
其实早在之前,我的一些文章里面就有做过关于学生课堂行为检测识别的项目,感兴趣的话可以自行移步阅读:
《yolov4-tiny目标检测模型实战——学生姿势行为检测》
《基于yolov5轻量级的学生上课姿势检测识别分析系统》
这些主要是偏目标检测类的项目
这里主要是想基于图像识别的方式来实现不同类型课堂行为的识别。首先来看下效果:
这里识别的课堂行为一共有以下5种,如下:
drink 喝水
listen 听课
phone 玩手机
trance 走神
write 记笔记
简单看下数据:
drink:

listen:

phone:

trance:

write:
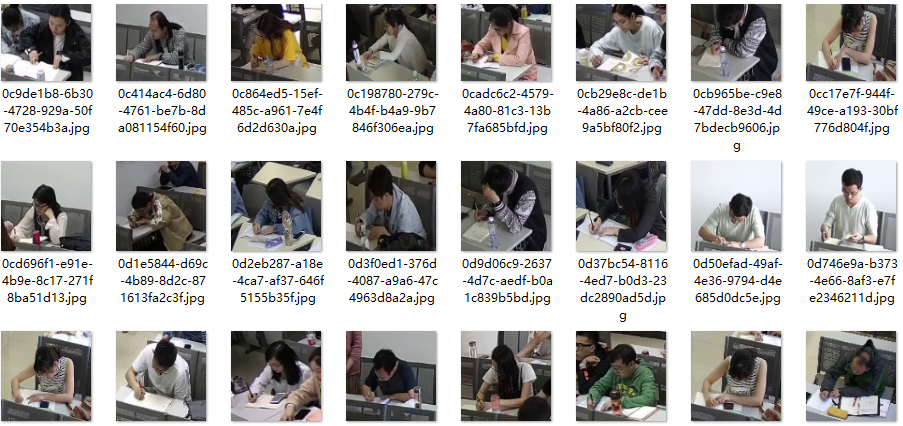
首先解析构建标砖h5数据集如下:
for one_label in os.listdir(picDir):
for one_pic in os.listdir(picDir + one_label + "/"):
if (
one_pic.endswith("jpg")
or one_pic.endswith("png")
or one_pic.endswith("jpeg")
):
try:
one_path = picDir + one_label + "/" + one_pic
print("one_path: ", one_path)
# 图片
one_img = cv2.imread(one_path)
one_img = cv2.resize(one_img, (100, 100))
one_img = one_img.transpose((2, 0, 1))
# 标签
one_pic_classes = one_label
one_y = getY(one_pic_classes)
# 整合
X_train.append(one_img)
y_train.append(one_y)
except Exception as e:
print("Exception: ", e)
接下来搭建轻量级的CNN模型,核心实现如下:
model = Sequential()
model.add(
Conv2D(
64,
(3, 3),
strides=(2, 2),
input_shape=input_shape,
padding="same",
activation="relu",
kernel_initializer="uniform",
)
)
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(
Conv2D(
128,
(3, 3),
strides=(2, 2),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
)
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(
Conv2D(
256,
(3, 3),
strides=(2, 2),
padding="same",
activation="relu",
kernel_initializer="uniform",
)
)
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.1))
model.add(Dense(512, activation="relu"))
model.add(Dropout(0.15))
model.add(Dense(numbers, activation="softmax"))
model.compile(
loss="categorical_crossentropy", optimizer="sgd", metrics=["accuracy"]
)
训练出来的模型很轻量级,只有不到5MB的大小。
训练集-测试集准确度曲线如下:
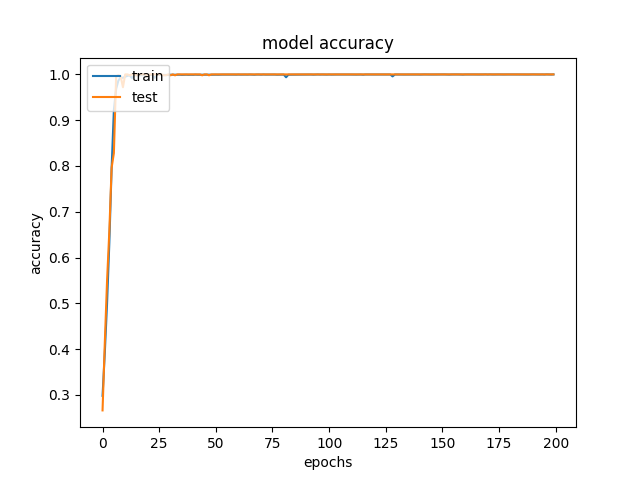
损失值曲线如下:
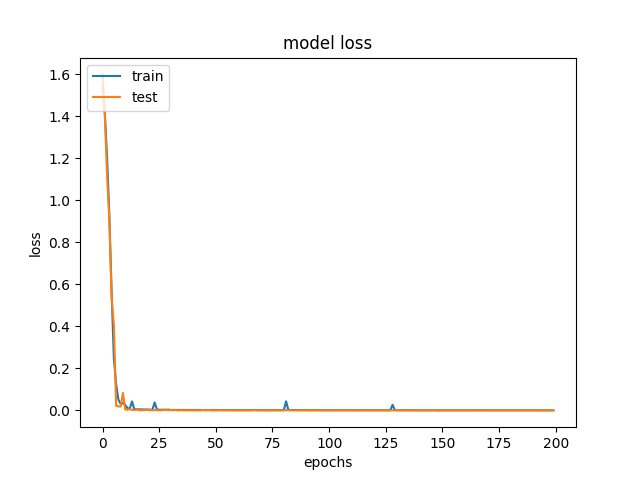
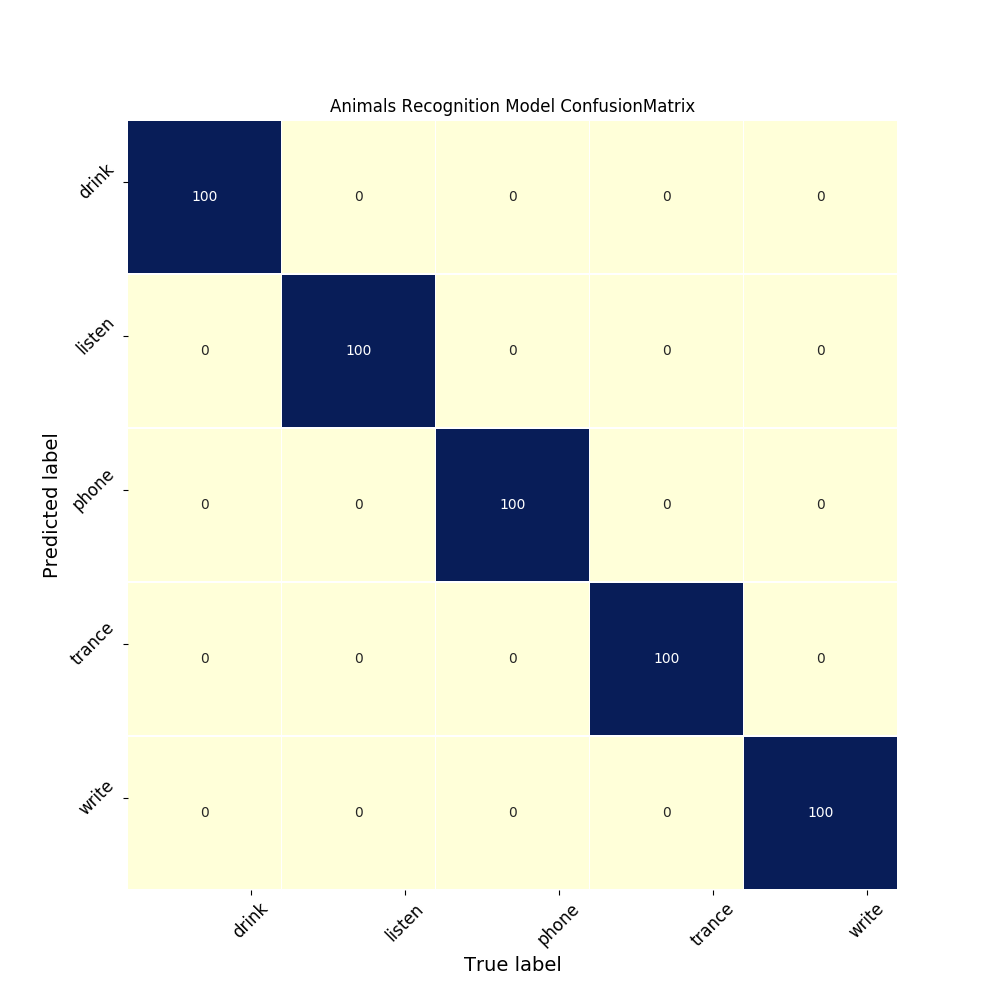
训练结束还绘制了混淆矩阵如下:
为了使得推理计算过程可视化,这里编写了专用的界面可以方便使用,如下:
点击上传自己想要测试的图片:

点击执行识别即可启动推理计算:
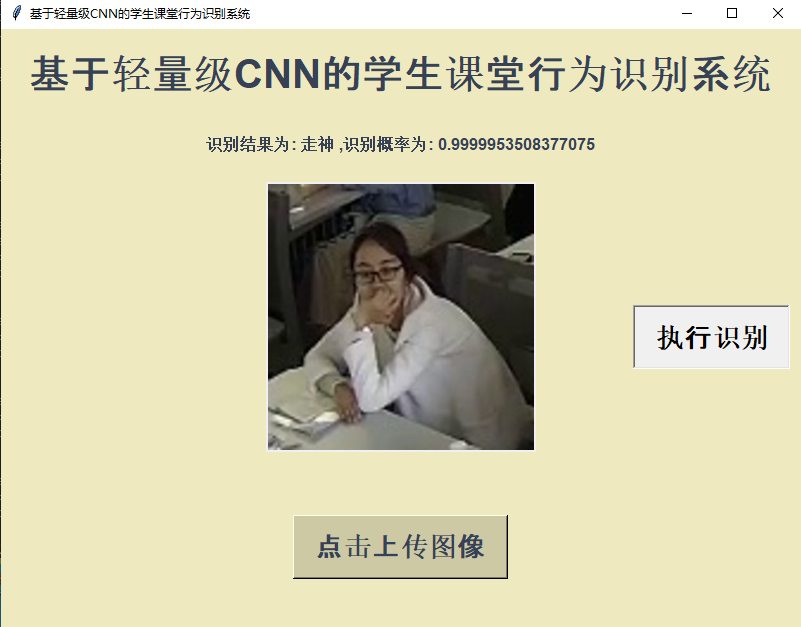
测试结果还是很不错的,这点从混淆矩阵上也可以印证。
本文转载自: https://blog.csdn.net/Together_CZ/article/details/128615279
版权归原作者 Together_CZ 所有, 如有侵权,请联系我们删除。
版权归原作者 Together_CZ 所有, 如有侵权,请联系我们删除。