
AI智能问答系统
AI智能问答系统是一种使用人工智能技术来回答用户提出的问题的系统。该系统可以理解自然语言输入,分析问题的语义和意图,并根据预先定义的知识库或学习过程中积累的知识,提供相应的答案或建议。AI智能问答系统通常包含以下组件:
- 自然语言处理(NLP)模块:用于将自然语言问题转化为计算机可处理的形式,并提取问题的语义和意图。
- 知识库:包含各种领域的知识和信息,如百科全书、专业数据库、文档等。知识库可以通过手动编写、自动抽取、学习等方式生成。
- 推理引擎:用于根据问题和知识库之间的关系,推理出最可能的答案或建议。
- 用户接口:用于与用户交互,接收用户的问题,并展示答案或建议。
AI智能问答系统在各种领域中都有广泛的应用,如客服、教育、医疗、金融等。例如,在客服领域,可以使用AI智能问答系统来自动回答常见问题,从而降低客服人员的负担;在教育领域,可以使用AI智能问答系统来解答学生的疑问,从而提高教学效果;在医疗领域,可以使用AI智能问答系统来提供医疗建议和诊断辅助等服务。
基础概念
1. AI模型
在人工智能领域中,模型通常是指一个数学函数或算法,用于完成某种特定的任务。模型可以接受输入数据,对其进行处理并生成输出结果。人工智能中的模型可以分为多种类型,例如监督学习模型、无监督学习模型、强化学习模型等。每种类型的模型都有其独特的特点和应用场景。
AI模型是一种使用机器学习算法训练出来的、能够对输入数据进行预测、分类、聚类等任务的模型。AI模型通常使用大量的数据进行训练,并且根据训练数据的特征和样本标签来发现数据之间的模式和规律,从而能够对新的未知数据进行预测或分类。
AI模型可以使用不同的机器学习算法来训练,例如神经网络、决策树、支持向量机、随机森林等。在训练模型时,需要选择合适的算法、调整模型的超参数,并进行交叉验证和模型评估,以获得最佳的模型性能和准确度。
AI模型可以应用于各种领域,如自然语言处理、图像处理、语音识别、人脸识别、推荐系统、金融风控等。例如,在自然语言处理中,可以使用AI模型对文本进行情感分析、关键词提取、文本分类等任务;在图像处理中,可以使用AI模型对图像进行分类、检测、分割等任务;在推荐系统中,可以使用AI模型对用户进行个性化推荐。
AI模型的性能和准确度取决于数据量、数据质量、算法选择、特征选择等因素。因此,在使用AI模型时,需要根据具体的应用场景和数据特点进行选择和调整,以实现更好的性能和效果。
2. 向量数据
向量是由一组有序数值组成的对象,通常表示为一个列矩阵或行矩阵。向量中的每个元素表示向量在不同维度上的取值,可以用于描述物理量的大小和方向。向量在数学和计算机科学中都有广泛的应用,如代数、几何、图形学、机器学习等领域。
向量数据是由多个向量组成的数据集合,每个向量表示一个数据点的特征或属性。在向量数据中,每个向量的每个维度都可以表示数据的不同属性或特征。向量数据在各种领域中都有广泛的应用,如图像处理、自然语言处理、人脸识别、聚类分析、分类问题等。
在机器学习中,向量数据通常用于表示样本的属性或特征。例如,在分类问题中,可以使用向量数据表示每个样本的属性向量,然后使用监督学习模型对其进行分类。在聚类问题中,可以使用向量数据表示每个样本的特征向量,然后使用无监督学习模型对其进行聚类。
向量数据的每个维度可以表示不同的属性或特征,因此在处理向量数据时需要进行特征工程,即选择和提取合适的特征,以提高机器学习模型的性能和准确度。
3. 余弦相似度
余弦相似度是一种衡量两个向量之间相似度的度量方法。它衡量的是两个向量在n维空间中的夹角,范围在-1到1之间,数值越大表示两个向量越相似。余弦相似度定义为两个向量的点积除以它们的模长的乘积,即:
cos(θ) = (A·B) / (||A|| ||B||)
其中,A 和 B 表示两个向量,||A|| 和 ||B|| 分别表示它们的模长,· 表示向量的点积,θ 表示两个向量之间的夹角。余弦相似度的值越接近 1,表示两个向量越相似;值越接近 -1,表示两个向量越不相似;值接近 0,表示两个向量之间没有明显的相似度或差异。余弦相似度在机器学习中有许多应用,其中一些包括:
- 文本分类:在文本分类中,可以使用余弦相似度来计算不同文本之间的相似度。首先将文本转换为词向量表示,然后计算不同文本之间的余弦相似度,从而实现文本分类和聚类等任务。
- 推荐系统:在推荐系统中,可以使用余弦相似度来计算用户与商品之间的相似度。首先将用户和商品表示为向量,然后计算它们之间的余弦相似度,从而推荐与用户兴趣相似的商品。
- 图像处理:在图像处理中,可以使用余弦相似度来计算不同图像之间的相似度。将图像表示为向量,然后计算它们之间的余弦相似度,从而实现图像检索、图像分类等任务。
- 自然语言处理:在自然语言处理中,可以使用余弦相似度来计算不同文本之间的相似度。将文本表示为向量,然后计算它们之间的余弦相似度,从而实现文本相似度匹配、关键词提取等任务。
- 特征选择:在特征选择中,可以使用余弦相似度来计算不同特征之间的相似度。将特征表示为向量,然后计算它们之间的余弦相似度,从而实现特征选择和降维等任务。
4. 向量数据库
向量数据库是一种用于存储和查询向量数据的数据库。与传统的关系型数据库不同,向量数据库是一种针对向量数据的专门设计的数据库,它可以高效地存储和检索大规模的向量数据。
向量数据库通常使用向量索引技术来实现高效的向量检索。向量索引是一种将向量数据映射到索引结构中的技术,可以在保证检索效率的同时,支持高维向量和相似度查询等复杂查询操作。
在向量数据库中,向量数据可以是图像、文本、音频等各种形式的数据。向量数据通常以向量形式存储,每个向量表示一个数据样本的特征或属性。向量数据的维度通常很高,因此在向量数据库中,高维向量的存储和检索是一个重要的挑战。
向量数据库在许多AI应用中得到广泛应用,如图像检索、文本检索、人脸识别、语音识别等。例如,向量数据库可以用于建立图像库,实现以图搜图的功能;也可以用于建立文本库,实现以文搜文的功能。在人脸识别中,可以使用向量数据库存储人脸特征向量,以实现快速的人脸比对和识别。
5. Milvus向量数据库
Milvus是一个开源的向量搜索引擎,使用它可以在大规模数据集中进行相似性搜索。向量数据库在许多领域都有广泛的应用,包括人脸识别、推荐系统、语义搜索等等。Milvus的主要特性包括:
- 灵活性和可扩展性:Milvus可以处理PB级别的数据,并且可以与许多流行的深度学习平台(如TensorFlow、PyTorch等)进行整合。
- 高效的搜索性能:Milvus的搜索性能优于许多其他向量搜索引擎。它使用了许多高效的索引结构(如IVF_FLAT、IVF_SQ8等)来提高搜索速度。
- 易用性:Milvus提供了Python、Java、Go等多种语言的客户端,使得用户可以方便地在自己熟悉的编程环境中使用它。
6. BERT模型
BERT(Bidirectional Encoder Representations from Transformers)是一个深度学习模型,主要用于自然语言处理任务。BERT模型的关键创新之处在于它使用了Transformer结构,并且同时考虑了上下文中的所有词,因此它是双向的。BERT模型的主要特性包括:
- 双向性:与传统的单向或者双向模型不同,BERT可以同时考虑上下文中的所有词,因此它可以更好地理解语义。
- 预训练和微调:BERT先在大规模的文本数据上进行预训练,然后在特定的任务上进行微调。这种训练方式使得BERT可以在各种各样的NLP任务上都取得很好的效果,包括情感分析、问答系统、命名实体识别等等。
- Transformer结构:BERT模型基于Transformer结构,这使得它可以处理长距离的依赖关系,并且计算效率很高。
AI智能问答系统架构
深蓝色线为数据导入过程,橘黄色线为用户查询过程:
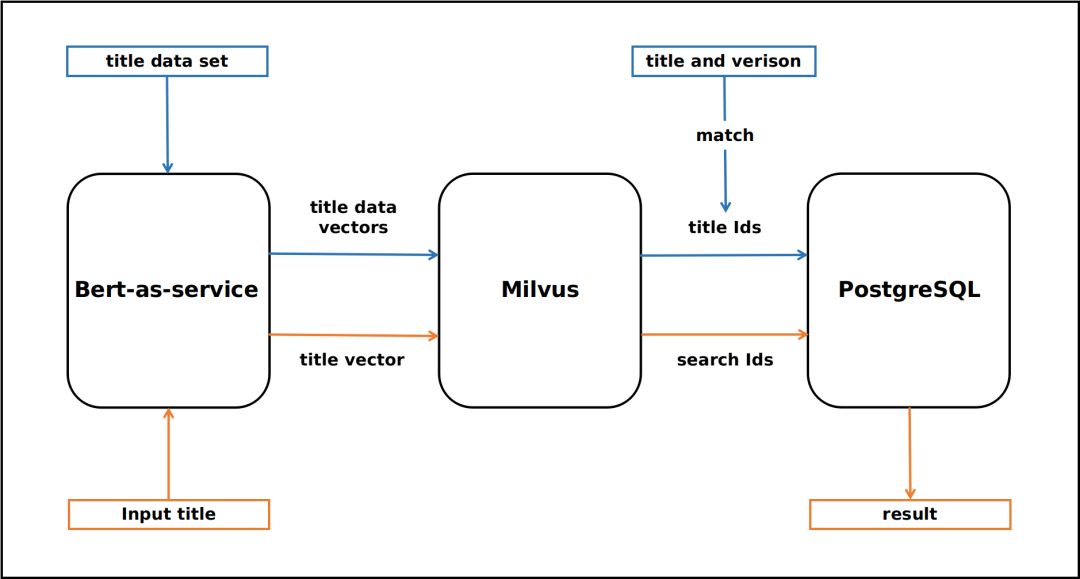
- 使用开源的bert-as-service,使用BERT做为句子编码器,将标题数据转化为固定长度为728维的特征向量,并导入Milvus库。
- 对存入Milvus库中的特征向量进行存储并建立索引,同时Milvus会给这些特征向量分配ID,将ID和对应的标题和文本存储在PostgreSQL数据库中。
- 用户输入标题,BERT将其转成特征向量。Milvus对特征向量进行相似度检索,得到相似的标题的ID,在PostgreSQL中找出ID对应的标题和文本返回。
版权归原作者 lichunericli 所有, 如有侵权,请联系我们删除。