
大赛是以银行产品认购预测为背景,根据记录的用户信息来推测该银行的用户是否会购买银行的产品。
赛题提供的数据集有3万条(训练集2.25万,测试集0.75万),包括20个特征变量,本文构建了XGBoost、LGBM、随机森林、逻辑回归、支持向量机、朴素贝叶斯分类器;得分分别为96.19、96.05、95.55、92.43、92.43、90.17
一、数据概览
每条数据都记录了如下信息:

赛题提供的测试集中包含22500条数据,其中订购银行产品的占13. 12%,用户年龄集中在25-60岁之间
二、数据探索
数据集共含21个变量,其中subscribe(是否订购)为预测变量,分类型变量、数值型变量各有10个:
查看数据分布
分类变量分布:

数值型变量分布:

可以看出训练集数据和测试集数据分布大体一致,且均不服从正态分布
对比分析
用tableau绘图展示:
2.1客户基本信息
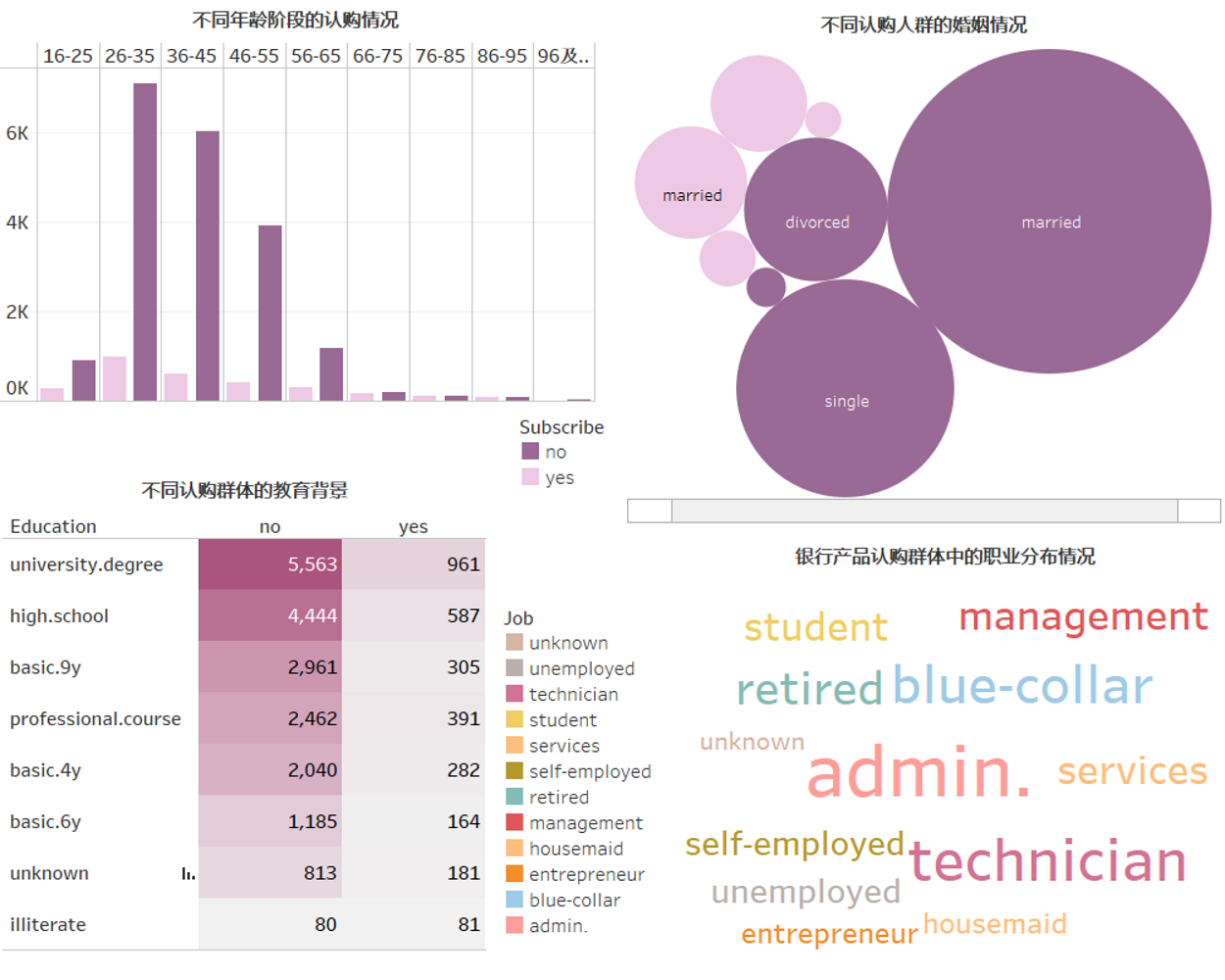
倾向购买银行产品的群体为年轻且工作了一段时间的青年群体,婚姻状况为单身/已婚,学历多为本科,多从事行政、技术岗
2.2个人信用指标

房贷差异不大,信用记录多为良好,无借贷的群体购买银行产品概率较高
2.3市场情况

高物价、就业情况好转的情况下,更容易认购银行产品,此时同业拆借率也不太高
2.4营销情况

移动电话联系,时长10分钟内,春末夏初期间联系更易购买银行产品

在有意愿购买银行产品的人群中,本次与上次营销活动联系客户次数均较少,距上次联系间隔3、4个月内或者从未联系过
相关性
3.1数值变量相关性

相关性较强的几个变量为:duration,pdays,previous;lending_rate3m,emp_var_rate
除此之外,其余数值变量相关性均不高
3.2分类变量相关性
一般地,使用熵进行分类变量的相关性计算。
熵衡量了不确定性,条件熵是X条件下Y的不确定程度,互信息就是在X条件下减少的熵,X与Y的互信息除以X,Y的熵开根号衡量了X与Y的相关性熵分类变量与目标变量的相关性

可以看出与subscribe相关性较强的几个变量:month,default,contact,job和marital
三、数据预处理
异常值识别与处理
箱线图:
训练集中,这四个变量---年龄、通话时长、本次营销活动联系客户的次数以及上次营销活动联系客户的次数 存在异常值,且异常值占比如下:

异常值占比不高,而训练集的缺失值占比为0:

可以看出该数据集较为干净,而且删除异常值,会导致训练集和测试集的分布不一致,影响建模的准确性,故而不对异常值进行处理。
特征编码&数据分箱
对各类别数据进行onehot/labelcode编码----基于XGboost模型
对各数值型数据进行归一化处理-----基于SVM模型
对各连续数值进行离散化(数据分箱处理)-----基于逻辑回归和朴素贝叶斯分类
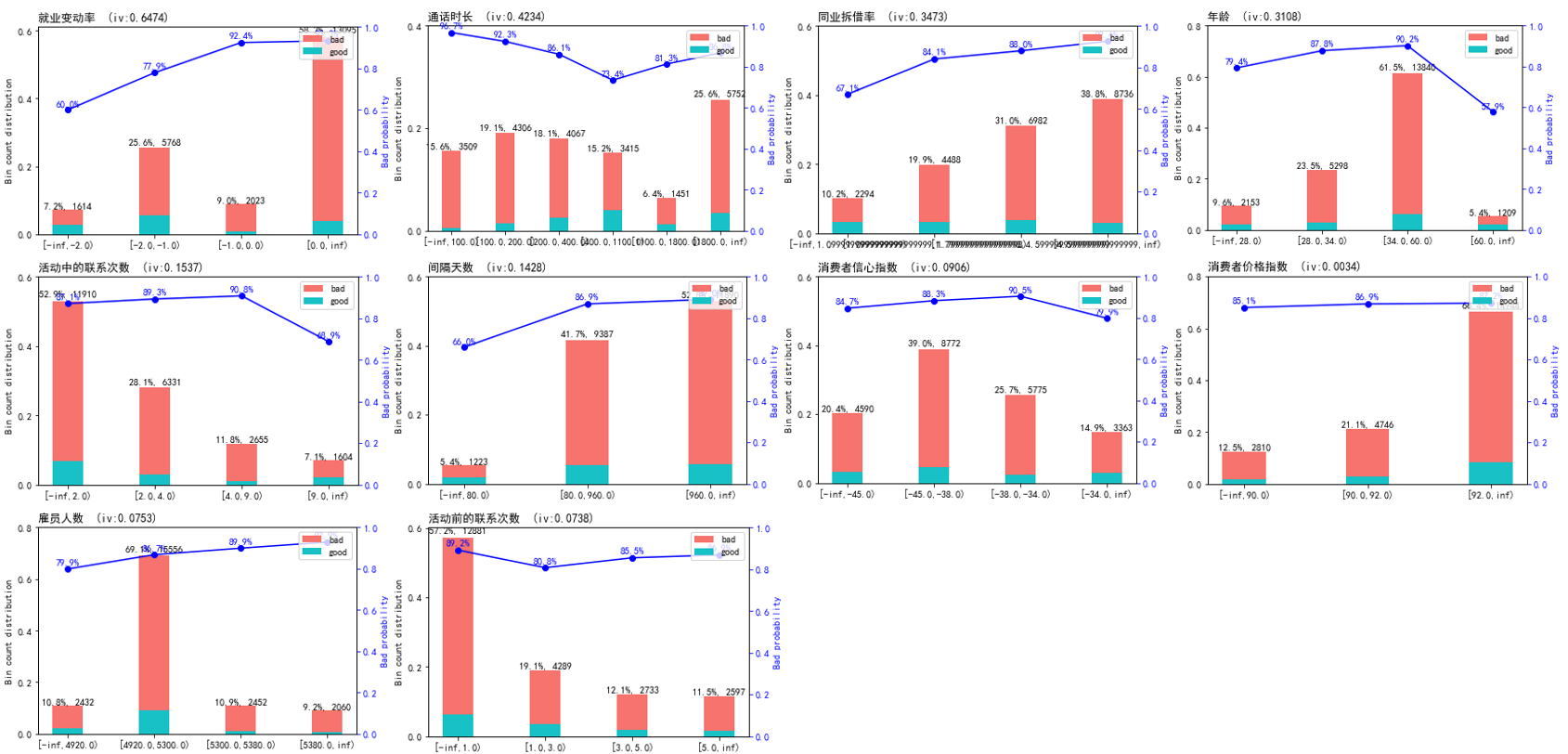
计算出各变量的IV值(IV值---衡量特征对目标变量预测能力的影响,对后续建模提供参考):
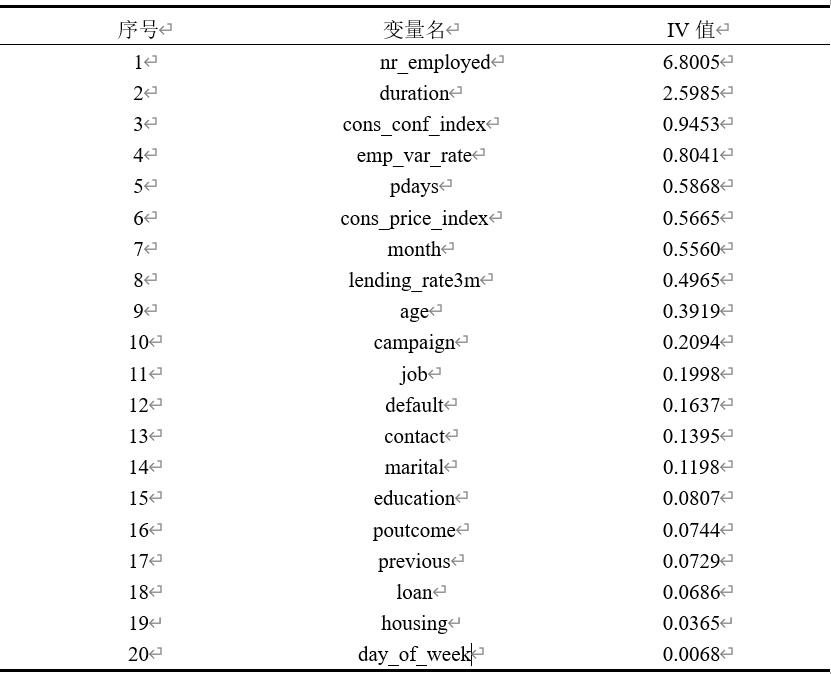
在分类问题中,对逻辑回归算法和朴素贝叶斯,分箱是极为重要且必须的。而对于树模型,如lightGBM、XGBoost等模型,分箱不是一个必须操作,但是却能够预防模型的过拟合并使模型的稳定性更好。
本文选择决策树分箱---用要进行分箱的这个特征与Y进行决策树的拟合,决策树训练后的结果会提供内部节点的阈值,这个阈值就会成为分箱的边界。
四、训练集建模
使用递归特征消除法,选择最优特征组合。本文选择随机森林作为分类器进行递归特征消除
使用cross_val_score选择最优评分的模型:

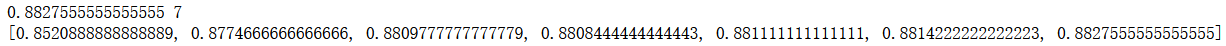
当特征数为19时,评分最高,各变量重要性排名为:

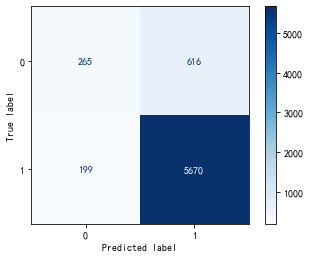
将train_data划分为训练和测试集,各个模型的准确率、精确率和召回率如下:
- XGBoost


- LGBM



- 随机森林


- 逻辑回归


- 支持向量机


- 朴素贝叶斯


最后将上述模型的准确率、精确率、召回率汇总如下表:

可以看出XGBoost、LGBM、随机森林、逻辑回归和朴素贝叶斯分类对训练集的分类效果较好,而支持向量机效果一般
五、测试集结果预测
将选出的特征对测试集中的数据进行建模,预测是否订购,提交结果如下:
得分最高的模型为XGBoost,得分为:

本文构建的模型可有效识别购买银行产品的用户,对于减少营销成本实现精准营销提供参考优化建议:
银行的营销积极性与市场外部条件会对银行产品的购买产生重要影响,低频率联系,学会制造新鲜感,是银行营销的技巧,同时,市场回暖,就业好转,物价指数较高时,也会增加用户购买银行产品的概率
版权归原作者 comeon! just_do_it 所有, 如有侵权,请联系我们删除。