
24年5月来自AI芯片创业公司SambaNova的论文“SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts“。
像 GPT-4 这样的单片大语言模型 (LLM) 为现代生成式 AI 应用铺平了道路。然而,大规模训练、服务和维护单片 LLM 仍然非常昂贵且具有挑战性。现代 AI 加速器的计算-内存的不成比例增加造成了内存壁垒,需要新的方法来部署 AI。最近的研究表明,由许多较小的专家模型组成的组合,每个模型的参数都少几个数量级,可以达到或超过单片 LLM 的能力。专家组合 (CoE) 是一种模块化方法,可降低训练和服务的成本和复杂性。然而,这种方法在使用传统硬件时面临两个关键挑战:(1) 没有融合操作,较小的模型具有较低的操作强度,这使得高利用率更难实现;(2) 在动态切换时,托管大量模型要么成本过高,要么速度很慢。
该文将描述如何结合 CoE、流动的数据流和三层内存系统来扩展 AI 内存壁垒。Samba-CoE,这是一个拥有 150 名专家和一万亿个总参数的 CoE 系统。在 SambaNova SN40L 可重构数据流单元 (RDU) 上部署了 Samba-CoE,这是一种商业化数据流加速器架构,专为企业推理和训练应用而设计。该芯片引入一种新的三层内存系统,具有片上分布式 SRAM、封装内 HBM 和封装外 DDR DRAM。专用的 RDU 之间网络支持在多个插槽上进行纵向和横向扩展。与未融合的基线相比,在8个RDU 插槽上运行的各种基准测试中展示从 2 倍到 13 倍的加速。对于 CoE 推理部署,8-插槽 RDU 节点可将机器占用空间减少多达 19 倍,将模型切换时间加快 15 倍至 31 倍,并且与 DGX H100 相比实现 3.7 倍的总体加速,与 DGX A100 相比实现 6.6 倍的总体加速。
最后,迎合单片大模型的系统计算 TFLOPS 的扩展速度远远快于内存带宽和容量,从而产生了内存壁垒 [35],内存系统无法再有效地支持计算。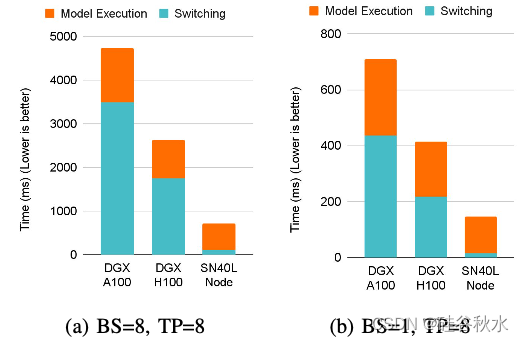
像 7B 参数的 Llama 3 [13]、Llama 2 [68] 和 Mistral 7B [44] 这样的小模型通常就足够了。它们在一般任务上的表现可能无法与大型模型相媲美,但小型模型可以在经过微调的较窄专门任务集上提供出色的准确性 [8][65]。例如,Flan-T5-XL 只有 3B 个参数,但MMLU 得分比 175B 参数的 GPT-3 高出近 10% [31]。此外,这些较小模型的组合已被证明能够表现出与单片大模型相匹配的涌现行为 [38][45][51][55][56]。
CoE 由多个小型专家模型组成,它们协同完成一项任务。一个专家的输出决定下一个要执行哪个专家。运行专家涉及将模型参数权重加载到加速器的主内存中,然后执行模型。因此,执行 CoE 涉及一系列模型切换和模型执行。目前最先进的 AI 加速器无法有效处理此操作序列,如图所示。
高效加速 CoE 归结为高效执行专家模型,同时最小化模型切换的成本。其主要是三个关键要求:
- 积极的算子融合和流水线并行,高效执行专家模型。较小的模型具有较低的操作强度 [67][70][74] 和算子之间的复杂访问模式 [34]。传统的算子融合技术 [22][26][40] 在随意访问模式下取得的成功有限。
- 高带宽内存,在生成推理过程中利用权重和中间结果的时间和空间局部性,以及
- 高容量内存,以最小化切换成本并存储许多专家模型的参数。
SN40L RDU 采用台积电 5nm 技术制造,是一种基于 2.5D 晶圆基板上芯片 (CoWoS) 芯片组的设计,包含两个 SN40L 可重构数据流芯片 (RDD) 和 HBM。每个 SN40L RDU 插槽使用 1040 个分布式模式计算单元 (PCU) 具有 638 BF16 TFLOPS 的峰值计算性能。此外还有 1040 个分布式模式内存单元 (PMU),它们总共提供数百 TBps 的片上内存带宽以及 PMU 内和PMU 间的高bank级并行性。灵活的片上地址生成逻辑为任意张量内存访问模式提供了高带宽。SN40L的三个内存排(tiers)是:520 MiB 的片上 PMU SRAM、64 GiB 的同封装 HBM 和高达 1.5 TiB 的 DDR DRAM(使用可插拔 DIMM)。在单个 SN40L 节点中,模型以超过 1 TB/s 的速度从 DDR 加载到 HBM。
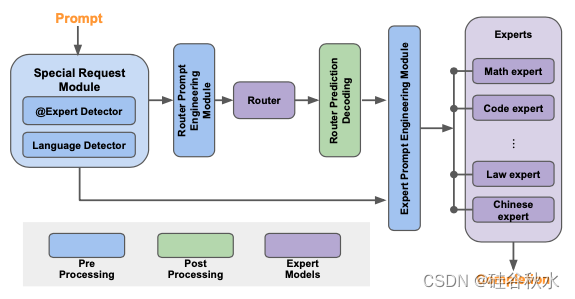
如图所示:Samba-CoE 由多个专家模型和一个路由器模型组成。每个专家都在特定领域进行了微调。用开源社区中针对编码、数学和语言翻译等领域进行微调的几个优秀专家模型。路由器是另一种专家模型,它将每个输入提示动态分配给最相关的专家。例如,与数学相关的查询将被路由到数学专家,而编码问题将转到代码专家。
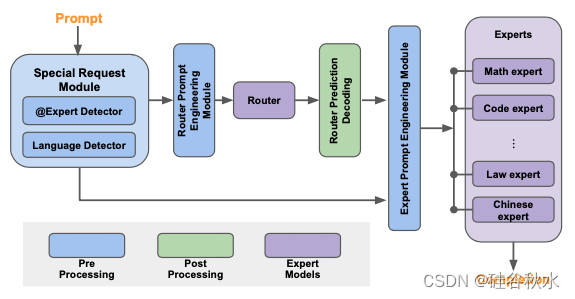
Samba-CoE 的灵感来自混合专家 (MoE) 架构 [42],但有几个关键区别。虽然 MoE 和 CoE 都比传统的密集单片模型更稀疏地激活,但 MoE 的灵活性不如 CoE。MoE 需要作为单个模型进行训练/微调,类似于单片模型,而 CoE 由独立和异构的专家模型组成,这些模型彼此独立训练/微调。 CoE 也更强大:先前的研究表明,CoE 的表现可以超越 MoE [38][51] 以及 GPT-3.5 和 GPT-4 [4][24] 等单片大型模型。但是CoE 和 MoE 是可以轻松组合的正交技术:CoE 可以利用在内部作为 MoE 实现的专家模型。
请注意,路由器和专家模型不必是同质的 - 它们可以是具有不同参数量的不同架构。选择 Llama2-7B 作为基础,是因为其大小合适、功能强大且社区支持强大。CoE 概念和 Samba-CoE 系统不仅限于 Llama2。
CoE 执行时间分为模型执行时间和模型切换时间。最小化 CoE 执行时间可用于减少每个用户的机器占用空间或增加给定占用空间下支持的用户数。为了减少模型执行时间,采用流动数据流,相对于传统算子融合,具备优势。为了最大限度地减少模型切换时间,需要高容量加速器-本地 DDR 接口和 HBM。
流动数据流
传统的算子融合是不充分的:算子融合是一种常见的优化技术,可以提高运算强度并提高硬件利用率 [22][26][32]–[34][40][74]。融合还可以减少运行模型所需的内核调用次数并分摊内核启动开销。然而,专家模型通常包含运算强度较低的算子 [25][36],以及涉及混洗和转置的复杂访问模式 [34]。复杂的访问模式严重限制了融合在 GPU 上的功效。PyTorch2 [22] 和 TensorRT [26] 等框架记录了对明确不支持融合模式的限制。因此,许多复杂的融合内核仍然是为 GPU 手写的 [32][33]。
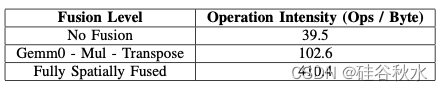
如图描绘一个简化的 Monarch FFT 分解 [34],边缘上标注了张量形状。下表显示了融合对运算强度的影响。更高的操作强度允许应用程序实现给定目标加速器的顶端性能。例如,A100 GPU 的 TFLOPS/TBps 比率约为 300/2 = 150,这意味着操作强度小于 150 FLOPs/字节的内核在 A100 上是内存限制的。在表中,前两行在 A100 上是内存限制的,最后一行是计算限制的。

但是,GPU 无法融合图中的所有内容,原因如下:
- 严格的内存分层结构和编程模型会造成数据移动瓶颈:GPU 内核通过网格状的线程块启动。网格结构在内核的持续时间内是固定的。融合 Gemm0 和 Mul 会很简单。但是,Transpose 强制线程访问其他 SM 中的线程值,从而通过共享缓存和 HBM 触发跨 SM 的数据交换。由于没有其他方式在 SM 之间传输数据,这种缺乏灵活性的情况会在共享缓存和 HBM 上造成瓶颈。
- 片上 SRAM 容量不足,迫使转置的输出到 HBM实体化,从而阻碍了融合机会。
- 算子之间没有利用流水线并行性:高阶 Monarch FFT 分解会创建许多 32 × 32 × 32 或更小的小矩阵乘法,这些乘法无法有效利用所有 SM。但是,所有矩阵乘法和逐元算子都具有流水线级并行。GPU SIMT 编程模型不提供直接以流水线形式执行图中算子的方法。
流动数据流支持任意访问模式的流水线和自动融合:与传统融合不同,流动数据流以粗粒度流水线的形式执行算子。张量通过此流水线平铺(tiled)和流动(streamed)。Tiles可以在算子之间具有任意的读写访问模式。
如图描述了空间融合的实现。蓝色框表示片上缓冲单元,灰色框表示片上计算单元。运算符 Gemm0、Mul 和 Gemm1 在粗粒度流水线中作为分阶段执行。中间的蓝色内存单元用作解耦阶段保存中间结果的缓冲区。由于 Gemm0 和 Gemm1 占总操作的较大比例,因此为它们分配了更多计算单元。通过使用适当数量的内存单元,将阶段缓冲区的输入和输出带宽与各自的阶段相匹配。例如,逻辑阶段缓冲区 I0 被划分为两个内存单元 I00 和 I01,以匹配 Gemm0 所需的输入带宽。出于容量原因,缓冲区 S0 - S3 被划分为四个内存单元。转置操作融合到缓冲区 T0* 和 T1* 中作为访问模式。
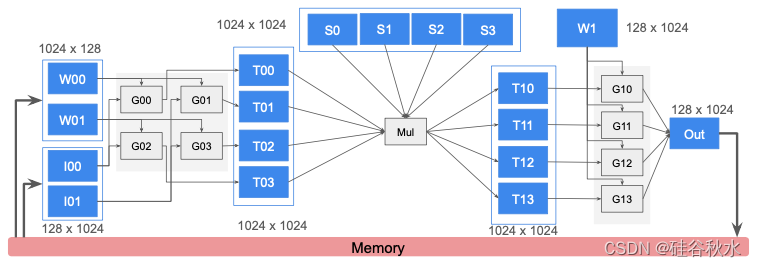
以下提炼出实现流动数据流的片上架构功能列表:
- 可组合内存单元:单个内存单元提供固定容量和带宽。由于片上张量的容量和带宽需求各不相同,硬件应支持跨内存单元的逻辑地址可编程交错。
- 地址生成带宽和灵活性:高数据带宽需要高地址生成带宽。此外,每个内存单元应支持非阻塞并发读取和写入,以有效实现阶段缓冲区。简而言之,地址生成硬件应允许以高吞吐量为任意的复杂地址表达式生成多个并发地址。
- 脉动和流动计算:ML 加速器架构通常实现脉动阵列以增加类似 GEMM 操作的计算密度。然而,在许多 ML 模型中,GEMM 后面经常跟着逐元算子和缩减,这需要高吞吐量流动计算能力。
- 一对多、多对一和数据重排序:生产单元和消费单位数量的差异会产生一生产单元-对-多消费单元和多生产单元-对一消费单元的交通流,这些交通流也需要流量控制。对于一对多,需要硬件支持在从源到程序决定的一组目的地互连中创建扇出(fan-out)路径。对于多对一,来自不同路径的数据可能会无序到达目的地。通常必须将无序序列放回原位,以匹配程序在目的地的期望。换句话说,硬件必须提供协议来重新排序数据流。最后,程序控制的带宽管理(例如,节流)和路由对于满足具有不同带宽要求的流是必要的。所有这些硬件支持都需要由编译器中的自动“部署-和-路由”算法使用。
模型托管和切换成本
HBM 的有限容量限制了托管在 GPU 或 TPU 上 CoE 中可以容纳的专家数。仅使用 HBM,运行大型 CoE 需要 (a) 使用更多机器来满足 HBM 容量要求,这会增加成本、使部署复杂化并带来负载平衡挑战,或 (b) 使用主机的内存,这会增加切换延迟。直接连接到加速器的更高容量 DDR 内存,可降低模型托管和模型切换成本。此外,CoE 在专家参数中表现出时间局部性,因为它们被多次使用(例如在自回归解码期间)。HBM 在利用这种时间数据局部性方面发挥着关键作用,它充当 DDR 和 SRAM 之间的软件管理缓存层。
因此,执行较小模型组合的系统需要两种类型的片外存储器:(1) 高带宽存储利用专家参数的时间局部性,以及 (2) 高容量存储以在小空间内存储专家参数。
以下简单介绍一下SN40L可重构数据流单元的硬件架构。
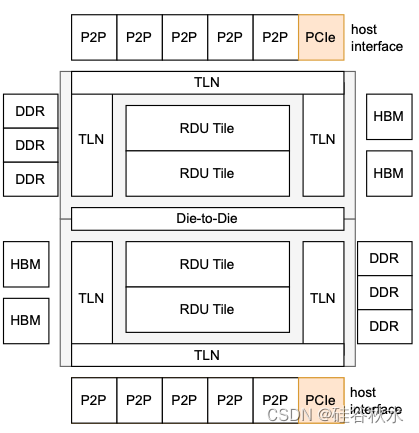
SN40L 数据流加速器采用台积电的 5FF 工艺制造,并使用晶圆基板芯片 (CoWoS) 多芯片封装技术封装为双芯片插座。如图显示了 SN40L 的主要组件,包括:RDU Tile,内存接口,芯片-到-芯片 (D2D) 接口,主管接口,P2P接口和顶级网络(TLN)。
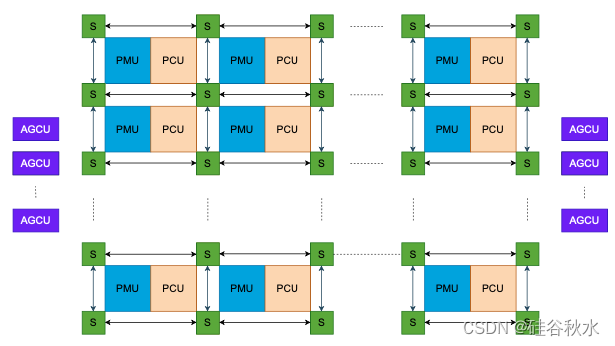
如图展示具有关键数据流组件的 SN40L 图块:模式计算单元(PCU)、模式内存单元(PMU)、可重构数据流网络(RDN )交换机和地址生产和合并单元(AGCU)。
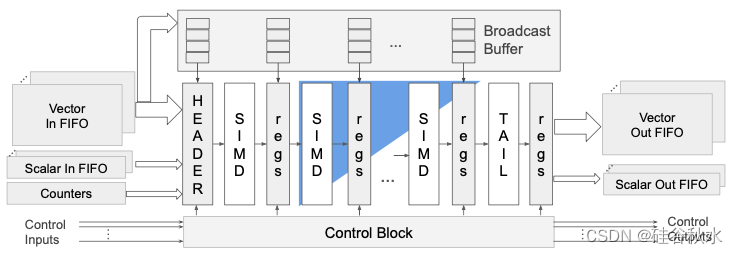
如图是PCU 框图,显示了脉动和 SIMD 操作的组件以及跨通道缩减。其说明了 PCU 同时作为 2D 脉动阵列和 SIMD 核心。
PMU 提供片上内存容量、带宽和寻址灵活性,以实现高效的算子融合。如图所示PMU 用于存储片上张量,如输入、参数、元数据和中间结果。
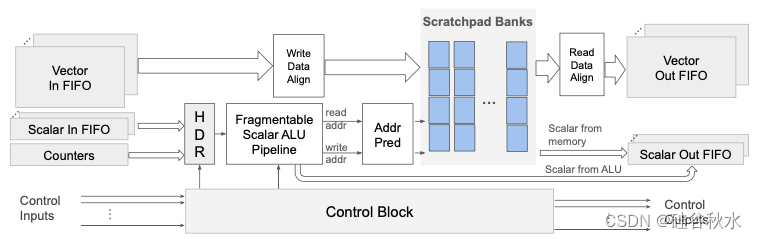
RDN 是片上可编程互连,可促进 PCU、PMU 和 AGCU 之间的通信。RDN 由三种物理结构组成 - 矢量、标量和控制。矢量和标量结构是分组交换的。控制结构是电路交换的,由一束可单独路由的单比特线组成。矢量结构是张量数据的主要管道。标量结构主要用于传输元数据(例如地址),但在某些情况下,它也可用于传输数据或控制。控制结构用于携带用于分布式粗粒度流控制的tokens并集体协调一个图的执行。控制tokens通常对应于指示循环结束的计数器“完成”事件。
AGCU 是一个可重构数据流桥,用于 RDU 块通过 TLN 访问本地设备内存 (HBM/DDR)、主机内存、远程 RDU 设备内存和远程 RDU 块。在Tile端,它通过公开 RDN 矢量、标量和控制口充当数据流核心。在 TLN 端,它生成读写请求并合并响应。它配备了标量地址生成流水线和计数器,与 PMU 逻辑 (无SRAM) 有一些相似之处。地址生成流水线包括它还为内存管理提供了地址转换层。
SN40L需要一定的软件支持。
Samba-CoE 由 150 个 Llama-7B 专家组成,总共拥有超过 1T 个参数。它部署在具有八个 RDU 插槽的单个 SN40L 节点上。如图显示了 Samba-CoE 如何利用 DDR 和 HBM,以及单个提示的简化事件流。所有 150 个专家的权重都保存在高容量 DDR 中,而路由器的权重则保存在 HBM 中。单个 Samba-CoE 推理有三个高级步骤:(1) 运行路由器以确定专家,(2) 将专家从 DDR 复制到 HBM,以及 (3) 运行专家。模型切换后,专家模型的权重在自回归解码循环中被多次读取以生成多个tokens。将权重移动到 HBM,可以利用 Samba-CoE 中固有的模型级时间局部性。
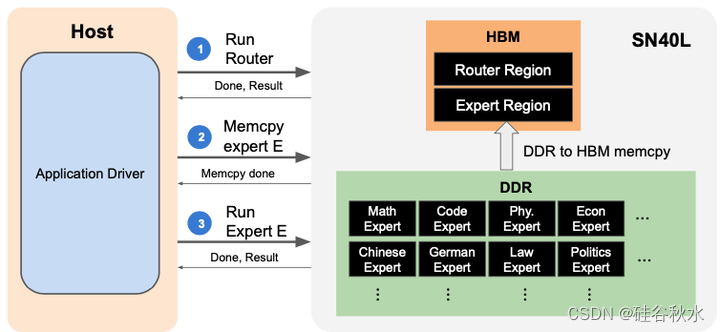
然而,这确实给软件堆栈带来了额外的负担,管理多个非均匀的内存空间。
SN40L 编译器中添加了自动异构设备内存管理。最初的假设是,只要一切合适,就默认使用 HBM。因此,将 DDR 用于两个主要目的:1) 当给定模型的驻留内存太大而无法容纳在 HBM 中时,将数据从 HBM 溢出到 DDR,2) 保存属于 CoE 但当前处于非活动状态的所有其他模型。
与单片模型相比,COE在软件模块化方面实现了重大飞跃。模型准确性和性能的进步非常迅速,CoE 使逐步利用最新创新变得容易。
为了实现这一目标,需要在运行时将任意数量的独立编译模型链接在一起,并在应用层收到新请求时动态切换它们。这种方法类似于传统软件应用程序中动态链接/加载的工作方式。
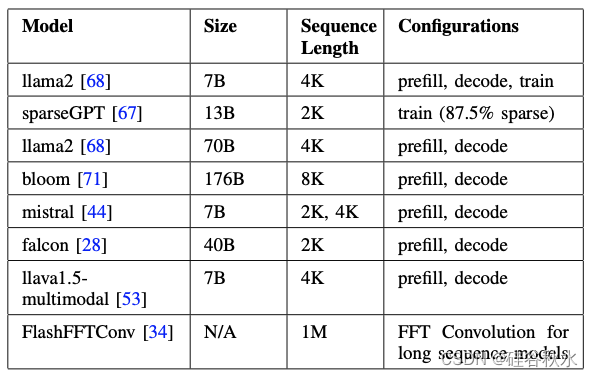
如表描述用于量化算子融合影响的语言模型基准:
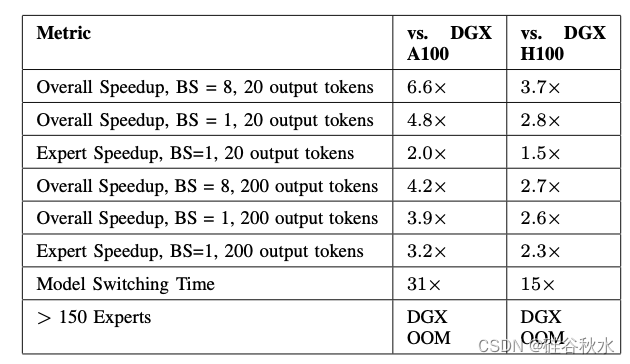
在 SN40L 节点上部署 Samba-CoE 时,随着专家数量的增加,与 DGX A100 和 DGX H100 相比,需要量化延迟和系统占用空间。结果见下表 所示:
版权归原作者 硅谷秋水 所有, 如有侵权,请联系我们删除。