
大多数 AI 应用都从一个简单的演示开始:用户提问、LLM 给出回答,所有人都觉得很厉害。
但是应用需要检索文档、调用工具、处理故障、路由请求、记住历史操作,还要在关键决策节点引入人工审核。这时这个聊天机器人已经变成了一套工作流。
很多 AI 项目就卡在这个转变上,演示和生产系统之间的差距,通常不在于模型本身而在于背后的架构。
LangChain 和 LangGraph 是目前构建现代 AI 应用最广泛使用的两个框架。两者结合提供了构建可靠、可扩展、易维护 AI 系统所需的核心构件。
如果你在 2026 年构建 AI Agent,在写下一个工作流之前,先把这些概念搞清楚。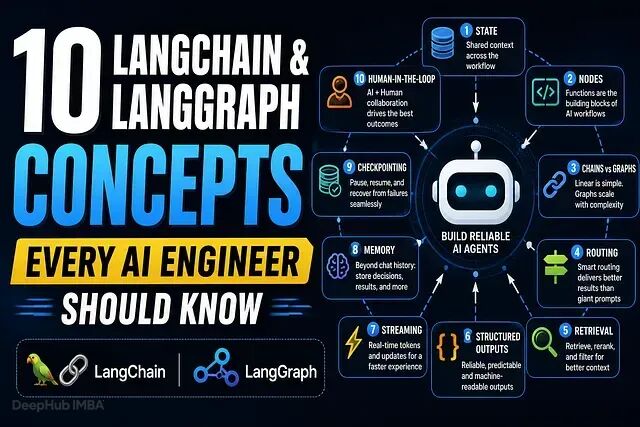
1、状态(State)是每个 Agent 的基础
为什么生产级 Agent 需要共享状态,而不是孤立的 Prompt。初学者脑海中的 AI Agent 通常长这样:
用户输入
↓
LLM
↓
响应
生产级 Agent 完全不同——它们在整个工作流中持续维护状态。
以一个客户支持 Agent 为例:
from typing import TypedDict
class SupportState(TypedDict):
ticket_id: str
customer_message: str
customer_tier: str
retrieved_articles: list
sentiment_score: float
draft_response: str
escalation_required: bool
final_response: str
工作流推进过程中,不同节点会不断更新这个共享状态:
{
"ticket_id": "TKT-9012",
"customer_message": "My payment failed twice",
"customer_tier": "Enterprise",
"retrieved_articles": [
"Payment Retry Policy",
"Credit Card Validation"
],
"sentiment_score": 0.91,
"draft_response":
"Please retry the payment...",
"escalation_required": False
}
没有状态,Agent 就没有上下文,调试无从下手,多步骤工作流也极易崩溃。有了状态,每一步都能感知之前发生了什么,整个系统才有可预测性。
把状态理解为整个工作流的共享记忆。
2、节点(Node)只是函数
很多人以为 AI Agent 是某种神奇框架驱动的,实际上大多数节点就是普通函数。
一个检索节点:
def retrieve_documents(state):
docs = vector_store.similarity_search(
state["user_query"],
k=5
)
return {
"retrieved_docs": docs
}
一个重排序节点:
def rerank_documents(state):
reranked = reranker.rank(
query=state["user_query"],
docs=state["retrieved_docs"]
)
return {
"retrieved_docs": reranked[:3]
}
一个生成节点:
def generate_answer(state):
response = llm.invoke(
state["retrieved_docs"]
)
return {
"draft_answer": response
}
把它们串起来:
检索
↓
重排序
↓
生成
↓
验证
每个节点只做一件事。力量来自编排,而不是单个节点的复杂度。
3、 链(Chain)与图(Graph)
很多 LangChain 应用从链开始构建:
Prompt
↓
LLM
↓
解析器
↓
响应
对于简单直接的流程,链完全够用。但当工作流中出现多个 Agent、条件分支、人工审批、重试逻辑或长时间运行的任务时,线性结构就开始力不从心了。
图能自然地处理这些场景:
路由器
│
┌────────┴────────┐
▼ ▼
研究 Agent 支持 Agent
│ │
└────────┬────────┘
▼
最终响应
一个 ERP 迁移助手的工作流可能需要:分析需求、生成测试用例、验证覆盖率、将问题路由给对应专家,最后请求人工审批。这个流程天然是图状的,强行套进线性链只会越写越难维护。
系统越复杂,图就越不可或缺。
4、路由(Routing)优于超长 Prompt
最常见的一个失误是把一个助手塑造成什么都懂的全才:
你是一个账单专家、
技术支持工程师、
销售代表、
产品专家
和合规顾问……
这种写法很难扩展。更好的方案是路由:
def classify_request(state):
query = state["user_query"]
if "billing" in query:
return "billing_agent"
if "error" in query:
return "technical_agent"
if "pricing" in query:
return "sales_agent"
return "general_agent"
工作流:
用户请求
│
▼
路由
│
┌────┼────┐
▼ ▼ ▼
技术 账单 销售
更短的 Prompt 意味着更高的准确率、更低的 Token 成本,以及更容易维护和预测的输出。最好的 AI 系统通常是一支专家团队,而不是一个试图解决所有问题的万能角色。
5、检索不只是向量搜索
很多人对 RAG 的认知停留在:
向量搜索
↓
LLM
↓
答案
这在演示中够用,生产系统则需要额外的层:
检索
↓
重排序
↓
过滤
↓
生成
具体来说:
docs=vector_store.search(
query,
k=20
)
reranked_docs=reranker.rank(
query,
docs
)
top_docs=reranked_docs[:5]
向量数据库可能返回 20 篇相关文档,但其中真正包含所需信息的可能只有 5 篇。重排序正是为了解决这个问题,它对答案质量的影响远比多数人预估的要大。
一个拥有 1000 万文档的企业知识库,在数据交给 LLM 之前,往往已经经过了混合搜索、元数据过滤、重排序和上下文压缩等多道处理。好的 RAG 系统,首先是一个检索系统,其次才是 AI 系统。
6、结构化输出(Structured Outputs)避免代价高昂的故障
每个 AI 工程师都碰到过类似的情况:
Prompt 里写着"返回有效的 JSON",模型回来的却是:
{
"priority": "high"
"category": "billing"
}
少了一个逗号,解析器崩溃,整个工作流失败。
换成结构化输出:
from pydantic import BaseModel
class TicketClassification(BaseModel):
category: str
severity: str
assigned_team: str
confidence_score: float
生成经过验证的输出:
result = llm.with_structured_output(
TicketClassification
).invoke(ticket_text)
结果:
{
"category": "Payment",
"severity": "High",
"assigned_team": "Billing",
"confidence_score": 0.94
}
只要有其他系统消费 AI 的输出,Schema 就应该是强制要求,而不是可选项。
7、流式输出(Streaming)改变用户对速度的感知
用户不喜欢等待。等 15 秒屏幕上什么都没有;或者响应立刻开始出现,逐字流入。两者的总耗时可能完全相同,但用户几乎总是偏向后者。
流式输出就是为了实现这种体验:
for chunk in model.stream(prompt):
print(chunk)
对于更复杂的工作流,可以在各阶段主动推送进度:
yield "正在分析需求……"
yield "正在检索文档……"
yield "正在生成响应……"
yield "正在验证结果……"
yield final_response
比如说批量生成数百个迁移测试用例的场景——实时显示进度,用户的满意度会有明显差异。感知性能往往比实际性能更重要。
8、记忆(Memory)不只是对话历史
大多数开发者把记忆等同于聊天记录:
messages= [...]
真正的 Agent 需要操作层面的记忆(operational memory)。以一个编程 Agent 为例:
{
"repository": "payments-api",
"modified_files": [
"payment.service.ts",
"retry.handler.ts"
],
"failed_tests": [
"payment_retry.spec.ts"
],
"last_fix_attempt": "...",
"pull_request_url": "..."
}
Agent 记住了之前的决策、工具的输出、失败的执行、检索到的文档,以及当前仓库的状态。有了这些,它才能在多个步骤中保持连贯的判断,而不是每次都从零开始。记忆把孤立的交互变成了真正意义上的智能工作流。
9、检查点(Checkpointing)支撑长时间运行的工作流
真实系统会出故障:模型超时、API 不可用、人工审核需要几个小时甚至几天。
没有检查点,发生故障只能重头来过;有了检查点,可以从中断处继续:
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
graph = workflow.compile(
checkpointer=checkpointer
)
稍后恢复时:
graph.invoke(
input_data,
config={
"thread_id": "loan-123"
}
)
以贷款审批流程为例:
文件收集
↓
检查点
↓
风险评估
↓
检查点
↓
人工审批
↓
最终决策
这个流程可能横跨数小时乃至数天。检查点的存在,保证了中途的任何故障都不会让已有进度付之一炬。
10、人机协作(Human-in-the-Loop)才是 AI 的真正未来
关于 AI Agent 最常见的误解之一,是认为它们应该完全自主运行。大多数企业系统实际上需要人工监督。
defapproval_node(state):
ifstate["risk_score"] >0.8:
return"human_review"
return"auto_approve"
工作流:
AI 分析
↓
风险评估
↓
人工审核
↓
继续工作流
贷款审批、法律合同分析、ERP 迁移验证、医疗建议、财务审计——这些场景里,人工介入都是常态,而不是例外。最成功的 AI 系统不是取代人类,而是帮助人类更快地做出更好的决策。
总结
构建 AI 系统过程中,一个反复得到印证的结论是:可靠的 AI 应用很少是靠模型决定的,决定因素是工作流设计。
- 状态(State)
- 节点(Node)
- 图(Graph)
- 路由(Routing)
- 检索(Retrieval)
- 结构化输出(Structured Outputs)
- 记忆(Memory)
- 检查点(Checkpointing)
- 人工审核
对 AI 系统的提升,掌握这些概念远比没完没了地调 Prompt 更有效。模型会持续演进,好的架构会持续重要。如果你在 2026 年构建 AI Agent,从这里开始。
作者:Sachin Kasana