
Redis高并发缓存架构性能优化实战
场景1: 中小型公司Redis缓存架构以及线上问题实战
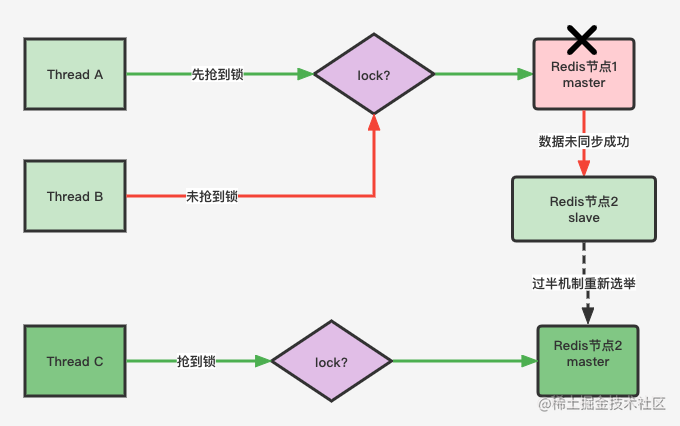
- 线程A在master获取锁之后,master在同步数据到slave时,master突然宕机(
此时数据还没有同步到slave),然后slave会自动选举成为新的master,此时线程B获取锁,结果成功了,这样会造成多个线程获取同一把锁 解决方案- 网上说RedLock能解决分布式锁失效的问题。对于RedLock实现原理是: 超过半数Redis节点加锁成功之后才能算成功,否则返回false,和Zookeeper的"ZAB"原理很类似,而且与Redis Cluster集群中解决脑裂问题的方案类似,但是RedLock方案有很大的弊端,也就是会造成Redis可用性的延迟,众所周知,Redis的AP(可用性+分区容忍性)机制,假如把Redis变成CP(一致性+分区容错性),这样肯定会牺牲一定的可用性,与Redis初衷不符合,也就是说还不如使用Zookeeper- Zookeeper具备CP机制以及实现了ZAB,能够确保某一个节点宕机,也能保证数据一致性,而且效率会比Redis高很多,更适合做分布式锁
场景2: 大厂线上大规模商品缓存数据冷热分离实战
问题:在高并发场景下,一定要把所有的缓存数据一直保存在缓存不让其失效吗- 虽然一直缓存所有数据没什么大问题,但是考虑到如果数据太多,就会一直占用缓存空间(内存资源非常宝贵),并且数据的维护性也是需要耗时的解决方案- 对缓存数据做冷热分离。在查询数据时,我们只需要在查询代码中再次更新过期时间,这样就能保证热点数据一直在缓存中,而不经常访问的数据过期了就自动从缓存中删除流程分析- 假如一个热点数据每天访问特别高,不停的查询该数据,每次查询时再次更新过期时间,那么在这个过期时间之内只要有人访问就会一直存在缓存中,这样就保证热点商品数据不会因为过期时间而从缓存中移除- 而对于不经常访问的冷门数据到了过期时间就可以自动释放了,同时也释放除了一部分缓存空间,而且当再次访问冷门数据的时候,从数据库拿到的永远是最新的数据,也减少了维护成本
场景3: 基于DCL机制解决热点缓存并发重建问题实战
DCL(双重检测锁)问题:冷门数据突然变成了热门数据,大量的请求突发性的对热点数据进行缓存重建导致系统压力暴增解决方案- 最容易想到的就是加锁-DCL机制。先查一次,缓存有数据就直接返回,没有数据,就加锁,在锁的代码块中再次先查询缓存。这样锁的目的就是为了当第一次缓存从数据库查询更新到缓存中,代码块执行完,其他线程再次进来,此时缓存中就已经存在数据了,这样就减少了查询数据库的次数
publicProductget(Long productId){Product product =null;String productCacheKey =RedisKeyPrefixConst.PRODUCT_CACHE+ productId;//DCL机制:第一次先从缓存里查数据
product =getProductFromCache(productCacheKey);if(product !=null){return product;}//加分布式锁解决热点缓存并发重建问题RLock hotCreateCacheLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX+ productId);
hotCreateCacheLock.lock();// 这个优化谨慎使用,防止超时导致的大规模并发重建问题// hotCreateCacheLock.tryLock(1, TimeUnit.SECONDS);try{//DCL机制:在分布式锁里面第二次查询
product =getProductFromCache(productCacheKey);if(product !=null){return product;}//RLock productUpdateLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);RReadWriteLock productUpdateLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX+ productId);RLock rLock = productUpdateLock.readLock();//加分布式读锁解决缓存双写不一致问题
rLock.lock();try{
product = productDao.get(productId);if(product !=null){
redisUtil.set(productCacheKey,JSON.toJSONString(product),genProductCacheTimeout(),TimeUnit.SECONDS);}else{//设置空缓存解决缓存穿透问题
redisUtil.set(productCacheKey,EMPTY_CACHE,genEmptyCacheTimeout(),TimeUnit.SECONDS);}}finally{
rLock.unlock();}}finally{
hotCreateCacheLock.unlock();}return product;}
场景4: 突发性热点缓存重建导致系统压力暴增
问题:假如当前有10w个线程没有拿到锁正在排队,这种情况只能等到获取锁的线程执行完代码释放锁后,那排队的10w个线程才能再次竞争锁。这里需要关注的问题点就是又要再次竞争锁,意味着线程竞争锁的次数可能最少>1,频繁的竞争锁对Redis性能也是有消耗的,有没有更好的办法让每个线程竞争锁的次数尽可能减少呢解决方案- 可以通过tryLock(time,TimeUnit)先让所有线程尝试获取锁- 假如获取锁的线程执行数据库查询然后将数据更新到缓存所需要的时间为1s,那么当其他线程获取锁时间结束后,会解除阻塞状态直接往下执行,然后再次查询缓存的时候发现缓存有数据了就直接返回-这样设计的好处就是把分布式锁在某些特定的场景使其"串行变并发",不过这个优化需要谨慎使用,防止超时导致的大规模并发重建问题。毕竟没有任何方案是完全解决问题的,主要是根据公司业务而定
场景5: 解决大规模缓存击穿导致线上数据库压力暴增
缓存击穿/缓存失效:可能同一时间热点数据全部过期而造成缓存查不到数据,请求就会从数据库查询,高并发情况下会导致数据库压力解决方案- 对于这个场景,可以给数据设置过期时间时,不要将所有缓存数据的过期时间设置为相同的过期时间,最好可以给每个数据的过期时间设置一个随机数,保证数据在不同的时间段过期。- 代码案例
privateIntegergenProductCacheTimeout(){//加随机超时机制解决缓存批量失效(击穿)问题returnPRODUCT_CACHE_TIMEOUT+newRandom().nextInt(5)*60*60;}
场景6: 黑客工资导致缓存穿透线上数据库宕机
缓存穿透:如果黑客通过脚本文件不停的传一些不存在的参数刷网站的接口,而这种垃圾参数在缓存和数据库又不存在,这样就会一直地查数据库,最终可能导致数据库并发量过大而卡死宕机解决方案-网关限流,Nginx、Sentinel、Hystrix都可以实现-代码层面,可以使用多级缓存,比如一级缓存采用布隆过滤器,二级缓存可以使用guava中的Cache,三级缓存使用Redis,为什么一级缓存使用布隆过滤器呢,其结构和bitmap类似,用于存储数据状态,能存大量的key布隆过滤器- 布隆过滤器就是一个大型的位数组和几个不一样的无偏Hash函数.当布隆过滤器说某个值存在时,这个值可能不存在,当说不存在时,那就肯定不存在-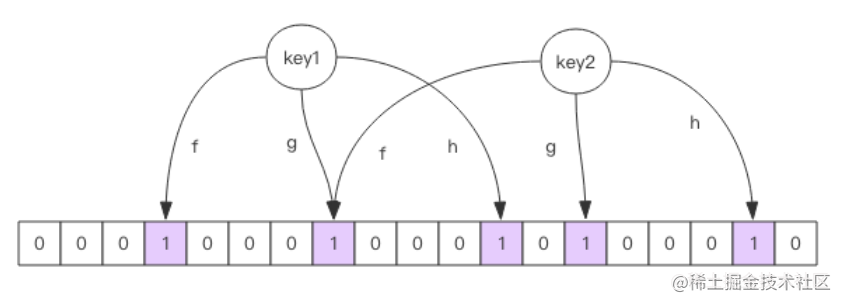
场景7: 大V直播带货导致线上商品系统崩溃原因分析
问题:这种场景可能是在某个时刻把冷门商品一下子变成了热门商品。因为冷门的数据可能在缓存时间过期就删除,而此时刚好有大量请求,比如直播期间推送一个商品连接,假如同时有几十万人抢购,而缓存没有的话,意味着所有的请求全部达到了数据库中查询,而对于数据库单节点支撑并发量也就不到1w,此时这么大的请求量,肯定会把数据库整宕机(这种场景比较少,但是小概率还是会有)解决方案- 可以通过tryLock(time,TimeUnit)先让所有线程尝试获取锁- 假如获取锁的线程执行数据库查询然后将数据更新到缓存所需要的时间为1s,那么当其他线程获取锁时间结束后,会解除阻塞状态直接往下执行,然后再次查询缓存的时候发现缓存有数据了就直接返回-这样设计的好处就是把分布式锁在某些特定的场景使其"串行变并发",不过这个优化需要谨慎使用,防止超时导致的大规模并发重建问题。毕竟没有任何方案是完全解决问题的,主要是根据公司业务而定
场景8: Redis分布式锁解决缓存与数据库双写不一致问题实战
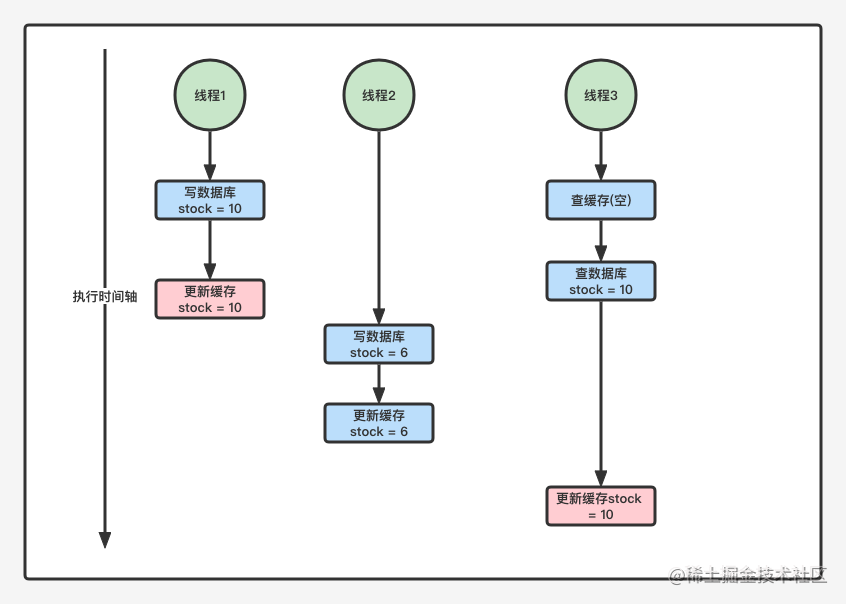
解决方案-重入锁保证并发安全。通常说在分布式锁中再加一把锁,锁太重,性能不是很好,还有优化空间-分布式读写锁(ReadWriteLock),实现机制和ReentranReadWriteLock一致,适合读多写少的场景,注意读写锁的key得一致-使用canal通过监听binlog日志及时去修改缓存,但是引入中间件,增加系统的维护度Lua脚本设置读写锁local mode = redis.call('hget', KEYS[1],'mode');if(mode ==false)then redis.call('hset', KEYS[1],'mode','read'); redis.call('hset', KEYS[1], ARGV[2],1); redis.call('set', KEYS[2]..':1',1); redis.call('pexpire', KEYS[2]..':1', ARGV[1]);redis.call('pexpire', KEYS[1], ARGV[1]);returnnil;end;if(mode =='read')or(mode =='write'and redis.call('hexists', KEYS[1], ARGV[3])==1)thenlocal ind = redis.call('hincrby', KEYS[1], ARGV[2],1);local key = KEYS[2]..':'.. ind;redis.call('set', key,1); redis.call('pexpire', key, ARGV[1]); redis.call('pexpire', KEYS[1], ARGV[1]);returnnil;end;return redis.call('pttl', KEYS[1]);ReadWriteLock代码案例@TransactionalpublicProductupdate(Product product){Product productResult =null;//RLock productUpdateLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + product.getId());RReadWriteLock productUpdateLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX+ product.getId());// 添加写锁RLock writeLock = productUpdateLock.writeLock();//加分布式写锁解决缓存双写不一致问题 writeLock.lock();try{ productResult = productDao.update(product); redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE+ productResult.getId(),JSON.toJSONString(productResult),genProductCacheTimeout(),TimeUnit.SECONDS);}finally{ writeLock.unlock();}return productResult;}publicProductget(Long productId){Product product =null;String productCacheKey =RedisKeyPrefixConst.PRODUCT_CACHE+ productId;//从缓存里查数据 product =getProductFromCache(productCacheKey);if(product !=null){return product;}//加分布式锁解决热点缓存并发重建问题RLock hotCreateCacheLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX+ productId); hotCreateCacheLock.lock();// 这个优化谨慎使用,防止超时导致的大规模并发重建问题// hotCreateCacheLock.tryLock(1, TimeUnit.SECONDS);try{ product =getProductFromCache(productCacheKey);if(product !=null){return product;}//RLock productUpdateLock = redisson.getLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);RReadWriteLock productUpdateLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX+ productId);// 添加读锁RLock rLock = productUpdateLock.readLock();//加分布式读锁解决缓存双写不一致问题 rLock.lock();try{ product = productDao.get(productId);if(product !=null){ redisUtil.set(productCacheKey,JSON.toJSONString(product),genProductCacheTimeout(),TimeUnit.SECONDS);}else{//设置空缓存解决缓存穿透问题 redisUtil.set(productCacheKey,EMPTY_CACHE,genEmptyCacheTimeout(),TimeUnit.SECONDS);}}finally{ rLock.unlock();}}finally{ hotCreateCacheLock.unlock();}return product;}
场景9: 大促压力暴增导致分布式锁串行争用问题优化
解决方案- 可以采用分段锁,和JDK7的ConcurrentHashMap的实现原理很类似,将一个锁,分成多个锁,比如lock,分成lock_1、lock_2…- 然后将库存平均分摊到每把锁,这样做的目的是分摊分布式锁的压力,本来只有一个锁,意味着所有的线程进来只能一个线程获取到锁,如果分摊为10把锁,那么同一时间可以有10个线程同时获取到锁对同一个商品进行操作,也就意味着在同等环境下,分段锁的效率比只用一个锁要高得多
场景10: 利用多级缓存解决Redis线上集群缓存雪崩问题
缓存雪崩:缓存支撑不住或者宕机,然后大量请求涌入数据库。解决方案-网关限流,Nginx、Sentinel、Hystrix都可以实现-代码层面,可以使用多级缓存,比如一级缓存采用布隆过滤器,二级缓存可以使用guava中的Cache,三级缓存使用Redis,为什么一级缓存使用布隆过滤器呢,其结构和bitmap类似,用于存储数据状态,能存大量的key
场景11: 一次微博明显热点事件导致系统崩溃原因分析
- 问题: 比如微博上某一天某个明星事件成为了热点新闻,此时很多吃瓜群众全部涌入这个热点,如果并发每秒达到几十万甚至上百万的并发量,但是Redis服务器单节点只能支撑并发10w而已,那么可能因为这么高的并发量导致很多请求卡死在那,要知道我们其他业务服务也会用到Redis,一旦Redis卡死,就会影响到其他业务,导致整个业务瘫痪,这就是典型的
缓存雪崩问题 解决方案: 参考场景10
场景12: 大厂对热点数据处理方案
**
解决方案
**
- 如果按照
场景10的方案去实现,需要考虑数据一致性问题,这样就不得不每次对数据进行增加、删除、更新都要立马通知其他节点更新数据,能做到及时更新数据的方案可能就是:Redis发布/订阅、MQ等 - 虽然说这些方案实现也可以,但是不可避免的我们需要再维护相关的中间件,提高了维护成本
- 目前大厂对于热点数据专门会有一个类似于
热点缓存系统来维护,所有的web应用只需要监听这个系统,只要有热点时,直接更新缓存,这样既能减少代码耦合,还能更好的维护热点数据。 那么热点数据来源怎么获取呢?可以在设计查询的接口使用类似于Spring AOP的方式,每次查询就把数据传送到热点数据,一般大厂都会有数据分析岗位,根据热点规则将数据分类
本文转载自: https://blog.csdn.net/qq_41804775/article/details/136287466
版权归原作者 枫吹过的柚 所有, 如有侵权,请联系我们删除。
版权归原作者 枫吹过的柚 所有, 如有侵权,请联系我们删除。