

本文将主要讲述如何使用BLiTZ(PyTorch贝叶斯深度学习库)来建立贝叶斯LSTM模型,以及如何在其上使用序列数据进行训练与推理。
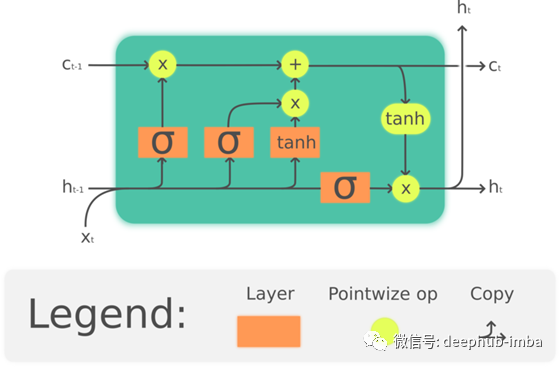
在本文中,我们将解释贝叶斯长期短期记忆模型(LSTM)是如何工作的,然后通过一个Kaggle数据集进行股票置信区间的预测。
贝叶斯LSTM层
众所周知,LSTM结构旨在解决使用标准的循环神经网络(RNN)处理长序列数据时发生的信息消失问题。
在数学上,LSTM结构的描述如下:
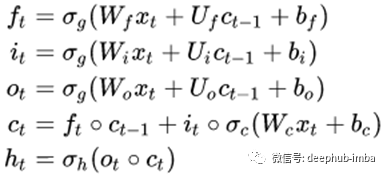
我们知道,贝叶斯神经网络的核心思想是,相比设定一个确定的权重,我们可以通过一个概率密度分布来对权重进行采样,然后优化分布参数。
利用这一点,就有可能衡量我们所做的预测的置信度和不确定性,这些数据与预测本身一样,都是非常有用的数据。
从数学上讲,我们只需要在上面的方程中增加一些额外的步骤,也即权值和偏置的采样,这发生在前向传播之前。
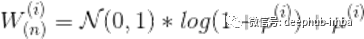
这表示在第i次在模型第N层上权重的采样。
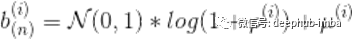
这表示在第i次在模型第N层上偏置的采样。
当然,我们的可训练参数是和,用来表示不同的权重分布。BLiTZ具有内置的
BayesianLSTM
层,可以为您完成所有这些艰苦的工作,因此您只需要关注您的网络结构设计与网络的训练/测试。
现在我们看一个例子。
第一步,先导入库
除了导入深度学习中最常用的库外,我们还需要从
blitz.modules
中导入
BayesianLSTM
,并从
blitz.utils
导入
variational_estimator
,后者是一个用于变量训练与复杂度计算的装饰器。
我们还要导入
collections.deque
来执行时间序列数据的预处理。
importpandasaspd
importnumpyasnp
importtorch
importtorch.nnasnn
importtorch.optimasoptim
importtorch.nn.functionalasF
fromblitz.modulesimportBayesianLSTM
fromblitz.utilsimportvariational_estimator
fromsklearn.model_selectionimporttrain_test_split
fromsklearn.preprocessingimportStandardScaler
importmatplotlib.pyplotasplt
%matplotlibinline
fromcollectionsimportdeque
数据预处理
现在,我们将创建并预处理数据集以将其输入到网络。我们将从Kaggle数据集中导入Amazon股票定价,获取其“收盘价”数据并将其标准化。
我们的数据集将由标准化股票价格的时间戳组成,并且具有一个形如
(batch_size,sequence_length,observation_length)
的shape。
下面我们导入数据并对其预处理:
#importing the dataset
amazon="data/AMZN_2006-01-01_to_2018-01-01.csv"
ibm="data/IBM_2006-01-01_to_2018-01-01.csv"
df = pd.read_csv(ibm)
#scaling and selecting data
close_prices = df["Close"]
scaler = StandardScaler()
close_prices_arr = np.array(close_prices).reshape(-1, 1)
close_prices = scaler.fit_transform(close_prices_arr)
close_prices_unscaled = df["Close"]
我们还必须创建一个函数来按照时间戳转换我们的股价历史记录。为此,我们将使用最大长度等于我们正在使用的时间戳大小的双端队列,我们将每个数据点添加到双端队列,然后将其副本附加到主时间戳列表:
defcreate_timestamps_ds(series,
timestep_size=window_size):
time_stamps = []
labels = []
aux_deque = deque(maxlen=timestep_size)
#starting the timestep deque
foriinrange(timestep_size):
aux_deque.append(0)
#feed the timestamps list
foriinrange(len(series)-1):
aux_deque.append(series[i])
time_stamps.append(list(aux_deque))
#feed the labels lsit
foriinrange(len(series)-1):
labels.append(series[i+1])
assertlen(time_stamps) == len(labels), "Something went wrong"
#torch-tensoring it
features = torch.tensor(time_stamps[timestep_size:]).float()
labels = torch.tensor(labels[timestep_size:]).float()
returnfeatures, labels
创建神经网络类
我们的网络类接收
variantal_estimator
装饰器,该装饰器可简化对贝叶斯神经网络损失的采样。我们的网络具有一个贝叶斯LSTM层,参数设置为
in_features = 1
以及
out_features = 10
,后跟一个
nn.Linear(10, 1)
,该层输出股票的标准化价格。
@variational_estimator
classNN(nn.Module):
def__init__(self):
super(NN, self).__init__()
self.lstm_1 = BayesianLSTM(1, 10)
self.linear = nn.Linear(10, 1)
defforward(self, x):
x_, _ = self.lstm_1(x)
#gathering only the latent end-of-sequence for the linear layer
x_ = x_[:, -1, :]
x_ = self.linear(x_)
returnx_
如您所见,该网络可以正常工作,唯一的不同点是BayesianLSTM层和variantal_estimator装饰器,但其行为与一般的Torch对象相同。
完成后,我们可以创建我们的神经网络对象,分割数据集并进入训练循环:
创建对象
我们现在可以创建损失函数、神经网络、优化器和dataloader。请注意,我们不是随机分割数据集,因为我们将使用最后一批时间戳来计算模型。由于我们的数据集很小,我们不会对训练集创建dataloader。
Xs, ys = create_timestamps_ds(close_prices)
X_train, X_test, y_train, y_test = train_test_split(Xs,
ys,
test_size=.25,
random_state=42,
shuffle=False)
ds = torch.utils.data.TensorDataset(X_train, y_train)
dataloader_train = torch.utils.data.DataLoader(ds, batch_size=8, shuffle=True)
net = NN()
criterion = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
我们将使用MSE损失函数和学习率为0.001的Adam优化器
训练循环
对于训练循环,我们将使用添加了
variational_estimator
的
sample_elbo
方法。它对X个样本的损失进行平均,并帮助我们轻松地用蒙特卡洛估计来计算损失。
为了使网络正常工作,网络
forward
方法的输出必须与传入损失函数对象的标签的形状一致。
iteration = 0
forepochinrange(10):
fori, (datapoints, labels) inenumerate(dataloader_train):
optimizer.zero_grad()
loss = net.sample_elbo(inputs=datapoints,
labels=labels,
criterion=criterion,
sample_nbr=3)
loss.backward()
optimizer.step()
iteration += 1
ifiteration%250==0:
preds_test = net(X_test)[:,0].unsqueeze(1)
loss_test = criterion(preds_test, y_test)
print("Iteration: {} Val-loss: {:.4f}".format(str(iteration), loss_test))
评估模型并计算置信区间
我们将首先创建一个具有要绘制的真实数据的dataframe:
original = close_prices_unscaled[1:][window_size:]
df_pred = pd.DataFrame(original)
df_pred["Date"] = df.Date
df["Date"] = pd.to_datetime(df_pred["Date"])
df_pred = df_pred.reset_index()
要预测置信区间,我们必须创建一个函数来预测同一数据X次,然后收集其均值和标准差。同时,在查询真实数据之前,我们必须设置将尝试预测的窗口大小。
让我们看一下预测函数的代码:
defpred_stock_future(X_test,
future_length,
sample_nbr=10):
#sorry for that, window_size is a global variable, and so are X_train and Xs
globalwindow_size
globalX_train
globalXs
globalscaler
#creating auxiliar variables for future prediction
preds_test = []
test_begin = X_test[0:1, :, :]
test_deque = deque(test_begin[0,:,0].tolist(), maxlen=window_size)
idx_pred = np.arange(len(X_train), len(Xs))
#predict it and append to list
foriinrange(len(X_test)):
#print(i)
as_net_input = torch.tensor(test_deque).unsqueeze(0).unsqueeze(2)
pred = [net(as_net_input).cpu().item() foriinrange(sample_nbr)]
test_deque.append(torch.tensor(pred).mean().cpu().item())
preds_test.append(pred)
ifi%future_length == 0:
#our inptus become the i index of our X_test
#That tweak just helps us with shape issues
test_begin = X_test[i:i+1, :, :]
test_deque = deque(test_begin[0,:,0].tolist(), maxlen=window_size)
#preds_test = np.array(preds_test).reshape(-1, 1)
#preds_test_unscaled = scaler.inverse_transform(preds_test)
returnidx_pred, preds_test
我们要将置信区间保存下来,确定我们置信区间的宽度。
defget_confidence_intervals(preds_test, ci_multiplier):
globalscaler
preds_test = torch.tensor(preds_test)
pred_mean = preds_test.mean(1)
pred_std = preds_test.std(1).detach().cpu().numpy()
pred_std = torch.tensor((pred_std))
upper_bound = pred_mean+ (pred_std*ci_multiplier)
lower_bound = pred_mean- (pred_std*ci_multiplier)
#gather unscaled confidence intervals
pred_mean_final = pred_mean.unsqueeze(1).detach().cpu().numpy()
pred_mean_unscaled = scaler.inverse_transform(pred_mean_final)
upper_bound_unscaled = upper_bound.unsqueeze(1).detach().cpu().numpy()
upper_bound_unscaled = scaler.inverse_transform(upper_bound_unscaled)
lower_bound_unscaled = lower_bound.unsqueeze(1).detach().cpu().numpy()
lower_bound_unscaled = scaler.inverse_transform(lower_bound_unscaled)
returnpred_mean_unscaled, upper_bound_unscaled, lower_bound_unscaled
由于我们使用的样本数量很少,因此用一个很高的标准差对其进行了补偿。我们的网络将尝试预测7天,然后将参考数据:
future_length=7
sample_nbr=4
ci_multiplier=10
idx_pred, preds_test = pred_stock_future(X_test, future_length, sample_nbr)
pred_mean_unscaled, upper_bound_unscaled, lower_bound_unscaled = get_confidence_intervals(preds_test,
ci_multiplier)
我们可以通过查看实际值是否低于上限并高于下限来检查置信区间。设置好参数后,您应该拥有95%的置信区间,如下所示:
y = np.array(df.Close[-750:]).reshape(-1, 1)
under_upper = upper_bound_unscaled>y
over_lower = lower_bound_unscaled<y
total = (under_upper == over_lower)
print("{} our predictions are in our confidence interval".format(np.mean(total)))
检查输出图形
现在,我们将把预测结果绘制为可视化图形来检查我们的网络是否运行的很顺利,我们将在置信区间内绘制真实值与预测值。
params = {"ytick.color" : "w",
"xtick.color" : "w",
"axes.labelcolor" : "w",
"axes.edgecolor" : "w"}
plt.rcParams.update(params)
plt.title("IBM Stock prices", color="white")
plt.plot(df_pred.index,
df_pred.Close,
color='black',
label="Real")
plt.plot(idx_pred,
pred_mean_unscaled,
label="Prediction for {} days, than consult".format(future_length),
color="red")
plt.fill_between(x=idx_pred,
y1=upper_bound_unscaled[:,0],
y2=lower_bound_unscaled[:,0],
facecolor='green',
label="Confidence interval",
alpha=0.5)
plt.legend()
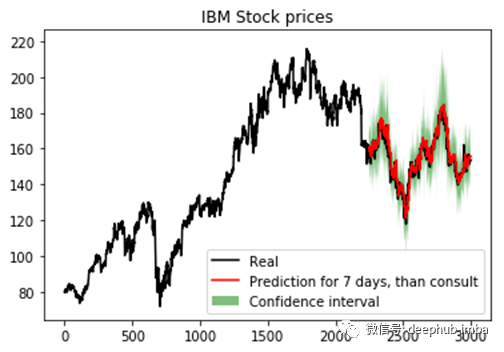
最后,我们放大一下着重看看预测部分。
params = {"ytick.color" : "w",
"xtick.color" : "w",
"axes.labelcolor" : "w",
"axes.edgecolor" : "w"}
plt.rcParams.update(params)
plt.title("IBM Stock prices", color="white")
plt.fill_between(x=idx_pred,
y1=upper_bound_unscaled[:,0],
y2=lower_bound_unscaled[:,0],
facecolor='green',
label="Confidence interval",
alpha=0.75)
plt.plot(idx_pred,
df_pred.Close[-len(pred_mean_unscaled):],
label="Real",
alpha=1,
color='black',
linewidth=0.5)
plt.plot(idx_pred,
pred_mean_unscaled,
label="Prediction for {} days, than consult".format(future_length),
color="red",
alpha=0.5)
plt.legend()
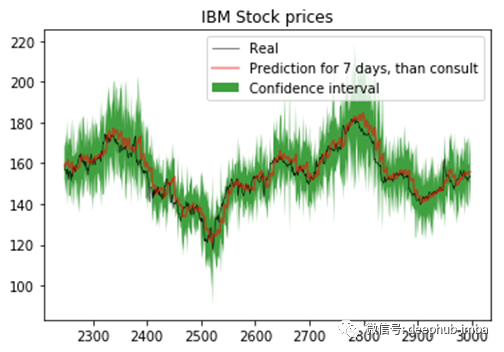
总结
我们看到BLiTZ内置的贝叶斯LSTM使得贝叶斯深度学习的所有功能都变得非常简单,并且可以顺利地在时间序列上进行迭代。我们还看到,贝叶斯LSTM已与Torch很好地集成在一起,并且易于使用,你可以在任何工作或研究中使用它。
我们还可以非常准确地预测IBM股票价格的置信区间,而且这比一般的点估计可能要有用的多。
作者:Piero Esposito
deephub翻译组:Alenander Zhao
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********
**
**