
1. 简介
本期为大家带来车位线检测相关知识点,以及算法工程落地的全流程演示。上期我们讲了车位线检测是自动泊车领域必不可缺的一环,而今天的车道线检测则是辅助驾驶领域必不可缺的一环。
所谓车道线检测任务就是对当前行驶道路的车道线进行检测,给出自车道及左右两侧至少各一个车道的车位线信息,如车道线的曲率、类型(虚线、实线、黄线、白线等)、宽度、长度等信息,从而进行车道保持、变道等功能。
2. 任务难点
1)车道线一般为细长形的外观结构,需要强大的高低层次特征融合来同时获取全局的空间结构关系和细节处的定位精度;
2)车道线的状态呈现具有不确定性,如被遮挡、磨损、道路变化时本身的不连续性、天气影响(雨、雪)等。需要网络针对不同情况具备较强的推理能力;
3)车辆的偏离或换道过程会产生自车所在车道的切换,车道线也会发生左/右线的切换。一些提前给车道线赋值固定序号的方法,在换道过程中会产生歧义的情况;
4)车道线检测必须实时或更快速地执行,以节省其他系统的处理能力。
3. 算法一览
3.1. 传统算法
在上个世纪,科学家就通过手工提取特征等传统计算机视觉的方式进行车道线检测,主要步骤为:
1)去畸变;通过透视变换将前视图转换为俯视图,从而划定ROI;
2)通过Canny/Sobel等边缘检测滤波,或是色彩阈值滤波等方式分割出车道线区域;
3)然后结合霍夫变换、RANSAC等算法进行车道线检测;最后进行跟踪。
然而传统算法存在很多致命的问题,比如:
1)算法需要人工手动去调滤波算子,根据算法所针对的街道场景特点手动调节参数,工作量大且鲁棒性较差,当行车环境出现明显变化时,车道线的检测效果不佳。
2)透视变换可以做多车道检测但在遮挡等情况下干扰严重,而且摄像机的安装和道路本身的倾斜都会影响变换效果。
随着深度学习算法的兴起,传统算法逐渐被人们所淘汰,我们就不对其进行展开讲解了,如果对此感兴趣,可以参考优达学城(Udacity)车道线检测项目进行了解,其效果如下:

3.2. LaneNet
LaneNet是车道线检测任务中首次提出end to end解决方案的工作,使用的Tusimple dataset是网上最早公开的车道线数据集,且网上很早就有人复现了论文并提供了开源代码,可以说lanenet是大多数人深入了解的第一篇paper。
算法整体流程:
1)网络分为binary segmentation branch(语义分割)和embedding branch(实例分割)两个分支,采用encoder-decoder形式,两者共享encoder层。
2)语义分割分支负责对输入图像像素进行二分类,判断像素属于车道线还是背景,损失函数使用的是标准的交叉熵损失函数。
3)实例分割分支负责对像素进行嵌入式表示,使用基于one-shot的方法做距离度量学习,使用聚类损失函数,将语义分割后得的车道线分离成不同的车道实例,训练后输出一个车道线像素点距离,用于后续聚类。
4)然后将两个分支的结果利用MeanShift算法进行聚类,聚类可以看做是后处理,前一步的Embedding_branch已经为聚类提供好了特征向量,利用这些特征向量可以用任何聚类算法完成实例分割的目标。
5)最后进行拟合,为了提高拟合质量,通常将图像转到鸟瞰图后做拟合,通过HNet输出一个转换矩阵H,将车道线的点坐标通过矩阵H转换到鸟瞰图后,用最小二乘法拟合,再逆变换到原图。
网络结构:
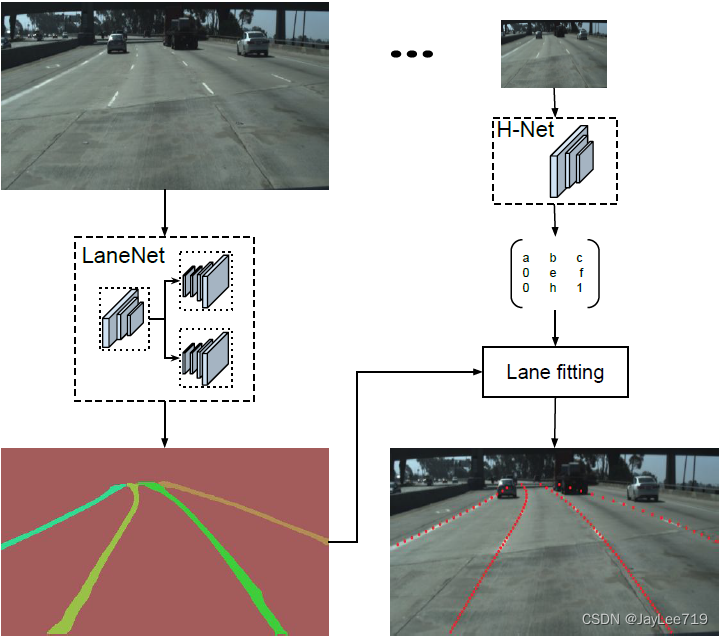
算法评价:
LaneNet是基于语义分割的方法,其亮点在于通过embedding vector与cluster配合使用,能检测不限条数的车道线;且通过HNet学得的perspective transformation,使得lane fitting能够更鲁棒。然而缺点也很明显,包括后续推出的同样基于语义分割的SCNN算法一样,这种基于语义分割的方法避免不了耗时较长的缺陷,在工程落地上不具有优势。
开源代码:github
3.3. Ultra-Fast Lane Detection(v1 and v2)
接下来为大家介绍Ultra-Fast Lane Detection,这是基于行分类的方法,它最大的特点正如名字所示,速度特别快,在GTX1080上可以达到322FPS。
算法整体流程: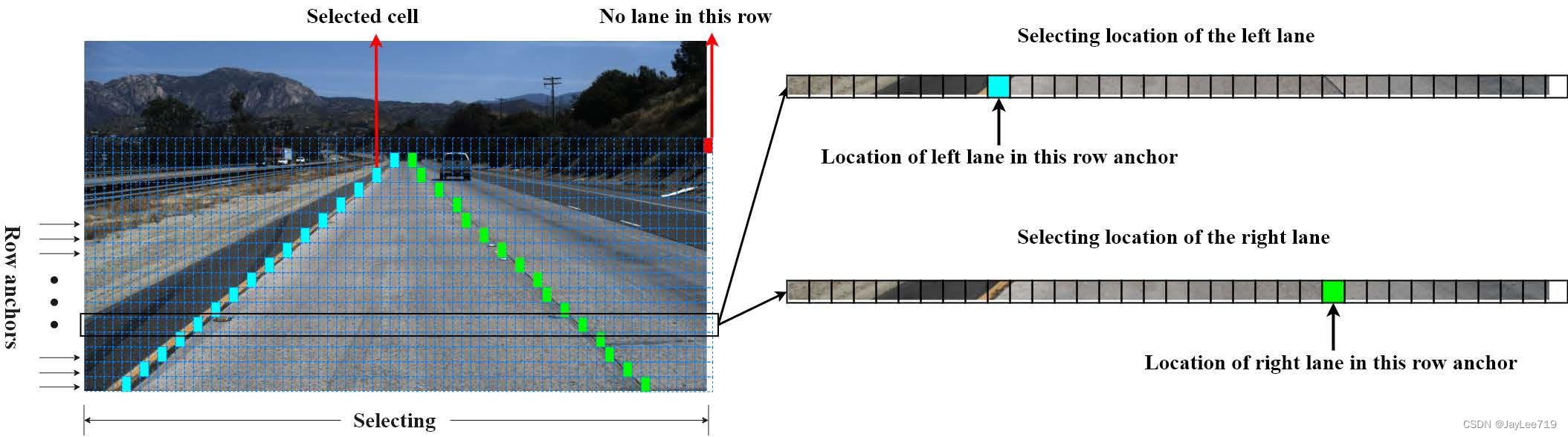
1)将车道线检测定义为寻找车道线在图像中某些行的位置的集合,即基于行方向上的位置选择、分类,将以往分割中需要处理HxW个分类问题直接缩减到了h个分类问题,h远小于H,因此极大地提高的了车道线检测算法的速度。
2)分类方法是基于全连接层的,不是分割的全卷积形式,它所使用的特征是全局特征。这样就直接解决了感受野的问题,在检测某一行的车道线位置时,感受野就是全图大小。那么来自图像其他位置的上下文信息可以用来解决遮挡情况下无视觉线索的问题。
网络结构: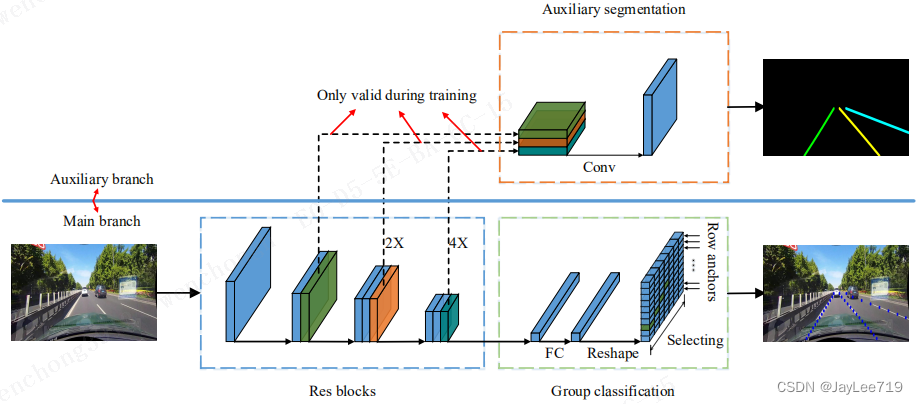
算法评价:
Ultra-Fast Lane Detection可以说是目前最快的检测网络,自然是我们工业落地算法中不错的选择,然而该算法也存在一些问题,首先是精度一般,其次存在一个致命的缺陷:横向锚点检测车道线,当车道线的水平角度比较小时,便会引起定位问题,也就是一定宽度的车道线会覆盖到多个关键点,导致定位错乱,而且角度越小,问题越严重。
v2版针对上述问题,提出了一种混合锚点机制,中间水平角度大的车道线使用横向锚点来表达,两侧水平角度小的车道线用纵向锚点来表达,有效提高了两侧车道线检测精度,也使得其宣称达到了速度精度双SOTA,然而这种锚选方式在泛化性上仍存在一定问题。
开源代码v1:github
开源代码v2:github
3.4. CLRNet
前面为大家介绍了基于语义分割、基于行分类的算法,接下来为大家介绍基于锚框的算法,其中典型算法就是22年的CLRNet,其刷新了精度记录,是目前2D车道线检测精度最高的算法。
算法整体流程:
CLRNet全称是“Cross Layer Refinement Network for Lane Detection”,也就是跨层优化网络,旨在充分利用车道检测中的高层和底层特征。
1)使用一个FPN网络去提取图像特征
2)之后在每个特征stage上去优化车道线的回归结果
3)当前stage的回归结果会被下一阶段的细致优化所采用,从而实现车道线的级联优化。
网络结构:
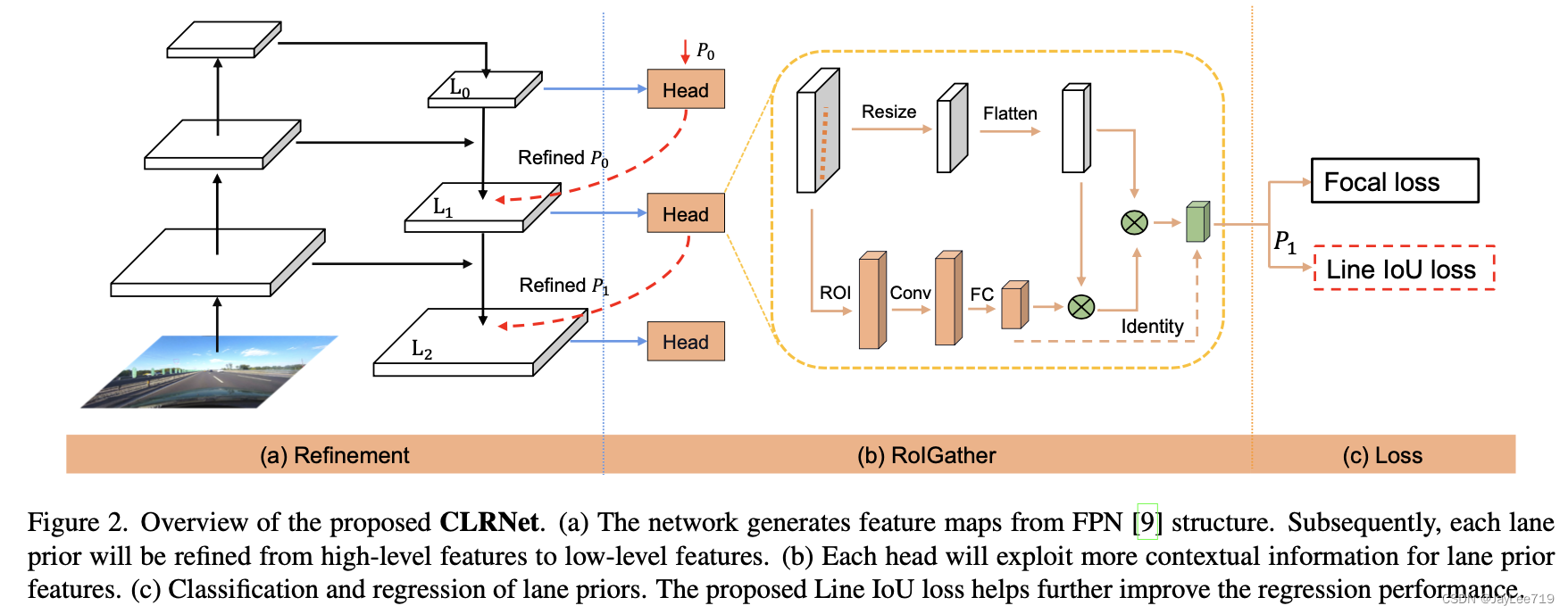
算法评价:
目前精度最高的算法,算法泛化性也很不错,检测效果十分稳定,只是在推理速度上较UFLD存在较大差距,工业落地存在一定困难。
开源代码:github
4. 数据集
常用的数据集有如下三个
4.1. Tusimple
采集美国高速公路数据,天气晴朗,车道线清晰。
车道线以点来标注,图像分辨率1280x720,数量约72k张
4.2. CULane
采集北京公路数据,多为城区,场景包含拥挤,黑夜,无线,暗影等八种难以检测的情况,难度较高。
车道线以点来标注,最多标记4条车道线,图像分辨率1640x590,数量约为98k张

4.3. CurveLanes
华为弯道检测数据集,道路弯曲度高。
标签以点形式json格式,相对BDD ,Tusimple,culane有更多的车道,车道类别不区分。图像分辨率为2560x1440,训练集10万张,验证集2万张,测试级3万张(测试集没有提供标签)。

5. 工程化
又到了我们工程化环节,接下来我们将一步步实现工程落地,这里我们选择实时性最好的Ultra-Fast Lane Detection v2作为我们部署选择。
5.1. 环境准备
1)下载Ultra-Fast-Lane -Detection-v2
git clone https://github.com/cfzd/Ultra-Fast-Lane-Detection-V2
2)下载CULane或CurveLanes数据集,并放入新建的datasets/目录下,可供后续训练使用
Tusimple场景太过简单,适用性不强,一般不选用;
若项目场景弯道较多,推荐选用CurveLanes数据集进行训练,对弯道检测效果更佳。
3)新建一个anaconda虚拟环境并进入
conda create -n UFLDv2 python=3.6source activate UFLDv2
4)安装环境
# If you dont have pytorch
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -r requirements.txt
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist --upgrade nvidia-dali-cuda110
# Install Nvidia DALI (Very fast data loading lib))cd my_interp
sh build.sh
# If this fails, you might need to upgrade your GCC to v7.3.0
build.sh会在此文件夹中生成build、my_interp.egg-info、dist三个文件夹。
5) 下载预训练模型
UFLDv2为我们提供了各个数据集预训练模型,这里推荐使用基于CurveLanes数据集的预训练模型,以更好的适应弯道场景,其中Backbone可根据计算资源自行选择18或34:
CurveLanes_ResNet18
CurveLanes_ResNet34
将下载的模型放入新建的model_pth/目录下。这样环境准备就完成了。
5.2. 进行ROS工程移植
这里可根据专栏前两章节所讲ROS移植基础知识,对工程代码demo.py进行改写,使之实现在ROS环境下运行,先贴出工程代码:
import torch, cv2
from utils.common import merge_config, get_model
import time
import rospy
from sensor_msgs.msg import Image
from cv_bridge import CvBridge, CvBridgeError
classlane_detector():def__init__(self):
self.image_topic ='/drivers/camera/image'
self.output_image_topic ='/perception/camera/plot_lanes'
self.img_w, self.img_h =1280,720
self.channel_mean, self.channel_std =[0.485,0.456,0.406],[0.229,0.224,0.225]
self.init_lane_detector()
self.bridge = CvBridge()
sub_image = rospy.Subscriber(self.image_topic, Image, self.img_callback, queue_size=1)
self.pub_image = rospy.Publisher(self.output_image_topic, Image, queue_size=1)definit_lane_detector(self):
torch.backends.cudnn.benchmark =True
args, self.cfg = merge_config()
self.cfg.batch_size =1print('setting batch_size to 1 for demo generation')
self.net = get_model(self.cfg)
state_dict = torch.load(self.cfg.test_model, map_location='cpu')['model']
compatible_state_dict ={}for k, v in state_dict.items():if'module.'in k:
compatible_state_dict[k[7:]]= v
else:
compatible_state_dict[k]= v
self.net.load_state_dict(compatible_state_dict, strict=False)
self.net.eval()print('start testing...')defimg_callback(self, data):print('Start reading image and preprocessing')
t_start = time.time()
image = self.bridge.imgmsg_to_cv2(data,"bgr8")
image_vis = image
image = cv2.resize(image,(self.cfg.train_width,int(self.cfg.train_height / self.cfg.crop_ratio)), interpolation=cv2.INTER_LINEAR)
image=cv2.cvtColor(image,code=cv2.COLOR_BGR2RGB)
imgs = torch.from_numpy(image).float().permute(2,0,1).unsqueeze(0).cuda()
imgs = imgs.div(255)for i inrange(3):
imgs[:,i,:,:]=(imgs[:,i,:,:]- self.channel_mean[i])/ self.channel_std[i]
imgs = imgs[:,:,-self.cfg.train_height:,:]print('Image load complete, cost time: {:.5f}s'.format(time.time()- t_start))
t_start = time.time()with torch.no_grad():
pred = self.net(imgs)
coords = pred2coords(pred, self.cfg.row_anchor, self.cfg.col_anchor, original_image_width = self.img_w, original_image_height = self.img_h)for lane in coords:for coord in lane:
cv2.circle(image_vis,coord,5,(0,255,0),-1)
t_cost = time.time()- t_start
print('Single imgae inference cost time: {:.5f}s'.format(t_cost))# pub
output_image = self.bridge.cv2_to_imgmsg(image_vis,'bgr8')
output_image.header.stamp = data.header.stamp
output_image.header.frame_id ="base_link"
self.pub_image.publish(output_image)if __name__ =='__main__':
rospy.init_node('lane_detector_node')
lane_detector()
rospy.spin()
以上就是将Ultra-Fast Lane Detection v2移植到ROS下完整代码,仅选本篇作为例子进行详细讲解,专栏后续博客就不再赘述了,望大家认真理解。
下面分函数进行解释:
1)init函数
这里主要是做一些基础定义工作,包括接收原始图像topic、发布检测后的图像topic、图像尺寸大小、图像标准化参数。
2)init_lane_detector函数
这里主要做2块工作:
一是做参数及配置文件读取工作;
二是做网络加载模型参数工作。
3)img_callback回调函数
这里分为4块内容:
一是对接收到的图像按照之前博客所讲内容进行转换,满足网络输入要求;
二是进行网络推理;
三是将网络输出通过pred2coords函数转换为像素坐标,绘制在图像上;
最后是将输出的图像转换回rosmsg进行发布。
4)pred2coords函数
这里对此函数做一些提醒,注意函数中
row_lane_idx = [1,2]
、
col_lane_idx = [0,3]
,这两个变量是车道线索引,可用此索引选择哪些车道线使用行检测结果,哪些车道线使用列检测结果,例如在这里就是指本车道的2条车道线使用行检测结果,而左右更远的2条车道线使用列检测结果。
但需要注意CurveLanes数据集输出车道线不止有4条,而是10条,故需要对其进行拓展,按照自己实际场景需求进行选择。
5.3. 推理
1)运行
roscore
2)进入环境
source activate UFLDv2
source ~/cv_bridge_catkin/devel/setup.bash --extend
3)运行程序,选择配置文件及模型
这里我们预训练模型使用使用CurveLanes_ResNet34,则对应的配置文件为config/curvelanes_res34.py,后续可根据自己项目需求对此文件进行自适应的修改并重新训练。
python run_inros.py configs/curvelanes_res34.py --test_model model_pth/curvelanes_res34.pth
4)回放自己采集的数据bag:
rosbag play data.bag
5)检测结果可视化
运行
rviz
进行可视化,接收上诉工程中指定的topic: ‘/perception/camera/plot_lanes’,即可查看实时检测结果:

6. 总结
本文介绍了历年来的车道线检测算法,并选取当前实时性最好的算法Ultra-Fast Lane Detection v2为例讲解如何实现ROS工程落地,可以看到满足实时性的同时,检测效果也十分优秀。
文章中的链接、项目工程均可私信我获取,有任何技术问题也可向我质询,谢谢大家观看!
版权归原作者 JayLee719 所有, 如有侵权,请联系我们删除。