
基于身份的攻击呈上升趋势,网络钓鱼仍然是最常见的和第二昂贵的攻击向量。一些攻击者正在使用 AI 制作更令人信服的网络钓鱼消息,并部署机器人来绕过旨在发现可疑行为的自动防御。
与此同时,企业应用程序的持续增长给 IT 团队带来了挑战,他们必须支持、保护和管理这些应用程序,而且通常不会增加人员。
连接设备的数量不断增加,由于攻击面的增加带来了安全风险。每个设备相关的潜在漏洞使这一问题更加复杂。
虽然有许多安全工具和应用程序可用于帮助企业抵御攻击,但集成和管理大量工具会增加成本、复杂性和风险。
网络安全是 三大挑战 之一,仅次于环境可持续发展和技术现代化。生成式 AI 可以为网络安全带来变革。它可以帮助安全分析师更快地找到完成工作所需的信息,生成合成数据以训练 AI 模型以准确识别风险,并运行假设场景以更好地应对潜在威胁。
利用 AI 与日俱增的威胁形势保持同步
网络安全是一个数据问题,而可用的海量数据对于手动筛选和威胁检测来说过于庞大。这意味着人类分析人员无法再有效地抵御复杂的攻击,因为攻击和防御的速度和复杂性超过了人类的能力。借助 AI,组织可以实现数据的 100%可见性,并快速发现异常情况,从而更快地检测威胁。
虽然呈指数级增长的数据量给威胁检测带来了挑战,但基于 AI 的网络防御方法需要访问训练数据。在某些情况下,这并不容易实现,因为组织通常不会共享敏感数据。借助生成式 AI,合成数据可以帮助解决数据差距并改善 AI 网络安全防御。
合成和上下文化数据的最有效方法之一是使用自然语言。大型语言模型 (LLM) 的进步正在扩展威胁检测和数据生成技术,从而改善网络安全。
本文将探讨三个用例,说明生成式 AI 和 LLM 如何改善网络安全,并提供三个示例,说明如何应用用于网络安全的 AI 基础模型。
Copilot 可提升安全团队的效率和能力
网络安全专业人员的人员短缺问题持续存在。检索增强生成 (RAG) 使组织能够利用现有知识库并扩展人类分析师的能力,从而提高他们的效率和效力。
Copilot 可以在自然的界面中学习安全分析师的行为,适应他们的需求,并提供相关见解来指导他们的日常工作。组织可以快速发现 RAG 聊天机器人的价值。
预计到 2025 年,三分之二的企业将结合使用生成式 AI 和 RAG 技术,为特定领域的自助式知识发现提供支持,从而将决策效率提升 50%1。
除了没有足够的网络安全人员外,组织还面临着培训新员工和现有员工的挑战。借助 Copilot,网络安全专业人员可以在复杂的部署场景中获得近乎实时的响应和指导,而无需额外的培训或研究。
虽然安全副驾驶可以为组织带来变革性优势,但它们只有在能够提供快速、准确和最新的信息时才有用。NVIDIA 采用检索增强型生成工作流程的 AI 聊天机器人 提供了一个很好的起点。它展示了如何构建代理和聊天机器人,以实时检索最新信息,并以自然语言提供准确的响应。
生成式 AI 可以显著改善常见漏洞防御
随着系统中报告的安全漏洞数量不断增加,修补软件安全问题正变得越来越具有挑战性。常见漏洞和暴露 (CVE) 数据库 在 2022 年创下新高。截至 2023 年第三季度,报告的累计漏洞超过 20 万个,这明显表明传统的扫描和修补方法已变得难以管理。
与仅依赖 CVE 评分来确定漏洞优先级的组织相比,部署基于风险的分析的组织所面临的泄露成本更低。使用生成式 AI 可以改善漏洞防御,同时减轻安全团队的负担。
在集成了 LLM 引擎之后,NVIDIA 利用 NVIDIA Morpheus 构建了一个工作流程,该工作流程通过 RAG 处理 CVE 风险分析。安全分析人员可以借助 LLM 和 RAG 来确定软件容器内是否包含有漏洞和可被利用的组件。
此方法使分析师能够平均将单个 CVE 的调查速度提高 4 倍,并以高准确度识别漏洞,以便对补丁程序进行优先级排序并相应地加以处理。
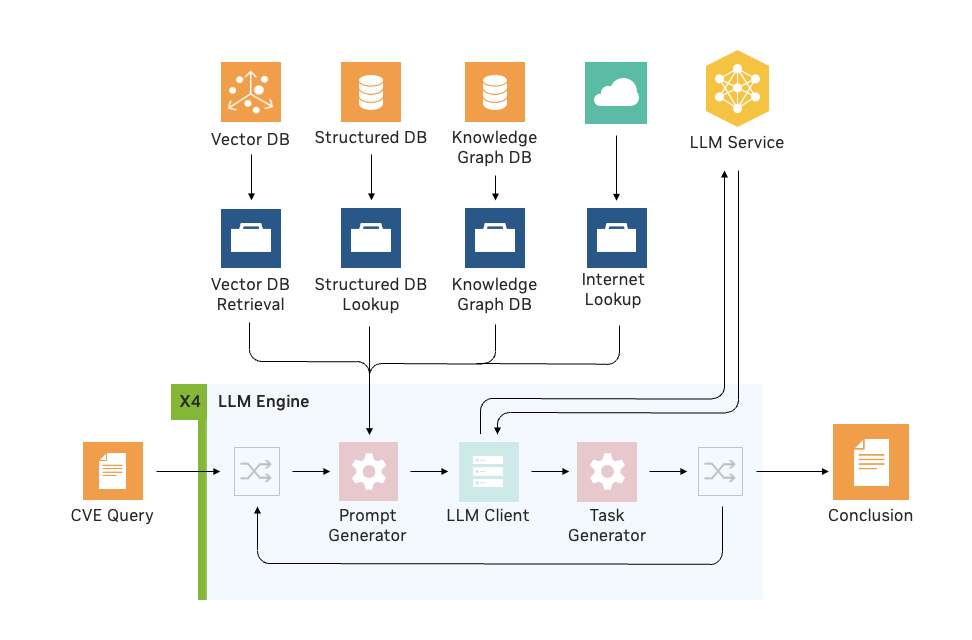
图 1.使用 Morpheus LLM 引擎支持模型生成的 RAG 任务和多循环的 CVE 可利用性
网络安全基础模型
虽然预训练模型对许多应用程序都很有用,但有时从头开始训练自定义模型会很有帮助。当特定领域具有独特的词汇量或内容具有不符合传统语言范式和结构的属性时,这很有帮助。
在网络安全领域,我们可以通过某些类型的原始日志来观察这一点。想想一本书,单词如何构成句子、句子如何构成段落和段落。语言模型中有一个固有结构。这与 JSON 行或 CEF 等格式中包含的数据形成对比。数据键和值的临近具有不同的含义。
使用自定义基础模型提供了多种机会。
解决数据缺口:虽然更好地利用涌入的数据可以改善网络安全,但数据的质量至关重要。如果缺乏高质量的可用训练数据,检测威胁的准确性就会受到影响。生成式 AI 可以通过合成数据生成来帮助弥补数据缺口,或者通过使用大型模型生成的数据来训练较小的模型。
执行“假设”场景:在缺乏用于构建防御系统的数据集的情况下,对抗新威胁的能力将显著提高。生成式 AI 可用于模拟攻击,并执行“假设”场景,以测试尚未遇到的攻击模式。这种基于不断演变的威胁和变化的数据模式的动态模型训练,有助于提升整体安全性。
输入下游异常检测器:使用大型模型生成数据,训练用于威胁检测的下游轻量级模型,既可以降低基础设施成本,又能保持相同的准确性水平。
NVIDIA 进行了许多实验,并训练了几个特定于网络安全的基础模型,包括一个基于 GPT-2 风格模型(称为 CyberGPT)的模型。其中一个是基于身份数据训练的模型(包括 Azure AD 等应用程序日志)。借助此模型,人们可以生成高度逼真的合成数据,以解决数据差距,并可以执行“假设”场景。
图 2 显示了各种大小的 CyberGPT 模型的 Rogue2 F1 分数,每个实例的准确率约为 80%.这意味着生成的 10 个日志中,有 8 个与真实网络用户生成的日志几乎没有区别。
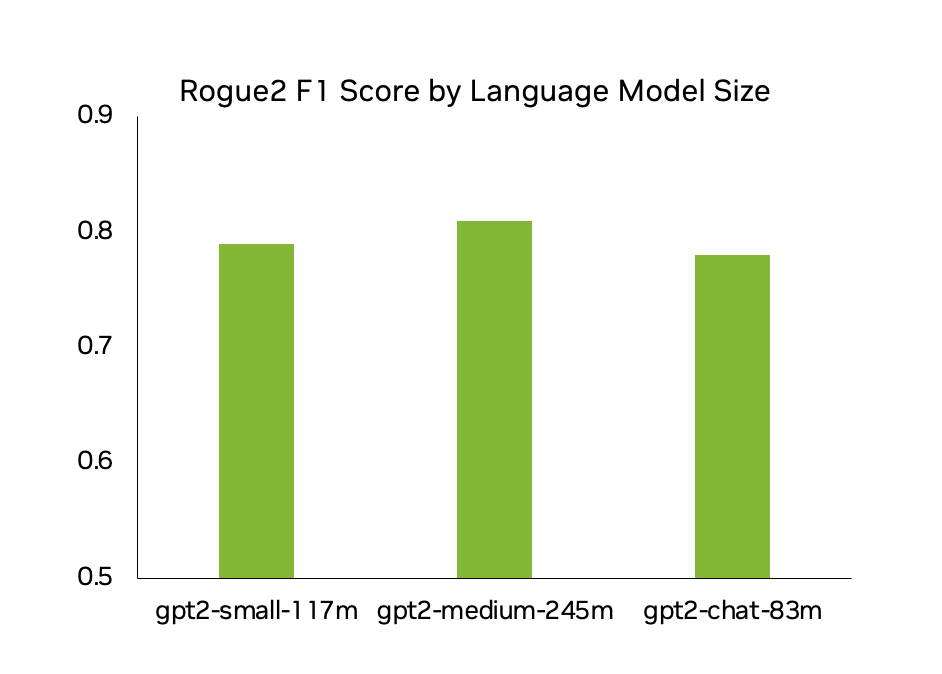
图 2.CyberGPT 模型生成的日志的准确性和真实度分数
至于训练时间,超级计算机并不是实现高质量结果的必要条件。在测试中,对于具有字符级标记化的 GPT-2 小型模型,训练时间低至 12 GPU 小时。此模型在 230 万行 100 多个用户日志上进行训练,并进行 1000 次迭代。此模型基于多种类型的数据进行训练,包括 Azure、SharePoint、Confluence 和 Jira.
此外,我们还使用分词器(主要是字符级分词器)、现成的字节对编码 (BPE) 分词器和自定义训练的分词器运行实验。虽然每种分词器都有优点和缺点,但通过训练自定义分词器可以获得更好的性能。这不仅可以根据自定义词汇更有效地利用资源,而且可以减少分词错误,并可以处理特定于日志的语法。
虽然这些结果反映了使用语言模型进行的实验,但使用 LLM 进行的相同测试也取得了类似的结果。
合成数据生成可 100% 检测鱼叉式网络钓鱼电子邮件
Spear 网络钓鱼电子邮件具有高度针对性,因此非常令人信服。Spear 网络钓鱼(通常情况下,任何有效的网络钓鱼活动)与良性电子邮件之间的唯一真正区别是发送者的意图。由于缺乏可用的训练数据,因此使用 AI 进行防御的 Spear 网络钓鱼具有挑战性。
为了探索合成数据生成在增强钓鱼枪电子邮件检测方面的潜力,我们使用 NVIDIA Morpheus 构建了一个工作流。
使用现成模型时,Spon 网络钓鱼检测管线漏掉了 16%(约 600 封)的恶意电子邮件。然后,未捕获的恶意电子邮件被用于创建新的合成数据集。从合成生成的电子邮件中学习新的意图模型,并将其集成到我们的 Spon 网络钓鱼检测管线中。在检测管线中添加这项新的意图模型功能后,仅在合成电子邮件上训练的 Spon 网络钓鱼电子邮件的检测率达到 100%.
我们的 NVIDIA 网络钓鱼检测 AI 工作流程提供了一个示例,展示如何使用 NVIDIA Morpheus 构建此解决方案。
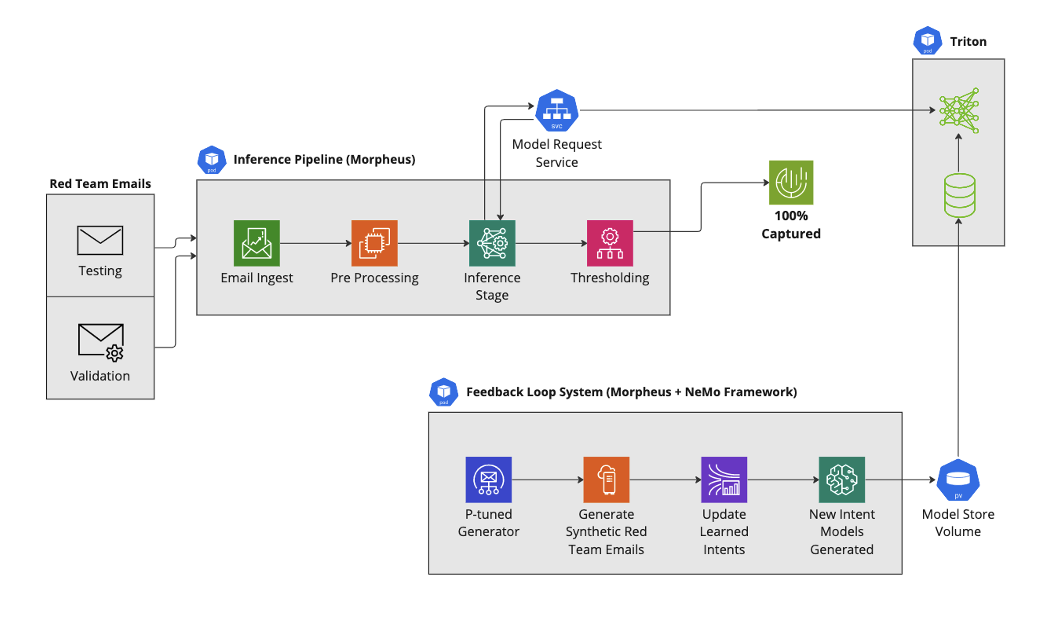
图 3.使用合成生成且符合特定行为意图的 Spear 网络钓鱼电子邮件构建的 Spear 网络钓鱼检测管道
版权归原作者 人工智能技术资讯 所有, 如有侵权,请联系我们删除。