
本文来源公众号“OpenCV与AI深度学习****”,仅用于学术分享,侵权删,干货满满。
原文链接:YOLOv8自定义数据集训练实现火焰和烟雾检测

YOLOv8一个令人惊叹的物体检测人工智能模型。与 YOLOv5 及之前的版本不同,您不需要克隆存储库、设置需求或手动配置模型。使用 YOLOv8,您只需安装 Ultralytics,我将向您展示如何使用一个简单的命令。YOLOv8 通过引入新的功能和改进,增强了早期 YOLO 版本的成功,从而提高了性能和多功能性。由于其速度、精度和用户友好的设计,它成为对象识别和跟踪、实例分割、图像分类和姿势估计等各种任务的理想选择。您可以在YOLOv8的官方网站上找到更多信息。
https://github.com/ultralytics/ultralytics/
我们可以使用这个模型执行三种任务。
(1) 目标检测
(2) 图像分割
(3) 图像分类
目标检测
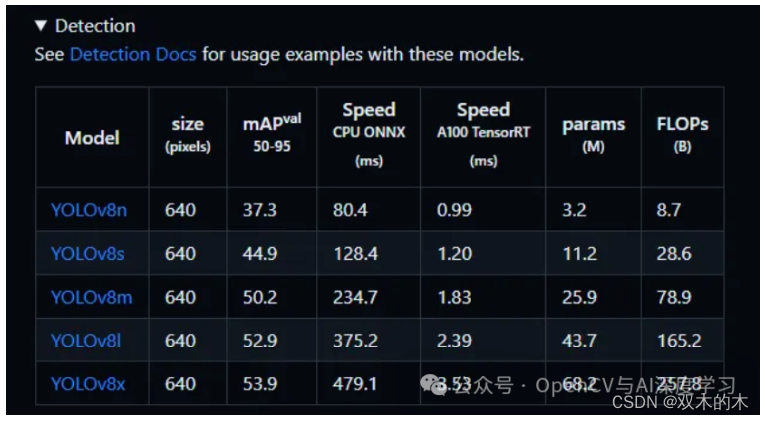
我们可以使用下表中的任何一种模型进行物体检测:
图像分割
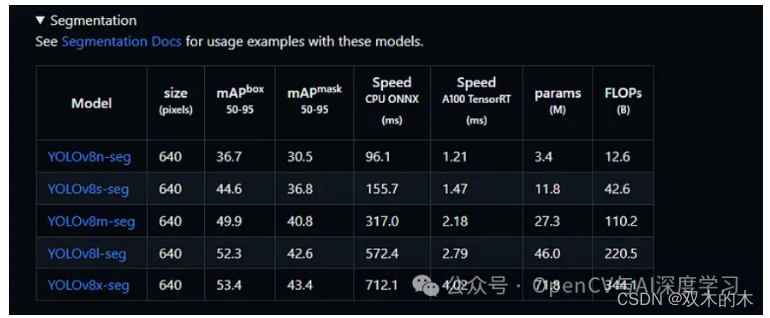
也可以使用下表中的任何一种模型进行图像分割:
图像分类
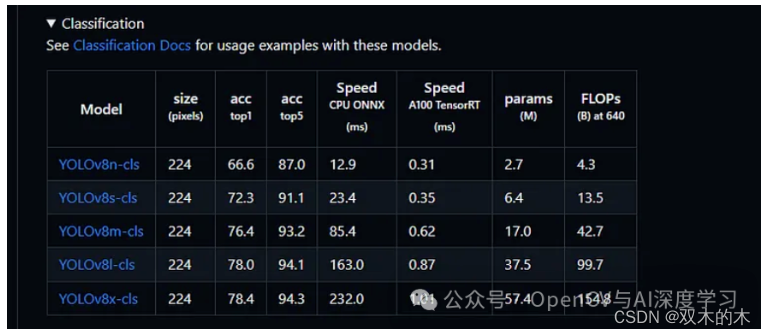
也可以使用下表中的任何一种模型进行图像分类:
现在我将使用Google colab来进行训练。
安装之前我需要连接我的 GPU:
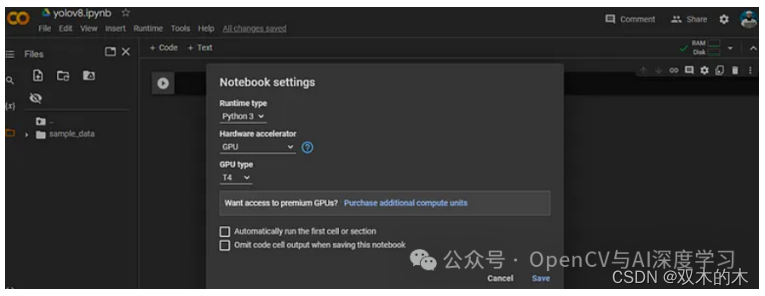
在上图中选择 GPU 作为硬件加速器后单击“保存”按钮。
挂载 Google 驱动器,以便 colab 可以访问其文件。
在上面的屏幕中选择安装按钮后,单击“连接到 Google 云端硬盘”按钮。现在我们的笔记本已经连接到Google Drive了。
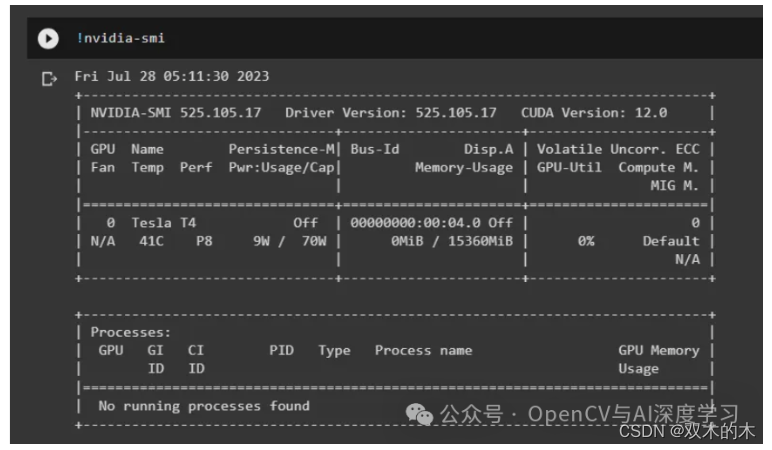
要测试我们是否有 GPU,请在 colab 上编写以下命令。
如果你成功获取GPU可以看到下面的提示:
数据集已上传至 Google Drive,链接如下:
https://drive.google.com/drive/folders/1jBxZcTBfDOZqjjbL6hm80IJV8qOG5pBQ?usp=sharing&source=post_page-----d9d0696fdcd7--------------------------------
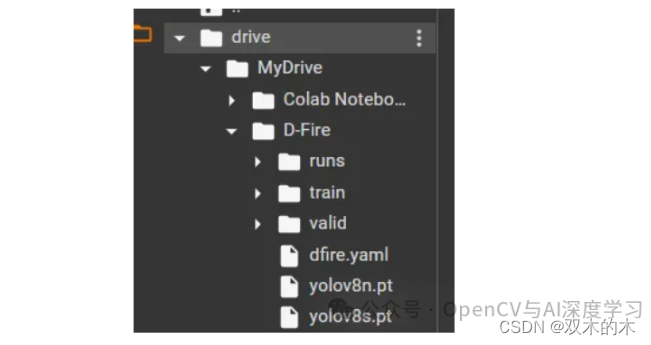
放置文件如下 :
使用以下命令安装 ultralytics
我们将通过下面给出的单个命令安装 YOLOv8 的所有要求和依赖项:
现在安装成功了。
**它有三种模式:**
(1) 训练模式——表示为mode = train
(2) 验证模式——表示为mode = val
(3) 预测模式——表示为 mode = Predict
**它执行三种任务:**
(1) 检测——表示为task = detect
(2) 分割——表示为task = segment
(3) 分类——表示为task =c lassify
运行以下命令测试是否正常:
使用 YOLOv8 检测图像:
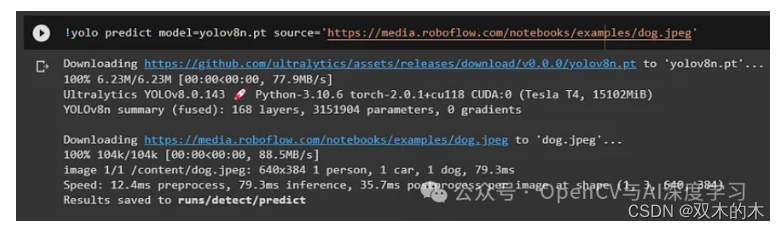
首先它会下载模型和图像,然后分别预测图像。在这里,我们从检测表中取出第一个模型——yolov8n。
在这里,您可以在上面的屏幕中看到预测结果。
开始定制训练:
我已经准备好数据集,已上传到 Google Drive,链接如下:
https://drive.google.com/drive/folders/1jBxZcTBfDOZqjjbL6hm80IJV8qOG5pBQ?usp=sharing&source=post_page-----d9d0696fdcd7--------------------------------

完整代码和笔记:
https://colab.research.google.com/drive/16D08IHyevp-FNuExYZXVEvGagJHiiAwY?source=post_page-----d9d0696fdcd7--------------------------------#scrollTo=1xxEa4LxQS_F
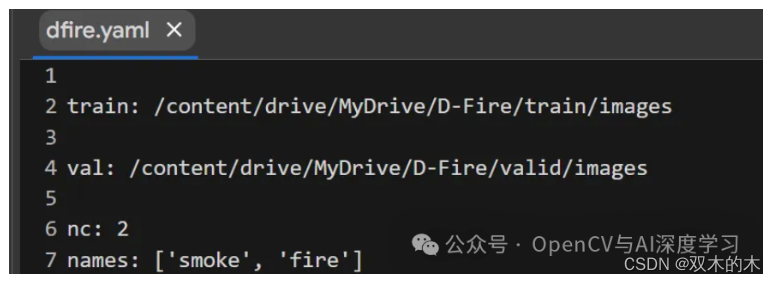
配置 dfire.yaml 文件:
** 上面代码的解释**
当然!该data.yaml文件包含有关用于机器学习任务中的训练和验证(可能用于对象检测或分类)的数据集的重要信息。让我们分解一下您提供的代码:
train: /content/drive/MyDrive/D-fire/train/images:此行指定包含训练图像的目录的路径。该模型将在训练过程中使用这些图像来学习和提高其检测或分类对象的能力。
val: /content/drive/MyDrive/D-fire/valid/images:此行指定包含验证图像的目录的路径。验证图像用于评估模型在训练后对新的、未见过的数据的泛化程度。验证有助于防止过度拟合,即模型会记住训练数据,但在新数据上表现不佳。
nc: 2:此行设置数据集中的类(或类别)数量。在本例中,有两个类别:“烟”和“火”。这意味着模型正在接受训练以检测图像中的烟雾或火灾。
names: ['smoke', 'fire']:此行提供数据集中类的名称。列表中的每个元素对应一个类标签。在本例中,列表包含两个元素:“smoke”和“fire”。这些标签用于识别和区分模型正在学习检测或分类的对象。
总之,该data.yaml文件指定训练和验证图像目录的文件路径、数据集中的类数量以及这些类的名称(在本例中为“smoke”和“fire”)。这些信息对于模型训练过程至关重要,使模型能够从训练数据中学习并概括其知识,以在验证和推理过程中检测和分类新的、看不见的图像中的“烟”和“火”。
** 安装到 Google 云端硬盘**

** **上面代码的解释
您发布的代码片段用于将 Google Drive 安装到 Colab 环境。让我们一步步分解:
from google.colab import drive:此行从 Google Colab 导入必要的模块,允许您与 Google Drive 交互。
drive.mount('/content/drive'):这一行是代码的核心部分。它会启动将 Google Drive 安装到 Colab 虚拟机的过程。当您运行此行时,它会提示您授权访问您的 Google 云端硬盘。
单击提供的链接在浏览器中打开新选项卡。
选择您想要与 Colab 连接的 Google 帐户。
单击“允许”授予 Colab 访问您的 Google 云端硬盘的权限。
复制提供的授权码。
将代码粘贴到 Colab 笔记本的输入字段中,然后按 Enter。
完成这些步骤后,您的 Google Drive 将安装在 Colab 环境中的路径“/content/drive”。这意味着您可以直接从 Colab 访问 Google Drive 文件并与之交互。例如,如果您的 Google 云端硬盘中有一个文件,您可以使用路径“/content/drive/MyDrive/”引用该文件,后跟该文件在 Google 云端硬盘目录结构中的位置。
通过安装 Google Drive,您可以轻松读写文件、访问数据集以及在不同 Colab 会话之间保存模型检查点或其他重要文件,而无需在每次使用该平台时重新上传它们。
** 切换到当前工作目录**

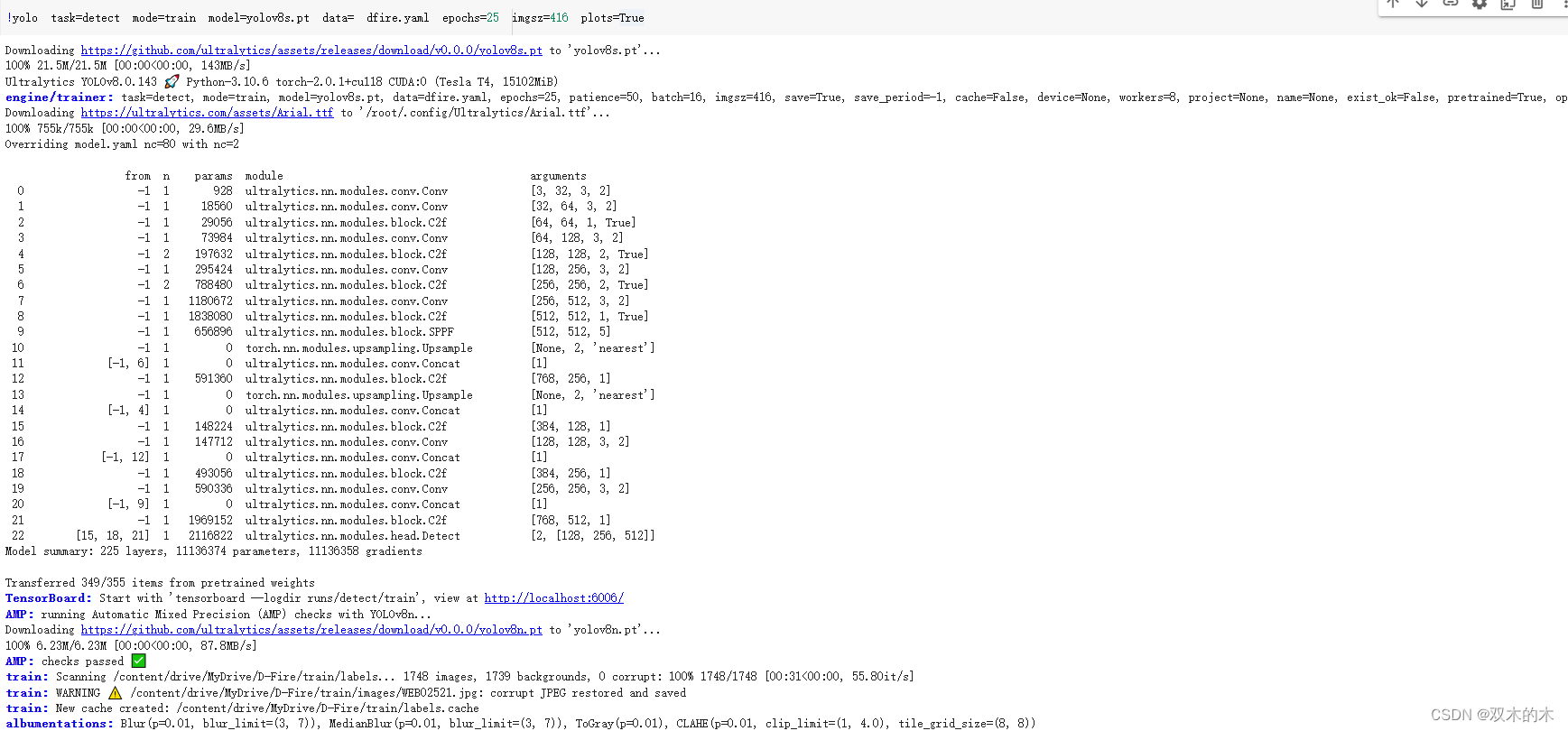
使用以下命令训练 YOLOv8:
!yolo task=detect mode=train model=yolov8s.pt data= dfire.yaml epochs=25 imgsz=416 plots=True
运行效果如下:
.........
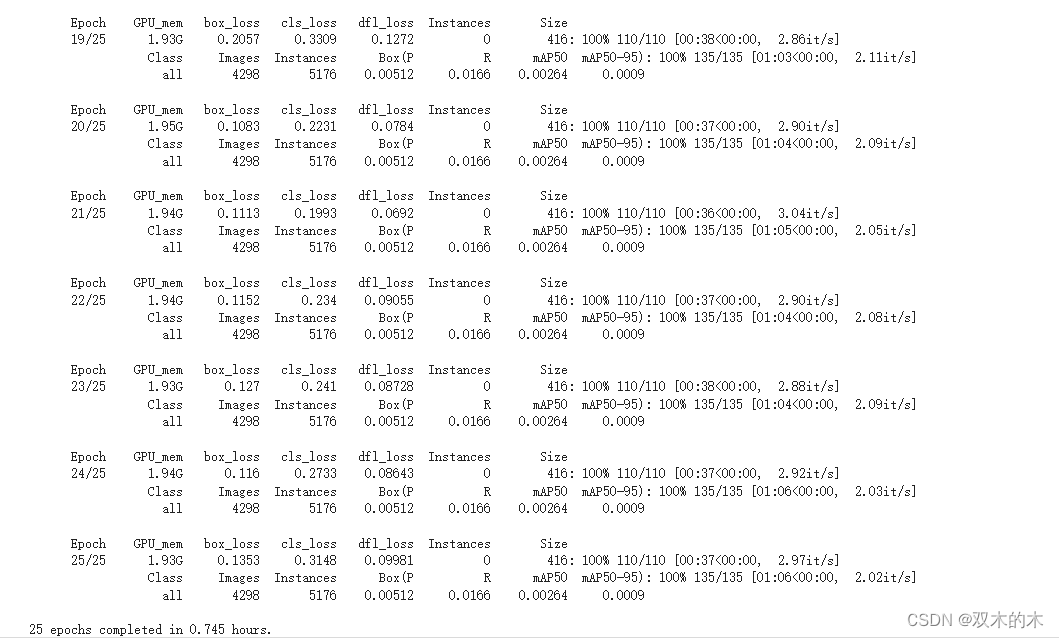
这里,data = dfire.yaml
在dfire.yaml文件中,我提到了所有图像路径。因此它会自动从该文件夹中获取图像和标签。
** 下面命令的解释**

!yolo:这似乎是与YOLO(You Only Look Once)算法相关的命令或代码片段。
task=detect:这表明正在执行的任务是对象检测,这意味着算法正在用于识别和定位图像中的对象。
mode=train:这指定模型处于训练模式,这意味着它将从数据集中学习以提高其对象检测能力。
model=yolov8s.pt:所使用的模型名为“yolov8s.pt”。YOLOv8 可能是 YOLO 算法的一个版本,“.pt”扩展名可能表明它是一个 PyTorch 模型文件。
data=dfire.yaml:用于训练的数据在名为“dfire.yaml”的文件中指定。该文件可能包含有关数据集的信息,例如图像的路径和相应的对象标签。
epochs=25:在训练过程中,模型将遍历数据集 25 次以从数据中学习。
imgsz=416:将图像大小调整为 416x416 像素,然后将其输入模型进行训练。
plots=True:这意味着将在训练过程期间或之后生成图表或可视化,可能是为了分析模型的性能。
总之,此命令可能使用“dfire.yaml”中定义的数据集执行对象检测模型 (YOLOv8s) 的训练。它将进行 25 次训练迭代,将图像大小调整为 416x416 像素,并可以提供可视化来监控模型的进度。
显示指定路径中名为“confusion_matrix.png”的图像'runs/detect/train/'
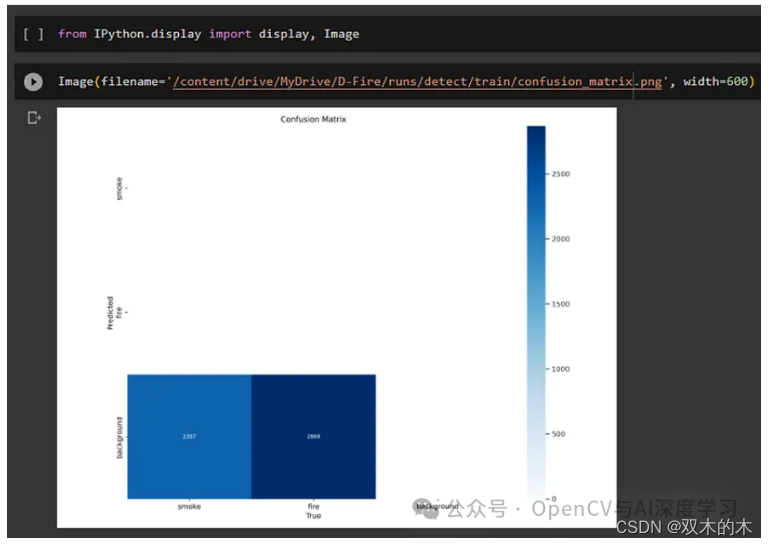
** 上面两个命令的解释**
当然!此代码片段使用 IPython 在 Jupyter Notebook 或 IPython 环境中显示图像。让我为你分解一下:
from IPython.display import display, Image:此行从模块导入display和函数。这些函数允许我们在 Jupyter Notebook 或 IPython 环境中显示图像和其他媒体。ImageIPython.display
Image(filename='/content/drive/MyDrive/D-Fire/runs/detect/train/confusion_matrix.png', width=600):这一行创建一个Image对象并指定我们要显示的图像文件的路径。在本例中,图像文件位于/content/drive/MyDrive/D-Fire/runs/detect/train/confusion_matrix.png.该width=600参数将显示图像的宽度设置为600像素,它控制显示时图像的大小。
当您在 Jupyter Notebook 或 IPython 环境中执行此代码片段时,它将加载并显示具有指定路径和大小的图像。该图像可能是一个混淆矩阵,它是机器学习模型性能的视觉表示,通常用于评估对象检测或分类任务的准确性。
**显示指定路径中另一张名为“results.png”的图像**

** 显示指定路径中另一张名为“val_batch0_labels.jpg”的图像**
Image(filename='/content/drive/MyDrive/D-Fire/runs/detect/train/val_batch0_labels.jpg', width=600)

显示指定路径中另一张名为“val_batch1_labels.jpg”的图像

THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。
版权归原作者 双木的木 所有, 如有侵权,请联系我们删除。