
注意力机制可以增加少量参数的情况下来提升计算精度和模型性能,在论文中常用的注意力模块合集(上)中介绍了三种注意力机制,它们分别是CA、CBAM和SE,均在目标检测和语义分割领域内能够提升模型的性能,废话不多说,直接开始讲解剩下的论文中常用的注意力模型。
1、有效通道注意力(Efficient Channel Attention Module, ECA)
深度学习中,降维不利于学习通道注意力,但是适当的跨通道交互可以在显著降低模型复杂性的同时保持性能。因此,这里的有效通道注意力(Efficient Channel Attention Module, ECA)模块是一种通过1D卷积实现无降维的局部跨信道交互策略,且可以自适应地选择1D卷积的核大小,以确定本地跨信道交互的覆盖范围,可以带来比较明显的性能增益,结构如图1所示。
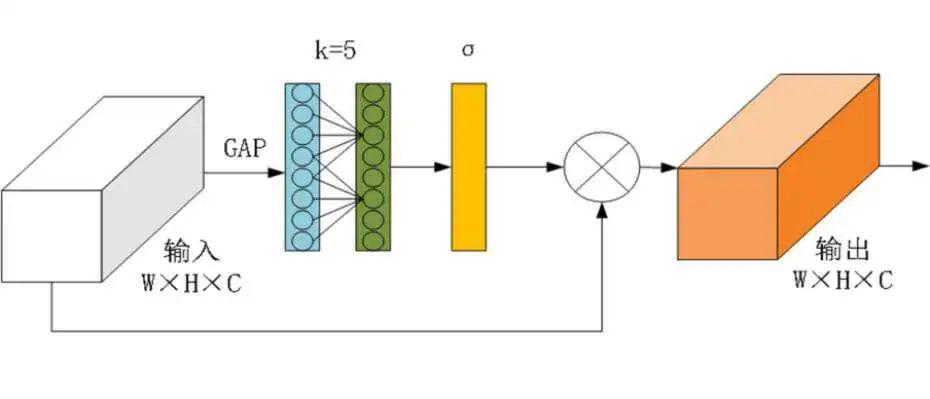
图1 ECA结构图
ECA模块需要确定交互的覆盖范围来捕获本地跨信道交互,但手动调整交互的优化覆盖范围会导致耗费大量计算资源。由于组卷积改进CNN架构中的高维(低维)信道会共享给定固定数量组的长距离(短距离)卷积,因此,相互作用的覆盖范围(即1D卷积核的大小k)与通道维度C成比例,即k和C之间存在映射φ:
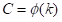
最简单的映射是线性函数,即φ(k)=γ*k−b,但是线性函数所表征的关系过于有限。另一方面,通道维度C常常是2的指数幂。故可将线性函数扩展为非线性函数:
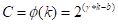
因此,当给定通道维度C时,卷积核大小k可以通过下述公式进行自适应确定:
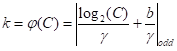
其中,

表示离t最近的奇数,这里将将γ和b分别设置为2和1。因此,通过使用非线性映射,高维通道具有更长距离的相互作用,而低维通道具有更短距离的相互作用。
2、双重注意力(Dual attention network,DANet)
双重注意网络以自适应地将局部特征与其全局依赖性集成,如图2所示,具体是分别在空间维度和通道维度上对语义相关性进行建模,空间维度上通过所有位置的特征加权和来选择性地聚集每个位置的特征,通道维度上通过整合所有通道特征图中的相关特征来选择性地强调相互依赖的通道特征。然后,将两个注意力模块的输出相加,以进一步改进特征表示,有利于获得更精确的分割结果。
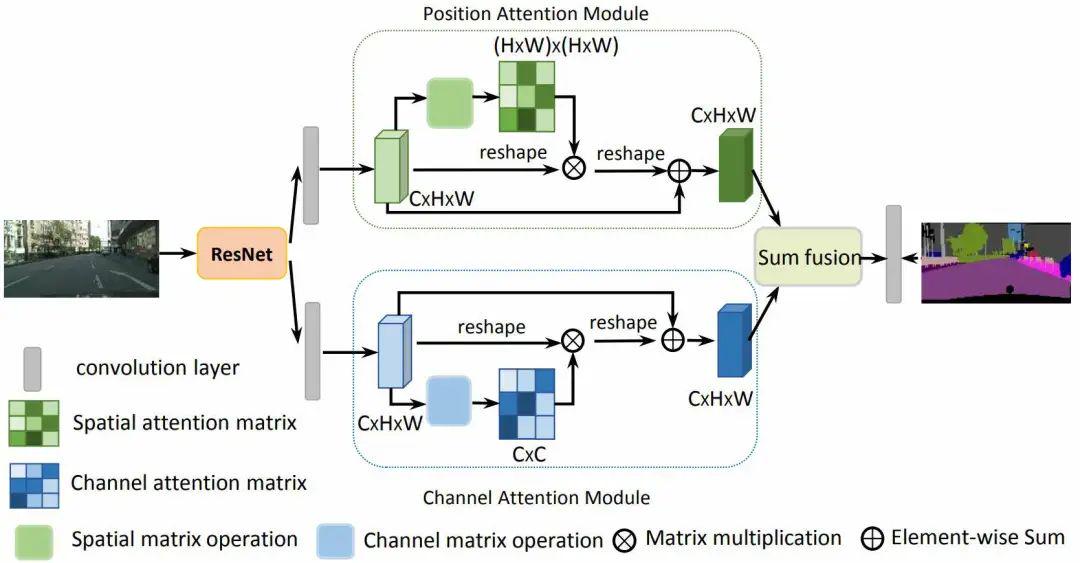
图2 DANet模块
2.1 空间注意力模块
空间注意力模块能够在局部特征上建立丰富的上下文关系模型,同时可以将更广泛的上下文信息编码为局部特征,从而增强其表示能力。
如图3所示,给定局部特征

,将其输入卷积层以分别生成两个新的特征映射B和C,其中
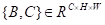
,然后令它们重塑为
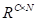
,其中N=H×W表示为像素数。之后,在C和B的转置之间执行矩阵乘法,并应用softmax层来计算空间注意力图
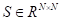
:
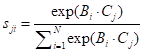
其中
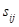
是计算第i个位置对第j个位置的影响。两个位置的更相似的特征表示有助于它们之间的更大相关性。
同时,也将特征A输入到卷积层中,以生成新的特征映射
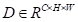
并依旧对其进行重塑为

。然后在D和S的转置之间执行矩阵乘法,并将结果重塑为
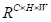
。最后,将其乘以比例系数α,并对特征A执行逐元素求和运算,以获得最终输出
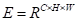
,如下所示

其中α初始化为0,并逐渐分配更多权重,且由此式可以推断出,每个位置处的结果特征E是所有位置上的特征和原始特征的加权和。因此,通过全局上下文视图,并根据空间注意力图选择性地聚合上下文,使得相似的语义特征得到了增强,从而提高了类内紧凑性和语义一致性。
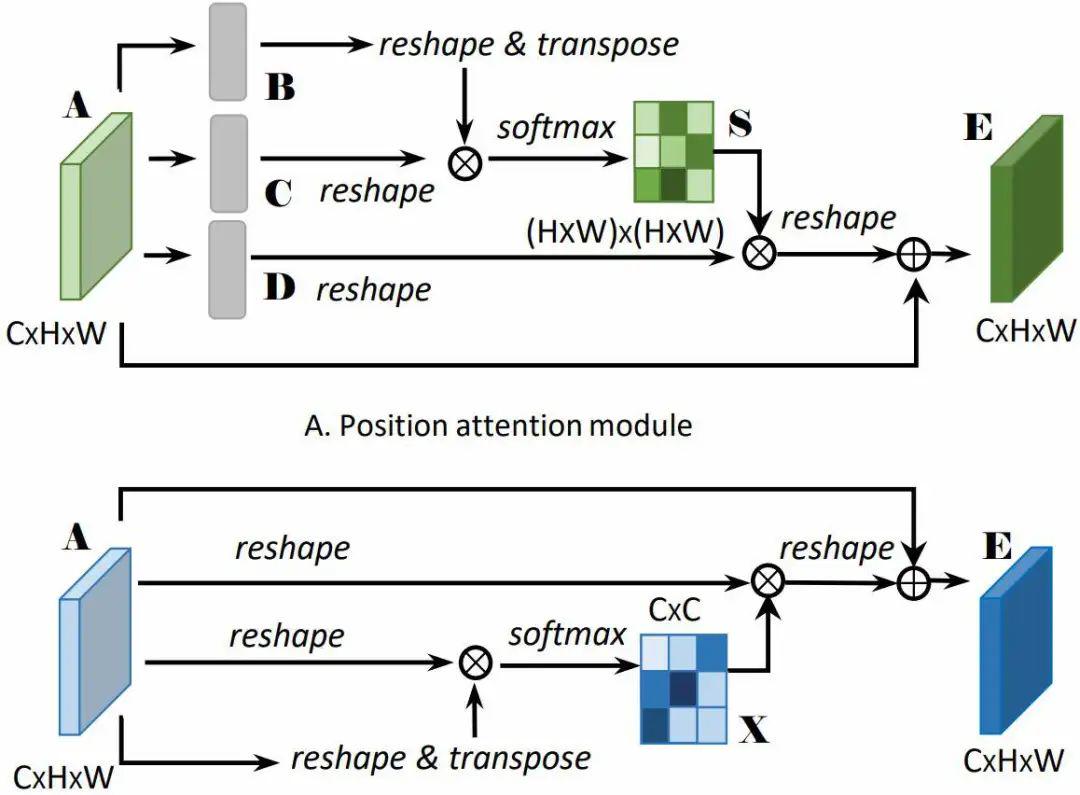
图3 空间注意力模块
2.2 通道注意力模块
高级特征的每个通道图都可以被视为一个特定类的响应,不同的语义响应彼此关联。通过利用通道图之间的相互依赖性,可以强调相互依赖的特征图,并改进特定语义的特征表示。
通道注意力模块如图3所示。与空间注意力模块不同,直接从原始特征
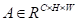
计算通道注意力图
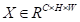
,即先将A重塑为
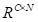
,然后让A和A的转置之间进行矩阵相乘。最后,应用softmax层来获得通道注意力映射
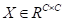
:
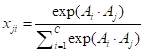
其中
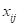
是计算第i个通道对第j个通道的影响。此外,在X和a的转置之间进行矩阵乘法,并将其结果重塑为
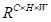
。然后,将结果乘以比例参数β,并与a执行逐元素求和运算,以获得最终输出
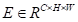
:

其中Β是从0逐渐开始学习权重。该式表明每个通道的最终特征是所有通道的特征和原始特征的加权和,也就是能够对特征图之间的长距离语义依赖性进行了建模,有利于提高特征的可分辨性。
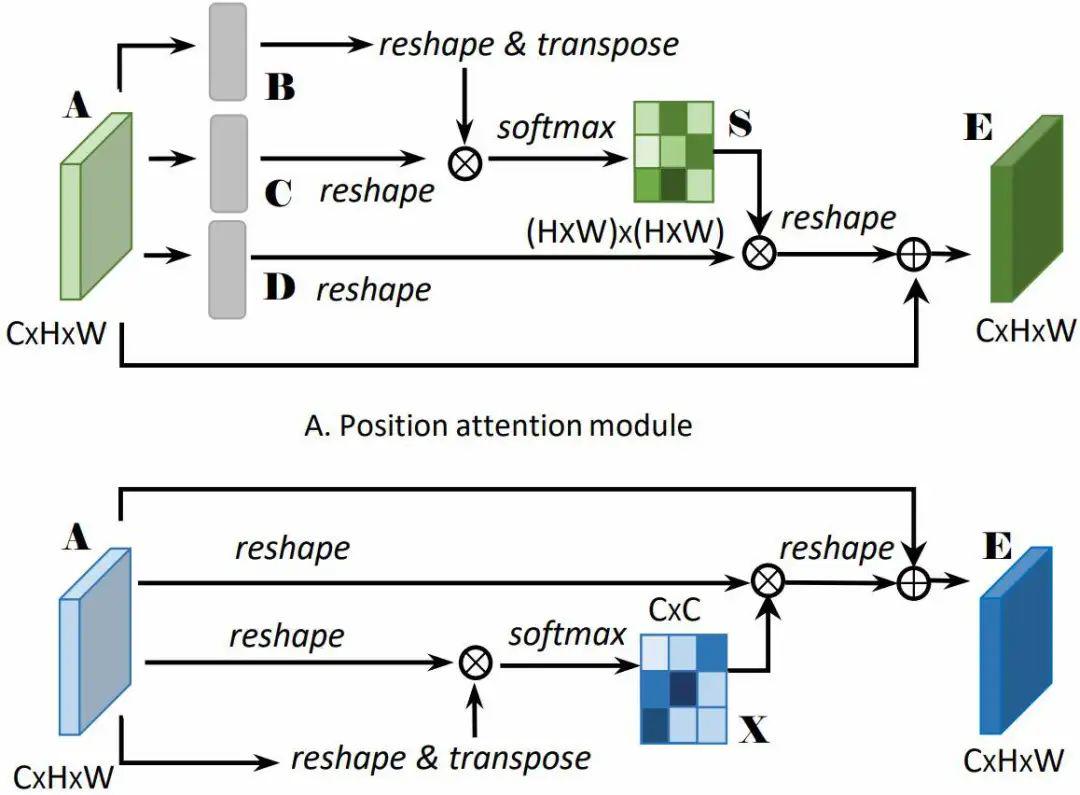
图4 通道注意力模块
为了充分利用长程上下文信息,通过卷积层变换两个注意力模块的输出,并执行元素和以实现特征融合。最后,跟随卷积层以生成最终预测图。该注意力模块简单,可以直接插入现有的FCN等框架中来有效增强特征表示,且不会增加太多参数。
3、柔性注意力
柔性注意力通过捕获不同通道特征图之间的特征依赖关系,计算所有通道特征图的加权值,进行显式地建模特征通道之间地相关性。
结构如图5所示,对于输入任意的HxWxC的特征层F,然后分别进行空间的全局平均池化和最大池化,池化大小为HxW,得到两个1x1xC的通道描述行向量Favg和Fmax。共享两个全连接层(Total Fully Connected,TFC),采用Relu激活函数,拟合通道之间的复杂相关性。再将得到的两个通道描述行向量相加,经过Sigmoid激活函数得到1x1xC的特征权重向量w,将原始的特征层和特征权重向量w进行全乘操作,得到不同通道重要性不一样的特征层。在重新生成的特征图上通过滑动窗口找到感兴趣的区域,完成图像分割。
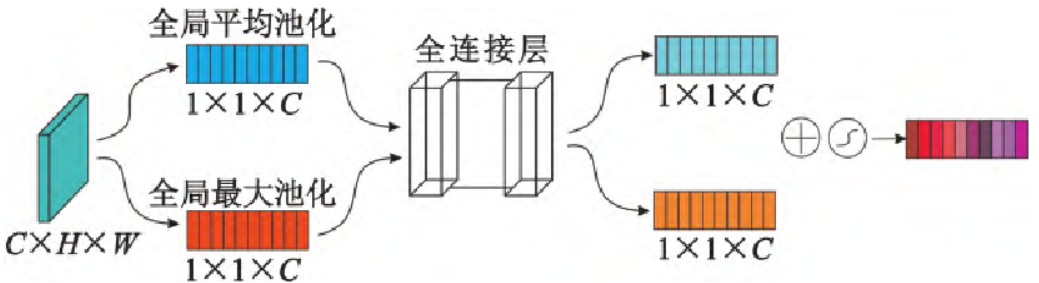
图4 柔性注意力模块
4、其他
以上是在图像中常用的注意力模块的方法,此外还有依据任务的多样性和复杂度来进行修改注意力模块,达到更轻便的架构,比如说论文里面会采用多尺度拼接、残差连接、扩张卷积、自监督机制、多头自注意力、与多样性正则化以及软、硬注意力结合等等一些方法来提高模型性能。
版权归原作者 深蓝学院 所有, 如有侵权,请联系我们删除。