
这里写目录标题
定义

类型

机器学习主要类型是监督式学习和无监督式学习
而监督式学习是机器学习应用最多的类型
监督学习
定义
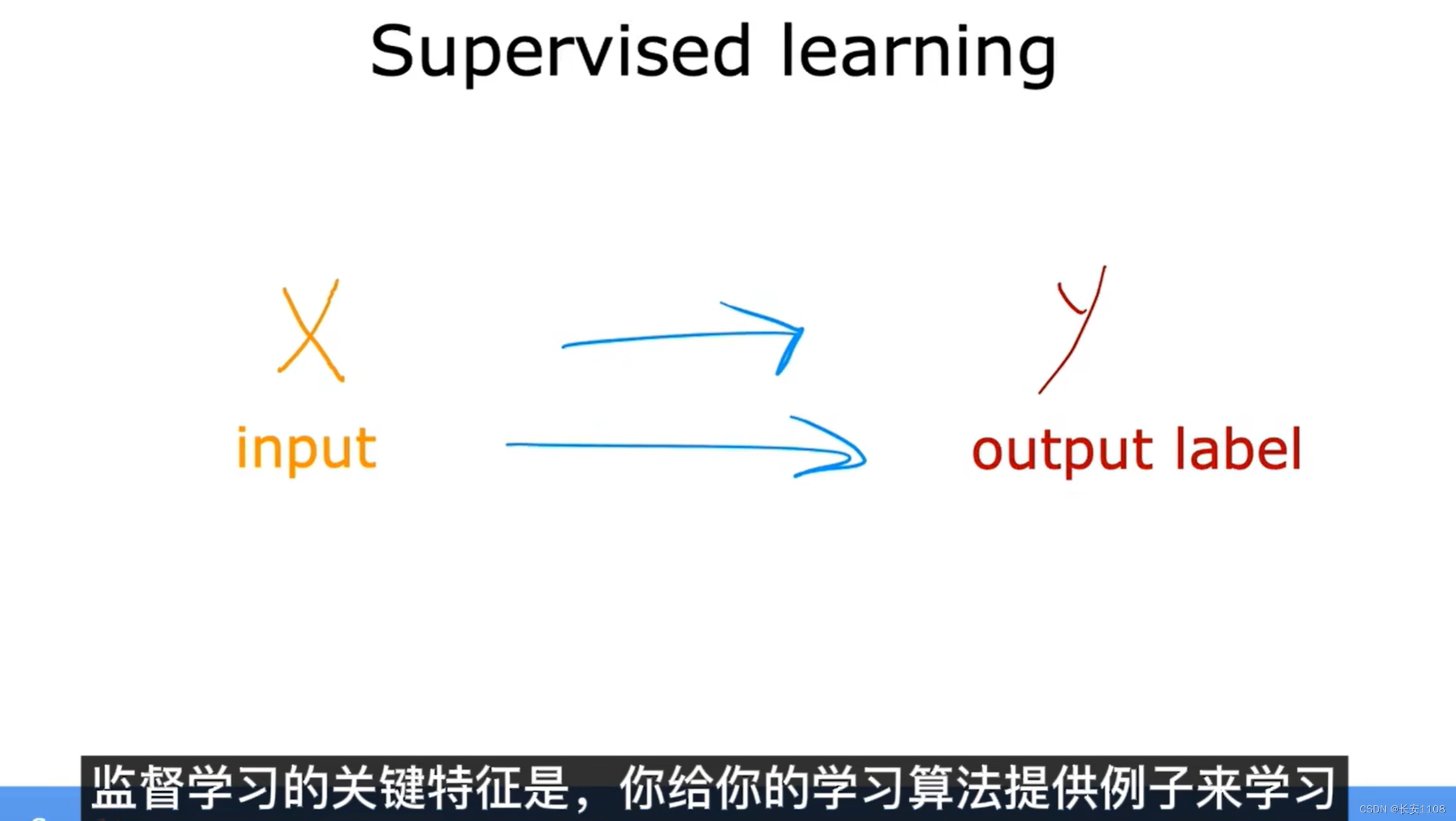


通过上面三个图可以得出,监督式机器学习,就是,首先你有一个学习算法,之后你提供这个学习算法许多带有正确答案的案例,以便算法进行学习,在大量的学习之后,你再次输入一个合理的输入,算法会给出一个合理的预测或者输出
例子
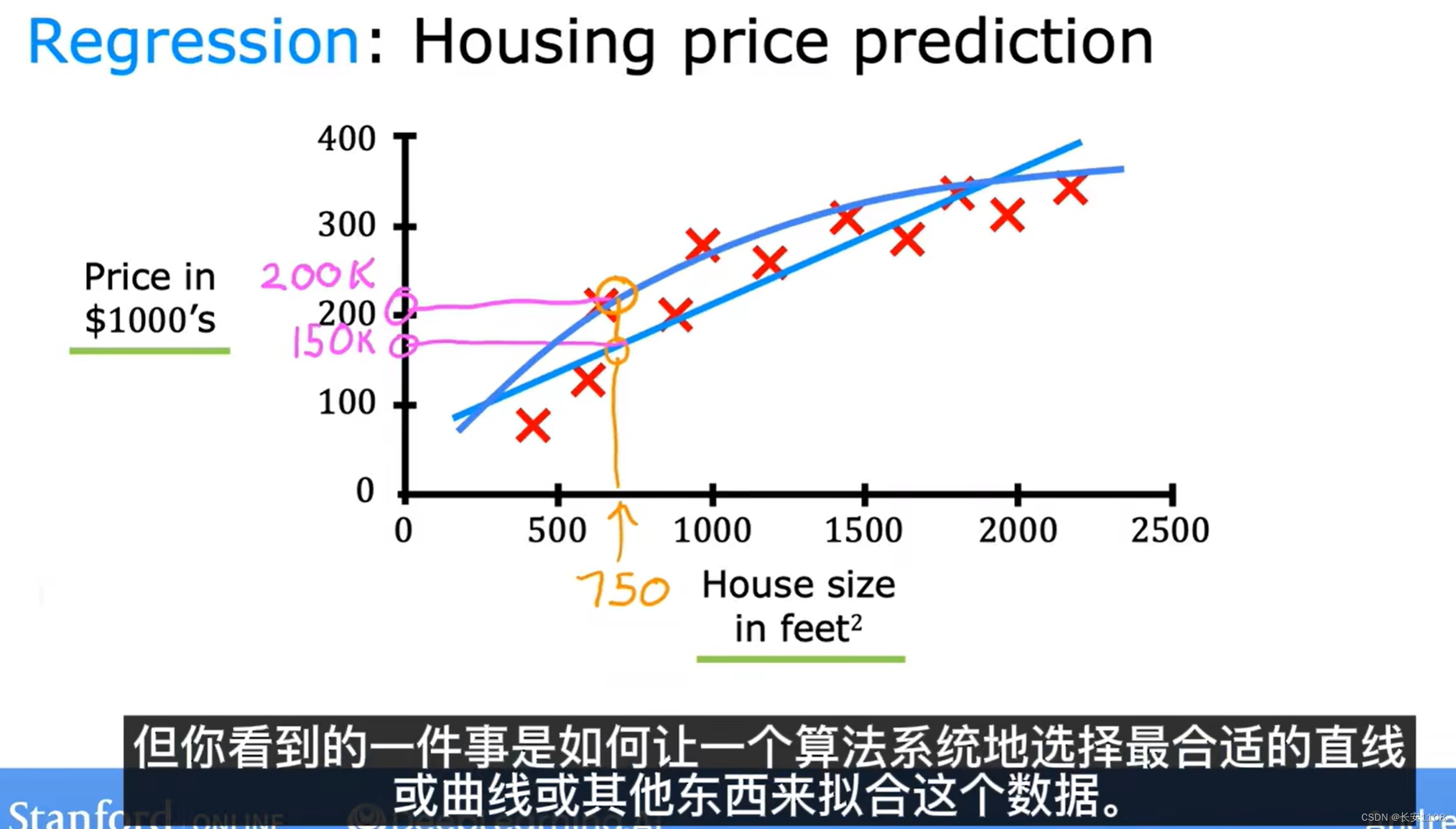
我们想根据一个数据集,预测在750的横轴对应的纵轴数据是多少,我们的工作重心是如何让一个算法系统选择最合适的工序(具体点说此处是函数)来拟合出一个最大限度合理的输出
回归式监督学习
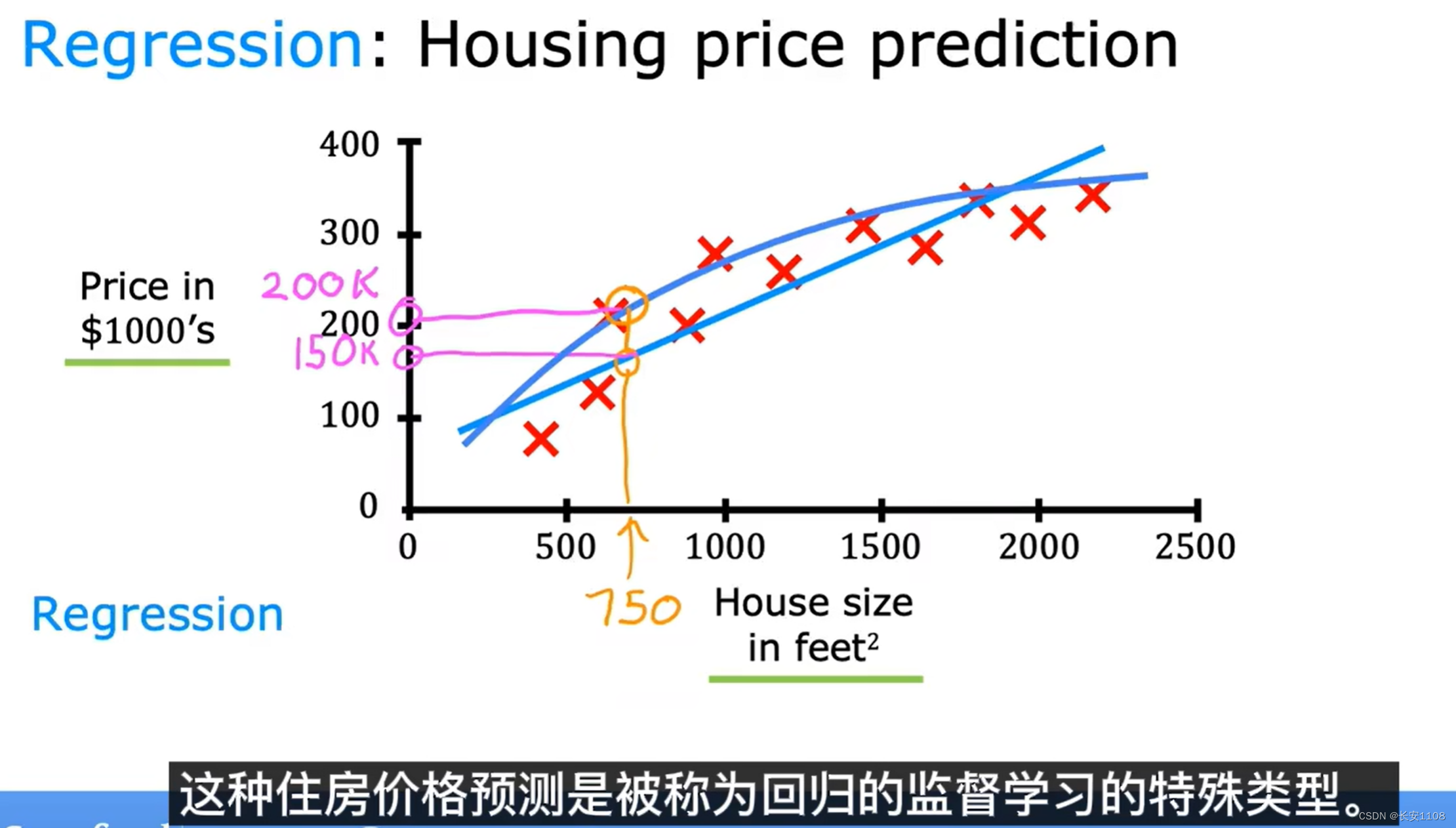
这种房价预测也被称为回归的监督学习的特殊类型,之所以被称为回归,是因为他的输出是从无限多个可能得答案中,输出一个算法认为合理的答案
分类的监督学习
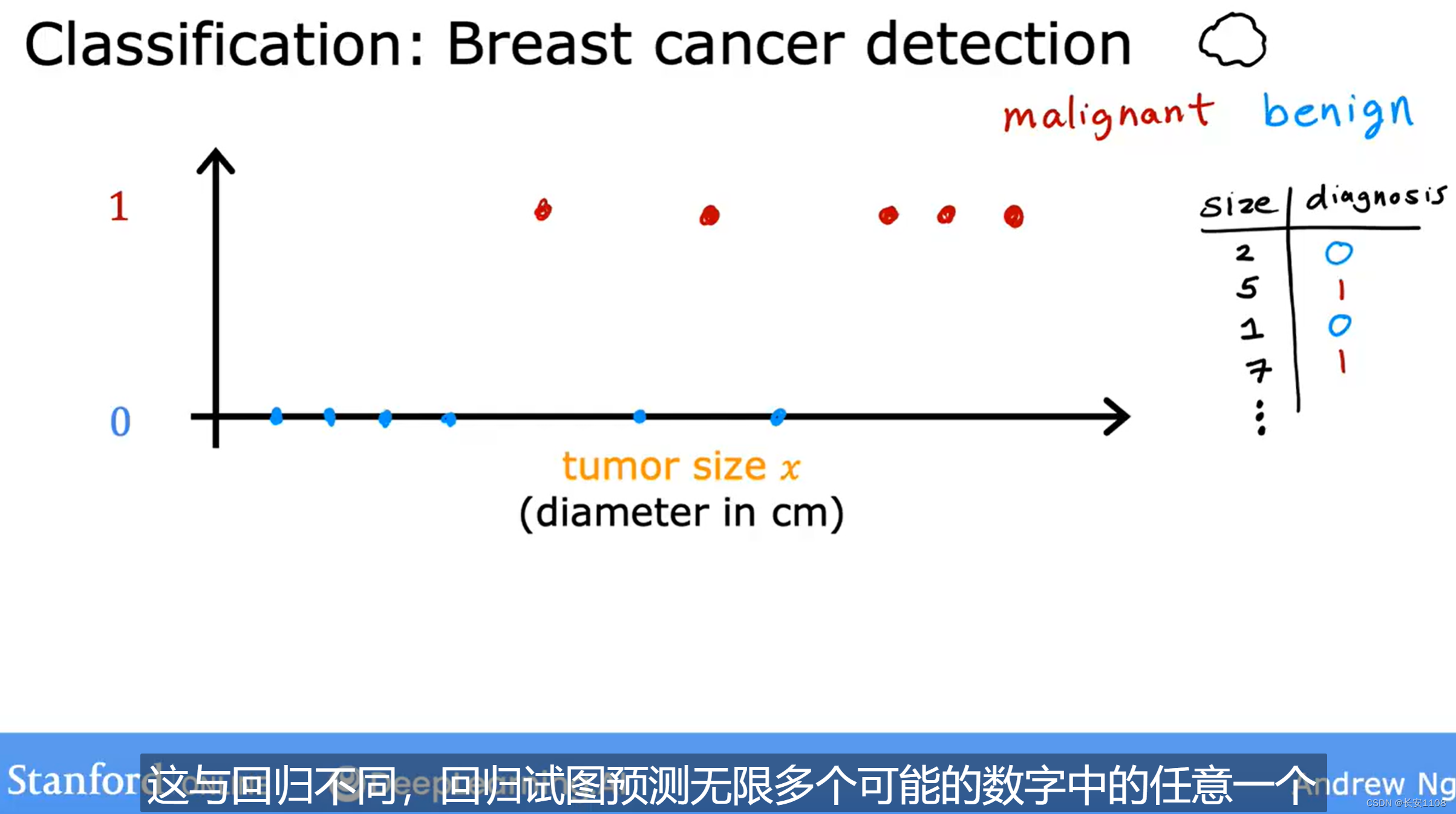
而如果从有限个可能的输出中预测一个合理的输出,那么就是分类式监督学习
分类式监督学习算法,他的输出是非数字居多,而如果输出是数字,他也从确切的有限的数字中做选择,而不是从一个数字范围内做选择(回归式)
多个输入
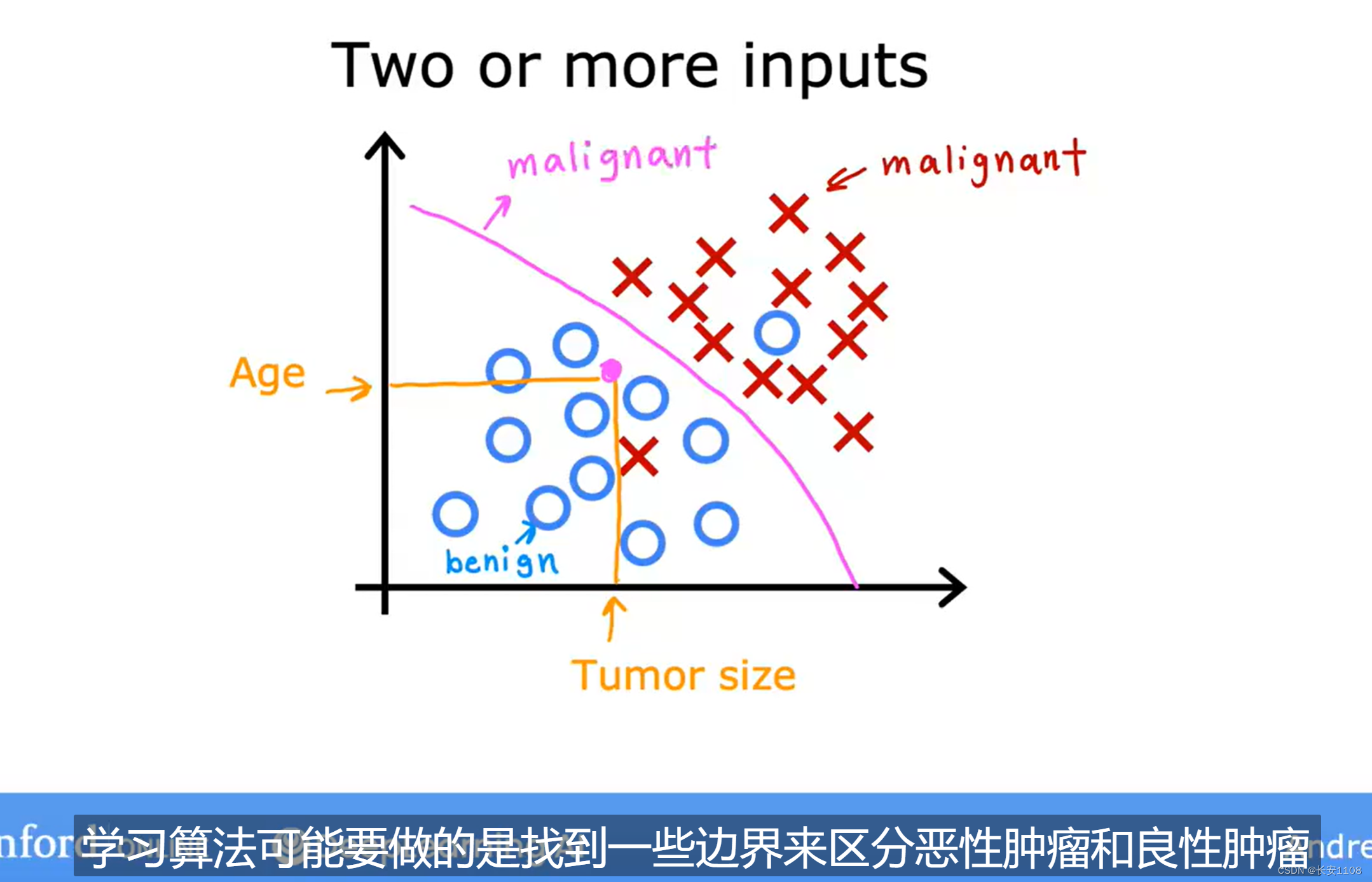
机器学习算法不仅仅局限于只有一个输入,我们可以有多个输入,如上图,横纵轴都是输入,而圈和叉则是代表着输出信息,学习算法的目的可能是找到区分不同结果的边界
总结

监督学习分为两类,回归式和分类式,回归式是从一个数字范围中预测可能得输出(即从无限多个可能的结果中预测出可能的结果)
而分类式是从几个确切的数字或者其他分类符号,这些结果中预测可能得结果(即从有限个可能得结果中预测可能的结果)
无监督学习
定义
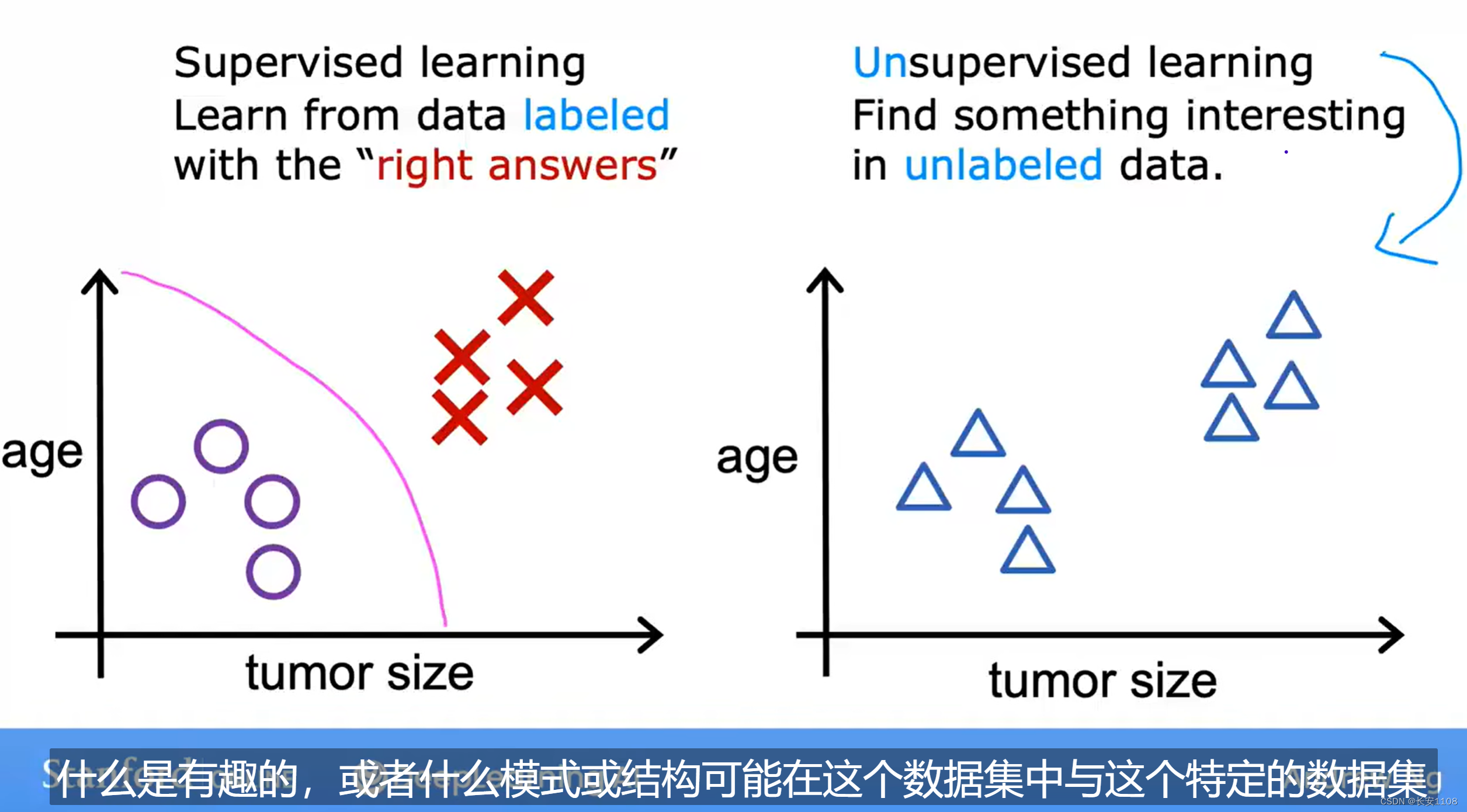
无监督式学习,表示我们给算法的案例中,没有标注哪些是正确答案,哪些是错误答案,或许这些答案本就是普通的同级别的数据,我们的目的不是去让算法通过一个输入去输出一个正确的结果,而是让算法通过我们给的案例,找到这些数据之间存在哪些模式或者结构
因为我们的目的是找到数据之间的模式或者结构,所以,对于无监督式学习,他严格来说没有输出,我们只是输入一些数据,他的输出是“数据之间的结构或者关系”,我们前期并不知晓数据之间的结构或者关系,所以在此之前我们没有输出信息,我们只是输入数据
聚类式无监督学习
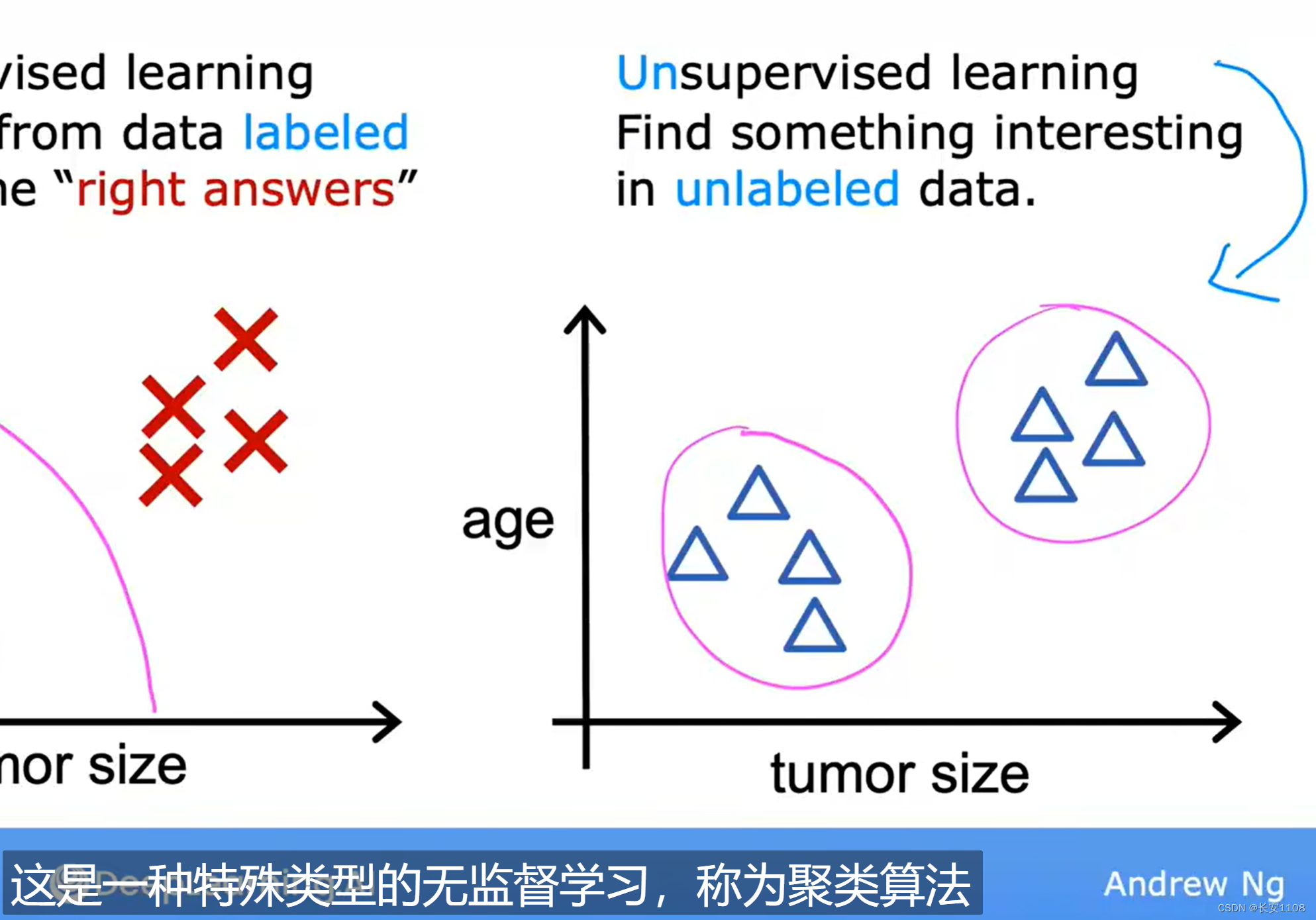
算法对数据案例做出分析之后,将这些数据进行分类分组,称为聚类式无监督学习
例子一: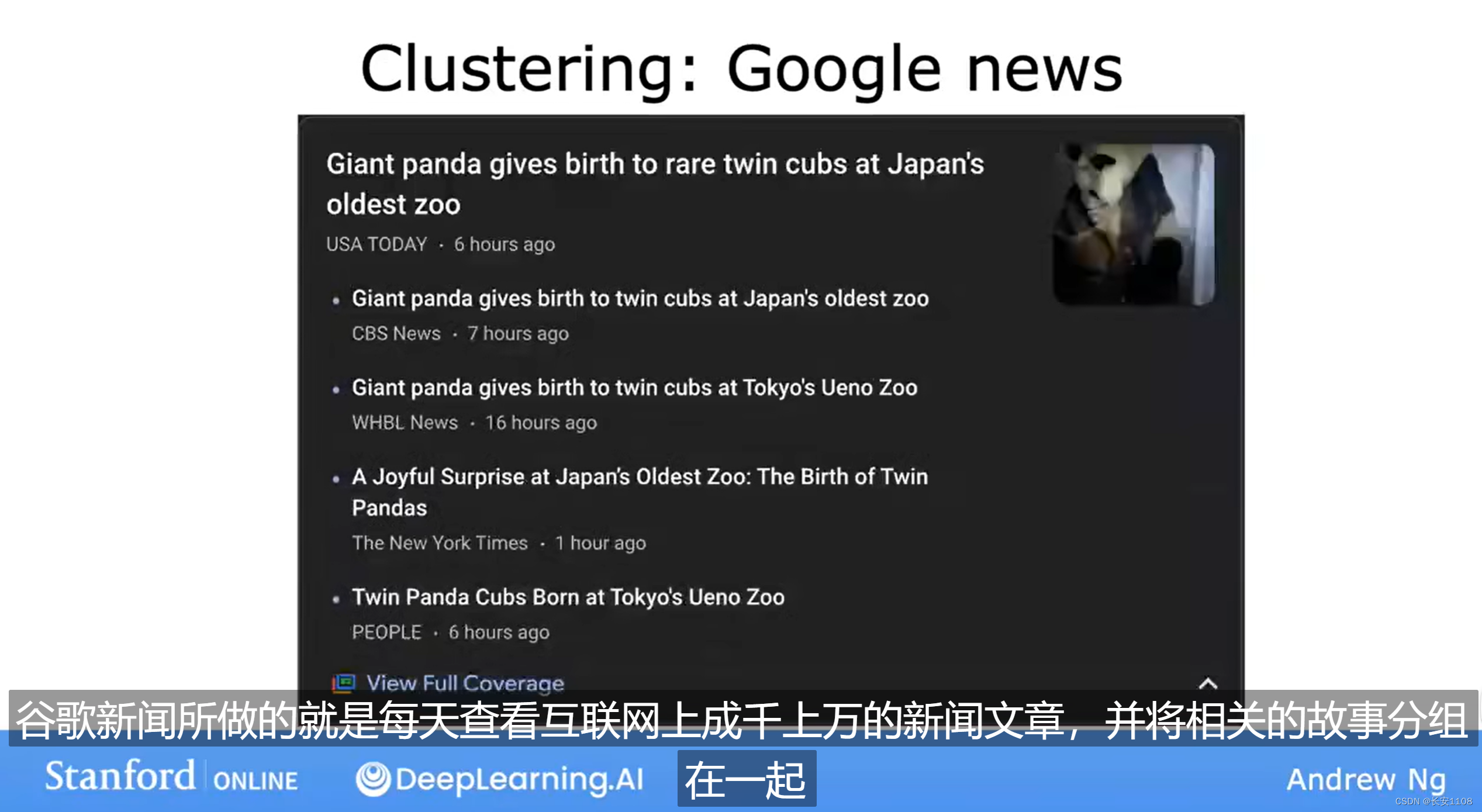
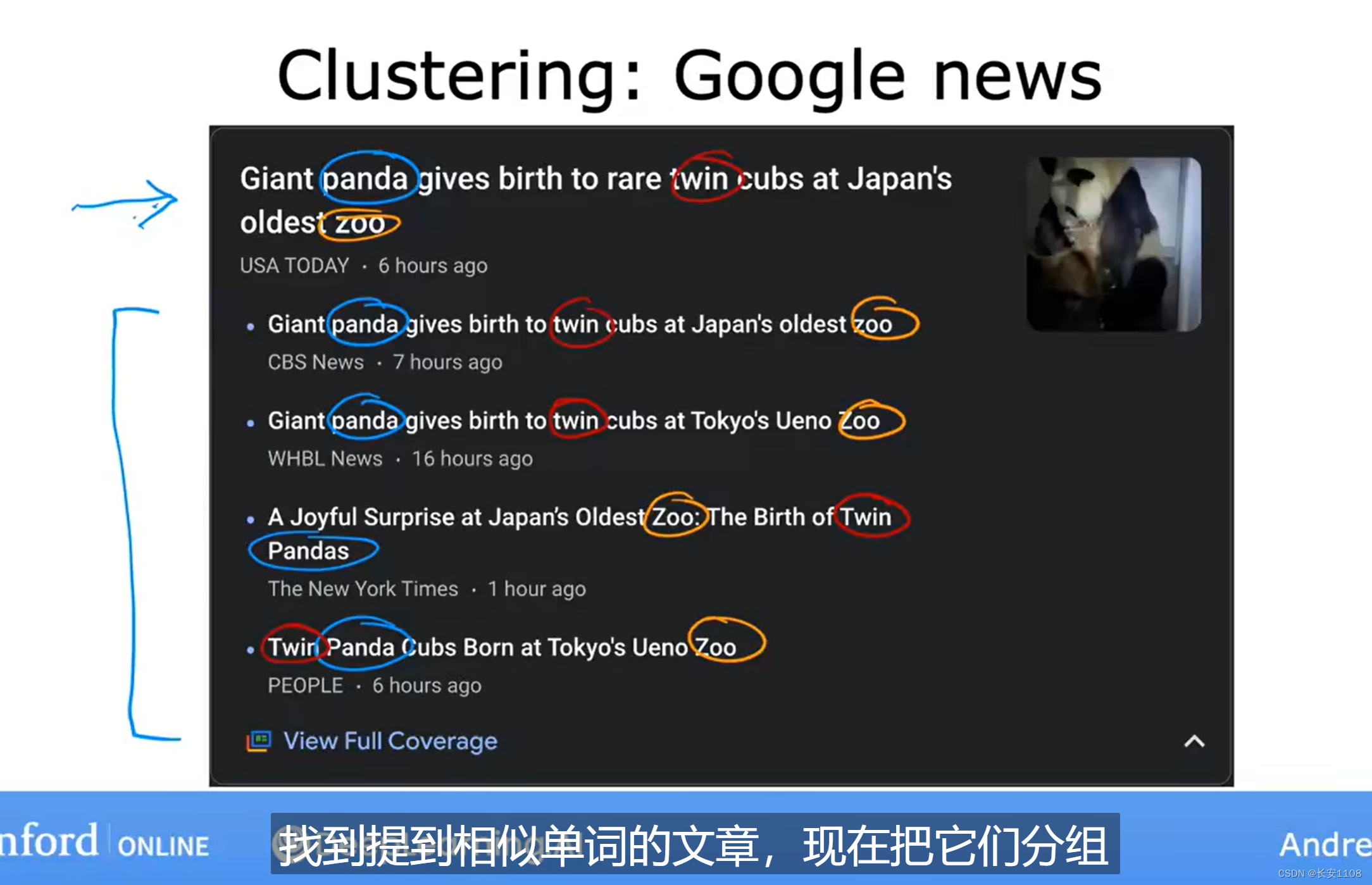
谷歌新闻就是根据一些关键词,将新闻进行分组
例子二: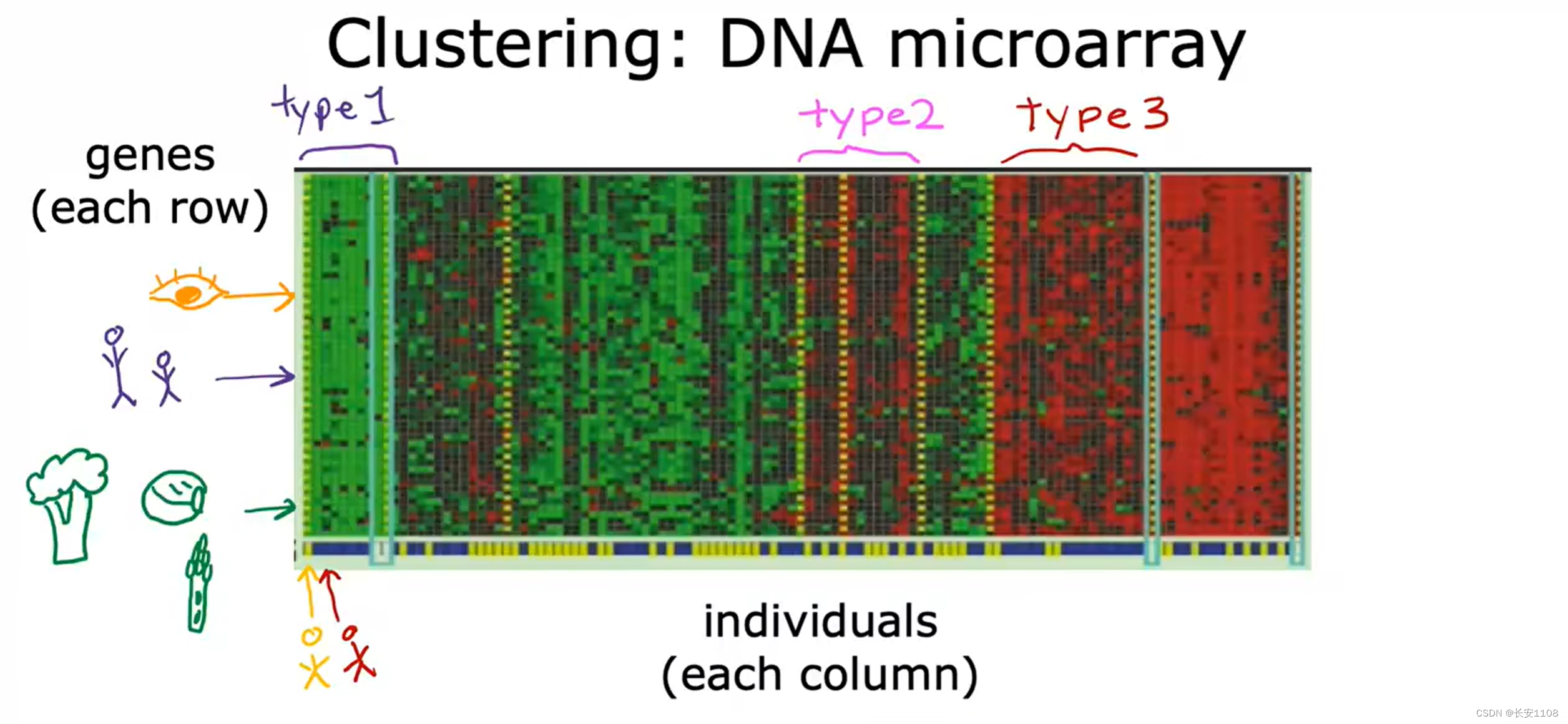
例如DNA矩阵分布图,我们给算法输入大量的案例,之后,算法会自己将这些数据进行分类,根据DNA分出不同类别的人群,这就是聚类式无监督学习,他的答案没有对错,只是进行分类
其他类型的无监督式学习

其他的无监督式学习还有异常检测、降维压缩数据
Jupyter Notebooks
回归模型
线性回归模型
定义

线性回归是回归模型的一种类型,他是指对回归式监督算法的数据继续拟合时,使用直线去拟合数据,而不是其他函数
例子

在回归式监督学习中,使用直线来拟合数据,就是线性回归模型
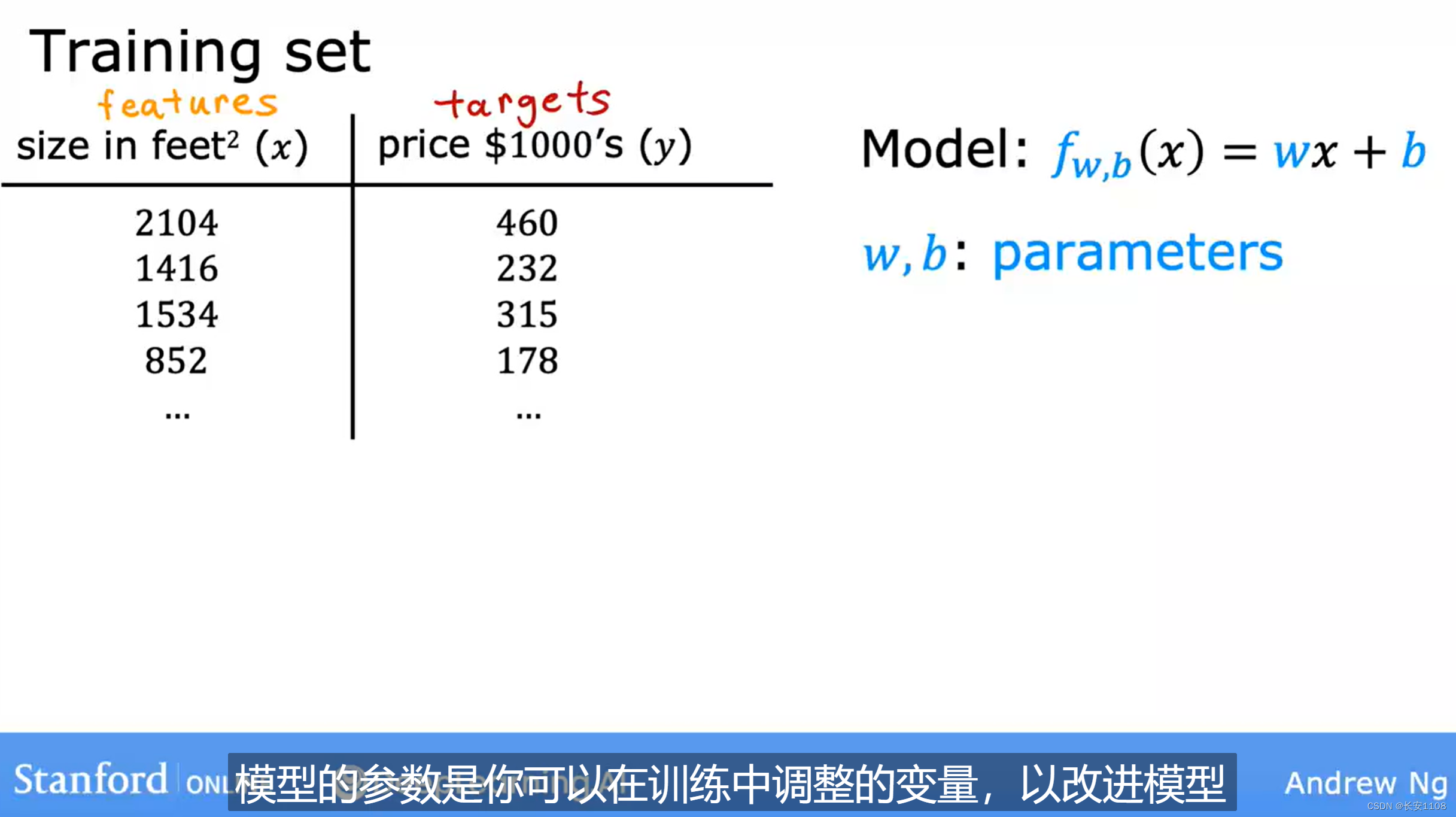
符号

如上图所示,
左边的数据集称为训练集
x通常代表输入变量
y通常代表输出变量
m代表训练案例的数量
(x,y)代表单个训练案例
x,y上面的标号,表示是第几个案例,注意,并不是指数,而是编号
线性回归的术语表达
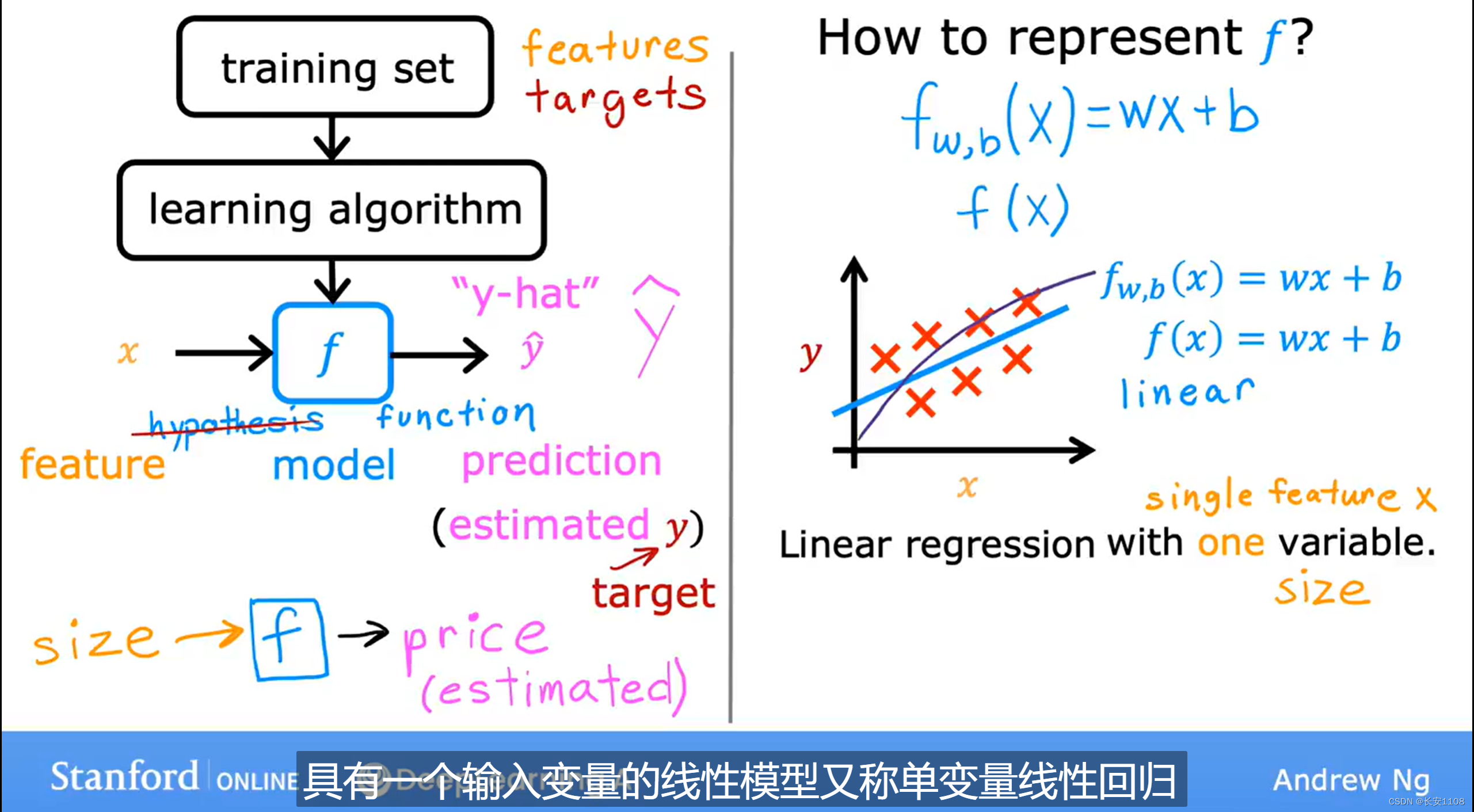
x是输入特征
f是一个函数,或者说是一个模型
y+^是真实值y的预测值
对于线性回归模型的f:
f(x)=wx+b
且对于只有一个输入变量的线性模型,又称单变量线性回归
成本函数
问题产生
我们在确定一个线性方程时,其实就是确定其参数,参数的调整可以改进模型,但是我们调整参数的依据是啥呢,是成本函数
定义
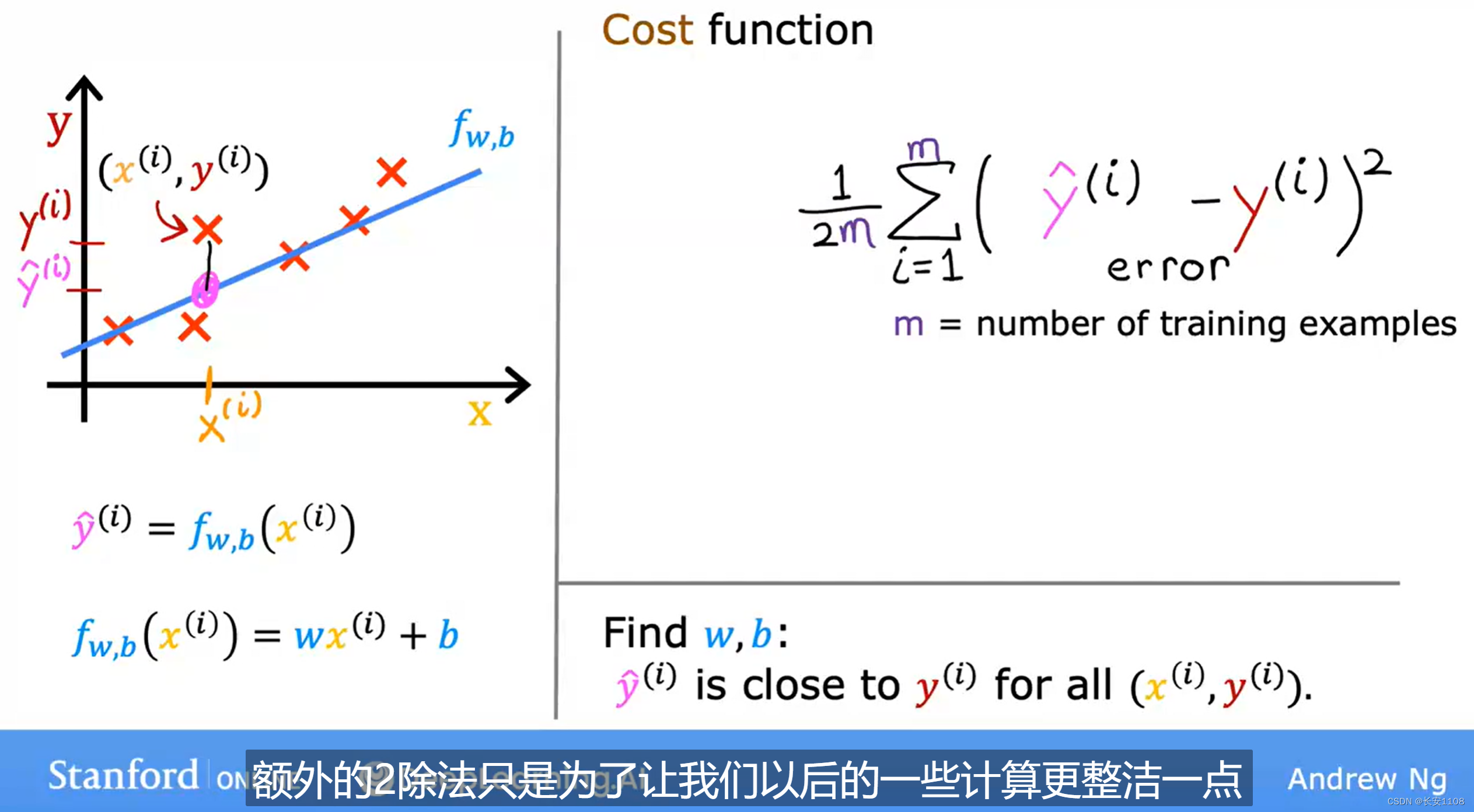
对于一个线性方程,将他放到由训练组成的表中时,肯定会有数据与方程所产出的数据之间,存在误差,而对于这些误差的计算以及数学定义,就是成本函数
具体函数如下:
首先计算每一项的误差,之后平方,然后将每一个误差平方进行求和,最后除以数据量的二倍,这也被称为平方误差成本函数
由于y^是线性方程的结果,所以可以写成如上图所示,这样我们将数据集带入进去之后,就可以调整参数w、b的值了,最终确定一个最佳状态的w、b,该方程可以被标记为J方程
总结

我们的目标是J最小化时的参数w和b
实例1

这里以b=0时为例,方便进行测试
以下是测试的效果: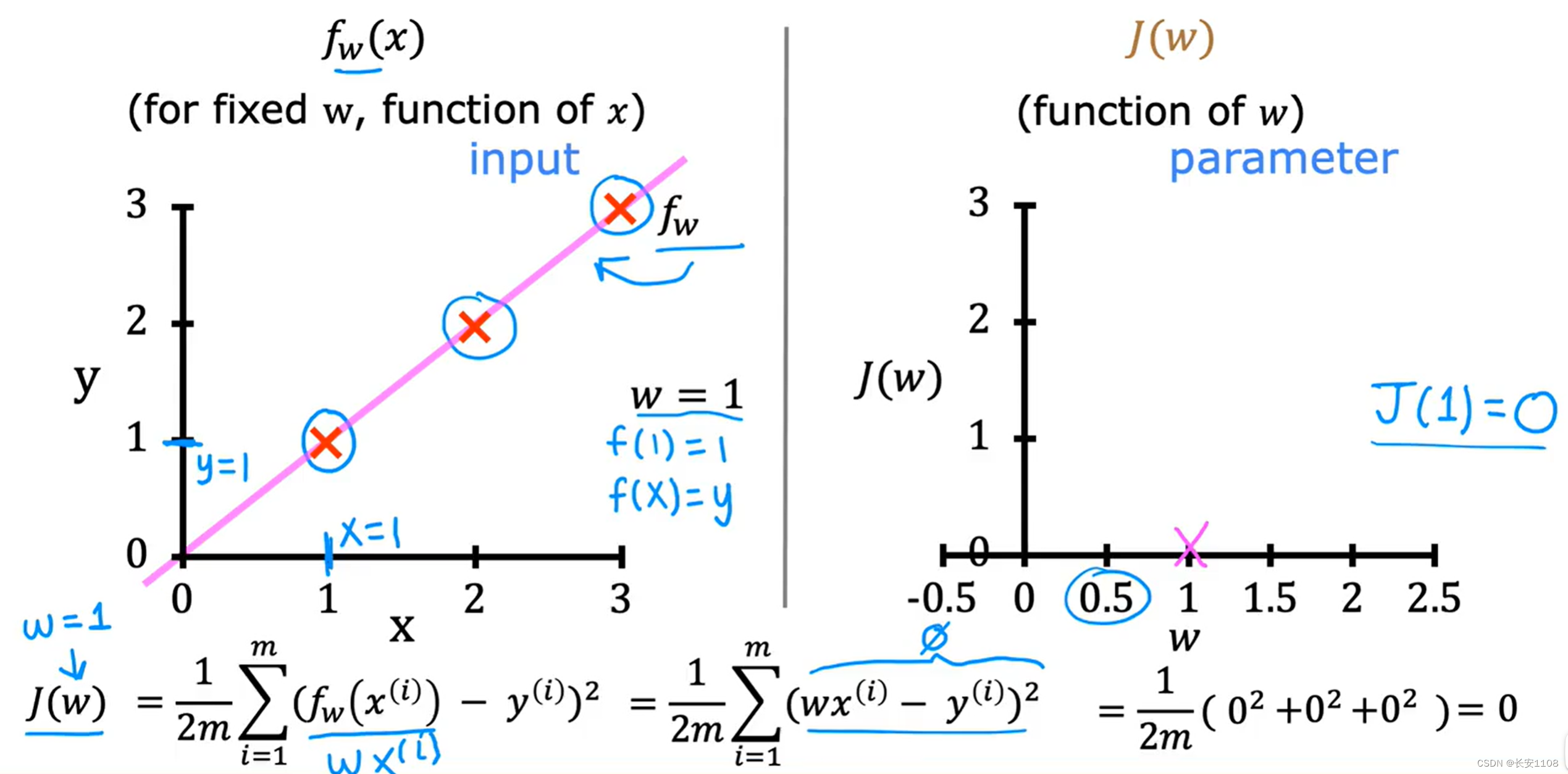
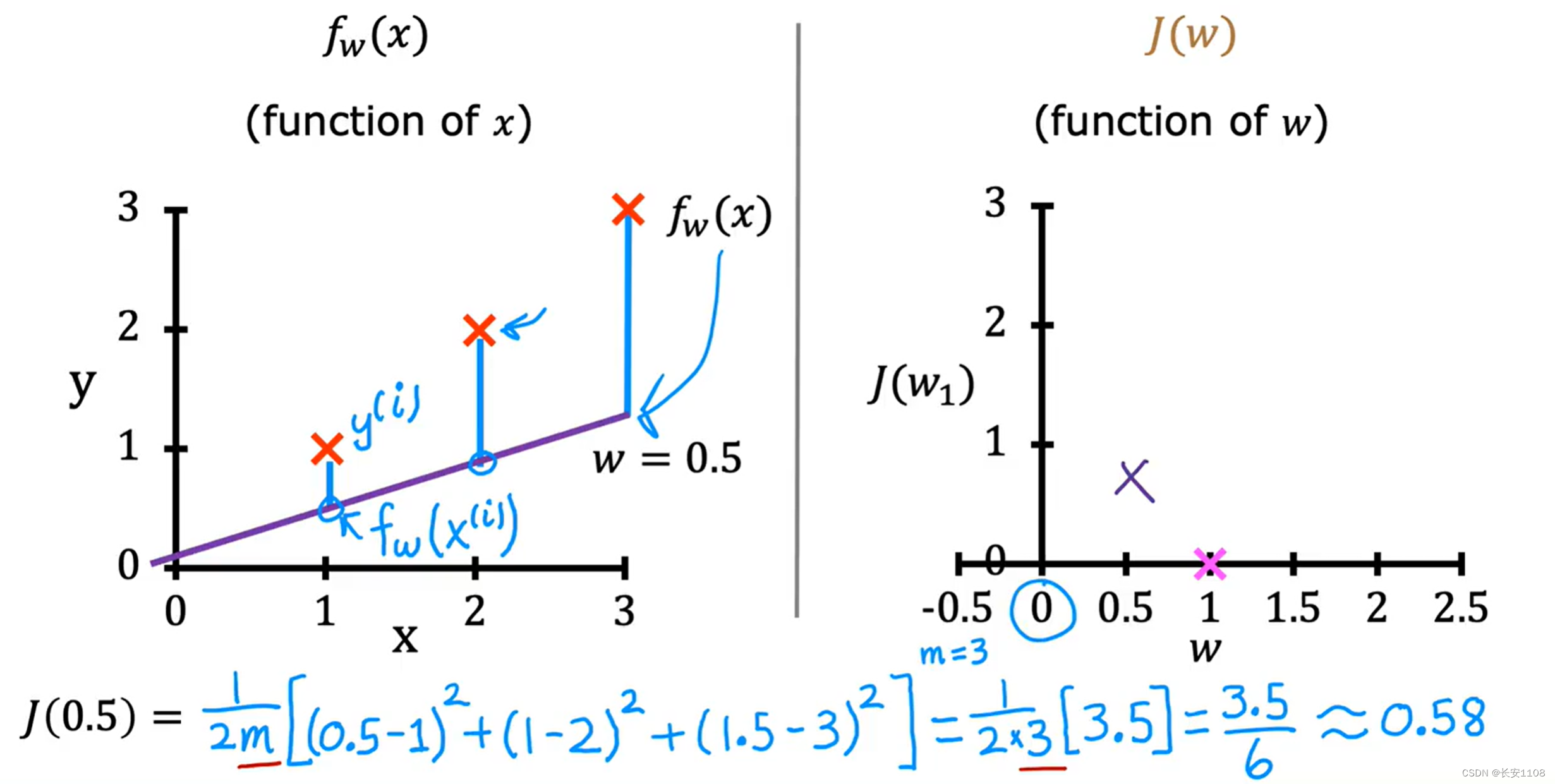
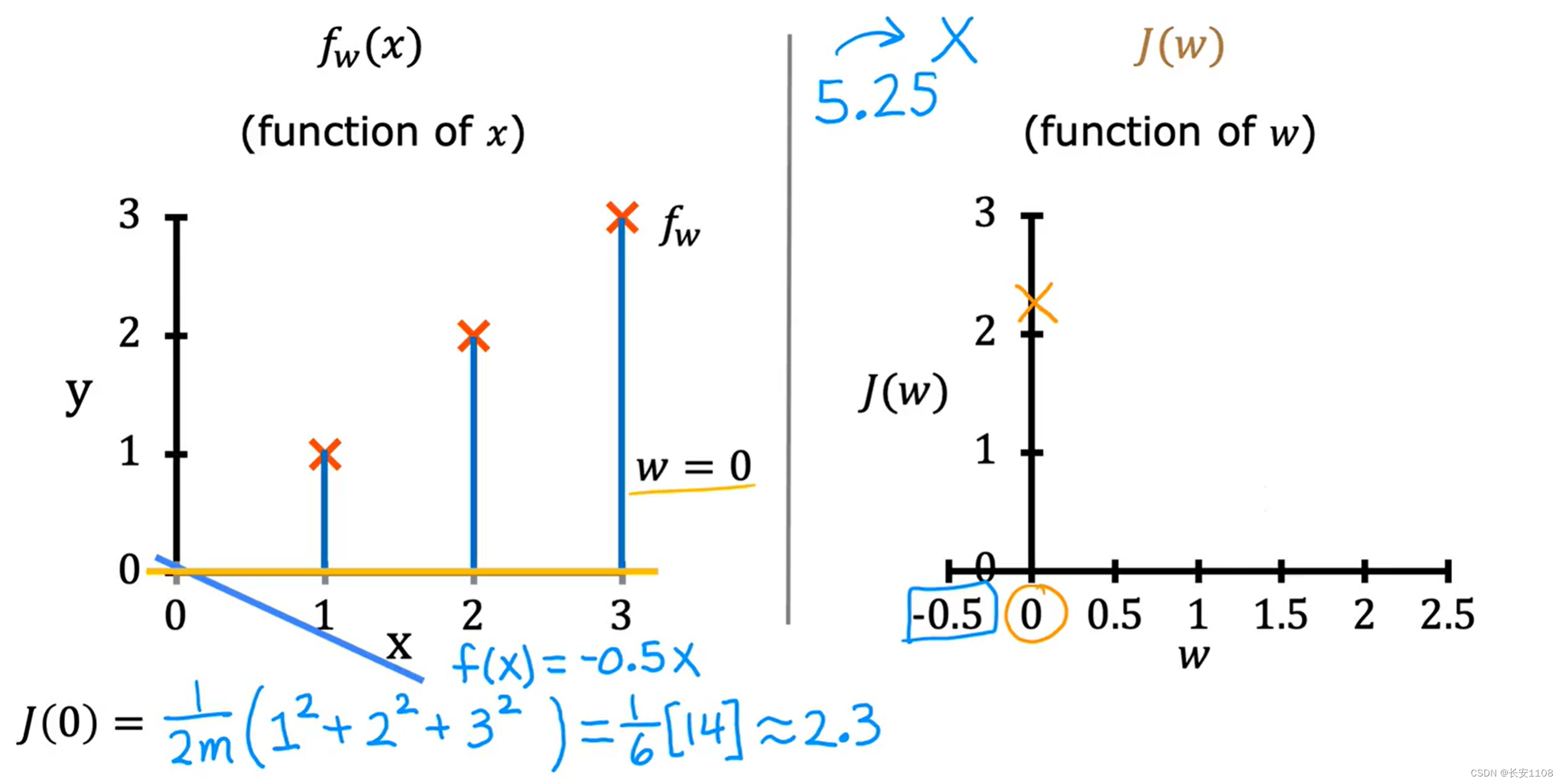
总结
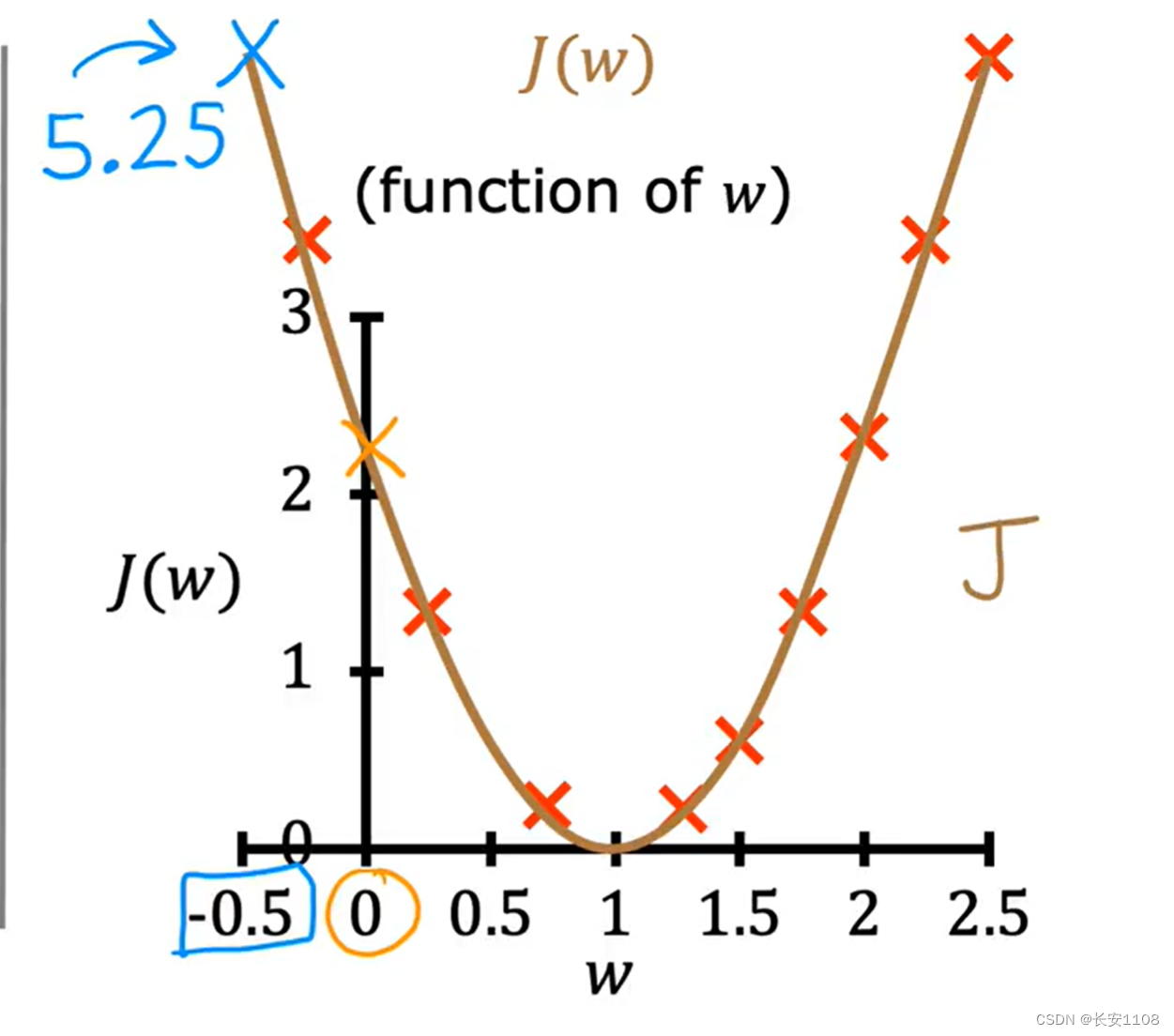
由于成本函数中,误差进行了平方处理,所以,J函数的值一定是一个大于等于0的数,这也方便了我们的选择,我们得到J(W)图像,直接选择最小值即可,因为他的所有数据只能是大于等于0,所以,最小值就是最近接于0的,也是误差最小的
实例2
当成本函数有一般的w、b两个参数的时候:
他的效果如下图所示:·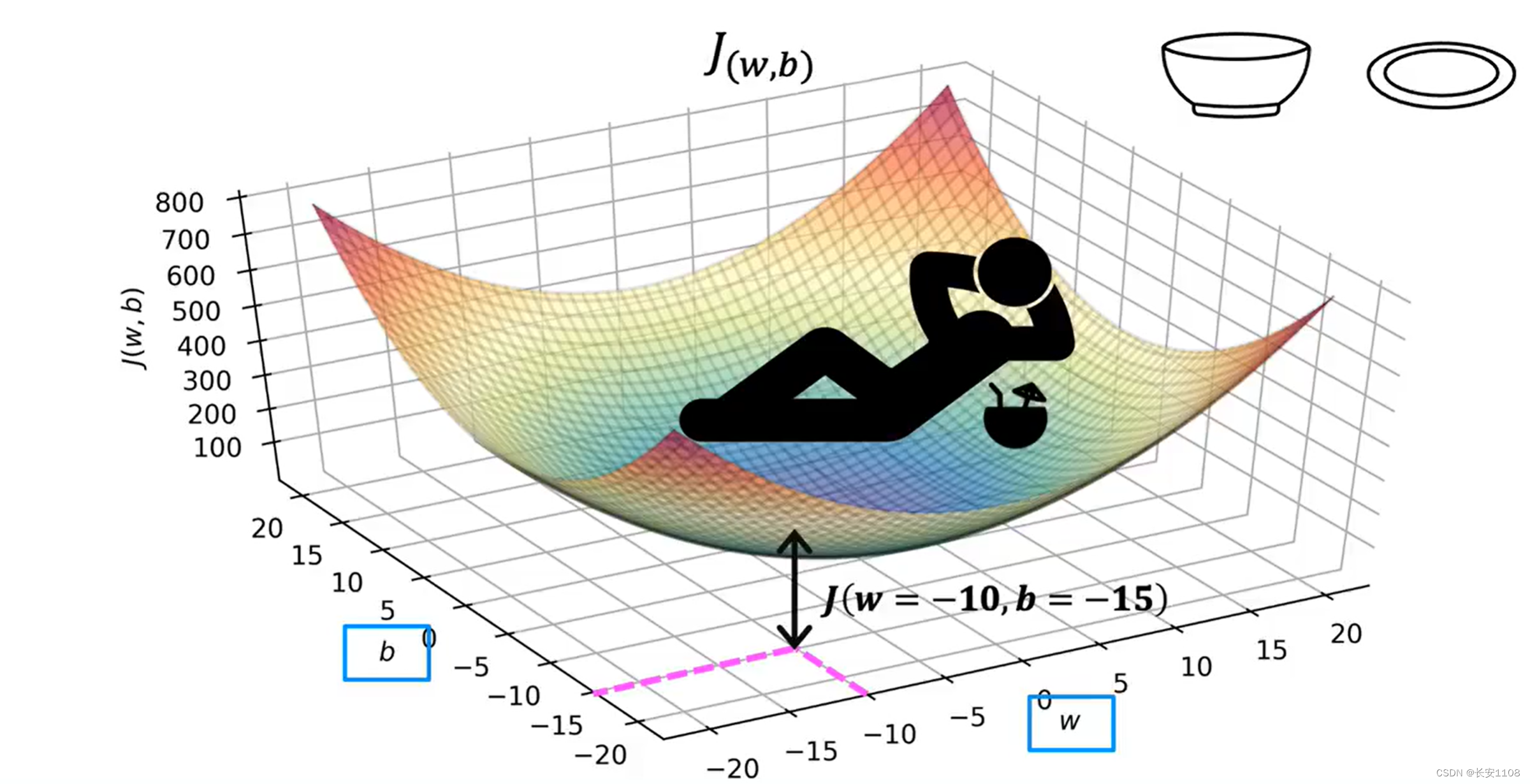
J(w,b),他的效果是一个如上图所示的类似于一个吊床的效果
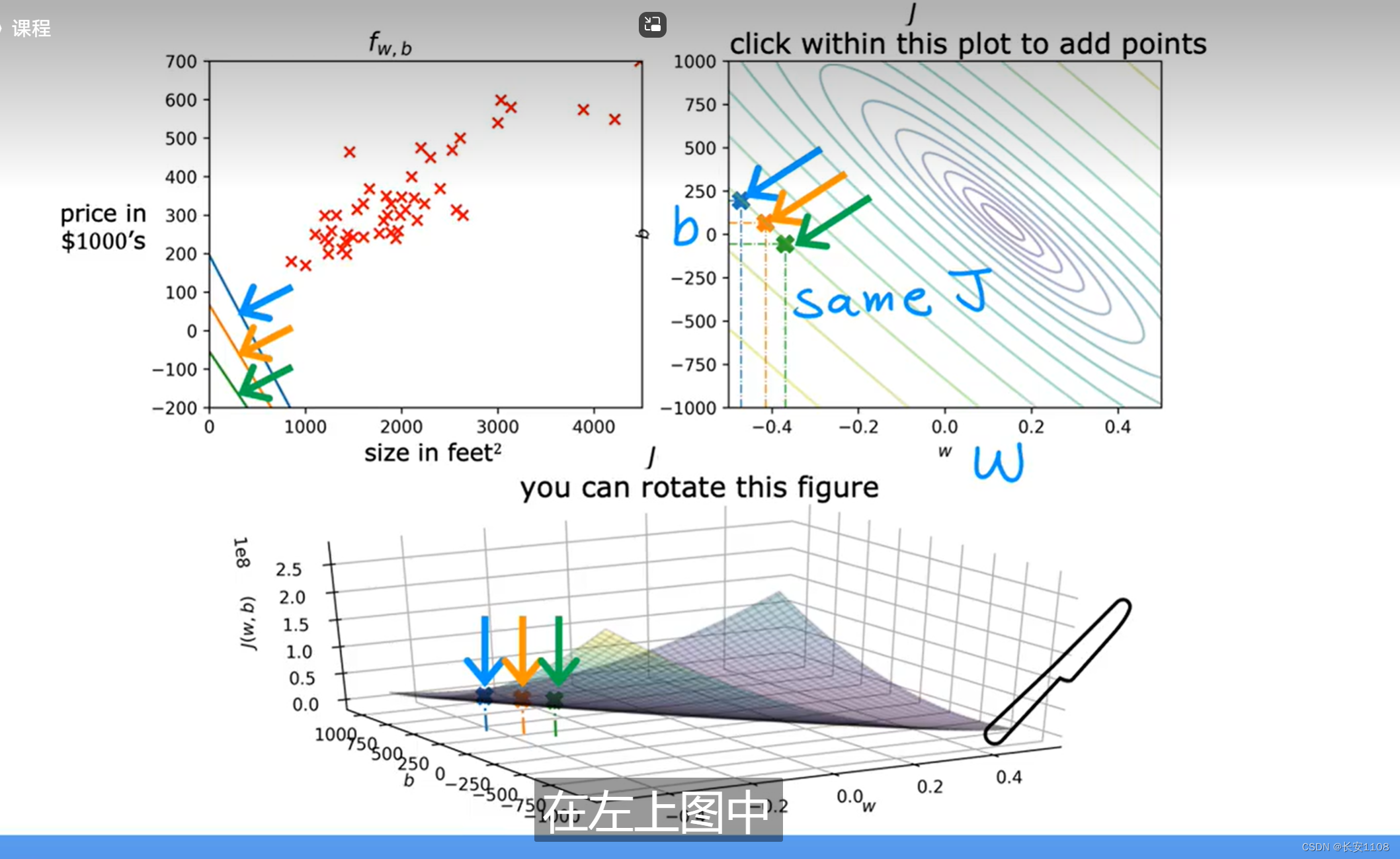
我们可以将其转化到平面,利用等高线(类似于地理上的等高线),来进行平面图的描绘
梯度下降
问题产生
上面我们提到成本函数,那么我们如何系统的找到成本函数中最小值那个点,就要用到梯度下降算法
思想
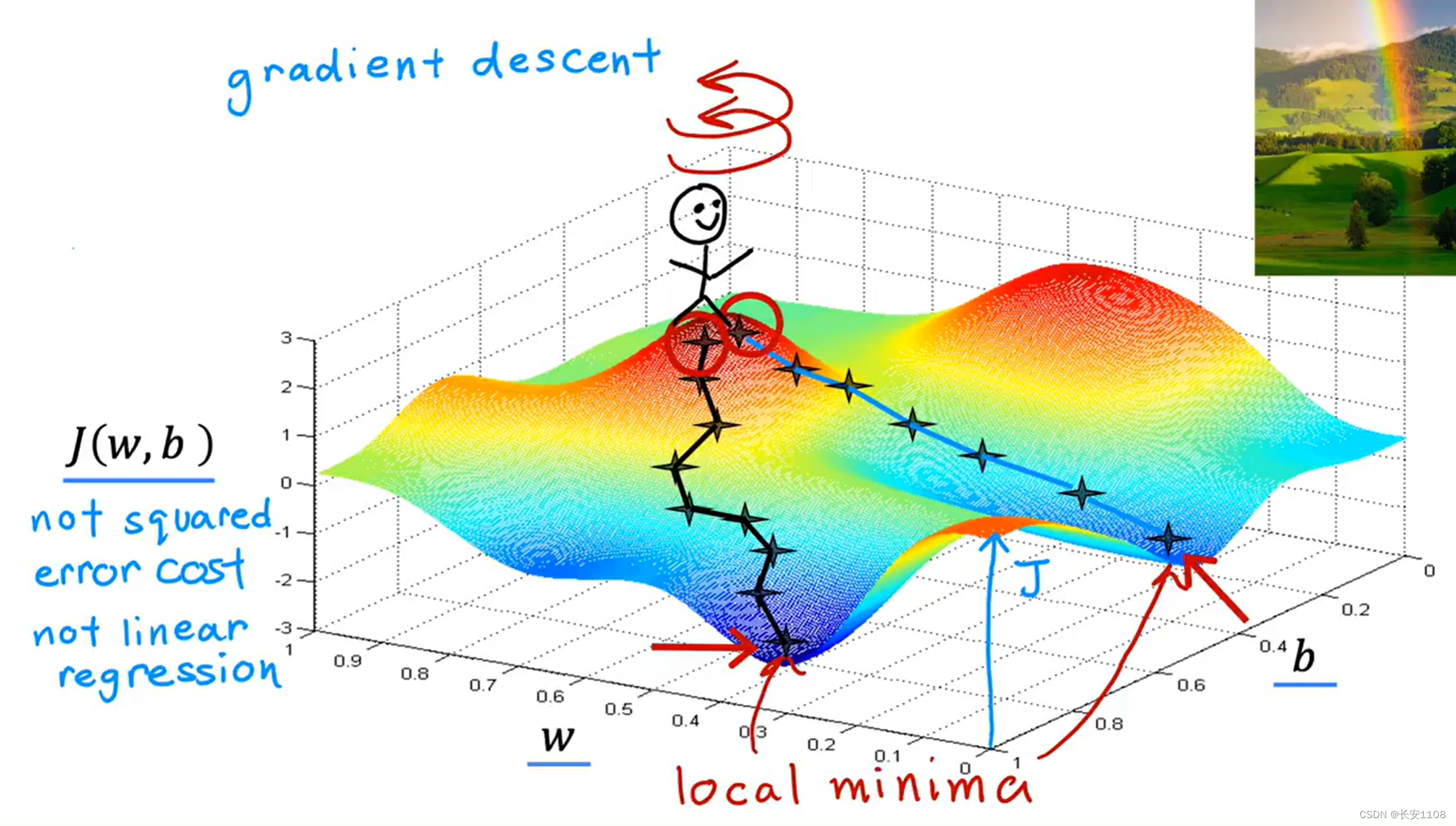
对于一个J(w,b)函数的立体图,(注意不一定是平方误差成本函数,而是具有普遍性的成本函数),我们使用梯度下降,让其降为一个极小值点
首先 我们的起点随机,假设是如上图所示的起点,我们从该起点开始,环顾四周,找到一个坡度最陡的一个方向,向该方向迈出一步,之后基于新的所在点,选择一个坡度最陡的一个方向,迈出一步,重复该过程,我们会发现, 我们到了一个局部最小点
但是如果我们换了一个起点,再次重复这样的过程,可能就到了另一个局部最小点
所以,梯度下降只是到达一个局部最小点,或者说极小点(如果成本函数只有一个极小值点,那么最后梯度下降一定会下降到全局最小值,线性回归方程的成本函数就是只有一个极小值点,但是我们这里以普遍性较强的多个极小值点的成本函数作为研究对象)
实现

我们需要不断的对w和b进行更新,因为每次位置的改变,都意味着w和b的变化
而w和b的更新公式如上图所示,α代表学习率,代表一次下降所迈出的步幅,通常α的值在0到1之间,α之后跟着一个导数,
w的公式对w求导,b的公式对b求导
不断的更新w和b,直到达到一个极小值,在该点,w和b不再随着你采取的每一个额外的步骤改变很多,或者说函数收敛
注意点
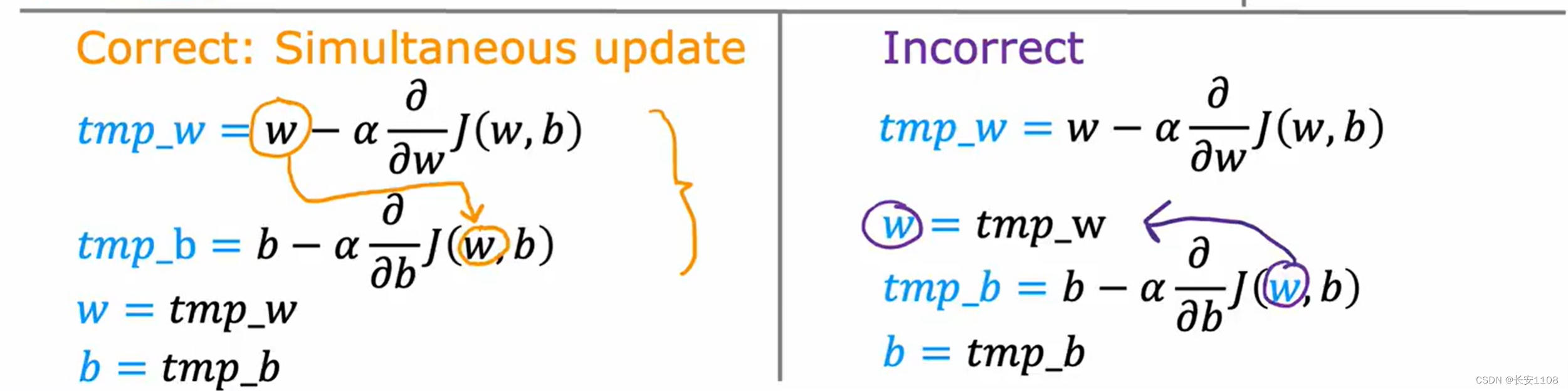
注意 在算法代码实现时,不要直接将更新好的值赋值给w,这样的效果就跟上图右边的代码一样,这样的话,会导致接下来b参数的更新出现逻辑错误
所以,我们在更新时,先将其结果存在两个临时变量中,之后待计算结束,再统一放入w和b变量中
关于梯度下降参数更新公式的导数项
我们举两个例子,来证明梯度下降的导数项是有意义的:(如下)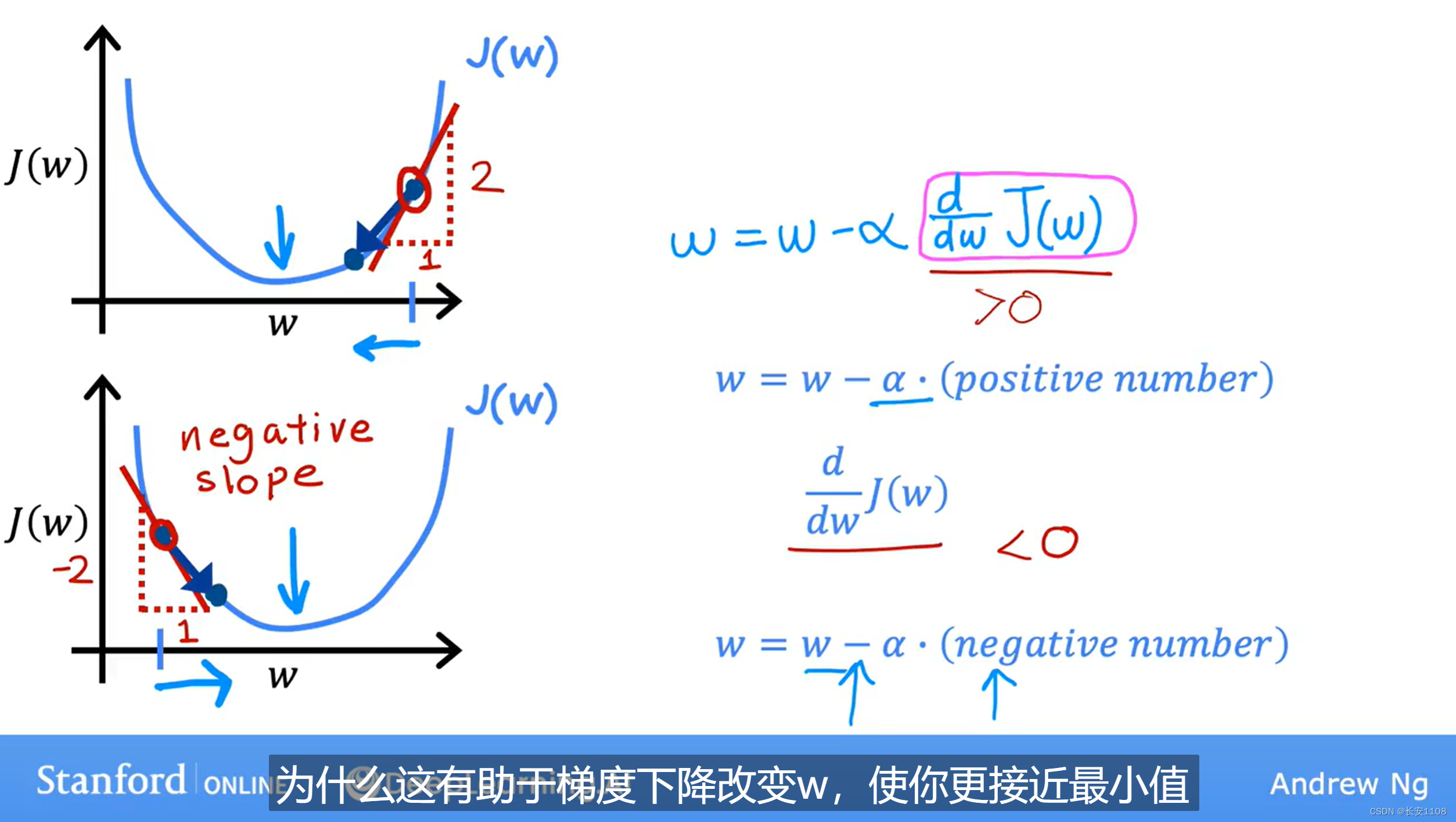
以之前b=0时的J(w)为例,此时J(w)的图像如上图所示
当我们的起点在w最小值的右边时,这时,导数项就是该点与曲线的切线斜率,且斜率为正值,而α也是正值,所以,w-一个正数,更新后的w是变小的,所以是向中间移动,合理
当我们的起点在w最小值的左边时,这时,导数项就是该点与曲线的切线斜率,斜率为负值,而α是正值,所以w-一个负数,即w+一个正数,更新后的w是变大的,所以是向中间移动,仍然合理
!!注意:w是横轴,所以每次移动,注意力放在横轴方向上进行移动
关于梯度下降参数更新公式的学习率
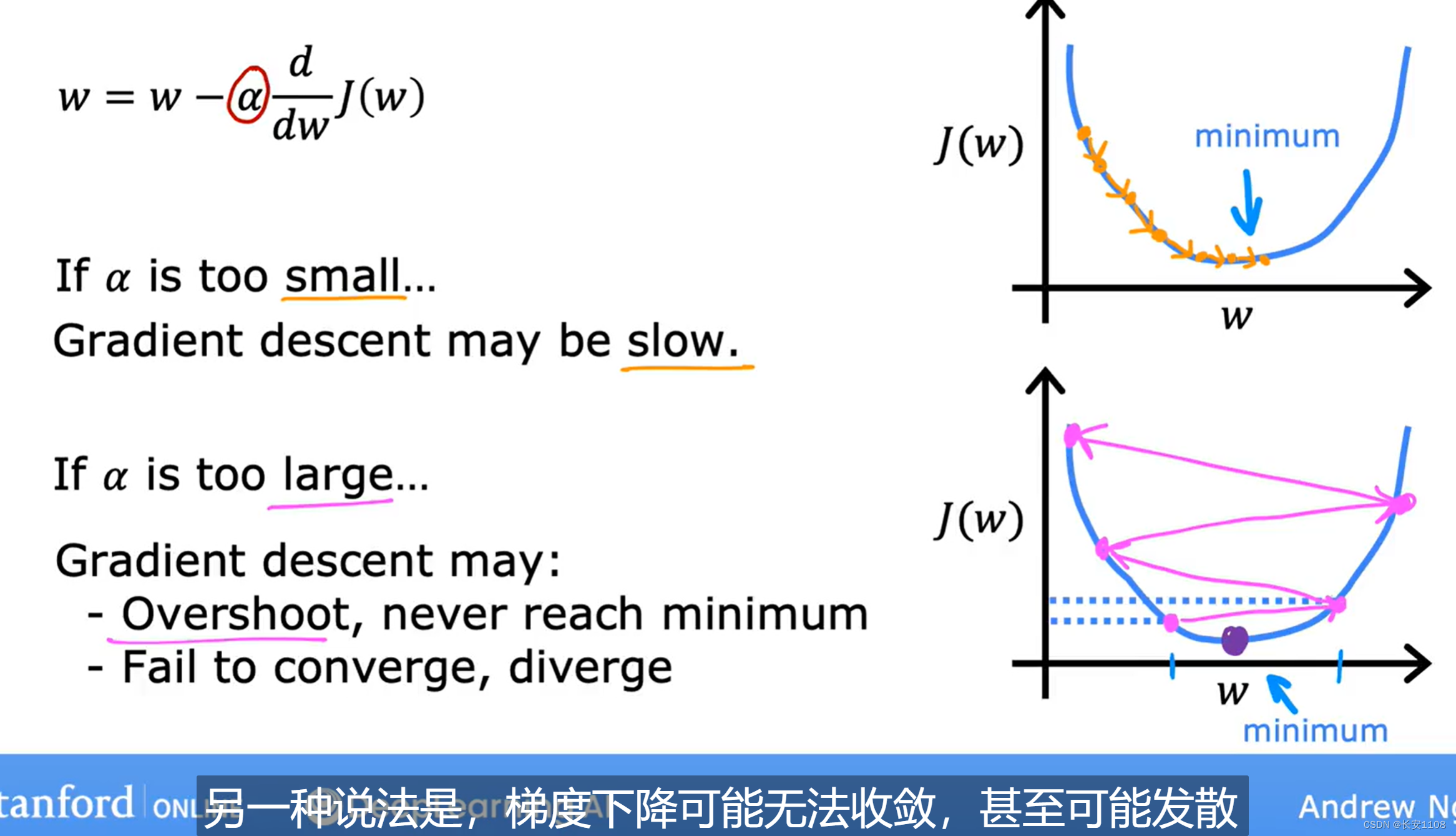
如果学习率太小,那么每次移动的方向是正确的,但是移动的速度会极为缓慢
如果学习率太大,那么每次移动,可能会超调,跨越的w太大,这样的话,可能会导致离min(w)越来越远,最终也无法到达成本函数的最小值
关于如何判断当前已经到达了极值点
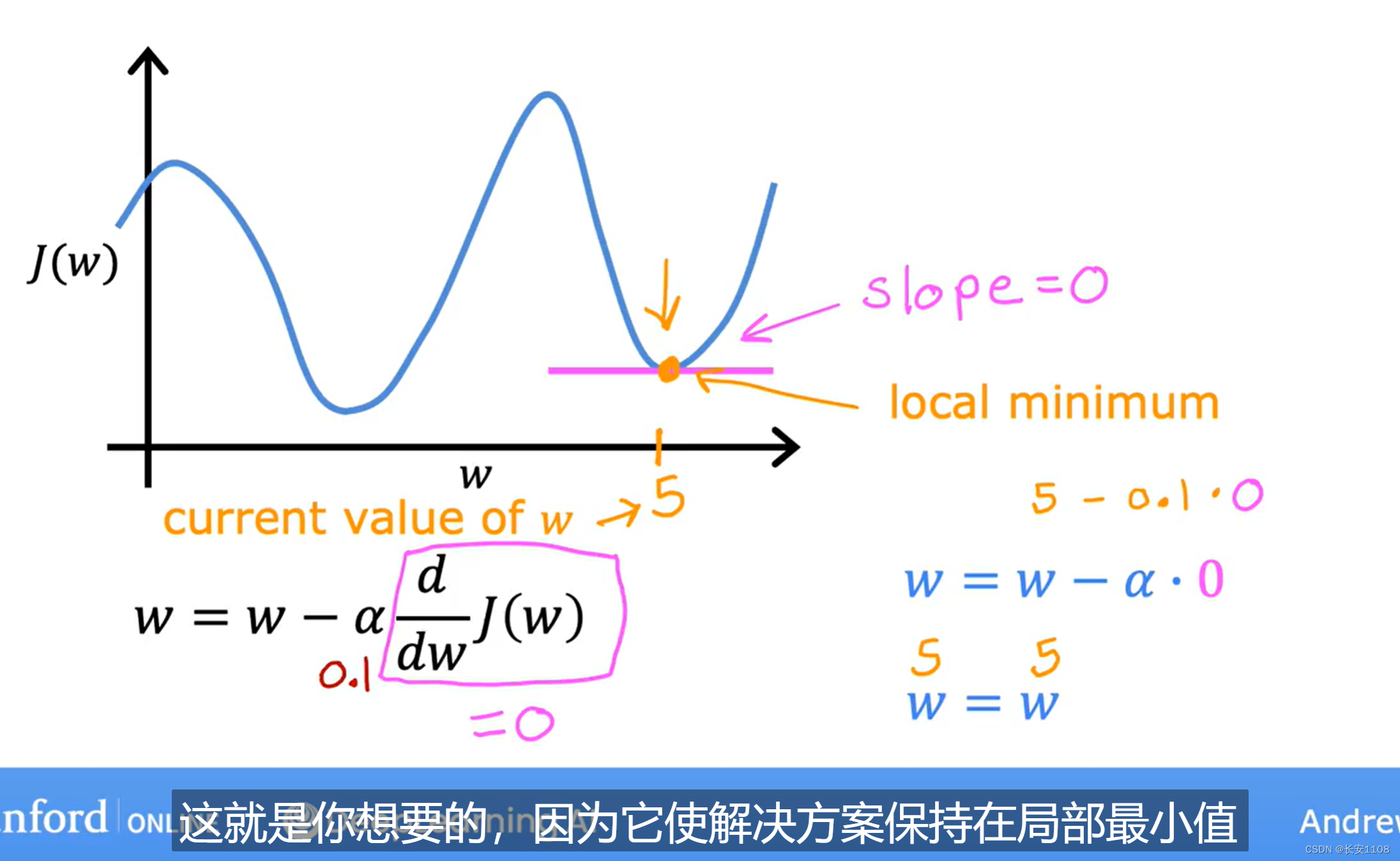
当我们到达了极值点时,我们的导数项为0,所以,可以判断是否导数项为0,或者可以判断是否参数没有发生任何的改变,这两个特征都是当前已经到达极值点的表现
这也表现出一个性质:随着梯度下降的进行,每次移动的距离会越来越小(如下图)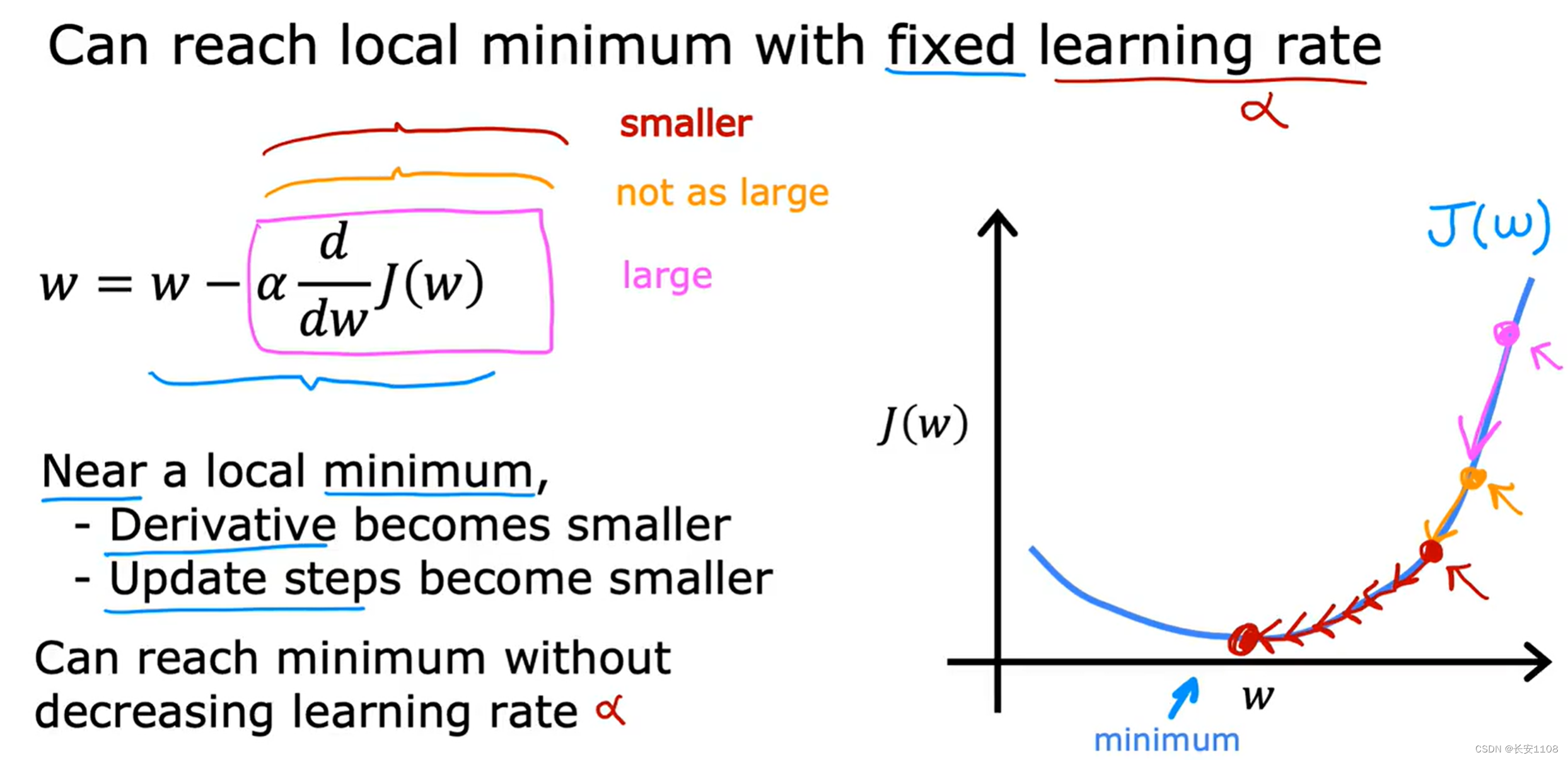
因为导数项会变的越来越小,而α不变,所以,整个移动项会越来越小
线性回归中的梯度下降
用到的函数
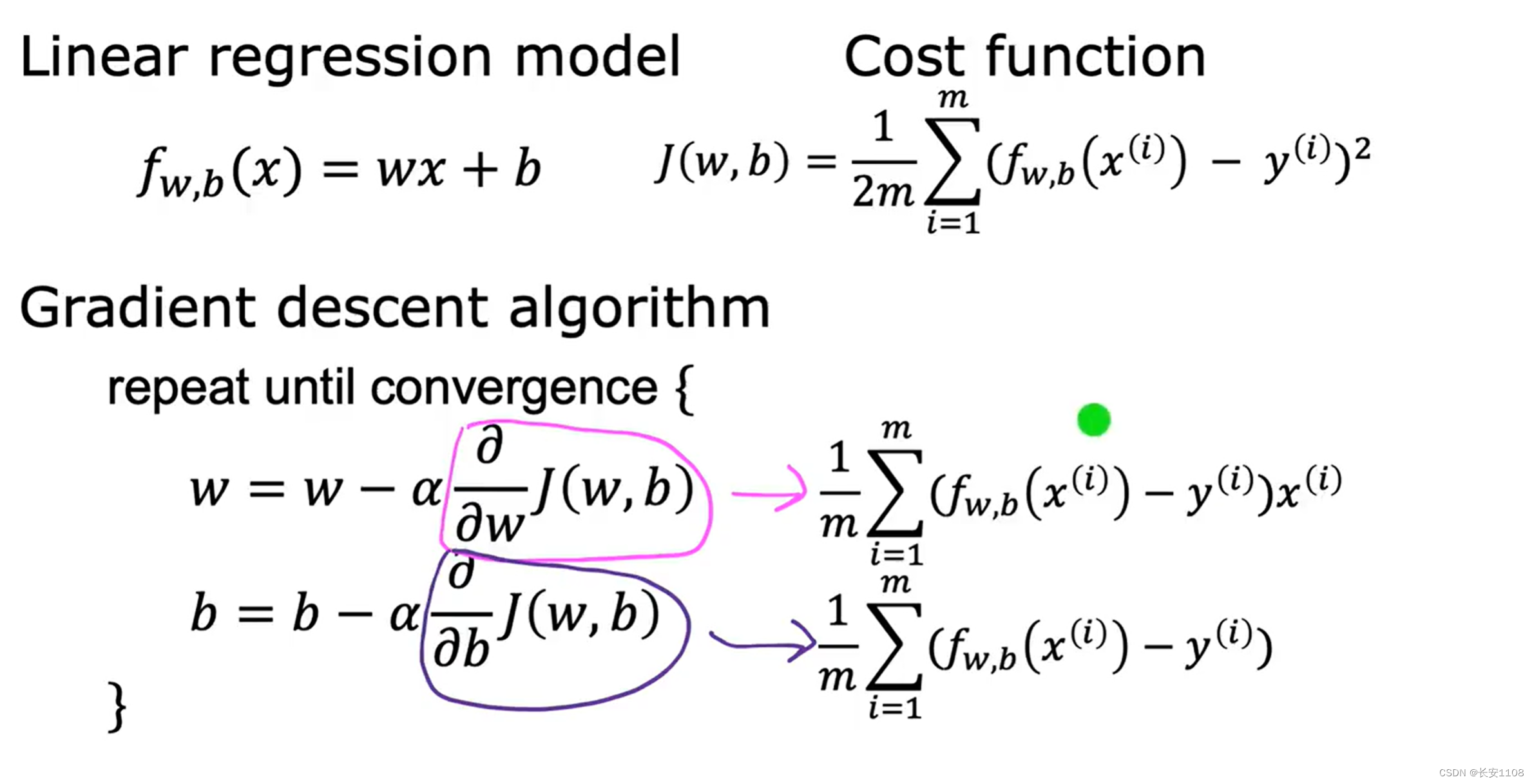
上图给出了线性回归方程、平方误差成本函数、以及梯度下降算法中导数项的公式
实现

要注意,w和b先用临时变量存储起来,最后再统一更新
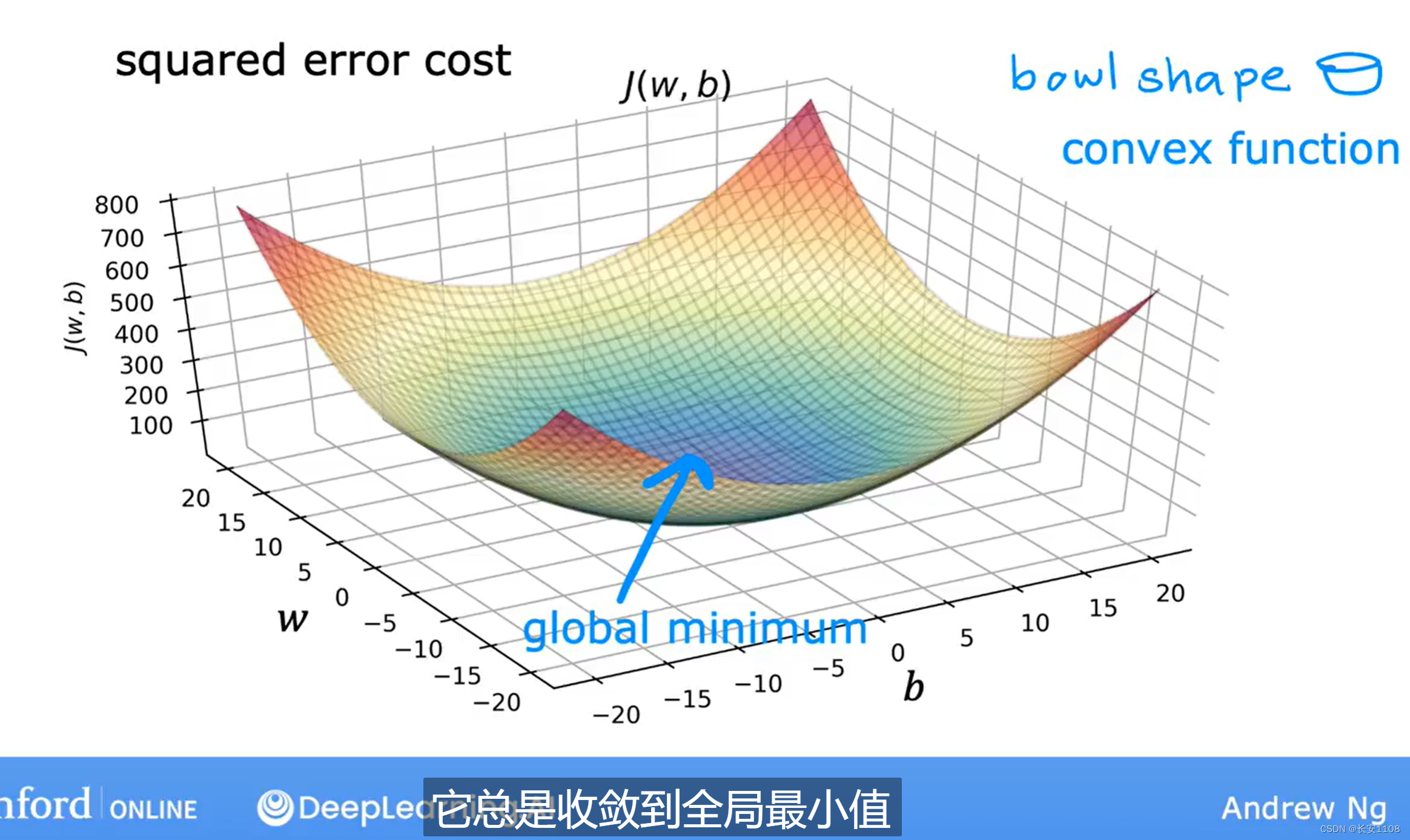
当我们对一个成本函数只有一个极小值点的成本函数进行梯度下降时,只要α选择恰当,它总是收敛到全局最小值
多种特征
简介
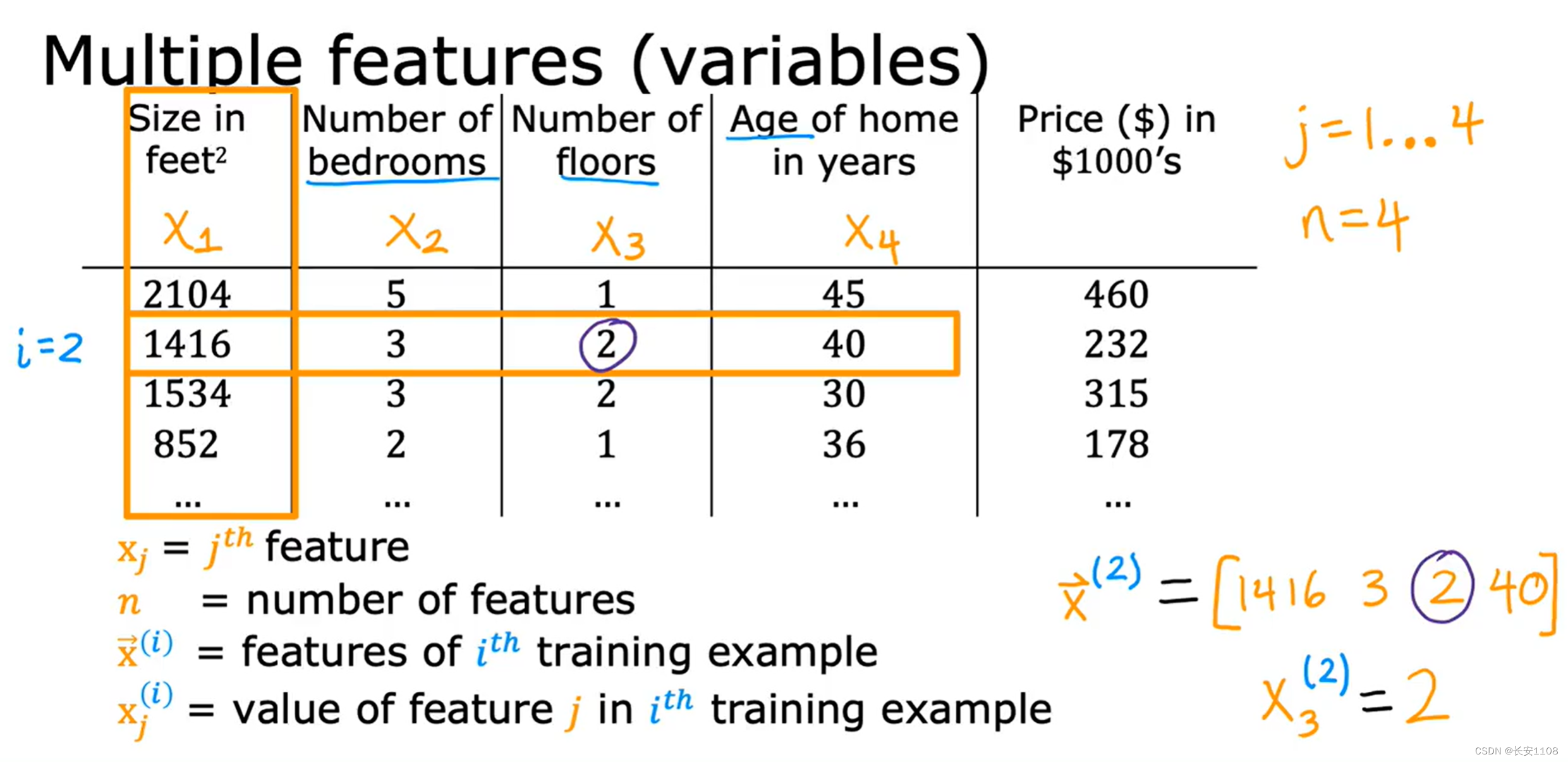
当我们的训练集有多种特征时,我们用新的符号来表示他们,
那么用x+下标,对每种不同种类的特征进行符号化
n代表特征的数量
x+箭头,表示向量x,而其加上 上角标,表示第几行的行向量,表示那一行的数据集合
x+箭头+上角标+下角标,表示在那个向量里的第几个数据,一般将箭头省去
多特征模型的例子
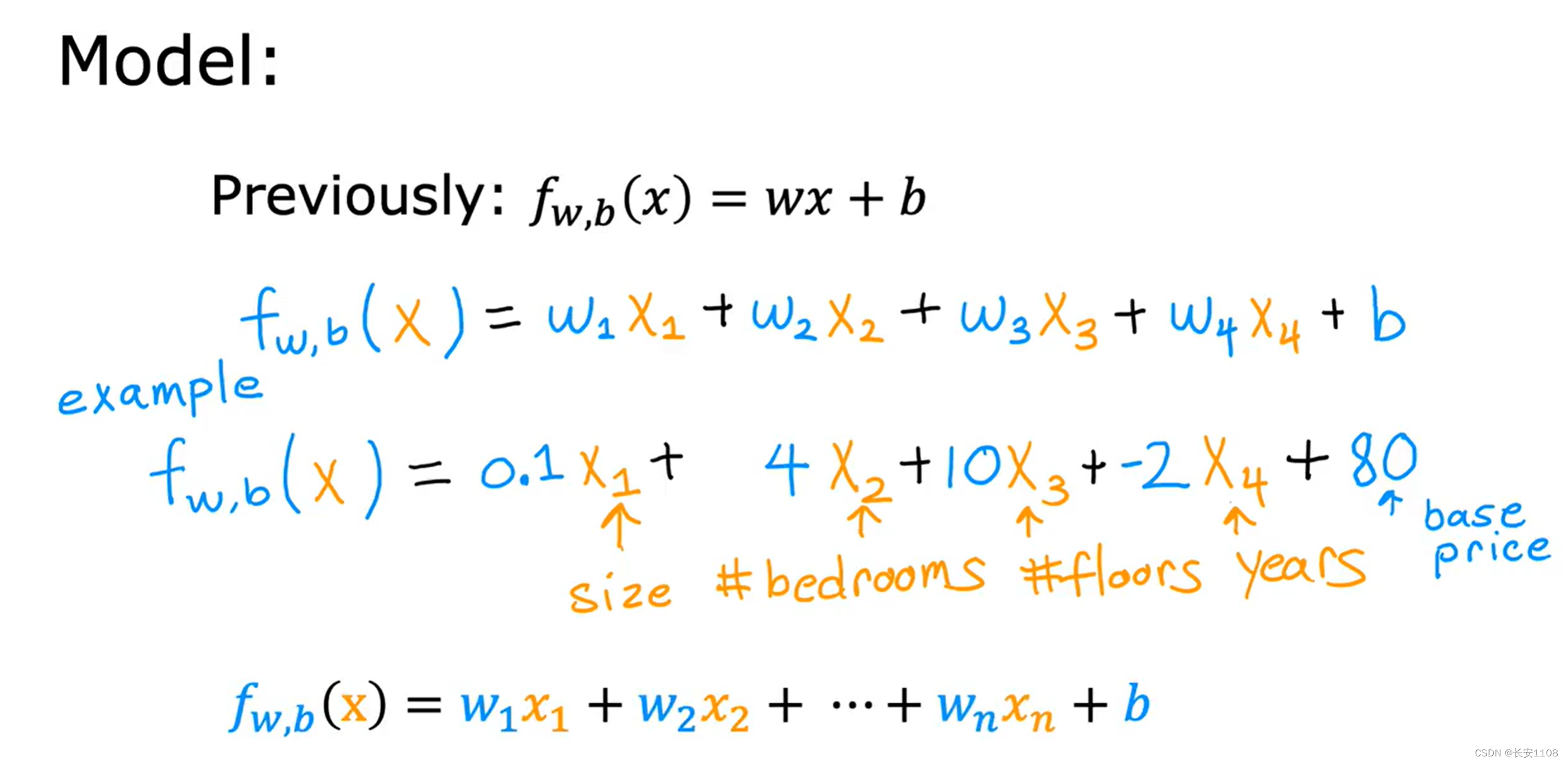

既然每个除b以外的参数都可以用向量集合起来,且未知数x也可以用向量表示,那么整个公式可以进行简化表示,即直接用向量来表示公式,如上图,注意此时向量之间的乘积用点乘,点乘乘开就是向量中的数据对应相乘即可,这样的model称为多元线性回归
向量化(多元线性回归的代码表示)
实现

首先,我们使用NumPy库函数对向量进行定义以及输入,实际上向量在代码中表示为集合,输入时要将所有数据用中括号+逗号 包装
b是额外的参数,
之后,我们对比使用传统方式进行多远线性回归公式的表示,以及使用NumPy库函数的API ,发现NumPy的API在代码优雅度以及效率上都要高于传统模式,即使用np(实例化对象).dot(w,x)+b,就可以将多元线性回归的公式进行代码表达
简单原理
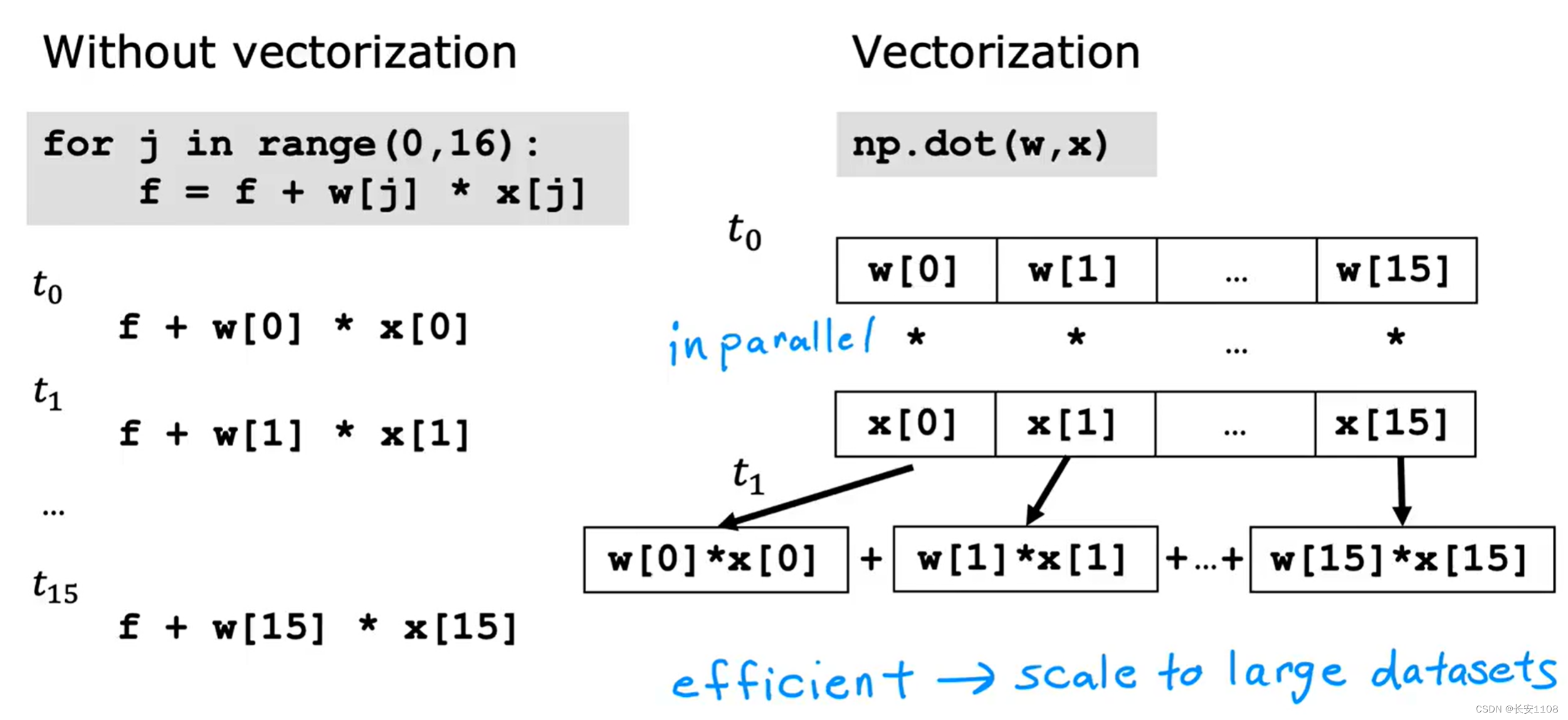
使用矢量化,他是将两个向量中的元素同时进行运算的,而不是像传统的for循环那样,线性的一个一个计算,所以他的效率会快很多
多元线性回归的梯度下降法
公式分析

从上到下依次是参数、回归模型函数、成本函数、梯度下降的参数更新函数,与前面一元模型不同的是,参数有一个变成了向量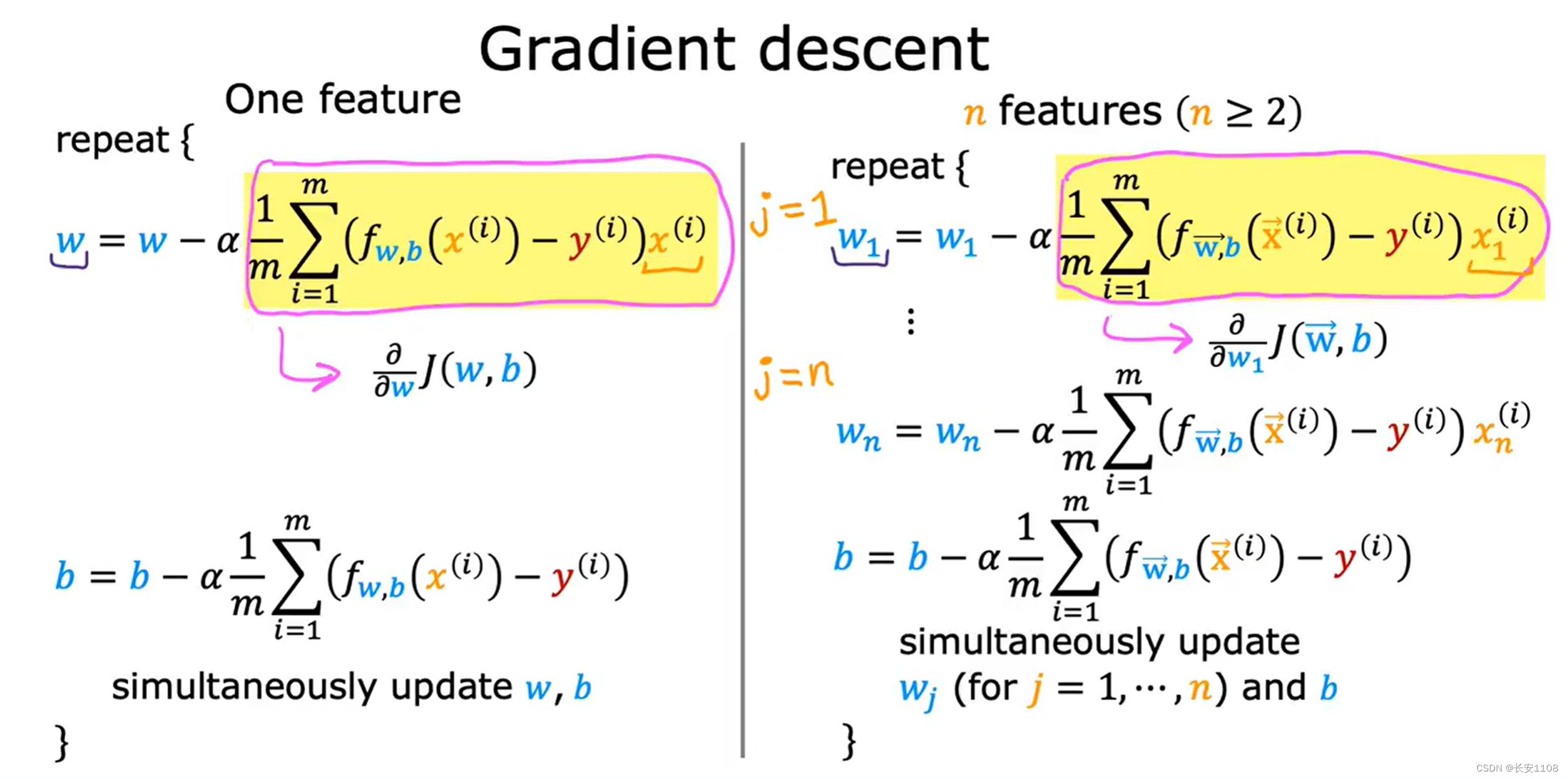
之后,因为w和x都是向量(或者说是集合),我们做导数项的时候,不能直接对整个集合进行求偏导,所以,只能w1、x1,w2、x2这样依次求下去,最后加上b的参数更新,这样就完成了一次梯度下降
法方程法

这种方法就是借助了NumPy库,但是他有明显的局限性,
这种算法求多元梯度下降,只能用于线性回归,且不能进行推广到其他算法,并且运行速度较慢,他的具体实现在网页可选实验室内
特征缩放
问题产生
实例


由上面的例子可以看出,当一个特征点的数据范围特别大时,该特征所对应的参数w就会相应的变的很小,不然该项的值会很大,这样其他特征点就不起作用了,
而当一个特征点的数据范围特别小时,该特征所对应的参数w就会相应变得很大,不然该项的值会很小,该项就会不起作用
总结
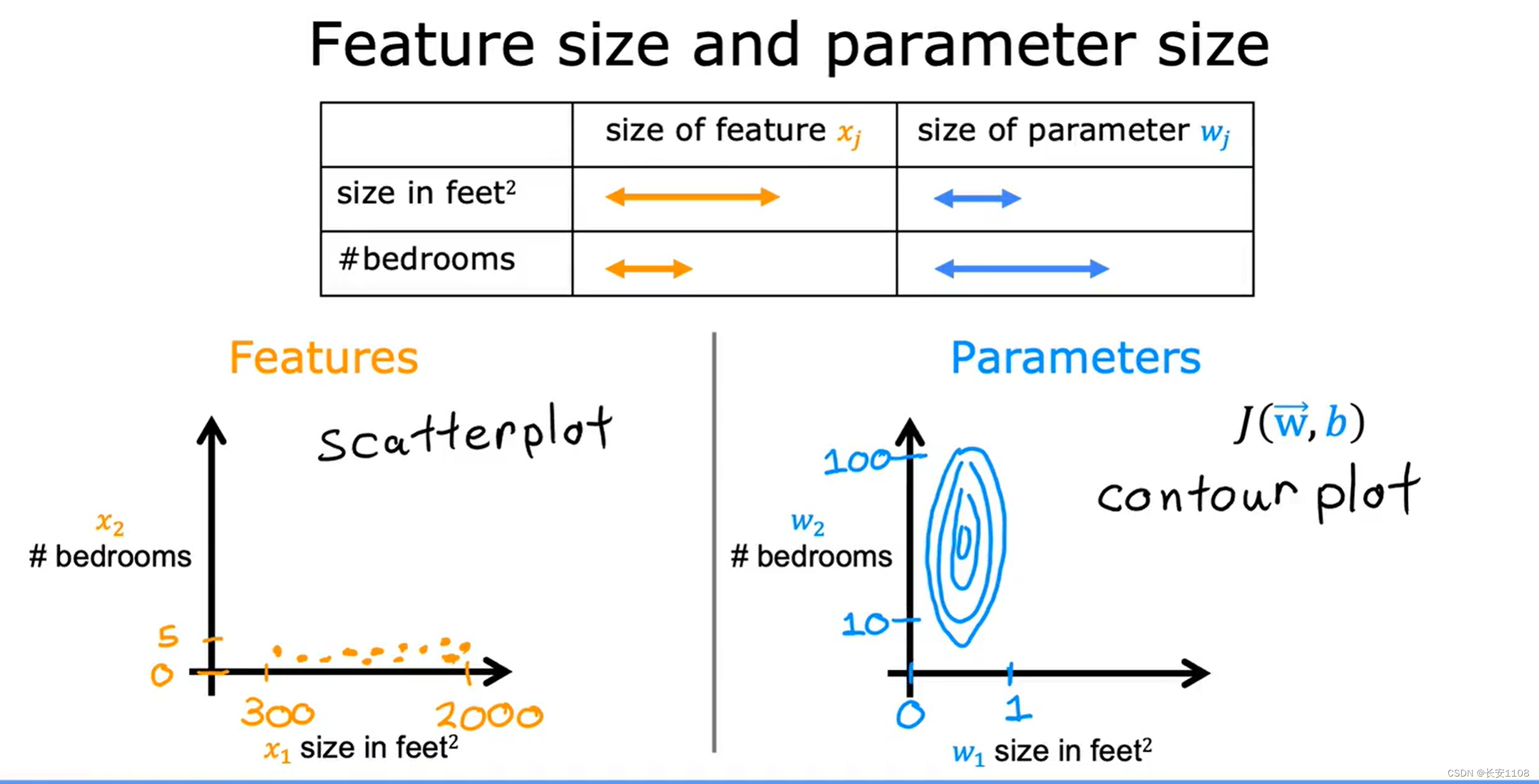
可以看出,参数的范围由我们的各个特征的数据范围决定,假如我们的各个特征的数据范围相差很大,那么我们的各个参数w也会相差很大,那么在成本函数图上,他就是一个椭圆,而对于一个椭圆形的成本函数,他在进行梯度下降时,极容易产生超调,进而离极小值越来越远,所以,我们要注意并解决这一问题
问题解决
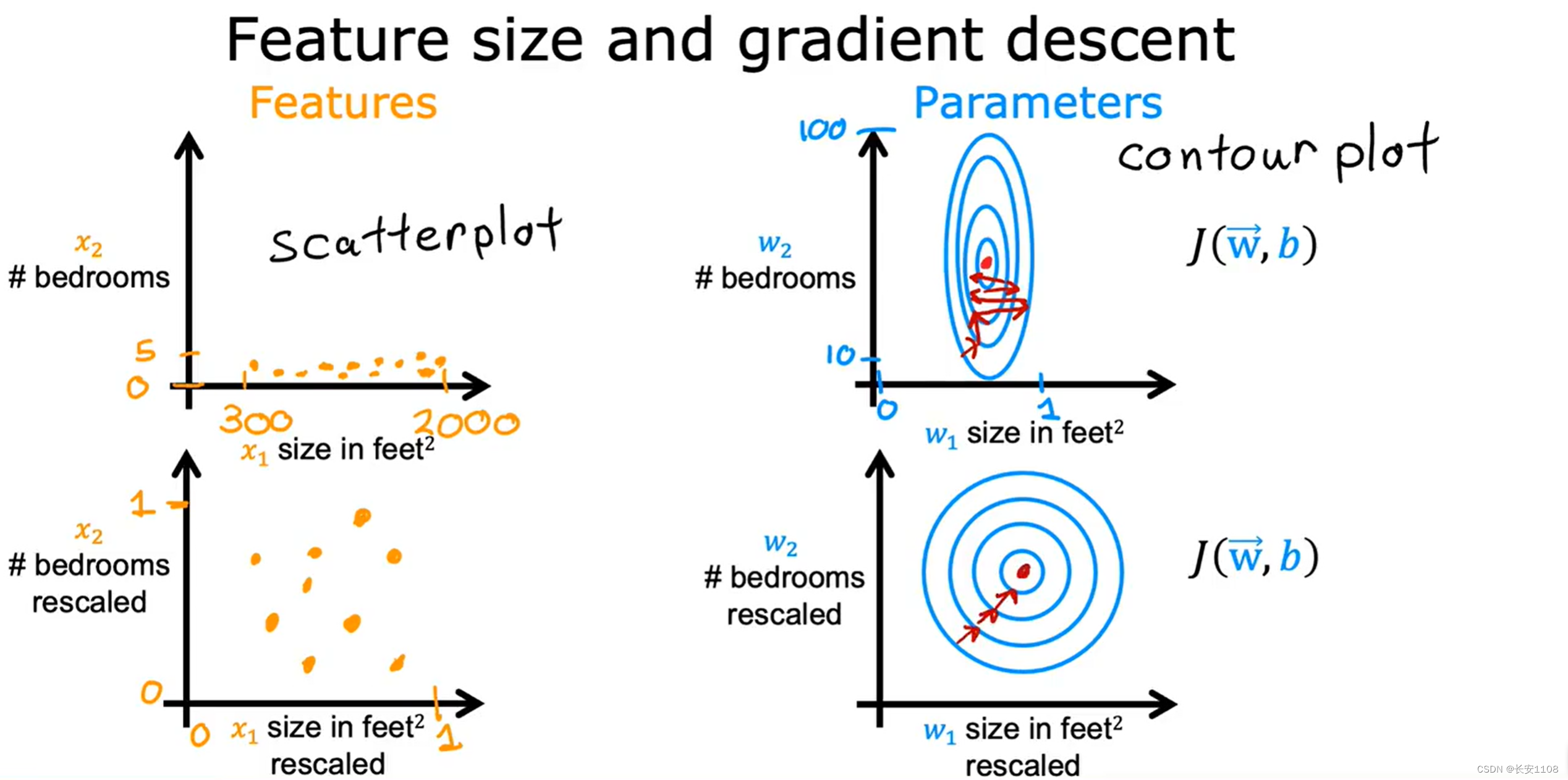
由于该问题是因为我们的不同特征点的数据范围相差很大引起的,所以,我们在选取数据进行训练时,要对各个特征点的数据进行优化,使其各个特征点的数据范围要相近,那么对应的各个特征点的参数范围也相近,这样,对应的成本函数就会是一个圆或者较为饱和的椭圆,这样就在进行梯度不容易引起超调
优化训练数据的几种方法
除去最值法
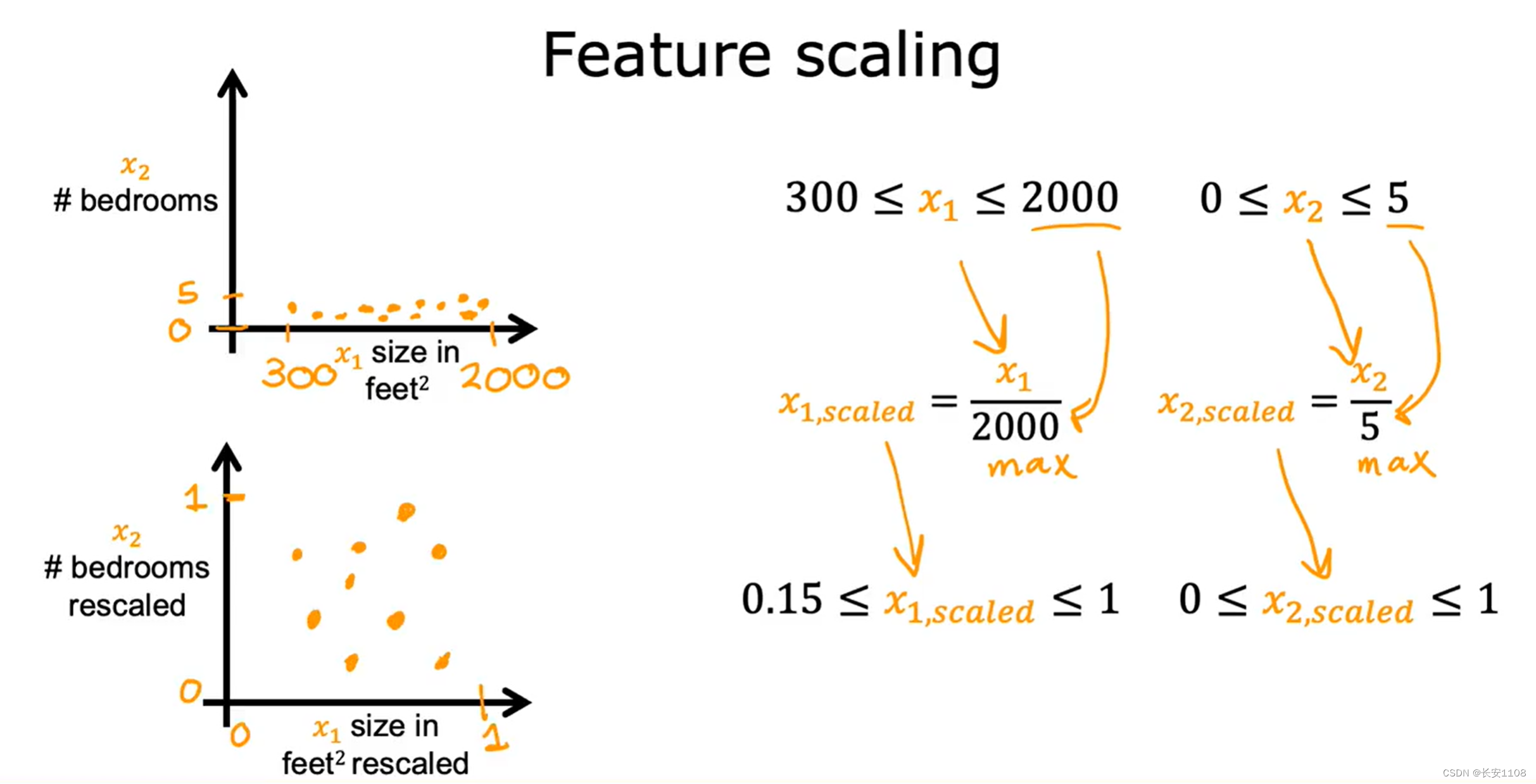
将所有特征点的数据,除以该特征点的最大值,得到的数据就都是从0到1的数据了
平均归一化

首先求出来各个特征点数据的平均值,之后,将所有的数据依次 - μ /(max-min),这样,所有特征点的数据都会化归为-1~+1
总结

总之,特征相差不大时,是允许的,相差很大时,就要进行缩放,来提高安全性和效率
检查梯度下降是否收敛
学习曲线
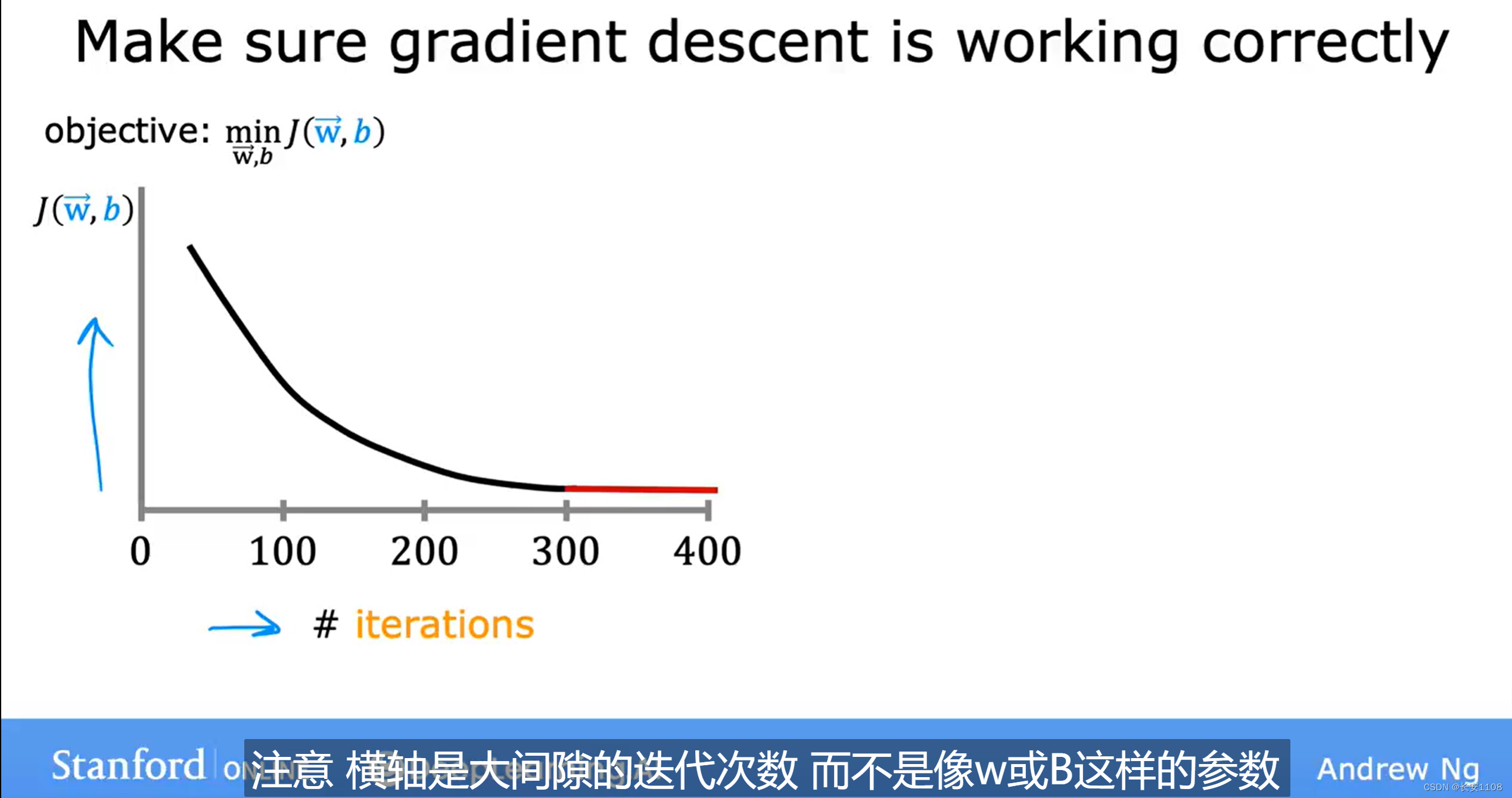
我们根据梯度下降的数据,可以拟合这样一条学习曲线,横轴是迭代次数,纵轴是成本函数的值J
通过他我们可以得到许多信息: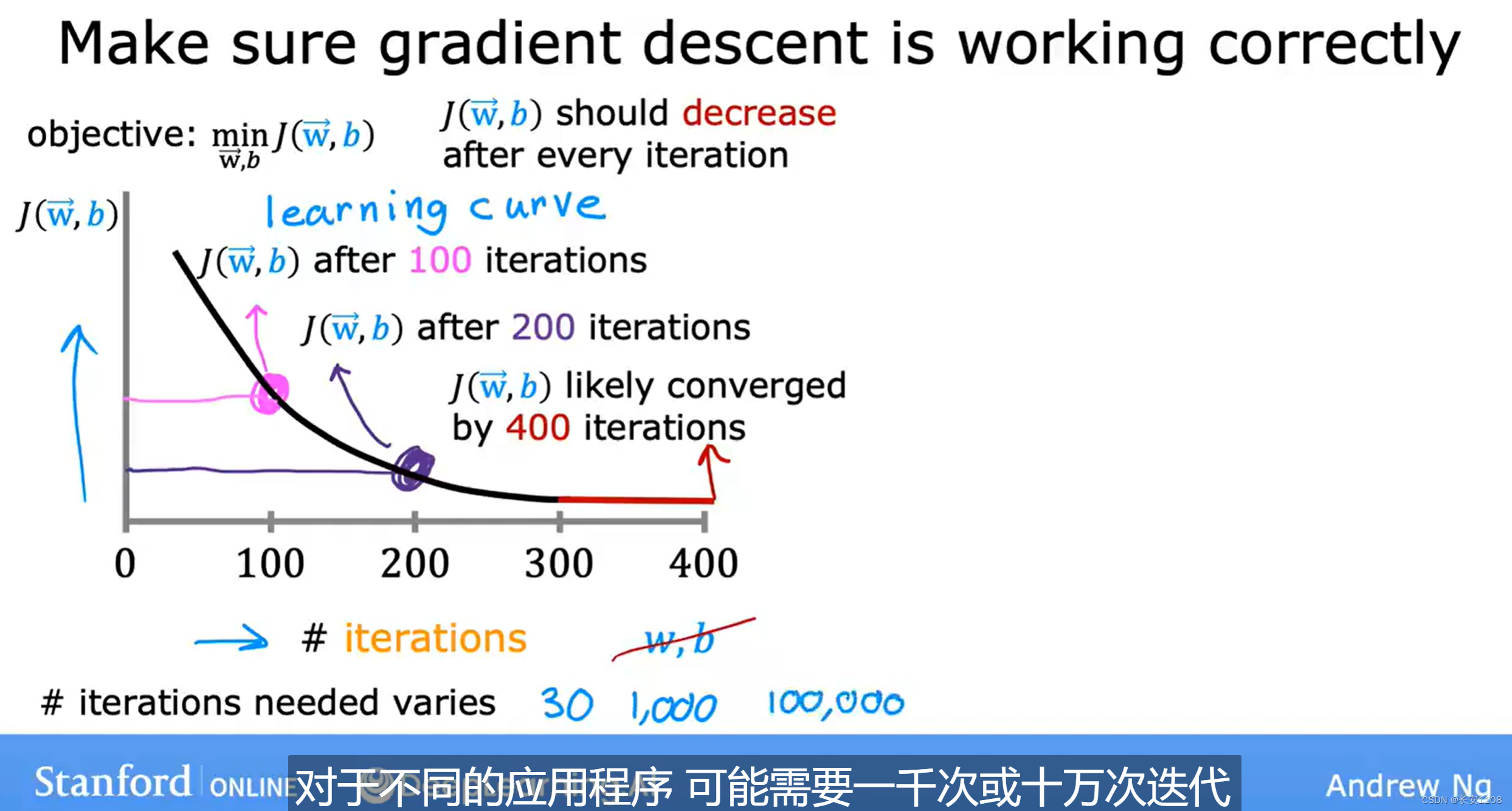
1、如果梯度下降算法正常工作,那么该函数应该是一个单调递减函数,如果一旦出现J随着迭代次数的增加而上升了,那么就反映出α有问题
2、400次时,曲线趋于稳定,这意味着,J不再下降,也意味着该学习曲线是收敛的,如果学习曲线收敛,那么梯度下降就是收敛的,就一定会下降到极小值
3、同时要注意,对于不同的情况,迭代次数可能会有所不同,所以,要迭代尽可能大的次数之后,再下结论
自动收敛测试

我们设一个很小的值为-1e3,如果J的下降幅度小于-1e3,那么可以认为目前在左侧曲线图中的平坦位置,此时可以宣布收敛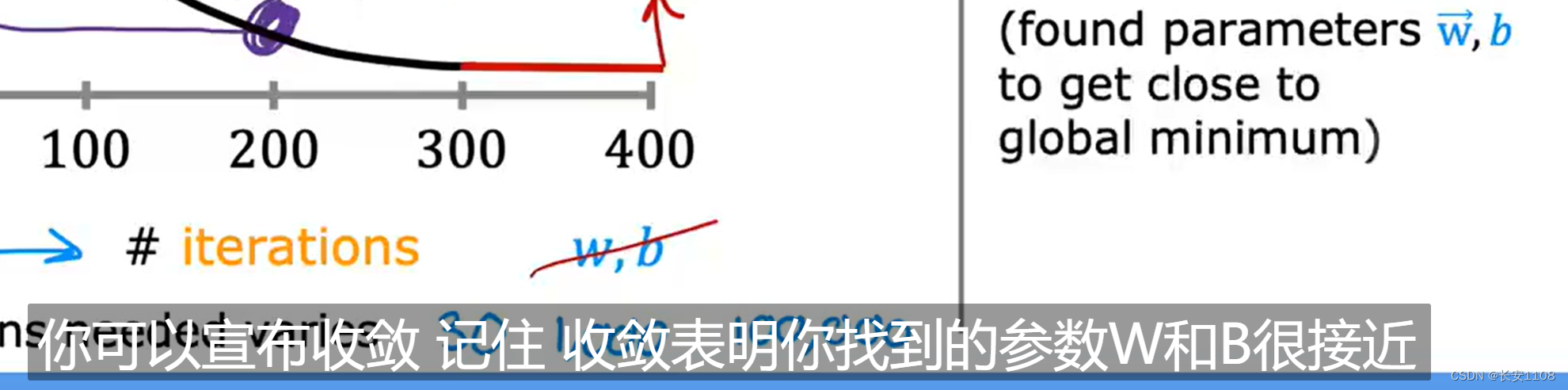
但是该方法不如学习曲线法更加严谨与精确
特征工程
例子引入


特征工程是指,我们在面对一个训练模型时,可以自己设计新的特征,将其加入到我们的模型函数中,以使得我们可以得到一个更好的模型
多项式回归
案例引入
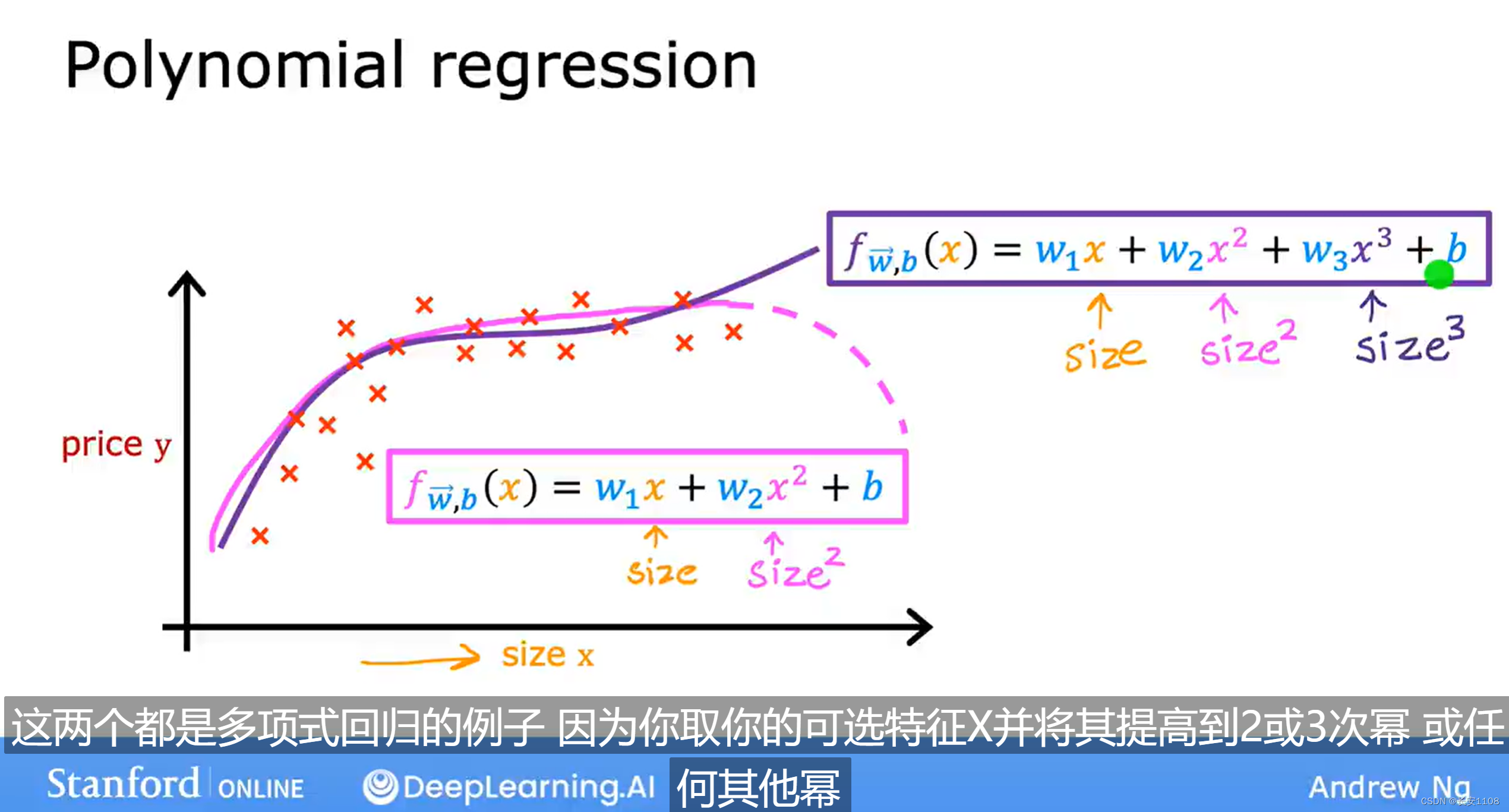
我们对于这样一个数据集,我们可以采取一元二次函数进行拟合,但是这样的函数在x的前半段似乎是合适的,但是后半段就不合理了,房价不可能因为size的增加而降低,所以我们尝试使用三次幂进行拟合,貌似看起来是合理的,这就是多项式回归

但是要注意,由于每个项的次幂不同,而次方的影响是巨大的,所以,势必会造成每个项对应的w的范围相差甚远,这时就要用到特征缩放进行训练了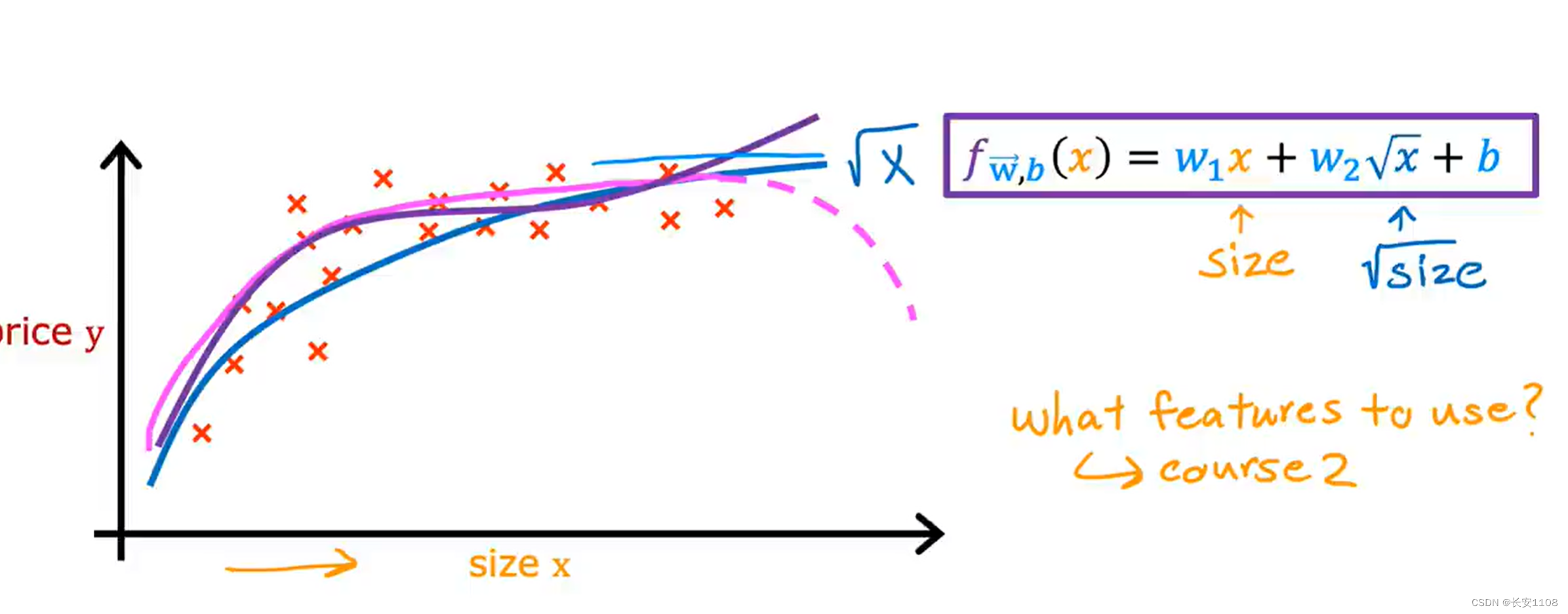
当然,我们也可以尝试使用根号来进行拟合,这看起来貌似也是合理的,但是具体如何选择,我们在今后会介绍
分类模型(逻辑回归)
简介
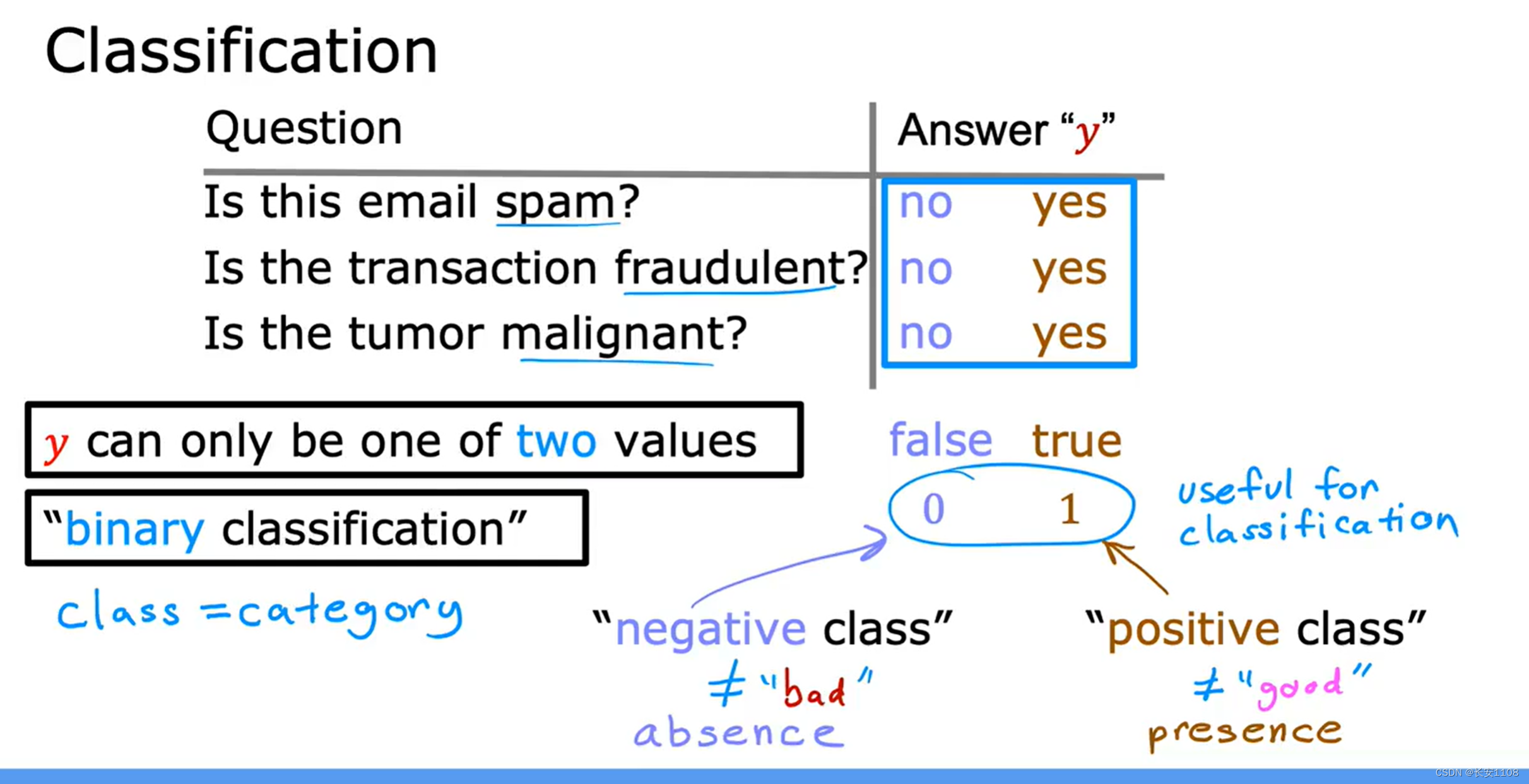
答案是有限的,算法需要进行选项的选择,从多个待定的选项中,选出他认为是正确答案的选项
对比
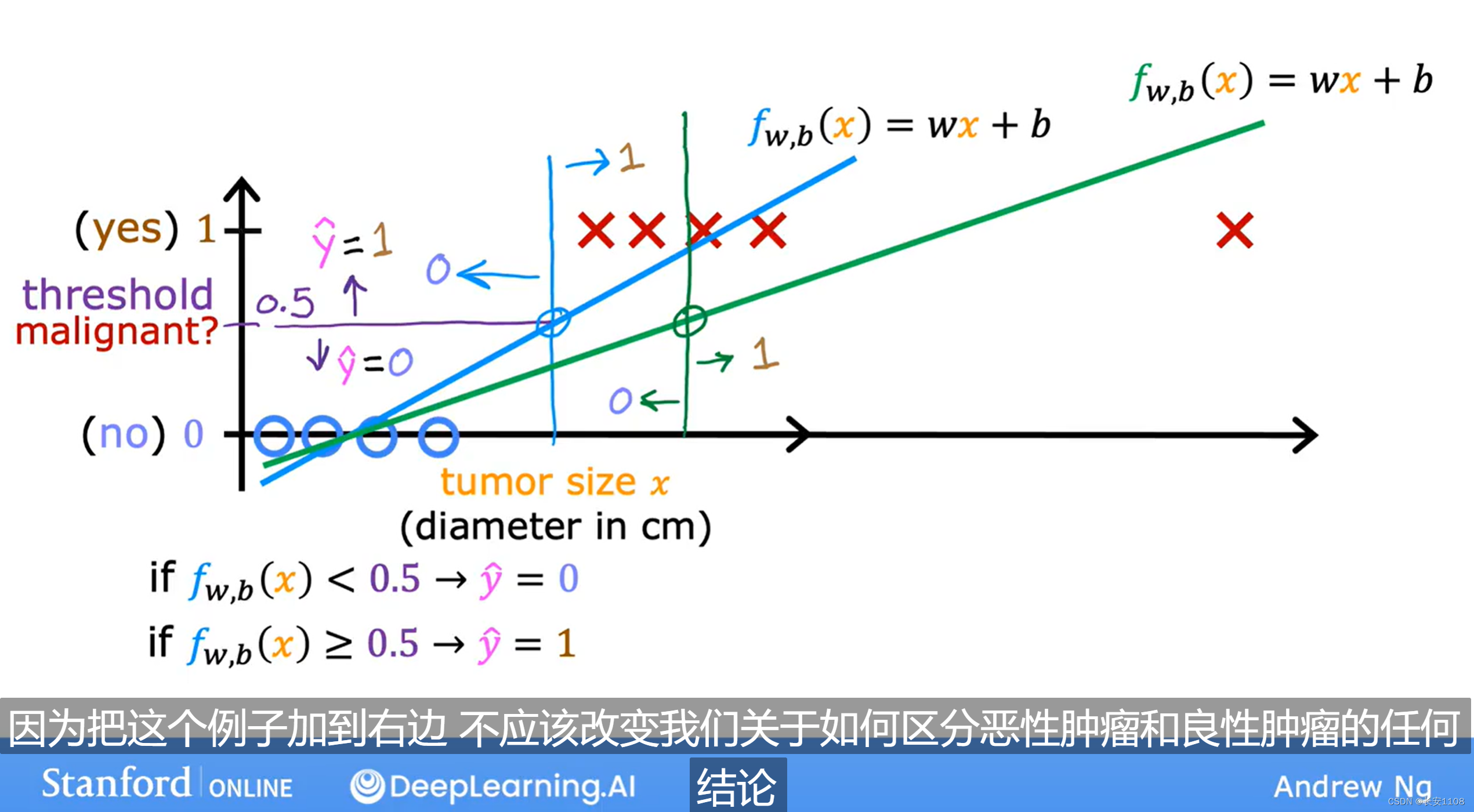
假如说我我们使用线性模型来进行分类算法的分类,该例中,输出结果要么是0(表示恶性)要么是1(表示良性),对于那条蓝色的线性直线,我们可以选取“门槛”,或者说是“界限值”,来决定他对应的值是0还是1,我们选取纵轴为0.5的位置所对应的横坐标作为界限值,那么看起来是合理的,但是,当我们最右侧出现一个训练案例,那么线性回归方程为了得到最优的拟合效果,他会变成上图绿色的线,这时,我们再选择纵轴为0.5的位置所对应的横坐标作为界限值,原先被划为恶性的案例,变成了良性,可见,线性回归模型根本无法拟合分类算法
logistic算法
简介

该算法的横轴是Z,纵轴是g(Z),其中,e是2.7,可以看到当Z特别大的时候,结果接近1,当Z特别小时,结果接近0。
当Z=0时,得到g(Z)的值是0.5,所以,我们构建出了上图所示轨迹
实现
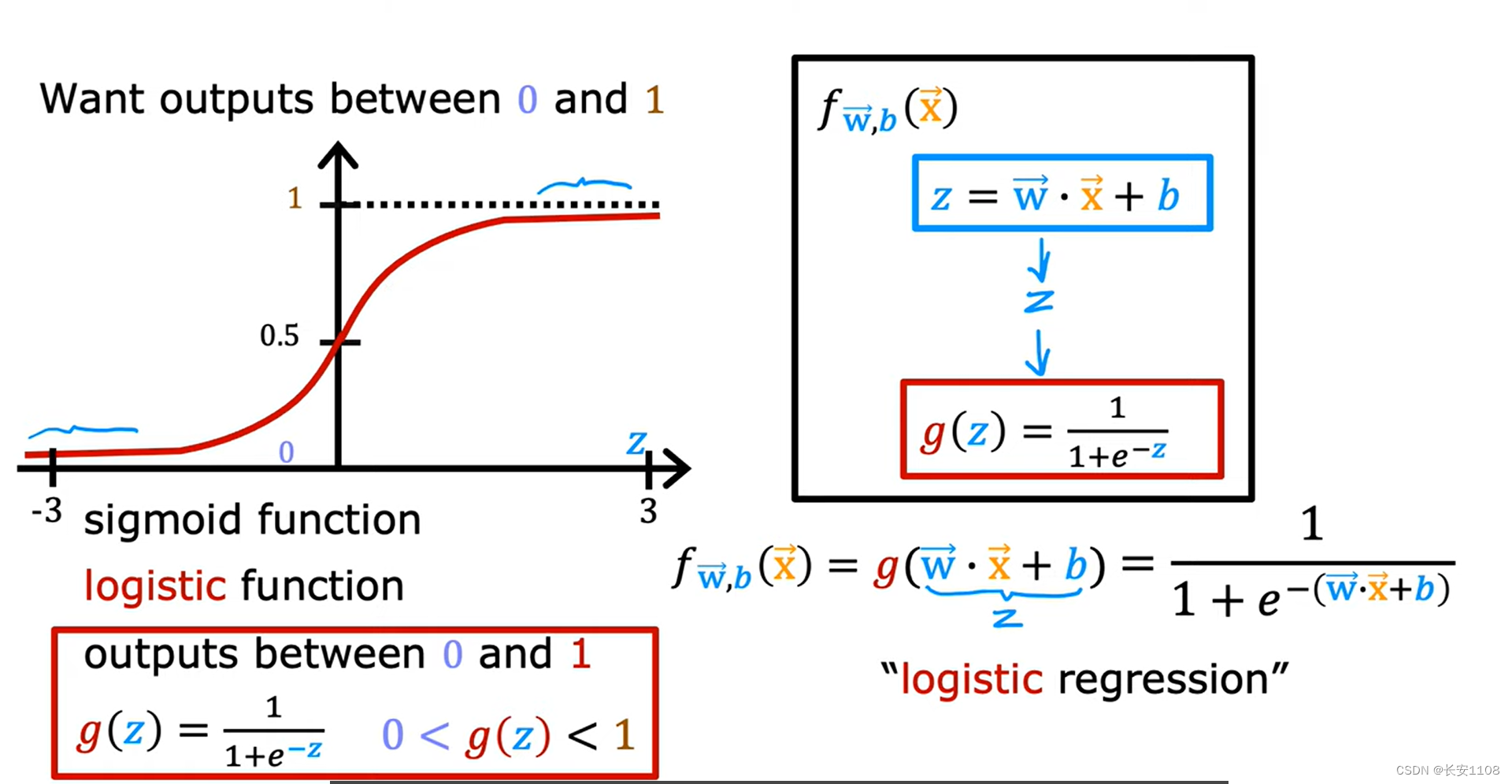
Z的表达式,就是w向量 点乘 x向量 + b 的结果,将z带入到g(z)中即可
实例

当输入一个患者的肿瘤块大小x之后,最终logistic算法得到的值是0.7,这意味着,模型认为,输出的y等于1的概率为0.7,我们可以视情况,将其界定为恶性
决策边界
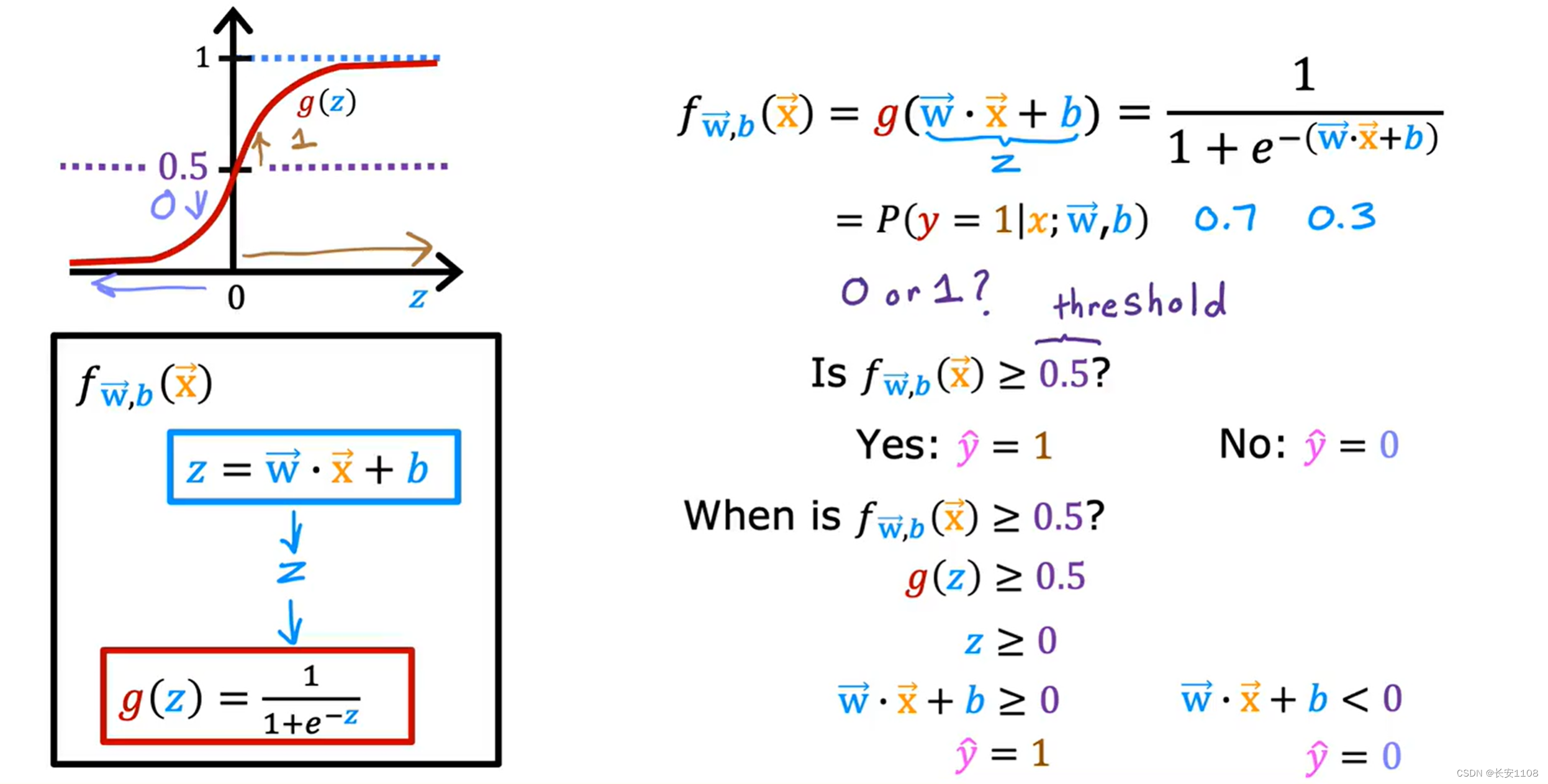
现在我们知道了g(Z)的值是,产出值y是1的概率,现在我们只拿到了概率,如何让算法根据概率进行决策选择是我们目前的问题,因为决策不是0就是1,而且根据概率的特性,0.5的概率一般被作为界定线,所以,当g(Z)=0.5时,是一个分界线,g(Z)>=0.5时,我们将其界定为1,那么再进行下一层推算,即Z>=0即可,那么也就是w向量点乘x向量+b >= 0时,y界定为1,相反,y界定为0
举例

我们有所有数据关于x1、x2特征的信息图,我们先找到边界线,第一步,先找z,z等于x1+x2±3,所以,当该式子等于0时,就是边界线,也就是x1+x2=3,我们可以将x2看成平时的y,即x2=-x1+3,就可以在图中画出边界线,所以该线左边都是小于0,右边都是大于0
其他高阶多项式模型的边界:

分类模型的成本函数
对比

我们对比线性模型的成本函数图像,假如我们还是使用线性回归模型的成本函数的计算方式,那么最终的图像如上图右边所示,是一个不规则的,具有多个凸起的图像,那么他就会有多个局部最小值,或者说有多个极小值,显然这是难以计算的
正确的成本函数
定义
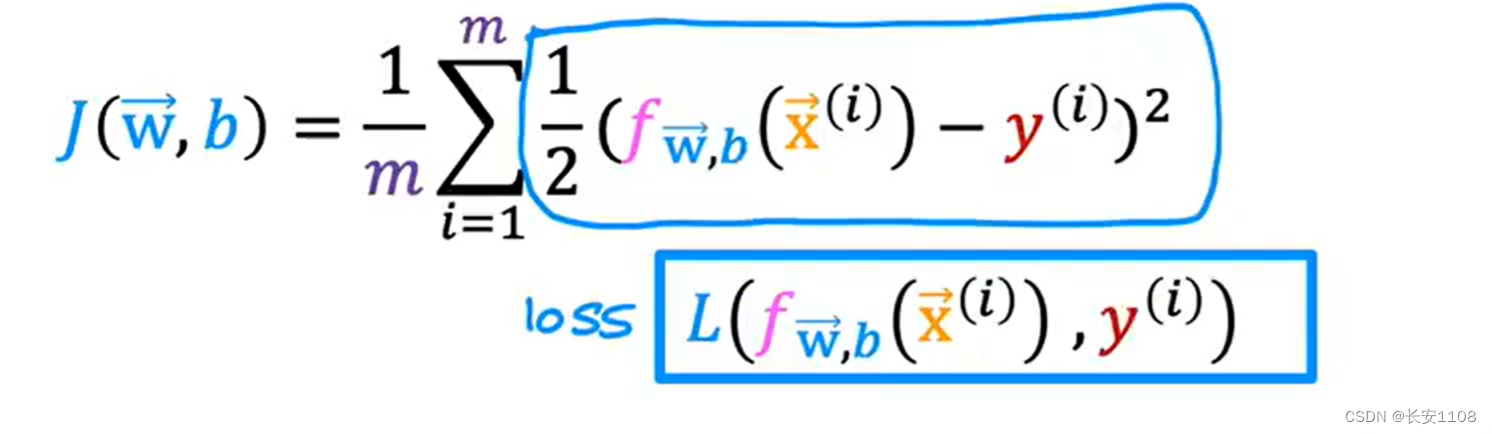
我们对成本函数做如上图所示的变换,将1/2放入求和符号里面的每一项,这样,我们就可以将每一项用L表示,也被称为损失函数,这样我们就得到了如下图所示的成本函数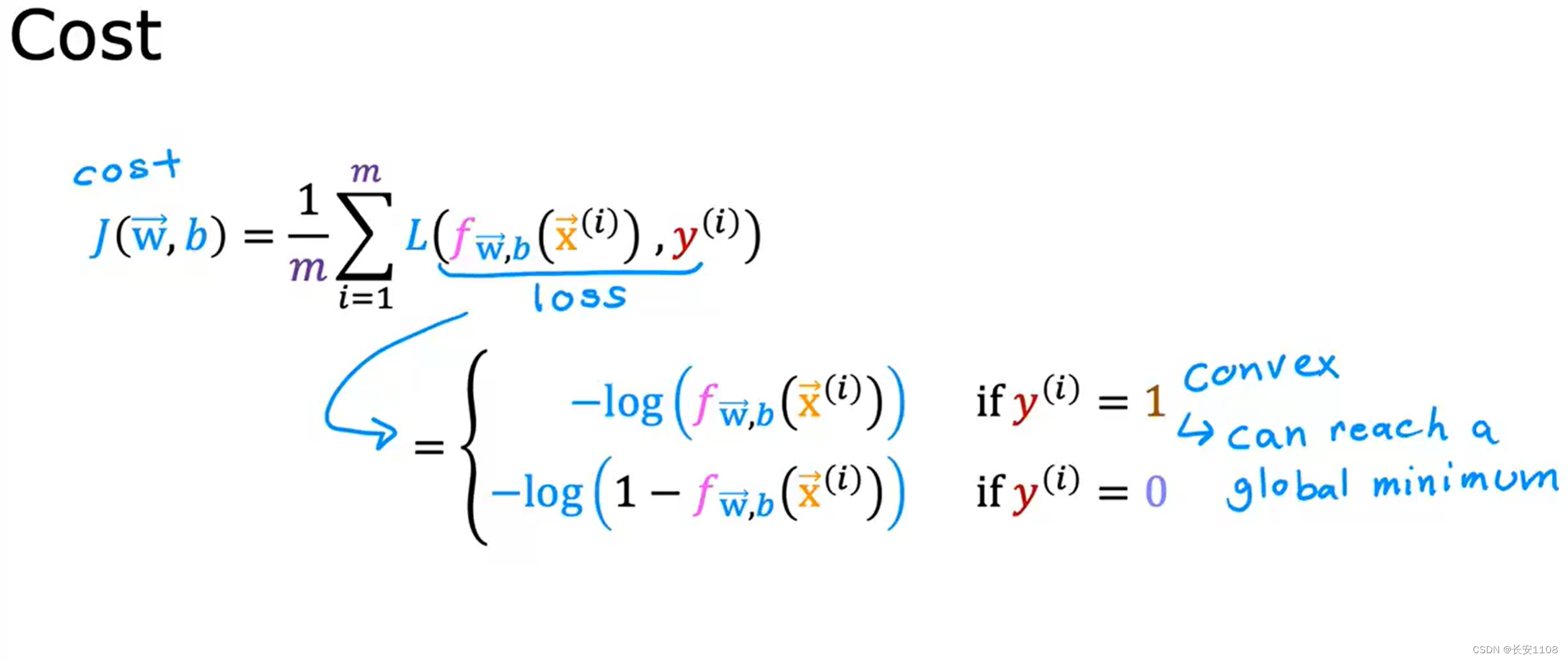
y=1
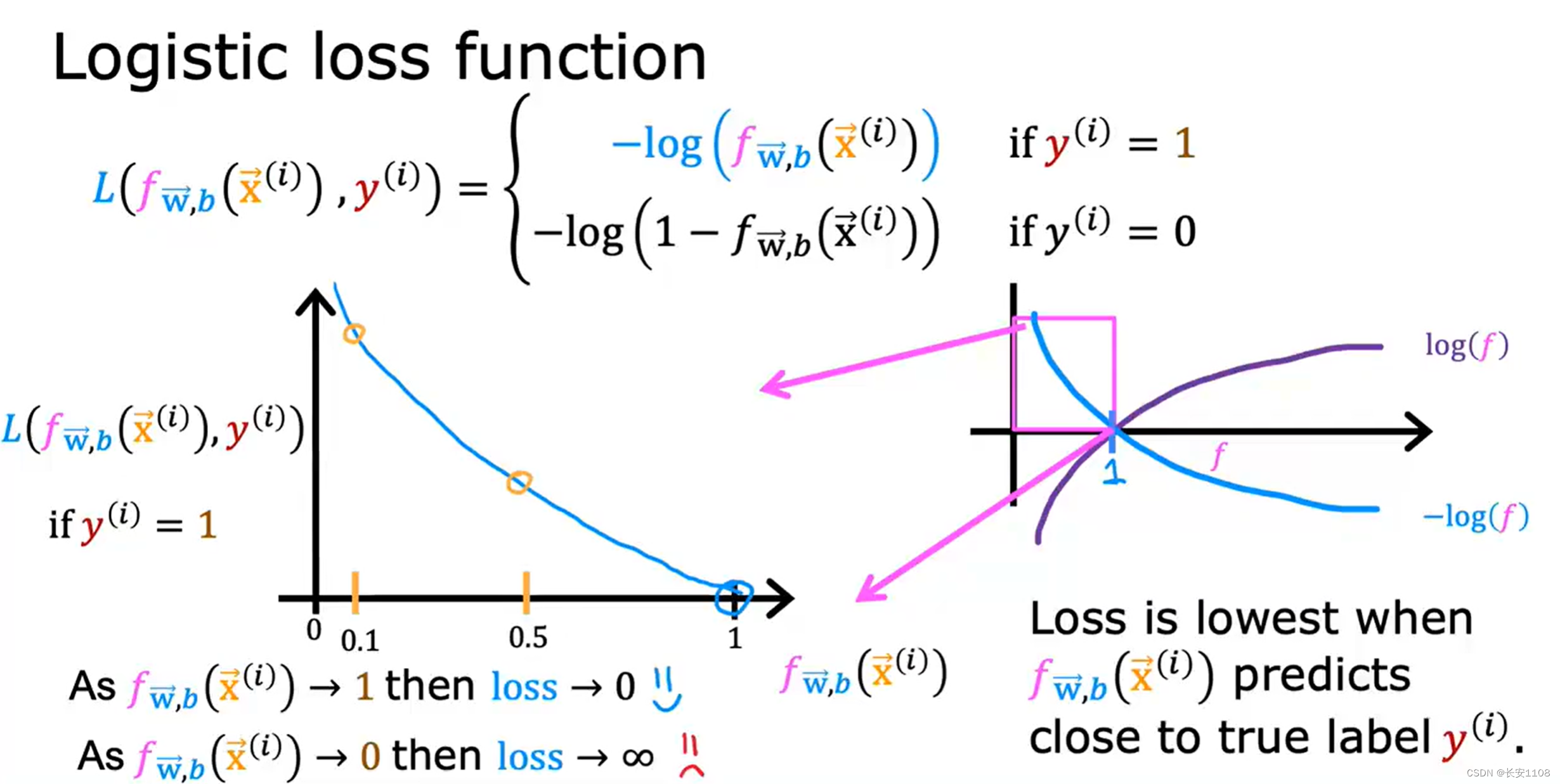
首先看等式左侧,L(f(x),y),表示单一训练例子的成本函数,也就是每个特征只拿一个数据。我们这里重点研究单一训练例子的成本函数,之后进去求和或者其他操作即可
之后再来看等式右侧,他是一个分段函数,我们先看y=1的情况,注意是y=1(而不是y^),也就是真实的数据就是y=1
f(x箭头),这个整体算出来就是y^,上图用 f 来表示。因为预测值是在01之间,所以 f 的范围也是01之间,而他是一个负对数,所以我么可以做出他的图像,左侧是放大图,当 f 的范围是 0到1时,他的值逐渐减小,说明,对于真实值是1的数据,当预测的y尖越接近于1,他的成本就越小,也就是损失越小,也就越准确
y=0
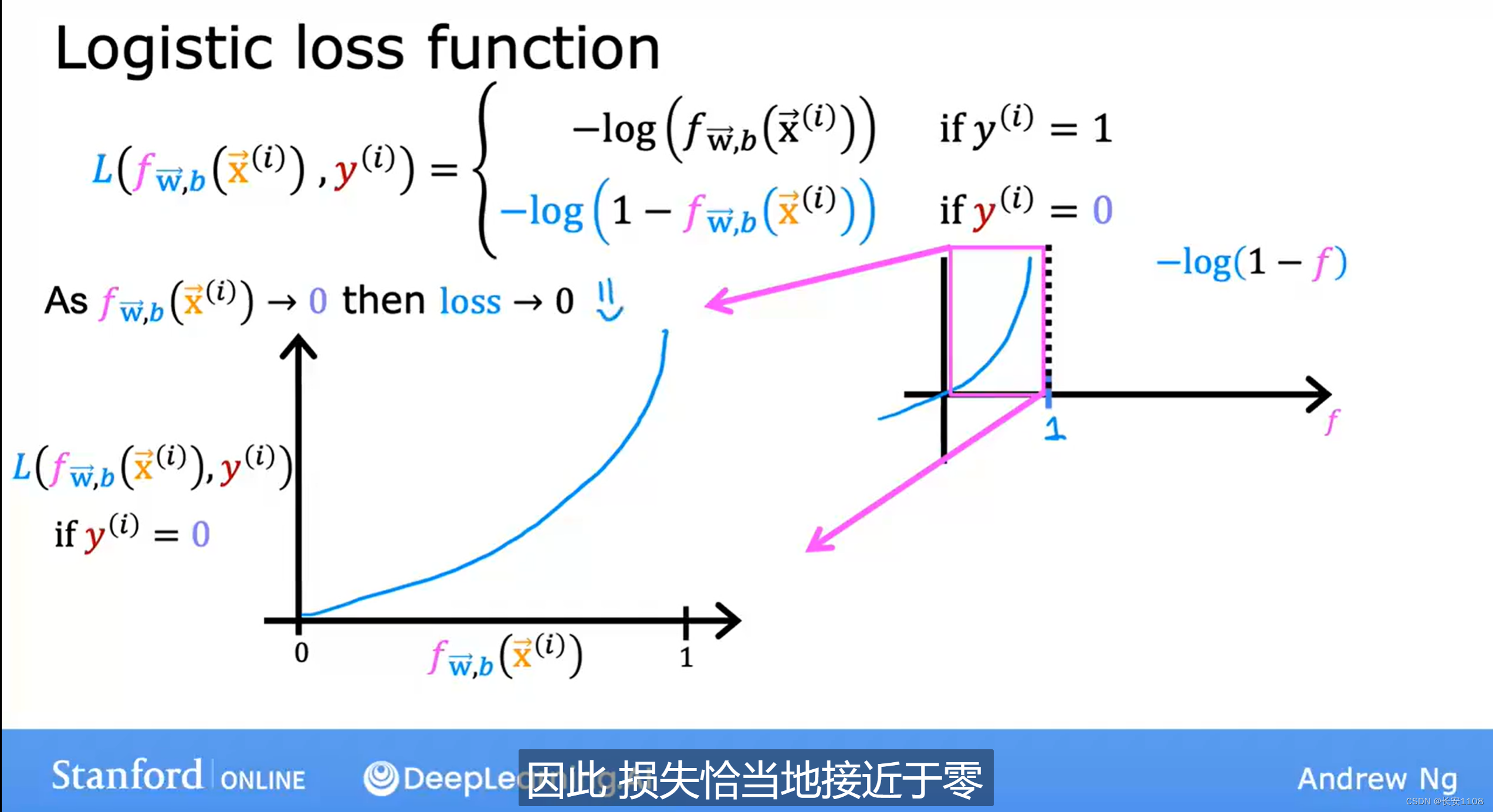
对于y=0的数据,他的成本函数如上图所示,当y^(也就是上图中的 f )越接近于0,也就是越接近于真实数据,那么损失就越小,相反,如果y的预测值与真实值相差甚远,那么成本会大大增加,损失会大大增加
简化版损失函数和成本函数

因为y只有0和1两个值,所以,我们可以将其与0、1的一些表达式进行组合,使其变成一个式子,如上图所示,他完全等价于我们的L
根据该损失函数,我们可以得到分类模型算法的成本函数:
他有一个很好的性质,该成本函数是凸的
梯度下降
有了合适的成本函数之后,我们可以进行梯度下降
最终我们会化成如下图所示的梯度下降公式,其中形式与之前的线性回归一致,但是其内涵是不同的,下图中的下部分是线性回归与当前的分类算法的梯度下降中 f 函数的对比
过拟合问题
简介(基于线性回归模型)
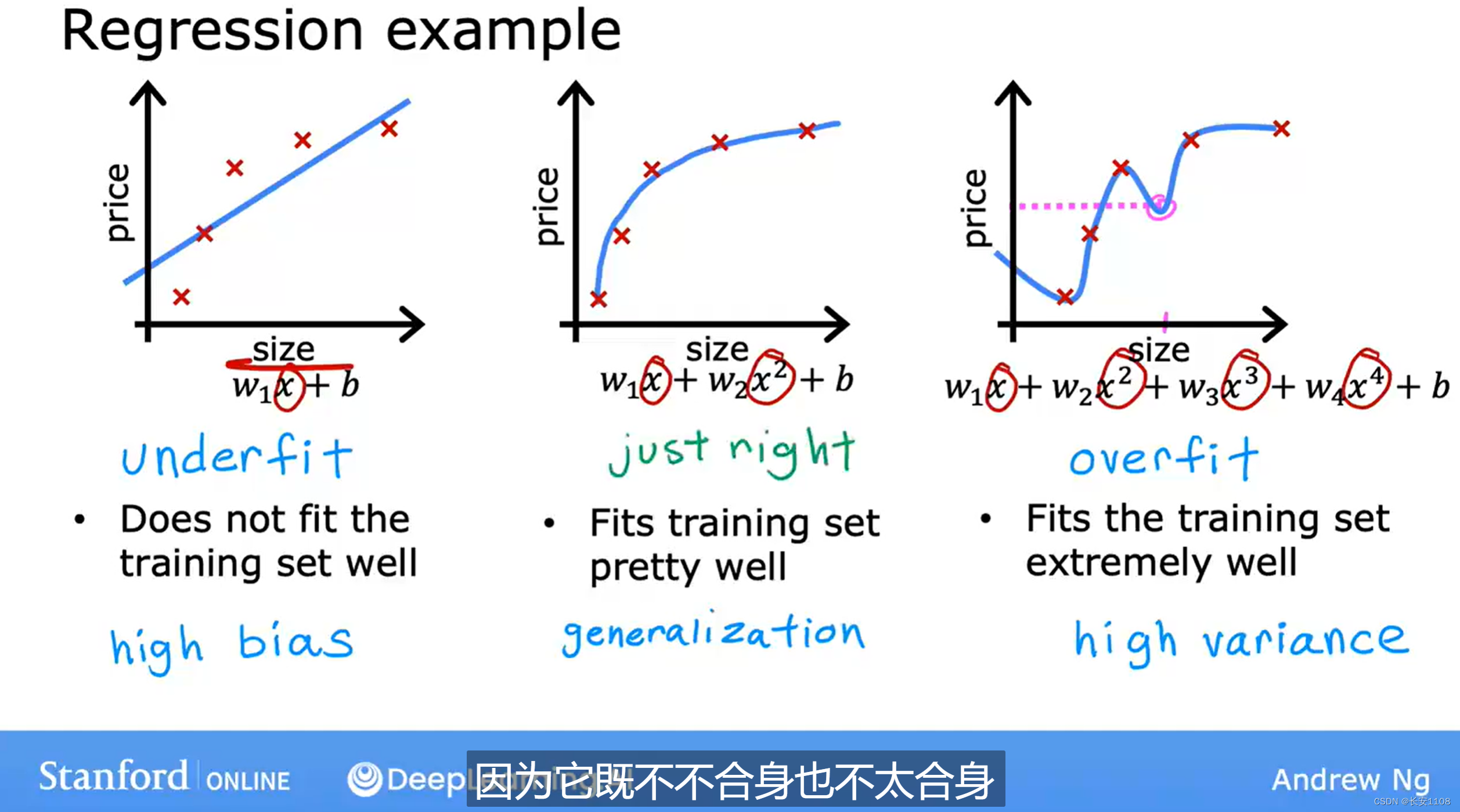
我们的算法尽可能的预测真实的数据点位或者其附近的过程,称为拟合数据
上图所示三种情况,
左边的拟合过少,不够具有说服性或者科学性
中间的拟合刚刚好,不会偏差很大也不会很特别合身,具有泛化的特性,可以更好的推理新的输入,给出合适的输出,这样的拟合数据是刚刚好的
右边的拟合过于合适,他过于的关注拟合数据的路线是否靠近真实数据,而忽略了整体的协调性与合理性,这叫做“过拟合”
所以:
分类模型的过拟合问题: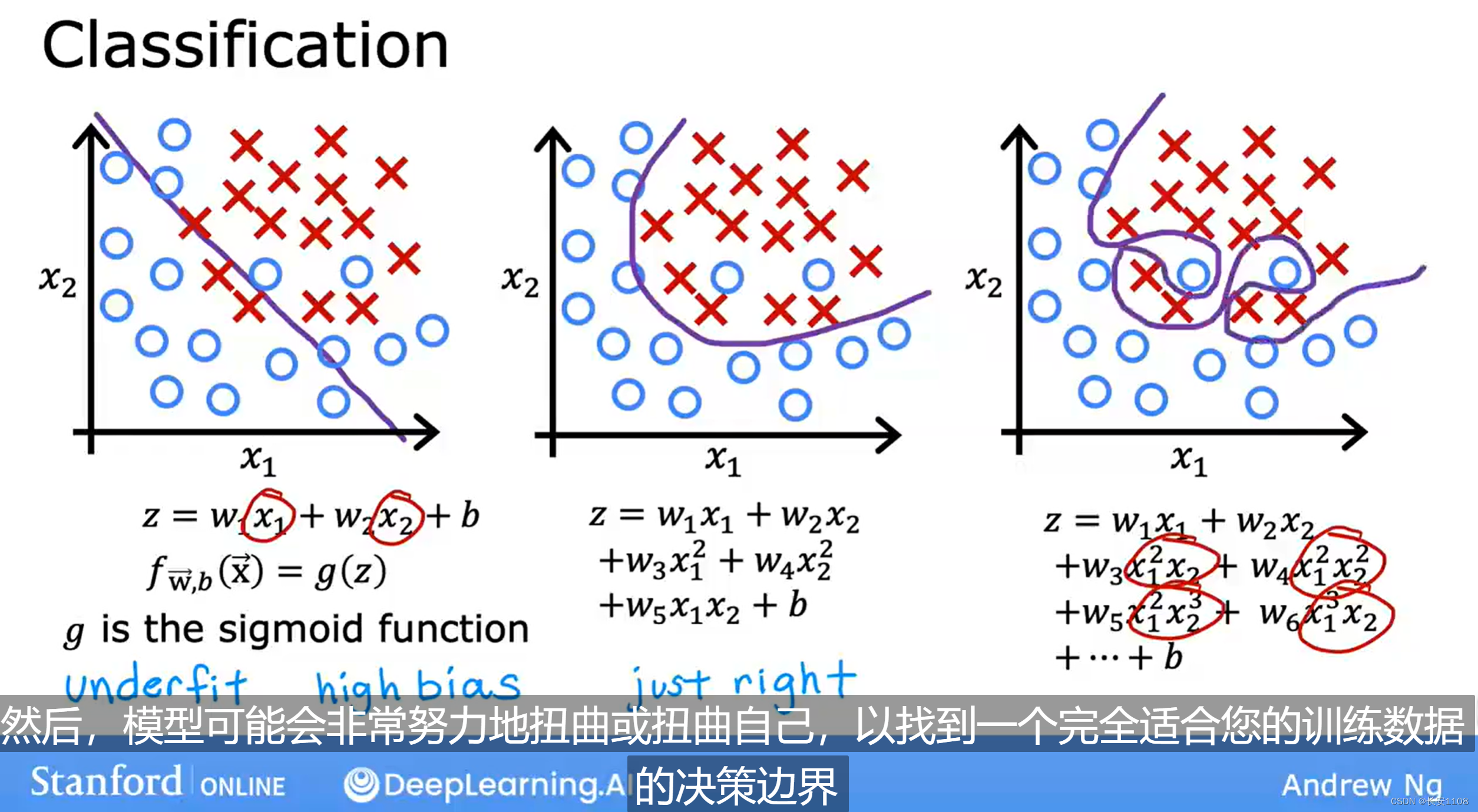
显然右边“过拟合”(或者说高方差,方差越高,拟合程度越好)
解决过拟合问题
输入更多的数据
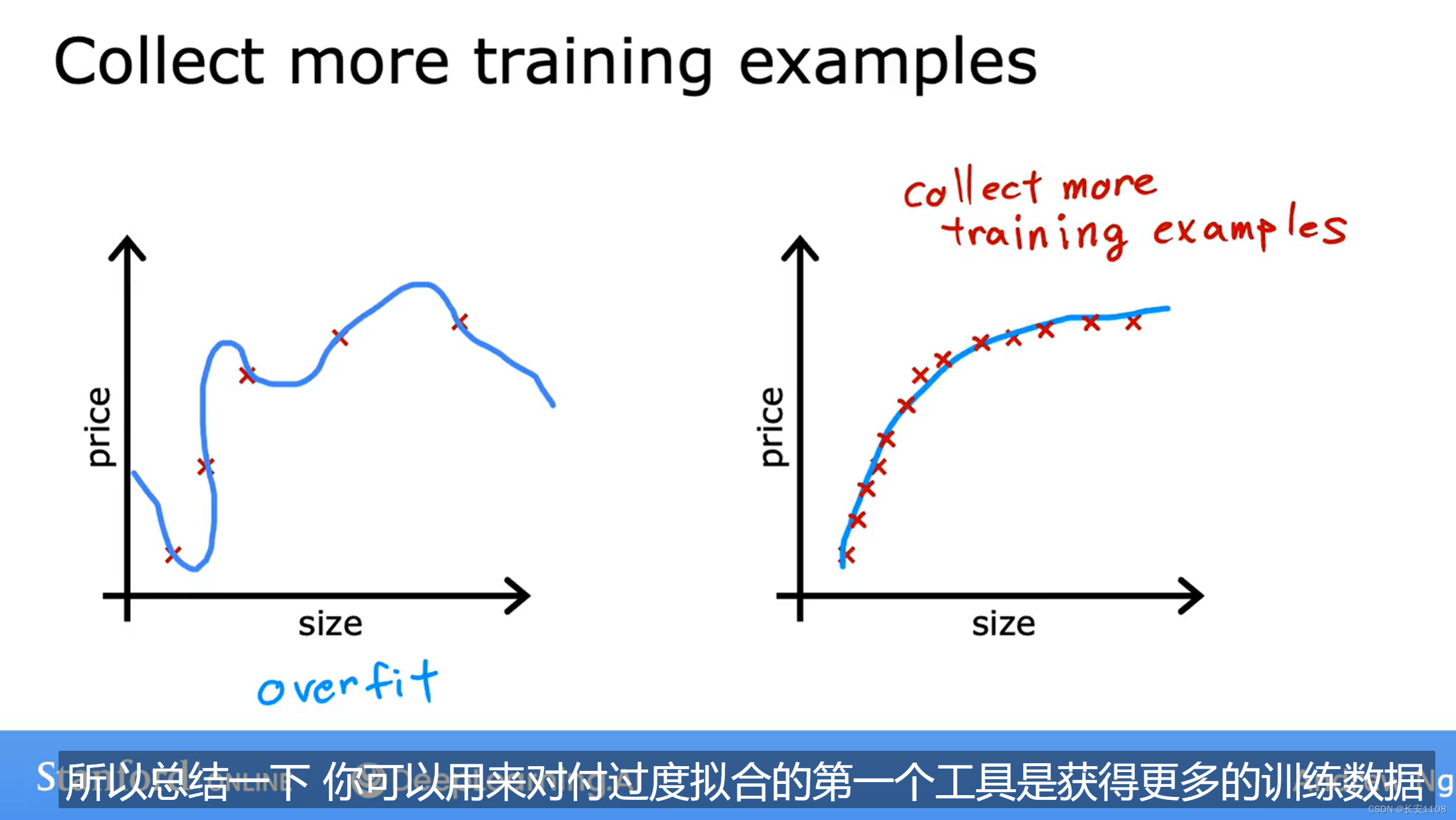
我们拿到更多的训练数据放入模型中训练,可能结果会变好
减少特征
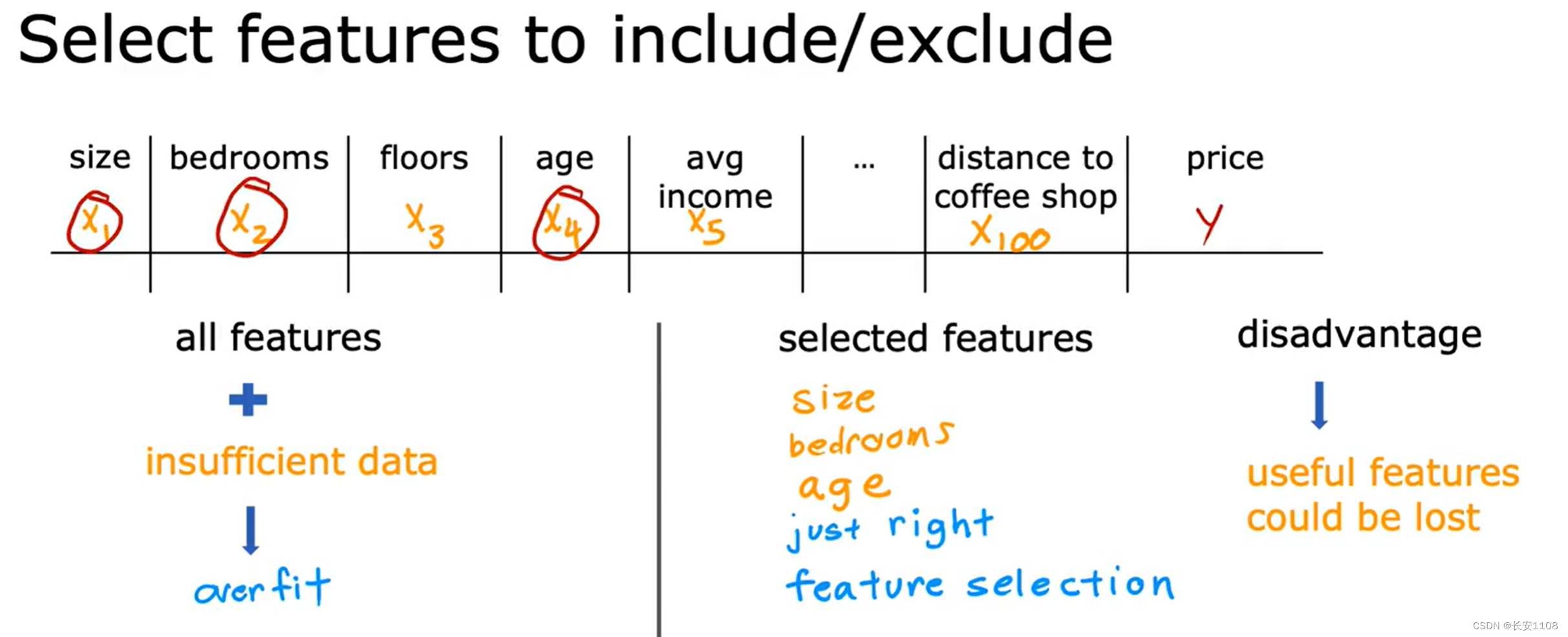
第二个减少过拟合的方法是减少使用过多的多项式特征
但是他的缺点是我们可能将有用的数据去掉了
正则化
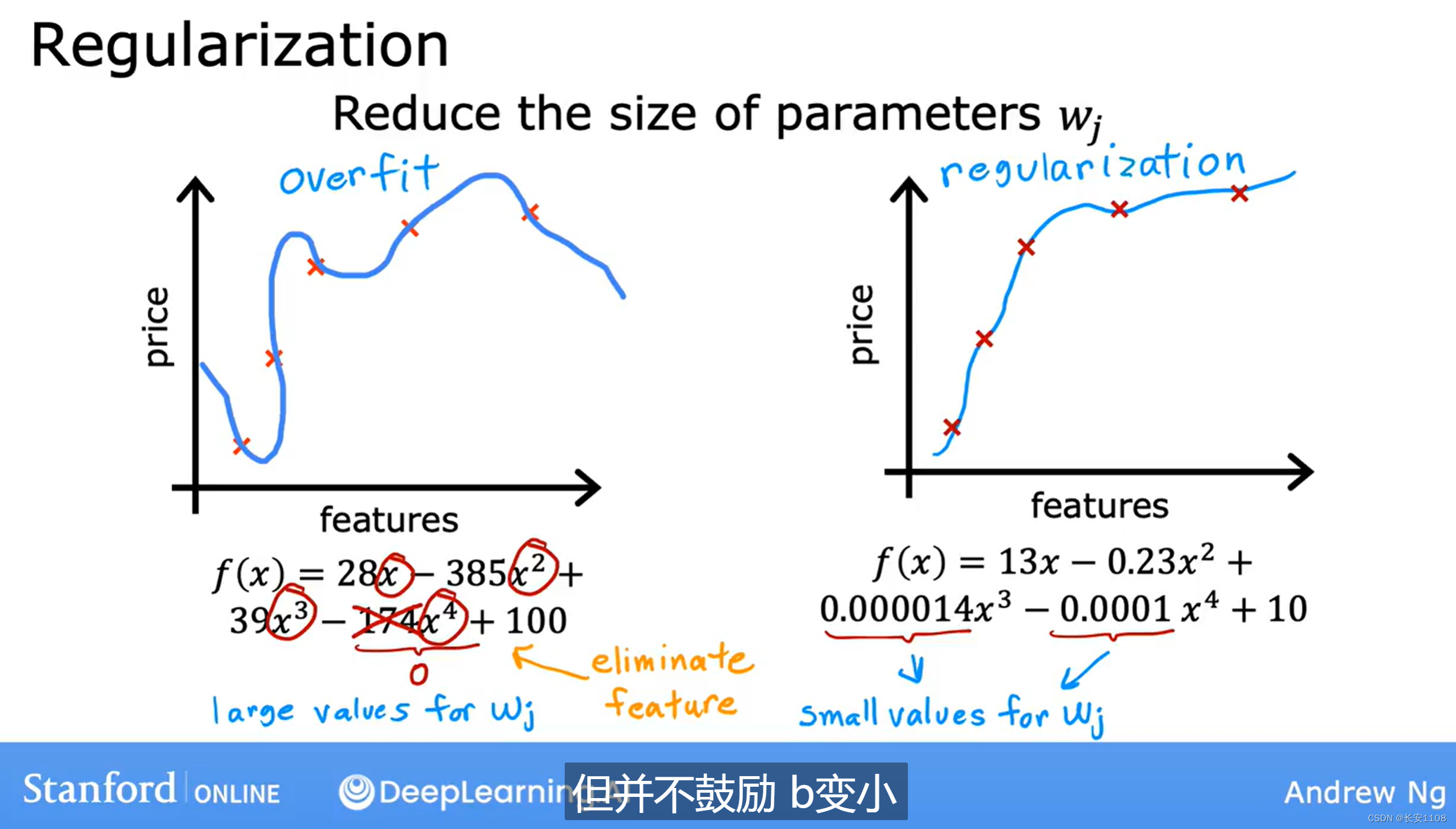
第三种方式是正则化,正则化就是将一些参数w的值缩小,重点缩小一些高次幂项的w值,但是并不鼓励缩小b(当然可以进行缩小,是合法的)
正则化代价函数(或者说成本函数)
案例引入
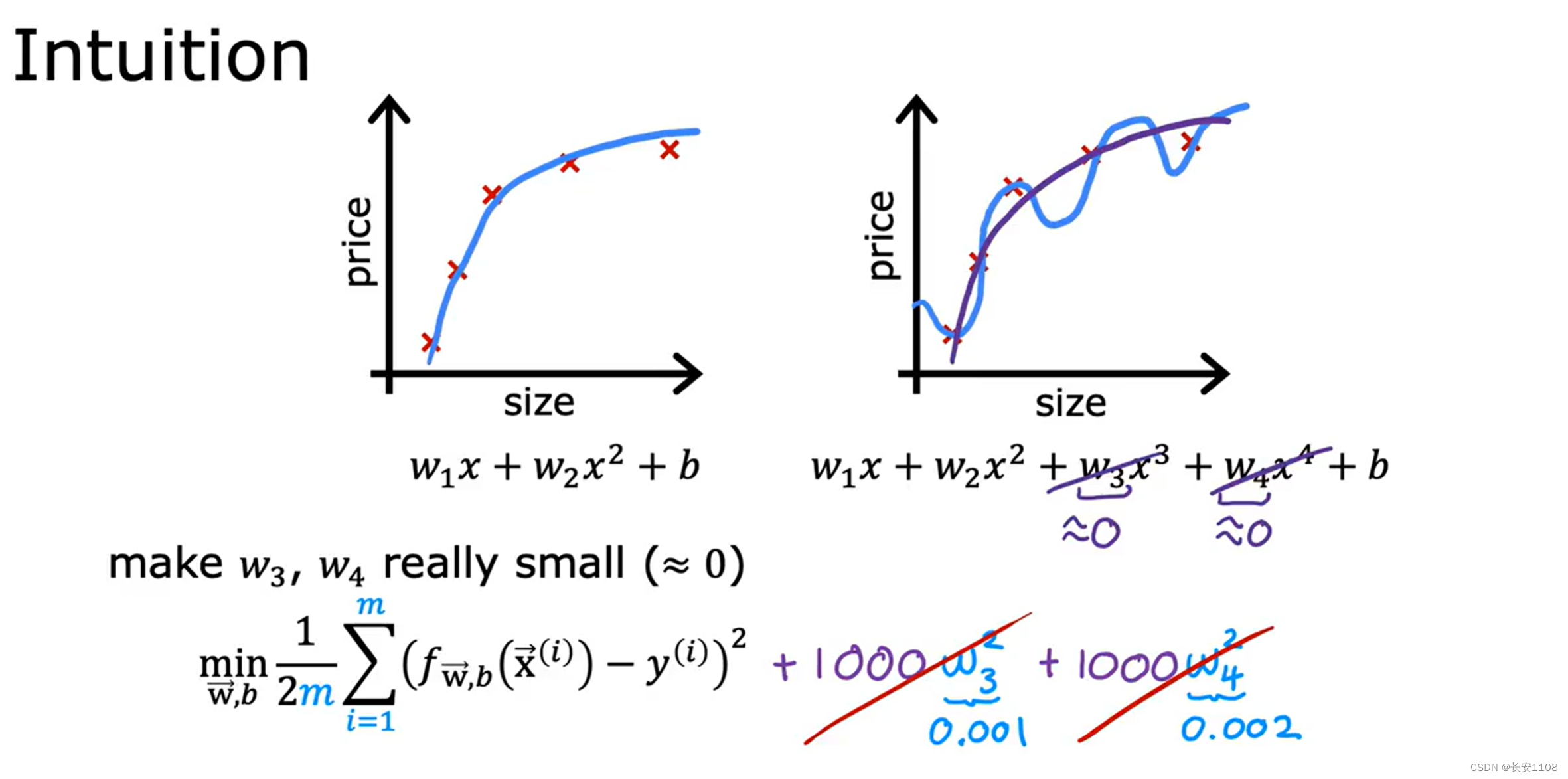
对于一个成本函数,我们可以添加几项如上图,这样,如果算法想让成本函数尽可能的小,那么w3和w4的值就要尽可能的小,甚至约等于0,这也可以叫做乘法w3和w4参数
简介
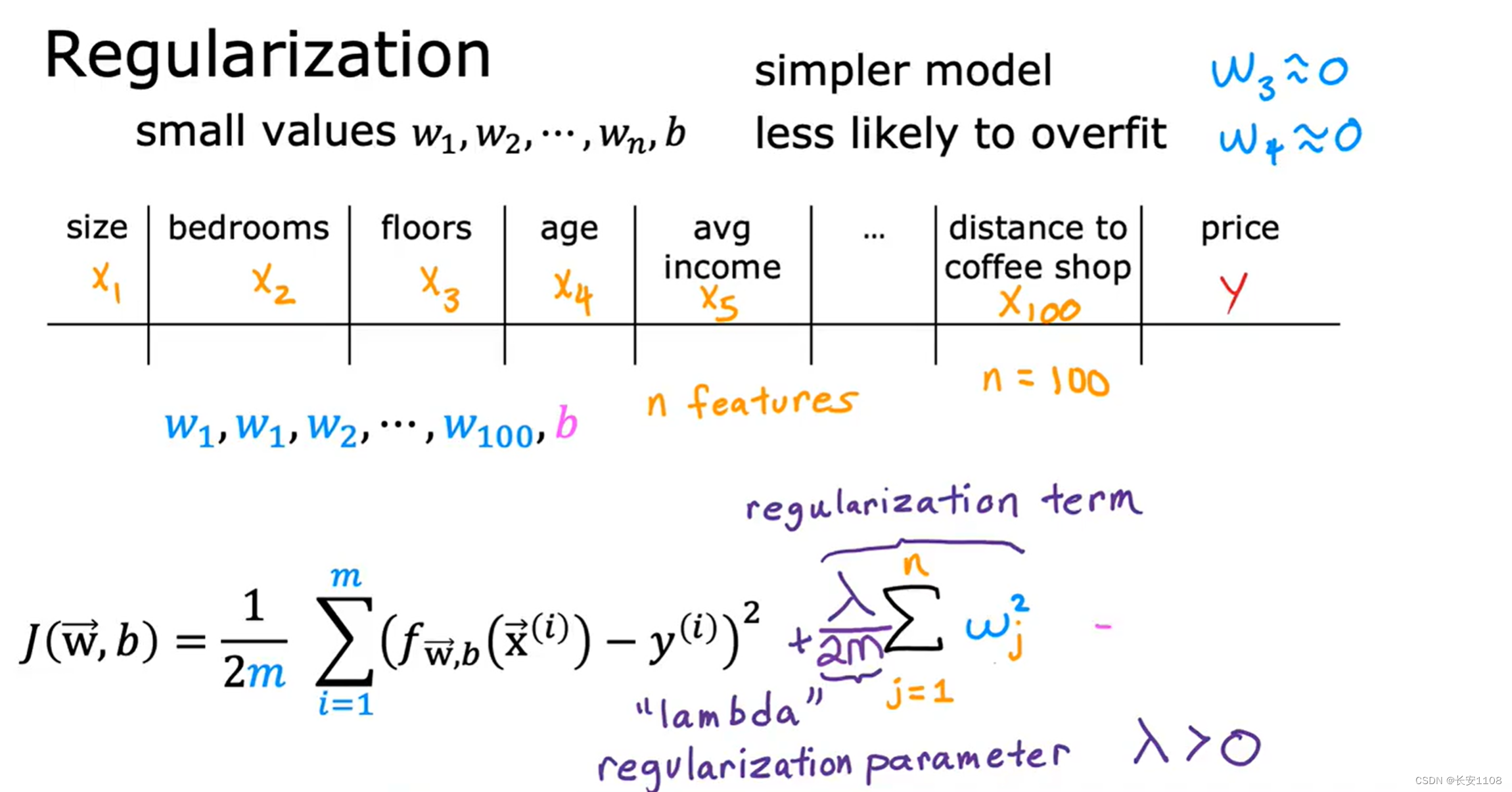
对于更常见的情况是,我们有很多个特征,我们不知道哪个是重要的哪个是不重要的,所以,一般更多的我们采取的方式是将所有的参数缩小,所以如上图所示,加入了一个求和项,其中lambda称为正则化参数,分母是2m。
当我们没有更多的m来解决过拟合时,那么m就会很小,那么新加入的求和项的权重就会越大,那么对参数的惩罚就越严重,我们就相当于使用了第二种方式解决过拟合
当我们有更多的m来解决过拟合时,m很大,那么lambda/2m就会很小,那么求和项的权重就很小,是否对参数惩罚已经不重要了,我们有了更多的数据来解决过拟合
但是注意,我们这里不建议对b也进行惩罚
优化后的成本函数

所以,最后的成本函数如上图所示,右边新加项为正则项,我们的关键在于如何设置lambda,如果他的值过大,那么正则化会过大,那么就会是一条直线b,如果lambda过小,正则化很小,正则化不起作用,那么就可能会出现过拟合
正则化线性回归
实现梯度下降的正则化


我们对成本函数进行了正则化之后,顺理成章,我们可以对梯度下降做出优化,如上图,唯一不同的是仅在w参数的导数项增加了一个lambda/m*wj,而b参数的导数项不变,因为我们还是坚持b参数不优化的原则
正则化了线性回归的成本函数和梯度下降,那么就完成了对线性回归的正则化
正则化逻辑回归
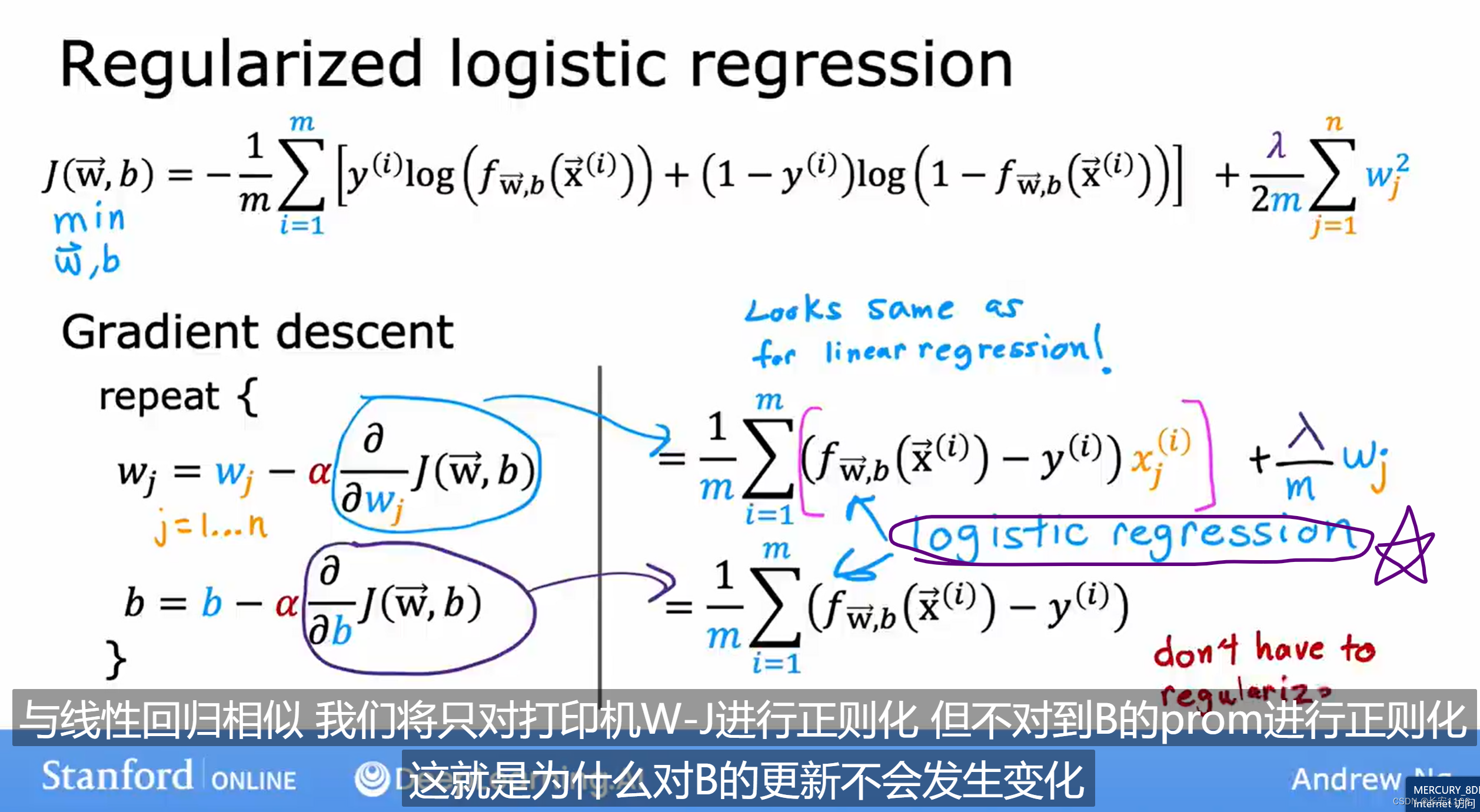
他对成本函数以及梯度下降公式的正则化,对公式的改动一模一样,唯一不同的是,逻辑回归中的 f 函数是logistic函数
版权归原作者 长安1108 所有, 如有侵权,请联系我们删除。