可以通过 word_idx 获取数据集的词表。在飞桨框架2.0版本中,推荐使用padding的方式来对同一个batch中长度不一的数据进行补齐,所以在字典中,我们还会添加一个特殊的词,用来在后续对batch中较短的句子进行填充。
word_dict = train_dataset.word_idx # 获取数据集的词表# add a pad token to the dict for later padding the sequence
word_dict['<pad>']=len(word_dict)for k inlist(word_dict)[:5]:print("{}:{}".format(k.decode('ASCII'), word_dict[k]))print("...")for k inlist(word_dict)[-5:]:print("{}:{}".format(k ifisinstance(k,str)else k.decode('ASCII'), word_dict[k]))print("totally {} words".format(len(word_dict)))
(一)、参数设置
- 在这里我们设置一下词表大小,embedding的大小,batch_size,等等
vocab_size =len(word_dict)+1print(vocab_size)
emb_size =256
seq_len =200
batch_size =32
epochs =2
pad_id = word_dict['<pad>']
classes =['negative','positive']# 生成句子列表defids_to_str(ids):# print(ids)
words =[]for k in ids:
w =list(word_dict)[k]
words.append(w ifisinstance(w,str)else w.decode('ASCII'))return" ".join(words)
- 在这里,取出一条数据打印出来看看,可以用 docs 获取数据的list,用 labels 获取数据的label值,打印出来对数据有一个初步的印象。
# 取出来第一条数据看看样子。
sent = train_dataset.docs[0]
label = train_dataset.labels[1]print('sentence list id is:', sent)print('sentence label id is:', label)print('--------------------------')print('sentence list is: ', ids_to_str(sent))print('sentence label is: ', classes[label])
(二)、用padding的方式对齐数据
文本数据中,每一句话的长度都是不一样的,为了方便后续的神经网络的计算,常见的处理方式是把数据集中的数据都统一成同样长度的数据。这包括:对于较长的数据进行截断处理,对于较短的数据用特殊的词进行填充。接下来的代码会对数据集中的数据进行这样的处理。
# 读取数据归一化处理defcreate_padded_dataset(dataset):
padded_sents =[]
labels =[]for batch_id, data inenumerate(dataset):
sent, label = data[0], data[1]
padded_sent = np.concatenate([sent[:seq_len],[pad_id]*(seq_len -len(sent))]).astype('int32')
padded_sents.append(padded_sent)
labels.append(label)return np.array(padded_sents), np.array(labels)# 对train、test数据进行实例化
train_sents, train_labels = create_padded_dataset(train_dataset)
test_sents, test_labels = create_padded_dataset(test_dataset)# 查看数据大小及举例内容print(train_sents.shape)print(train_labels.shape)print(test_sents.shape)print(test_labels.shape)for sent in train_sents[:3]:print(ids_to_str(sent))
(三)、用Dataset 与 DataLoader 加载
将前面准备好的训练集与测试集用Dataset 与 DataLoader封装后,完成数据的加载。
classIMDBDataset(paddle.io.Dataset):'''
继承paddle.io.Dataset类进行封装数据
'''def__init__(self, sents, labels):
self.sents = sents
self.labels = labels
def__getitem__(self, index):
data = self.sents[index]
label = self.labels[index]return data, label
def__len__(self):returnlen(self.sents)
train_dataset = IMDBDataset(train_sents, train_labels)
test_dataset = IMDBDataset(test_sents, test_labels)
train_loader = paddle.io.DataLoader(train_dataset, return_list=True,
shuffle=True, batch_size=batch_size, drop_last=True)
test_loader = paddle.io.DataLoader(test_dataset, return_list=True,
shuffle=True, batch_size=batch_size, drop_last=True)
三、模型配置
样本出现的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要。
对了适应这种需求,就出现了题主所说的另一种神经网络结构——循环神经网络RNN。
本示例中,我们将会使用一个序列特性的RNN网络,在查找到每个词对应的embedding后,简单的取平均,作为一个句子的表示。然后用
Linear
进行线性变换。为了防止过拟合,我们还使用了
Dropout
。
RNN对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,利用了RNN的这种能力,使深度学习模型在解决语音识别、语言模型、机器翻译以及时序分析等NLP领域的问题时有所突破。
在普通的全连接网络或CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被成为前向神经网络(Feed-forward Neural Networks)。而在RNN中,神经元的输出可以在下一个时间戳直接作用到自身,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输出外,还包括其自身在(m-1)时刻的输出!表示成图就是这样的:
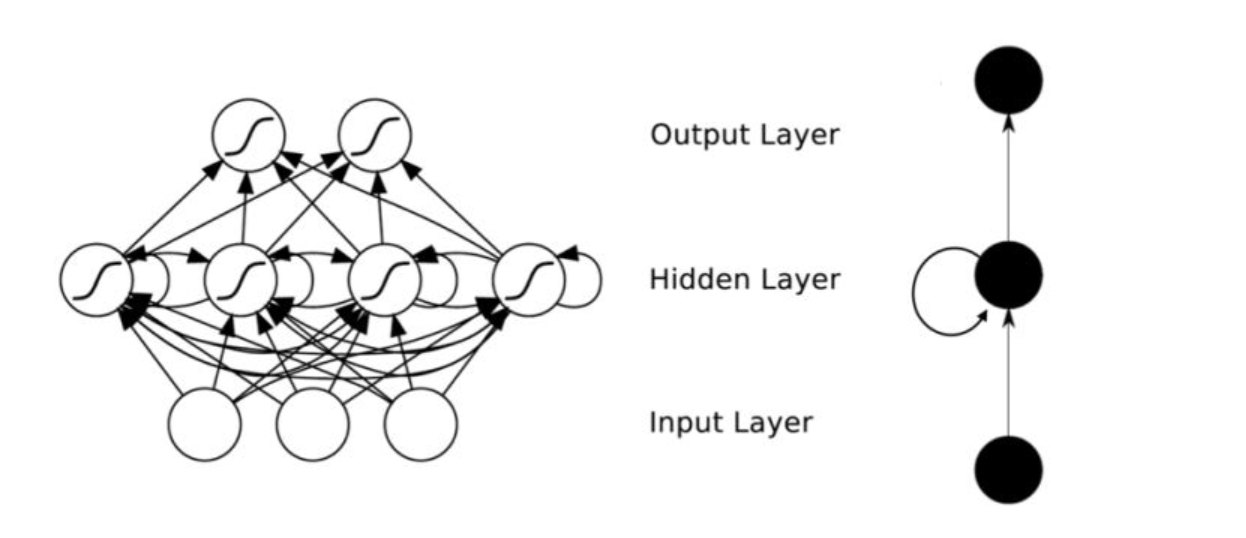
可以看到在隐含层节点之间增加了互连。为了分析方便,我们常将RNN在时间上进行展开,得到如图所示的结构:
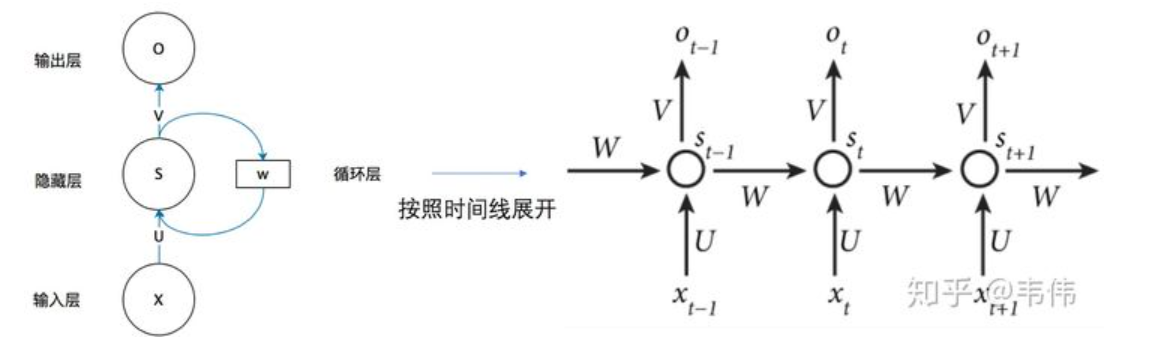
(t+1)时刻网络的最终结果O(t+1)是该时刻输入和所有历史共同作用的结果!这就达到了对时间序列建模的目的。
import paddle.nn as nn
import paddle
# 定义RNN网络classMyRNN(paddle.nn.Layer):def__init__(self):super(MyRNN, self).__init__()
self.embedding = nn.Embedding(vocab_size,256)
self.rnn = nn.SimpleRNN(256,256, num_layers=2, direction='forward',dropout=0.5)
self.linear = nn.Linear(in_features=256*2, out_features=2)
self.dropout = nn.Dropout(0.5)defforward(self, inputs):
emb = self.dropout(self.embedding(inputs))#output形状大小为[batch_size,seq_len,num_directions * hidden_size]#hidden形状大小为[num_layers * num_directions, batch_size, hidden_size]#把前向的hidden与后向的hidden合并在一起
output, hidden = self.rnn(emb)
hidden = paddle.concat((hidden[-2,:,:], hidden[-1,:,:]), axis =1)#hidden形状大小为[batch_size, hidden_size * num_directions]
hidden = self.dropout(hidden)return self.linear(hidden)
四、模型训练
(一)、可视化定义
# 可视化定义defdraw_process(title,color,iters,data,label):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel(label, fontsize=20)
plt.plot(iters, data,color=color,label=label)
plt.legend()
plt.grid()
plt.show()
(二)、对模型进行封装
# 对模型进行封装deftrain(model):
model.train()
opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
steps =0
Iters, total_loss, total_acc =[],[],[]for epoch inrange(epochs):for batch_id, data inenumerate(train_loader):
steps +=1
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label)
acc = paddle.metric.accuracy(logits, label)if batch_id %500==0:# 500个epoch输出一次结果
Iters.append(steps)
total_loss.append(loss.numpy()[0])
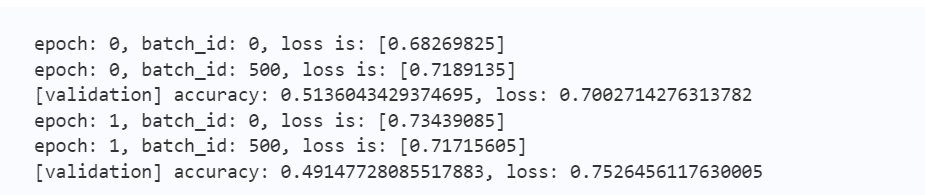
total_acc.append(acc.numpy()[0])print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy()))
loss.backward()
opt.step()
opt.clear_grad()# evaluate model after one epoch
model.eval()
accuracies =[]
losses =[]for batch_id, data inenumerate(test_loader):
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label)
acc = paddle.metric.accuracy(logits, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)print("[validation] accuracy: {}, loss: {}".format(avg_acc, avg_loss))
model.train()# 保存模型
paddle.save(model.state_dict(),str(epoch)+"_model_final.pdparams")# 可视化查看
draw_process("trainning loss","red",Iters,total_loss,"trainning loss")
draw_process("trainning acc","green",Iters,total_acc,"trainning acc")
model = MyRNN()
train(model)
输出结果如下图1所示:
五、模型评估
'''
模型评估
'''
model_state_dict = paddle.load('1_model_final.pdparams')# 导入模型
model = MyRNN()
model.set_state_dict(model_state_dict)
model.eval()
accuracies =[]
losses =[]for batch_id, data inenumerate(test_loader):
sent = data[0]
label = data[1]
logits = model(sent)
loss = paddle.nn.functional.cross_entropy(logits, label)
acc = paddle.metric.accuracy(logits, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)print("[validation] accuracy: {}, loss: {}".format(avg_acc, avg_loss))
六、模型预测
defids_to_str(ids):
words =[]for k in ids:
w =list(word_dict)[k]
words.append(w ifisinstance(w,str)else w.decode('UTF-8'))return" ".join(words)
label_map ={0:"negative",1:"positive"}# 导入模型
model_state_dict = paddle.load('1_model_final.pdparams')
model = MyRNN()
model.set_state_dict(model_state_dict)
model.eval()for batch_id, data inenumerate(test_loader):
sent = data[0]
results = model(sent)
predictions =[]for probs in results:# 映射分类label
idx = np.argmax(probs)
labels = label_map[idx]
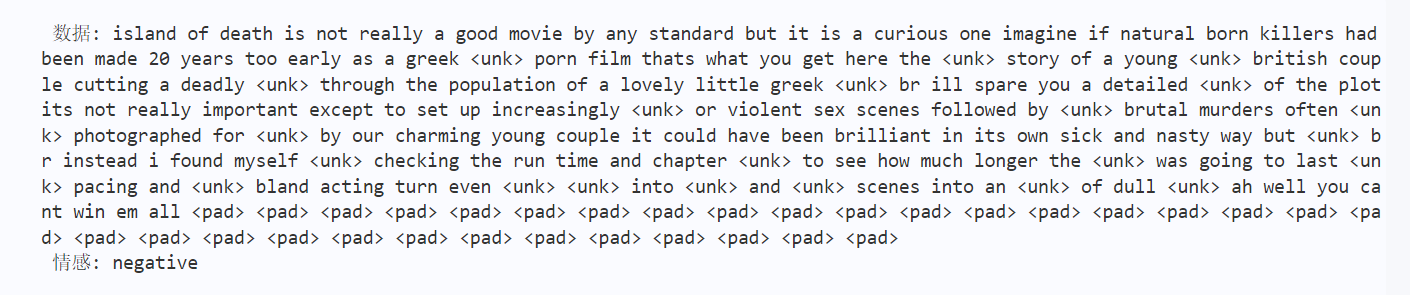
predictions.append(labels)for i,pre inenumerate(predictions):print(' 数据: {} \n 情感: {}'.format(ids_to_str(sent[0]), pre))breakbreak
输出结果如下图2所示:
总结
本系列文章内容为根据清华社出版的《机器学习实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~

版权归原作者 ぃ灵彧が 所有, 如有侵权,请联系我们删除。