
背景
Ai作图从Diffusion模型开始,作图进入稳步发展快车道。然后用过diffusion系列作图的同学对产图稳定性,以及可控性都会颇有微词。diffusion系列作图方法在宏观层面上确实能够比较好的做出看上去还不错的图。然后当你细抠细节时候,发现这东西太不可控了:
1.位置关系经常搞错
2.prompt描述不符合人类习惯
3.无法比较好get人类意图
4.两张画之间角色不稳定
5.一些细粒度的特征不好控制(比如表情、衣服颜色、色系)
6.动作控制极不方便
7.动态效果表示很不容易
8.图分区域控制极不方便
为了让diffusion系列模型变的更可控,各企业、实验室和科研人员可谓下足功夫。这篇文章整理了在可控图生成方面近期比较大的、个人觉得比较有前景的几个方向做介绍。
1.介绍diffusion model的模型结构,以及它的一些数学理论
2.用文字来控制作图SD模型
3.让作图在结构层面可控的controlnet
4.给参考例子让模型仿照作图,promptdiffusion
5.让文本字典更适合人类习惯,perfDiffusion
从更宏观视角来看,解决文本生成图的思路就三大类:
1.引入更多的信息
2.让控制指令结构化,统一化,减少数据稀疏行;调整图文映射空间,让文本指令能够更好表达人类意图
3.incontext learn,给例子让模型造样作图
controlnet、image2image的思路就是引入更多的图结构画的信息,让图的布局更可控,让图的生成有上下文;promptdiffusion已经有incontext learn的意思,给例子让模型造样作图;prompt2prompt的思路就是让文本控制指令结构化,对文本生成图更结构化,抽象出一个作图描述的结构,让稀疏数据聚成一类,让生成过程更可控;风格化lora、textual做法就是拉齐图文映射空间距离,让输入的词更能够表达用户意图,以便更好的画出符合人类心理预期的画。MJ现在的做法会更进一步,把上面的各种思路融合在一起,直接用一个多模态模型来解决多个思路需要多个模型分开解决的问题,从数据收集、到训练数据整理做格式化,让模型从设计、训练就能满足用户需求,所以用户使用体感就是,它懂我能够比较精准把握心理想要做出图的预期,并且在审美上超越我。
模型介绍
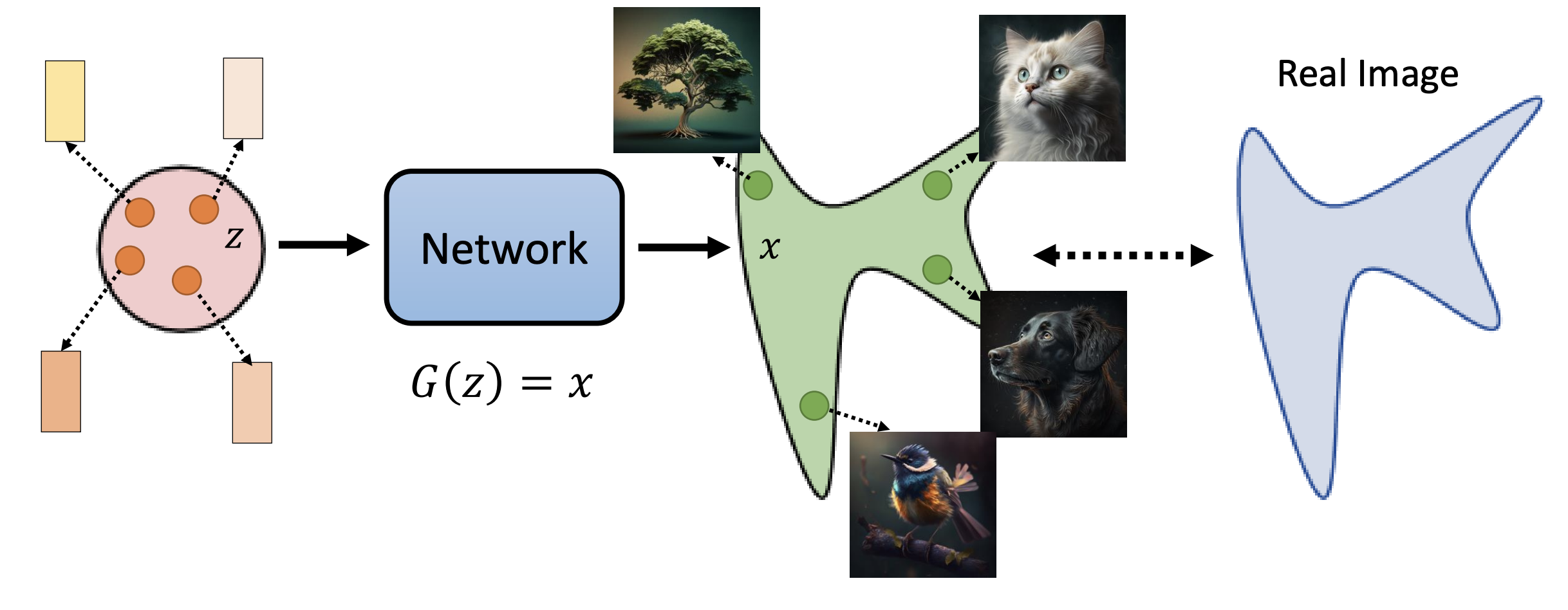
图生成的数据建模如上:
1.Z就是图空间,就是这张图片在现实中出现的概率分布
2.Network是对图pixel空间分布建模,就是每张图的构成是由各种特征符合一定数学分布构造出来的
3.x是对pixel空间产出现实中图的分布映射,也就是pixel特征分布构造出来的图的分布
Z、X空间每种算法基本差异不大,大部分的差异在于Network部分,不同的思路就是对pixel像素空间构图的物理建模理解差异。比如VAE的假设是,pixel的特征是符合multi-gussion分布的,也就是一张图其实就是多种特征的不同高斯组合出来的,每张图都可以分解成不同特征的、每个特征的高斯分布(成分差异)差异导致图片差异。Diffusion模型的假设是图的生成过程是一个随机过程,由一个序列的随机分布层组成,多个层合并在一起就构成差异化的图,每个随机分布层也是有pixel特征的不同高斯分布(成分差异)组成,换句话说就是Diffusion其实是一个序列的VAE过程。
利用上面图生成的数学建模,只要能够把每个阶段的分布参数学到,那么这个数学模型就是确定的。也就是整个图的生成过程就是可控的,可以在数学模型的任何过程和阶段给些input,那就能够按要求产出想要的图。求解这个数学模型参数的过程,就是模型训练过程。类似高中、大学求解方程组,只要给到足够的X、Y对那么方程的隐参数就是可以求解出来的。
Diffusion
扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process),其中前向过程又称为为扩散过程(diffusion process)。无论是前向过程还是反向过程都是一个参数化的马尔可夫链(Markov chain),其中反向过程可以用来生成数据,通过变分推断来进行建模和求解。
前向过程

扩散过程是指的对数据逐渐增加高斯噪音直至数据变成随机噪音的过程。对于原始数据,总共包含步的扩散过程的每一步都是对上一步得到的数据按如下方式增加高斯噪音:
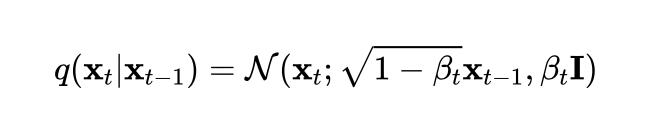
这里为每一步所采用的方差,它介于0~1之间。对于扩散模型,往往称不同step的方差设定为variance schedule或者noise schedule,通常情况下,越后面的step会采用更大的方差,即满足。在一个设计好的variance schedule下,的如果扩散步数足够大,那么最终得到的就完全丢失了原始数据而变成了一个随机噪音。 扩散过程的每一步都生成一个带噪音的数据,整个扩散过程也就是一个马尔卡夫链:
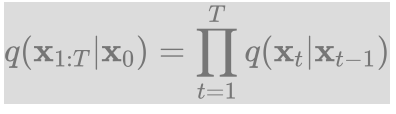
反向过程
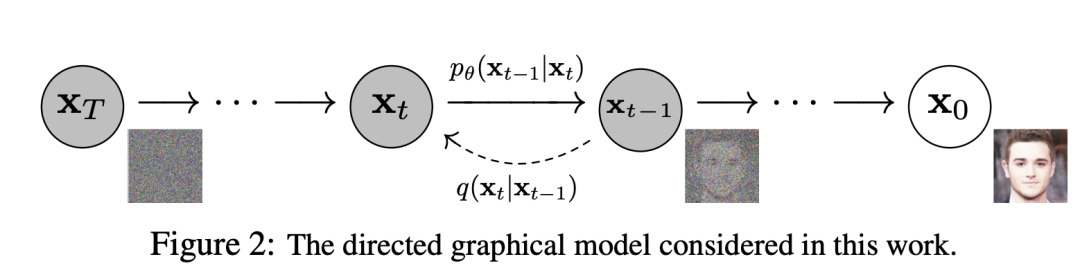
扩散过程是将数据噪音化,那么反向过程就是一个去噪的过程,如果知道反向过程的每一步的真实分布,那么从一个随机噪音开始,逐渐去噪就能生成一个真实的样本,所以反向过程也就是生成数据的过程。
估计分布需要用到整个训练样本,可以用神经网络来估计这些分布。这里,将反向过程也定义为一个马尔卡夫链,只不过它是由一系列用神经网络参数化的高斯分布来组成:
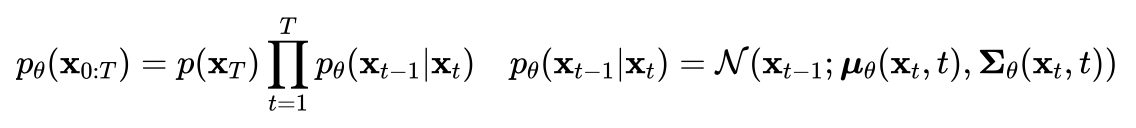
扩散模型就是要得到这些训练好的网络,因为它们构成了最终的生成模型。
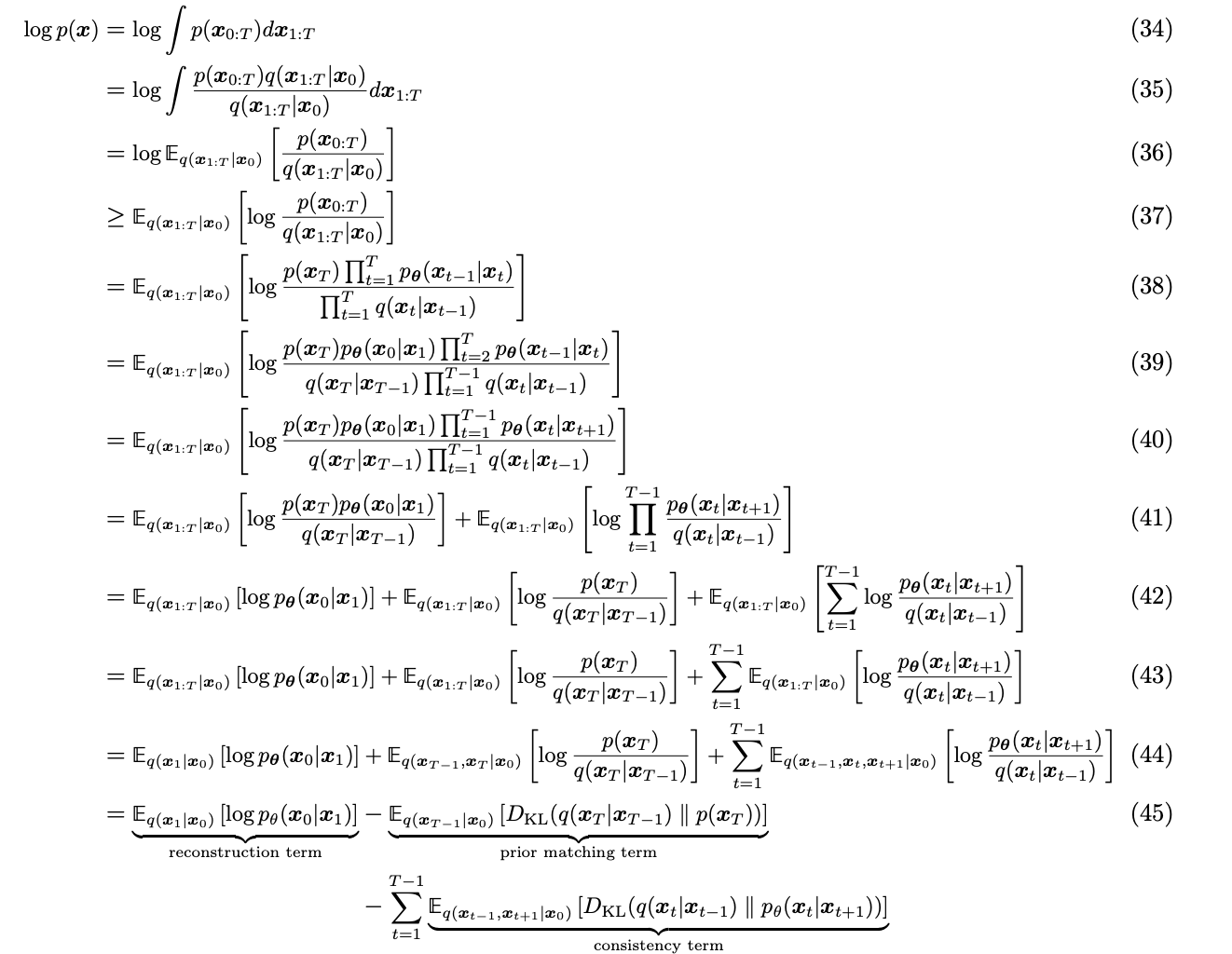
经过复杂的假设和推导,可以得出求解方程如上。具体的求解推导过程可以参考下面论文:
https://arxiv.org/pdf/2208.11970.pdf
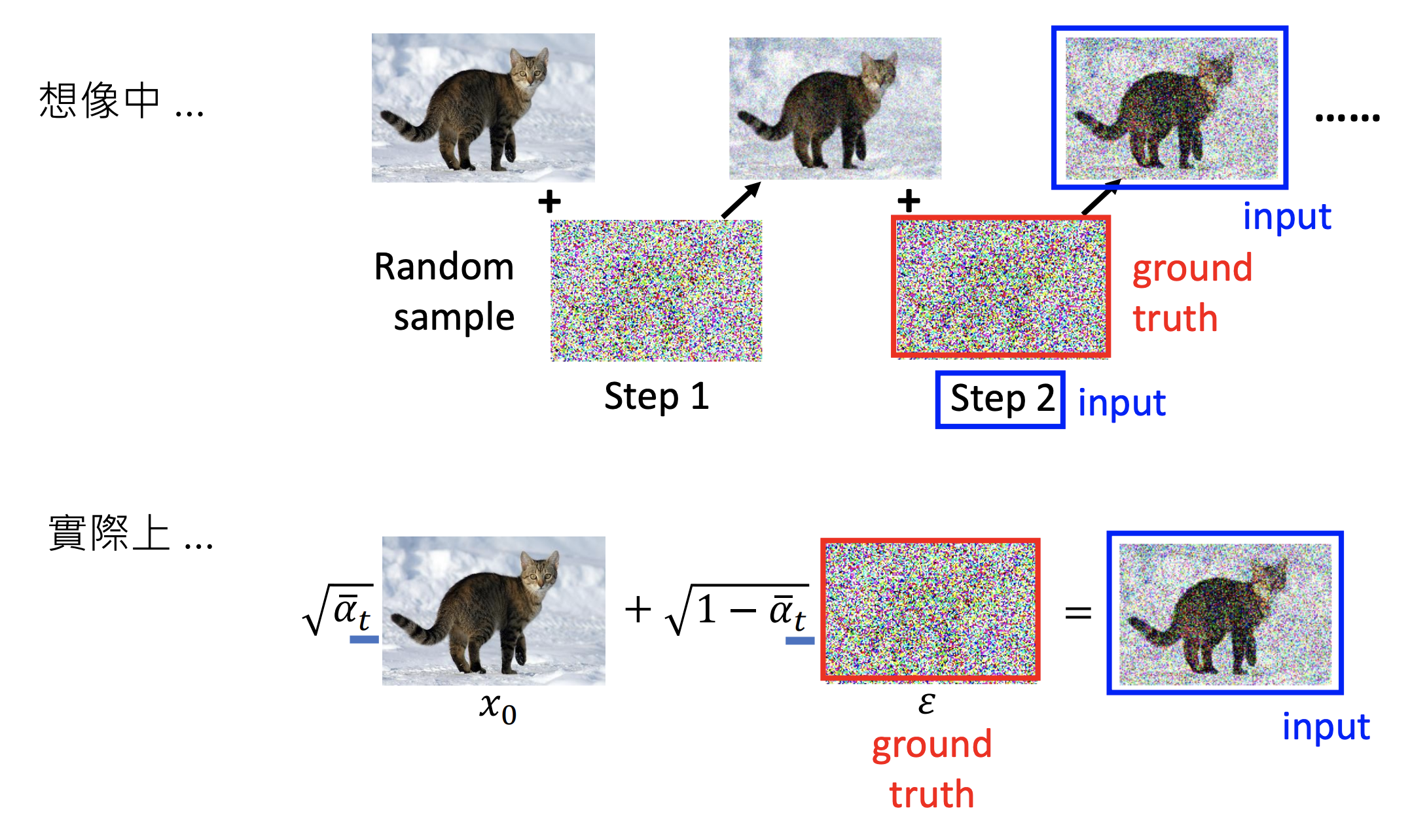
虽然扩散模型背后的推导比较复杂,但是最终得到的优化目标非常简单,就是让网络预测的噪音和真实的噪音一致。DDPM的训练过程也非常简单,如下图所示:随机选择一个训练样本->从1-T随机抽样一个t->随机产生噪音-计算当前所产生的带噪音数据(红色框所示)->输入网络预测噪音->计算产生的噪音和预测的噪音的L2损失->计算梯度并更新网络。

一旦训练完成,其采样过程也非常简单,如上所示:从一个随机噪音开始,并用训练好的网络预测噪音,然后计算条件分布的均值(红色框部分),然后用均值加标准差乘以一个随机噪音,直至t=0完成新样本的生成(最后一步不加噪音)。不过实际的代码实现和上述过程略有区别(见https://github.com/hojonathanho/diffusion/issues/5:先基于预测的噪音生成,并进行了**clip处理**(范围[-1, 1],原始数据归一化到这个范围),然后再计算均值。我个人的理解这应该算是一种约束,既然模型预测的是噪音,那么也希望用预测噪音重构处理的原始数据也应该满足范围要求。
用图来更直观的表示前向和反向推理过程下面图,具体可以参考李宏毅老师最新的讲解diffusion model的视频。
训练部分

推理部分
模型设计
前面介绍了扩散模型的原理以及优化目标,那么扩散模型的核心就在于训练噪音预测模型,由于噪音和原始数据是同维度的,所以可以选择采用AutoEncoder架构来作为噪音预测模型。DDPM所采用的模型是一个基于residual block和attention block的U-Net模型。如下所示:

U-Net属于encoder-decoder架构,其中encoder分成不同的stages,每个stage都包含下采样模块来降低特征的空间大小(H和W),然后decoder和encoder相反,是将encoder压缩的特征逐渐恢复。U-Net在decoder模块中还引入了skip connection,即concat了encoder中间得到的同维度特征,这有利于网络优化。DDPM所采用的U-Net每个stage包含2个residual block,而且部分stage还加入了self-attention模块增加网络的全局建模能力。 另外,扩散模型其实需要的是个噪音预测模型,实际处理时,可以增加一个time embedding(类似transformer中的position embedding)来将timestep编码到网络中,从而只需要训练一个共享的U-Net模型。具体地,DDPM在各个residual block都引入了time embedding,如上图所示。
StableDiffusion
Diffussion Model其实是一个产图的数学建模框架,输入可以是直接像素级别的图做生成,也可以是把像素空间图压倒latent空间。最开始Diffusion的模型还真是直接把像素级别的图输入训练模型,一张图的数据量是很大的,所以为了让模型可以训练输入的图都是小尺寸图,生成后在做图超分生成大图。现实中的图其实尺寸是各异的、并且图也比较大,并非所有的图都适合压缩尺寸然后拿来训练,所以为了解决这一现实问题stablediffusion 提出把图用图特征抽取模型抽取latent特征来做训练。
(下面部分参考自硬核解读Stable Diffusion(系列一))
SD是一个基于latent的扩散模型,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于Latent Diffusion这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。
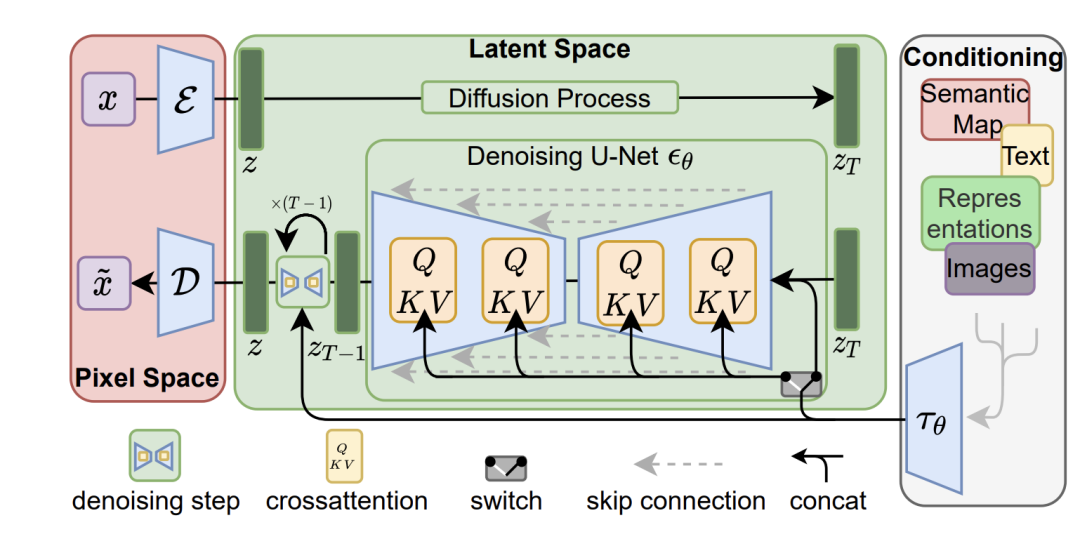
基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势。文生图模型往往参数量比较大,基于pixel的方法往往限于算力只生成64x64大小的图像,比如OpenAI的DALL-E2和谷歌的Imagen,然后再通过超分辨模型将图像分辨率提升至256x256和1024x1024;而基于latent的SD是在latent空间操作的,它可以直接生成256x256和512x512甚至更高分辨率的图像。
SD模型的主体结构如下图所示,主要包括三个模型:
- autoencoder:encoder将图像压缩到latent空间,而decoder将latent解码为图像;
- CLIP text encoder:提取输入text的text embeddings,通过cross attention方式送入扩散模型的UNet中作为condition;
- UNet:扩散模型的主体,用来实现文本引导下的latent生成。
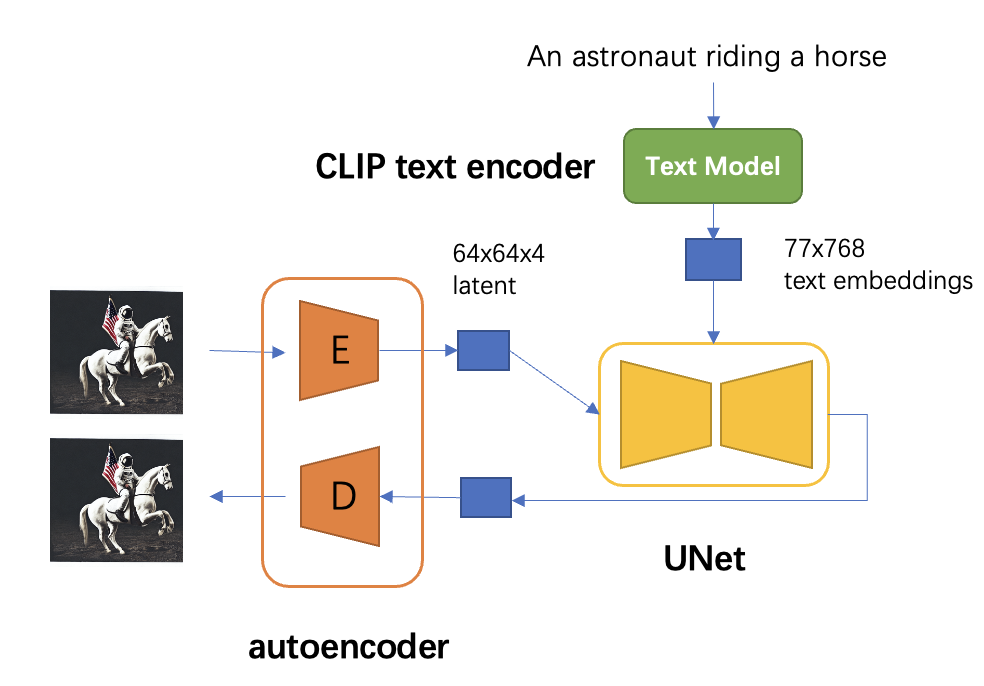
对于SD模型,其autoencoder模型参数大小为84M,CLIP text encoder模型大小为123M,而UNet参数大小为860M,所以SD模型的总参数量约为1B。
autoencoder
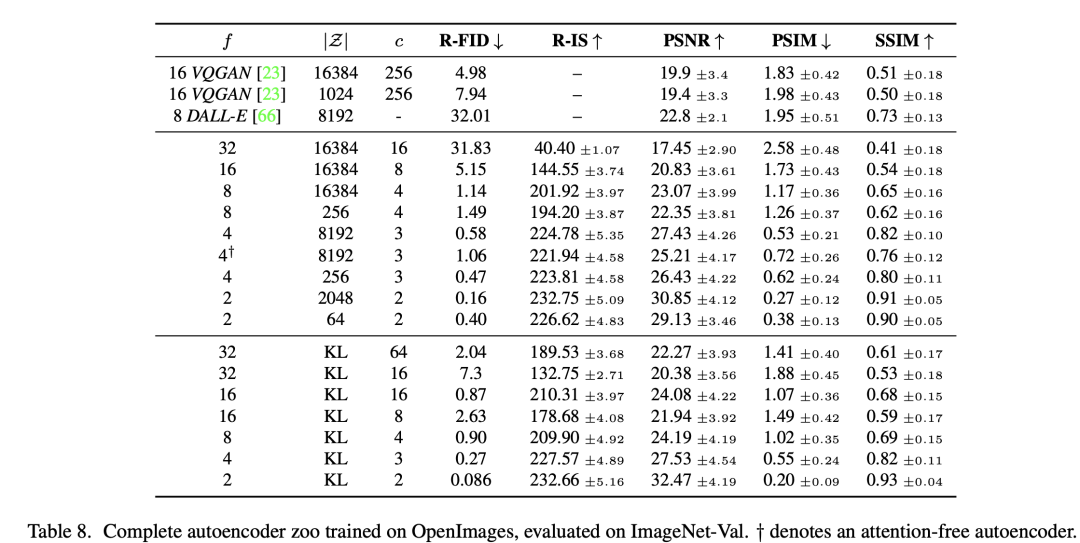
autoencoder是一个基于encoder-decoder架构的图像压缩模型,对于一个大小为的输入图像,encoder模块将其编码为一个大小为的latent,其中为下采样率(downsampling factor)。在训练autoencoder过程中,除了采用L1重建损失外,还增加了感知损失(perceptual loss,即LPIPS,具体见论文The Unreasonable Effectiveness of Deep Features as a Perceptual Metric)以及基于patch的对抗训练。辅助loss主要是为了确保重建的图像局部真实性以及避免模糊,具体损失函数见latent diffusion的loss部分。同时为了防止得到的latent的标准差过大,采用了两种正则化方法:第一种是KL-reg,类似VAE增加一个latent和标准正态分布的KL loss,不过这里为了保证重建效果,采用比较小的权重(~10e-6);第二种是VQ-reg,引入一个VQ (vector quantization)layer,此时的模型可以看成是一个VQ-GAN,不过VQ层是在decoder模块中,这里VQ的codebook采样较高的维度(8192)来降低正则化对重建效果的影响。latent diffusion论文中实验了不同参数下的autoencoder模型,如下表所示,可以看到当较小和较大时,重建效果越好(PSNR越大),这也比较符合预期,毕竟此时压缩率小。
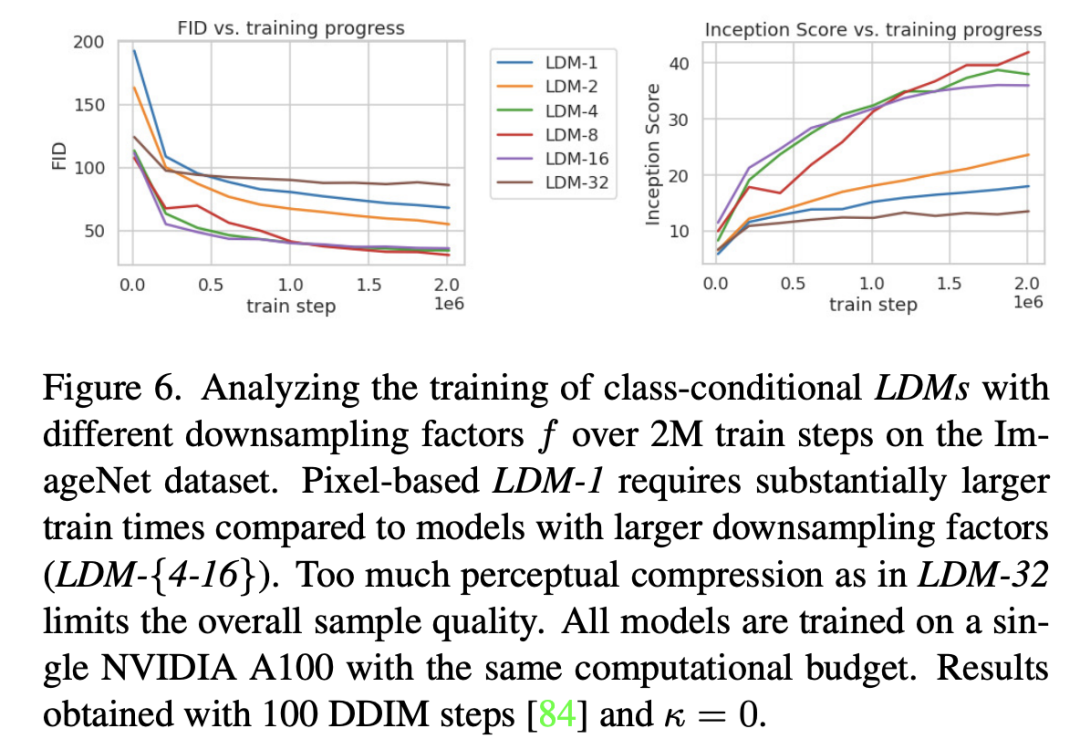
论文进一步将不同的autoencoder在扩散模型上进行实验,在ImageNet数据集上训练同样的步数(2M steps),其训练过程的生成质量如下所示,可以看到过小的(比如1和2)下收敛速度慢,此时图像的感知压缩率较小,扩散模型需要较长的学习;而过大的其生成质量较差,此时压缩损失过大。
当在4~16时,可以取得相对好的效果。SD采用基于KL-reg的autoencoder,其中下采样率,特征维度为,当输入图像为512x512大小时将得到64x64x4大小的latent。autoencoder模型时在OpenImages数据集上基于256x256大小训练的,但是由于autoencoder的模型是全卷积结构的(基于ResnetBlock),所以它可以扩展应用在尺寸>256的图像上。
CLIP text encoder
SD采用CLIP text encoder来对输入text提取text embeddings,具体的是采用目前OpenAI所开源的最大CLIP模型:clip-vit-large-patch14,这个CLIP的text encoder是一个transformer模型(只有encoder模块):层数为12,特征维度为768,模型参数大小是123M。对于输入text,送入CLIP text encoder后得到最后的hidden states(即最后一个transformer block得到的特征),其特征维度大小为77x768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中。
值得注意的是,这里的tokenizer最大长度为77(CLIP训练时所采用的设置),当输入text的tokens数量超过77后,将进行截断,如果不足则进行paddings,这样将保证无论输入任何长度的文本(甚至是空文本)都得到77x768大小的特征。在训练SD的过程中,CLIP text encoder模型是冻结的。在早期的工作中,比如OpenAI的GLIDE和latent diffusion中的LDM均采用一个随机初始化的tranformer模型来提取text的特征,但是最新的工作都是采用预训练好的text model。比如谷歌的Imagen采用纯文本模型T5 encoder来提出文本特征,而SD则采用CLIP text encoder,预训练好的模型往往已经在大规模数据集上进行了训练,它们要比直接采用一个从零训练好的模型要好。
UNet
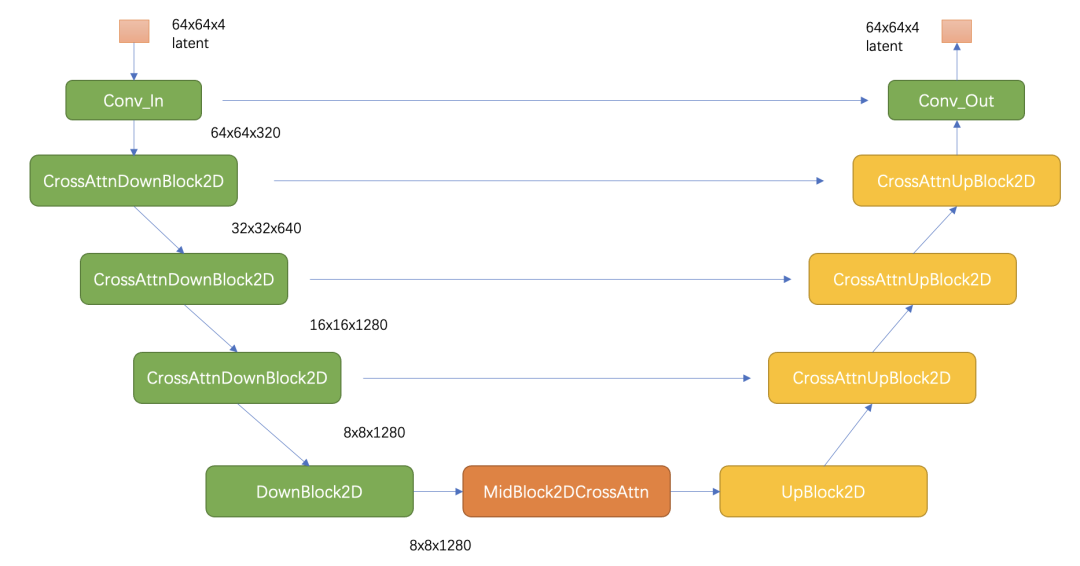
SD的扩散模型是一个860M的UNet,其主要结构如下图所示(这里以输入的latent为64x64x4维度为例),其中encoder部分包括3个CrossAttnDownBlock2D模块和1个DownBlock2D模块,而decoder部分包括1个UpBlock2D模块和3个CrossAttnUpBlock2D模块,中间还有一个UNetMidBlock2DCrossAttn模块。encoder和decoder两个部分是完全对应的,中间存在skip connection。注意3个CrossAttnDownBlock2D模块最后均有一个2x的downsample操作,而DownBlock2D模块是不包含下采样的。
其中CrossAttnDownBlock2D模块的主要结构如下图所示,text condition将通过CrossAttention模块嵌入进来,此时Attention的query是UNet的中间特征,而key和value则是text embeddings。SD和DDPM一样采用预测noise的方法来训练UNet,其训练损失也和DDPM一样:这里的为text embeddings,此时的模型是一个条件扩散模型。
在训练条件扩散模型时,往往会采用Classifier-Free Guidance(这里简称为CFG),所谓的CFG简单来说就是在训练条件扩散模型的同时也训练一个无条件的扩散模型,同时在采样阶段将条件控制下预测的噪音和无条件下的预测噪音组合在一起来确定最终的噪音,具体的计算公式如下所示:
这里的为guidance scale,当越大时,condition起的作用越大,即生成的图像其更和输入文本一致。CFG的具体实现非常简单,在训练过程中,只需要以一定的概率(比如10%)随机drop掉text即可,这里可以将text置为空字符串(前面说过此时依然能够提取text embeddings)。这里并没有介绍CLF背后的技术原理,感兴趣的可以阅读CFG的论文Classifier-Free Diffusion Guidance以及guided diffusion的论文Diffusion Models Beat GANs on Image Synthesis。CFG对于提升条件扩散模型的图像生成效果是至关重要的。
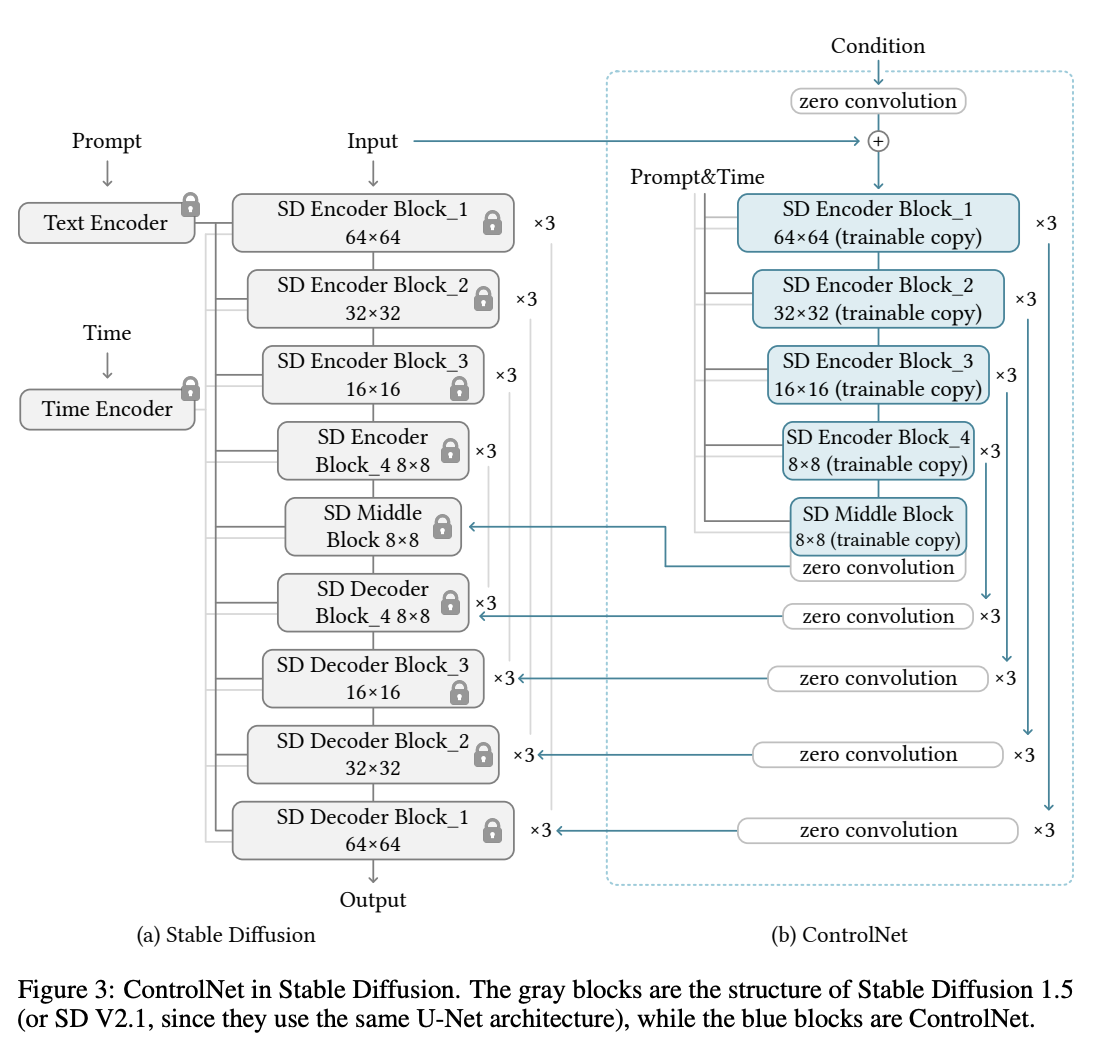
Controlnet
ControlNet,用于控制预训练的大型扩散模型,以支持额外的输入条件。ControlNet以端到端的方式学习任务特定的条件,即使训练数据集很小(< 50k),学习也很稳健。此外,训练ControlNet与微调扩散模型一样快,而且模型可以在个人设备上进行训练。如果有强大的计算集群可用,模型可以扩展到大量(百万到十亿)的数据。我们报告说,像稳定扩散这样的大型扩散模型可以通过ControlNet增强,以实现条件输入,如边缘图、分割图、关键点等。这可能丰富了控制大型扩散模型的方法,并进一步促进相关应用。
大型文本到图像模型的出现,生成视觉上吸引人的图像可能只需要用户输入一段简短的描述性提示。在输入一些文本并获取图像后,我们可能会自然地想到几个问题:这种基于提示的控制是否满足我们的需求?例如,在图像处理中,考虑到许多有明确问题表述的长期任务,这些大型模型是否可以应用于促进这些特定任务?我们应该构建什么样的框架来处理广泛的问题条件和用户控制?在特定任务中,大型模型是否能保持从数十亿张图像中获得的优势和能力? 首先,在特定领域的任务中,可用的数据规模并不总是与一般的图像文本领域一样大。许多特定问题(如物体形状/法线、姿态理解等)的最大数据集大小通常在10万以下,即比LAION5B小5 × 104倍。这就需要稳健的神经网络训练方法,以避免过拟合,并在大型模型被训练用于特定问题时保持泛化能力。 其次,当图像处理任务采用数据驱动的解决方案时,并不总是有大型计算集群可用。这使得快速训练方法对于在可接受的时间和内存空间内(例如,在个人设备上)优化大型模型到特定任务非常重要。这进一步要求利用预训练的权重,以及微调策略或迁移学习。 第三,各种图像处理问题有不同形式的问题定义、用户控制或图像注释。在解决这些问题时,虽然可以以“程序化”的方式调节图像扩散算法,例如,约束去噪过程、编辑多头注意力激活等。
controlNet,用于控制大型图像扩散模型(如稳定扩散),以学习任务特定的输入条件。ControlNet将大型扩散模型的权重克隆为“可训练副本”和“锁定副本”:锁定副本保留了从数十亿张图像中学习的网络能力,而可训练副本则在特定任务的数据集上进行训练,以学习条件控制。可训练和锁定的神经网络块通过一种独特类型的卷积层连接,称为“零卷积”,其中卷积权重以学习的方式从零逐渐增长到优化参数。由于生产就绪的权重被保留,因此训练在不同规模的数据集上是稳健的。由于零卷积不会向深层特征添加新的噪声,因此训练与微调扩散模型一样快,相比之下,从头开始训练新层。 我们使用不同条件的各种数据集训练了几个ControlNet,例如,Canny边缘、Hough线、用户涂鸦、人体关键点、分割图、形状法线、深度等。我们还用小数据集(样本数小于5万甚至1千)和大数据集(百万级样本)实验了ControlNet。我们还展示了在一些像深度到图像这样的任务中,使用个人计算机(一台Nvidia RTX 3090TI)训练ControlNet可以达到与商业模型竞争的结果,而这些商业模型是在拥有太字节级GPU内存和数千个GPU小时的大型计算集群上训练的。
Canny边缘
我们使用Canny边缘检测器[5](随机阈值)从互联网上获取300万个边缘图像标题对。该模型使用Nvidia A100 80G训练了600个GPU小时。基础模型是稳定扩散1.5。
Canny边缘(Alter)
对上述Canny边缘数据集的图像分辨率进行排序,并采样了几个子集,其中包含1k、10k、50k、500k个样本。我们使用相同的实验设置来测试数据集规模的影响。
Hough线
使用基于学习的深度霍夫变换[13]从Places2 [66]中检测直线,然后使用BLIP [34]生成标题。获得了60万个边缘图像标题对。使用上述Canny模型作为起始检查点,并使用Nvidia A100 80G训练了150个GPU小时。
HED边界
使用HED边界检测[62]从互联网上获取300万个边缘图像标题对。该模型使用Nvidia A100 80G训练了300个GPU小时。基础模型是稳定扩散1.5。
用户素描
使用HED边界检测[62]和一组强大的数据增强(随机阈值、随机屏蔽掉一定百分比的涂鸦、随机形态变换和随机非最大抑制)的组合从图像中合成人类涂鸦。从互联网上获得了50万个涂鸦图像标题对。使用上述Canny模型作为起始检查点,并使用Nvidia A100 80G训练了150个GPU小时。也尝试了一种更“人性化”的合成方法[57],但这种方法比简单的HED慢得多,而且我们没有注意到明显的改进。
人体姿态(Openpose)
使用基于学习的姿态估计方法[6]来从互联网上找到人类,使用与上述Openpifpaf设置相同的规则。我们获得了20万个姿态图像标题对。注意,我们直接使用带有人体骨架的可视化姿态图像作为训练条件。该模型使用Nvidia A100 80G训练了300个GPU小时。其他设置与上述Openpifpaf相同。
语义分割(COCO)
COCO-Stuff数据集4由BLIP[34]标注。获得了164K分割图像标题对。该模型使用Nvidia RTX 3090TI训练了400个GPU小时。基础模型是稳定扩散1.5。语义分割(ADE20K) ADE20K数据集[67]由BLIP[34]标注。获得了164K分割图像标题对。该模型使用Nvidia A100 80G训练了200个GPU小时。基础模型是稳定扩散1.5。
深度(大规模)
使用Midas [30]从互联网上获得300万个深度图像标题对。该模型使用Nvidia A100 80G训练了500个GPU小时。基础模型是稳定扩散1.5。
深度(小规模)
对上述深度数据集的图像分辨率进行排序,以采样一个包含20万对的子集。这个集合用于实验训练模型所需的最小数据集大小。
法线图
使用DIODE数据集[56],由BLIP[34]标注。获得了25,452个法线图像标题对。该模型使用Nvidia A100 80G训练了100个GPU小时。基础模型是稳定扩散1.5。
法线图(扩展)
使用Midas [30]计算深度图,然后进行法线-距离转换,得到“粗糙”的法线图。使用上述法线模型作为起始检查点,并使用Nvidia A100 80G训练了200个GPU小时。
卡通线条绘画
使用一种卡通线条绘画提取方法[61]从互联网上的卡通插画中提取线条绘画。通过按照流行度对卡通图像进行排序,获得了前100万个线条-卡通-标题对。该模型使用Nvidia A100 80G训练了300个GPU小时。基础模型是Waifu Diffusion(一个有趣的社区开发的变体模型,来自稳定扩散[36])。)
PromptDiffusion
大语言模型(LLM)比如GPT的一个很重要的能力是它的In-Context Learning能力,所谓In-Context Learning是指只需要给定一个任务的一些具体例子(包含输入和输出)作为context,模型就能够对新例子(输入)执行这个任务(输出),下图是GPT-3论文中的In-Context Learning方法,这里的任务是机器翻译(将英语翻译成法语),这里的输入其实包含了“任务描述”+“任务例子”+“prompt”,这里的prompt就是这个任务的一个新输入。当任务例子只有一个时,In-Context Learning其实就变成了one-shot learning,而任务例子超过1个时,其实就是few-shot learning。注意In-Context Learning是利用LLM本身预训练学习到的知识而不需要去finetune模型。
PromptDiffusion就是让文生图模型Stable Diffusion拥有这样的In-Context Learning。PromptDiffusion的目标是通过实现In-Context Learning能力,达到和ControlNet一样的可控生成效果。这里设计的prompt如下所示,其中“exmaple: (image1 → image2)”就是任务的一个具体示例,比如这里的任务实现从hed map到图像的生成,而“image3”是这个任务的一个新输入(一个hed map),然后再给定对应的“text-guidance”,模型就能够生成和“image3”以及“text-guidance”匹配的图像。

PromptDiffusion其实设计的是一个one-shot learning,原始的SD并没有这样的能力,所以PromptDiffusion设计了一个具体的数据集(或者说instruction dataset)来finetune SD。这里选择的是6个任务,包括depth map -> image,hed map -> image,segmentation map -> image以及它们对应的逆任务,如下所示:

训练数据集是采用InstructPix2Pix中使用的图像文本对数据集,共包含310k个样本,训练过程每个样本只需要随机选择一个任务构建具体的prompt,对于map -> image的任务,其对应的prompt的text guidance是image caption,而逆任务的text guidance则是map的描述,比如“hed maps”。
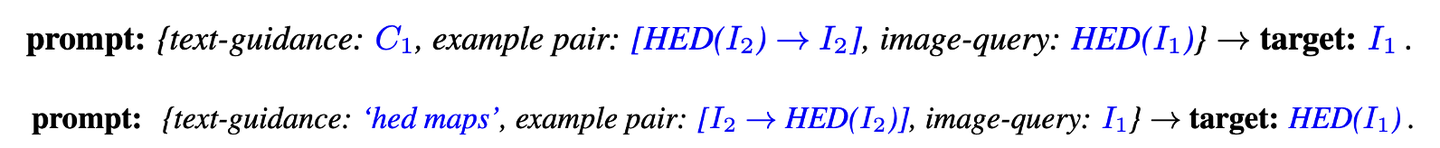
原始的SD只接受text输入,而现在还要接受3个额外的图像,所以需要模型架构上也要进行调整,这里借鉴了ControlNet,如下所示:

这里也像ControlNet一样复制了一个UNet的encoder,不过是额外增加了两个轻量级的网络(stacked convolutional layers)将example和image query映射到和UNet的输入同空间维度大小的特征上。具体的,是将example中的两个图像拼接在一起通过第一个网络得到特征,然后image query通过第二个网络得到特征,两个特征加在一起再送入ControlNet中。要注意的是,这里只freeze了原始UNet的encoder,而其它模块是进行微调的。 在具体效果上,PromptDiffusion在训练过程中见过的这6个任务上表现还是比较好的,如下所示:

PromptDiffusion选择了3个新的任务(scribble -> image,canny edge -> image,normal map -> image)来评测泛化能力,如下所示,可以看到模型是能够泛化到新的生成任务上的:

另外PromptDiffusion可以用于图像编辑任务,当只输入image query时(不输入examle),模型其实也是可以生成匹配的图像的,如下图中的one-step,利用这个功能就可以实现图像编辑:给定图像,首先生成对应的condition map,然后再根据condition map+text生成编辑后的图像。不过,这个没看出来具体的优势,因为直接拿图像对应的condition map也可以生成比较一致的图像。

PerDiffusion
文本到图像模型(T2I)通过允许用户通过自然语言指导创作过程,提供了一种新的灵活性。然而,将这些模型个性化以与用户提供的视觉概念保持一致仍然是一个具有挑战性的问题。T2I个性化的任务提出了多个难题,例如在保持高视觉保真度的同时允许创意控制,将多个个性化概念结合在一张图像中,以及保持小型模型大小。提出了Perfusion,一种T2I个性化方法,它使用动态秩-1更新来解决这些挑战。Perfusion通过引入一种新的机制,将新概念的交叉注意力键“锁定”到它们的超类别,避免了过拟合。此外,开发了一种门控秩-1方法,使能够在推理时控制学习概念的影响,并结合多个概念。这使得在运行时有效地平衡视觉保真度和文本对齐度成为可能,而只需要一个100KB的训练模型,比当前最先进的技术小五个数量级。此外,它还可以在不需要额外训练的情况下,平衡用户不同描述对应图片表达,有较强泛化性。最后,展示了Perfusion在定性和定量方面都优于强基线。重要的是,与传统方法相比,键锁定导致了新颖的结果,使得能够以前所未有的方式描绘个性化对象之间的交互,即使是在单次设置中也是如此。
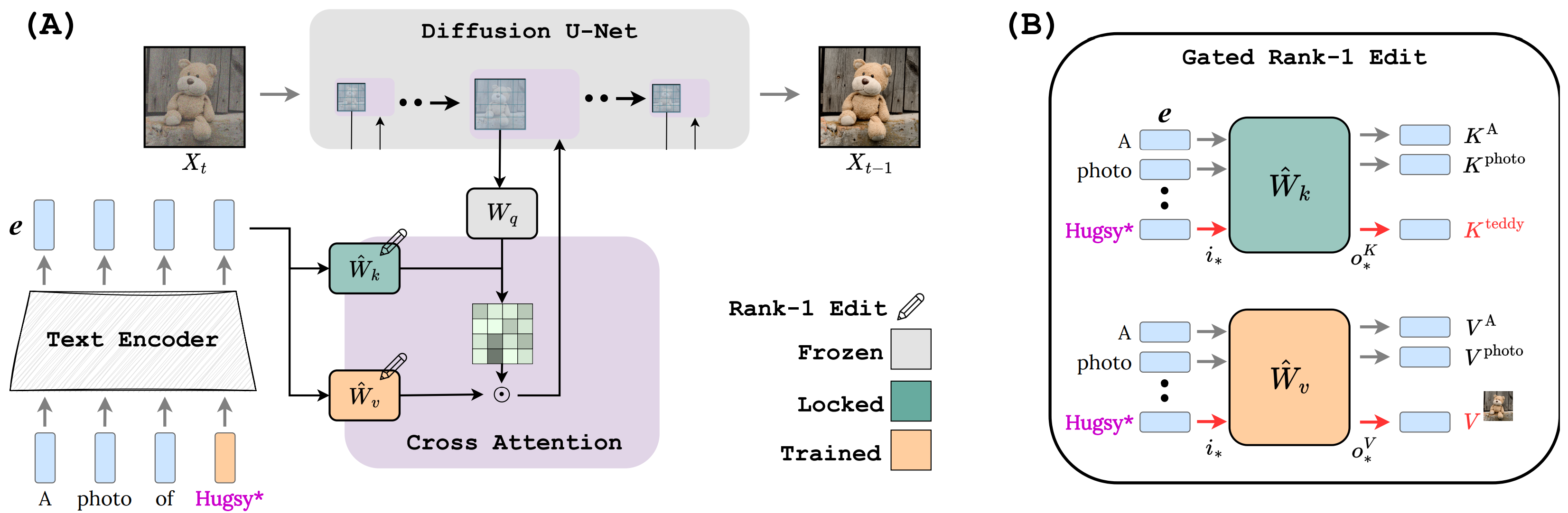
架构概述(A):一个提示被转换为一系列编码。每个编码都被输入到扩散U-Net去噪器的一组交叉注意力模块(紫色块)。放大的紫色模块显示了Key和Value路径如何受文本编码的影响。Key驱动注意力图,然后调制Value路径。门控秩-1编辑(B):顶部:K路径被锁定,所以任何到达𝑊𝑘的𝑒_Hugsy编码都被映射到超类别𝐾_teddy的键。底部:任何到达𝑊𝑣的𝑒_Hugsy编码,都被映射到𝑉_Hugsy,它是学习得到的。这种更新的门控特性允许只对必要的编码进行选择性应用,并提供了调节学习概念强度的方法,如输出图像中所表现的。
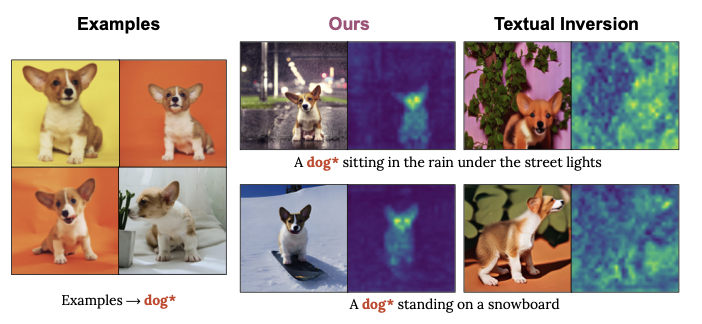
以一种富有表现力和高效的方式对模型进行个性化。texual_inverse,容易出现过拟合,即学习到的概念通过改变包含它的提示很难修改。这个问题源于注意力机制,因为新的概念引起了超出其视觉范围的注意力。texual_inverse中典型的过拟合,是由学习嵌入的注意力占据整个图像造成的。这里可视化了与“dog”单词对应的注意力图。TI注意力区域(右面板)分布在整个图像上,而不是聚焦在对象上。这导致生成过程忽略了提示的其余部分,只描绘了“dog”概念。 接下来,描述Perfusion,一种通过秩-1层编辑来克服这个问题的方法。概述了一种门控机制,它提供了更好的推理时控制,并描述了如何利用它来组合孤立学习的概念。
“在哪里”路径"和“是什么”路径。为了同时提高这两个目标,的关键洞察是,模型需要将生成的内容与生成的位置分离开来,利用交叉注意力机制的解释。𝐾路径——与“键”相关联的那个路径,与创建注意力图有关。它因此充当控制最终图像中对象位置的路径。相比之下,𝑉路径负责向每个区域添加特征。从这个意义上说,它可以控制最终图像中出现的内容。将𝐾映射解释为一个“在哪里”的路径,将𝑉映射解释为一个“是什么”的路径。
避免过拟合。在初步实验中注意到,当从有限数量的示例中学习个性化概念时,“在哪里”路径(𝑾 𝐾 )的模型权重容易过拟合到这些示例中看到的图像布局。显示了个性化示例可能“占据”整个注意力图,并阻止其他单词影响合成的图像。因此通过限制“在哪里”路径来防止这种基于注意力的过拟合。
保持身份。在Image2StyleGAN中,Abdal等人[2019]提出了一种分层潜在表示,以更有效地捕捉身份。在那里,他们不是在生成器的输入空间预测一个单一的潜在代码,而是对合成过程中的每个分辨率预测一个不同的代码。将What(V)路径激活作为一个类似的潜在空间,考虑到它们的紧凑性和底层U-Net去噪器的多分辨率结构。 为了满足这两个目标,考虑这样一个简单的解决方案:每当编码包含目标概念时,确保它的交叉注意力键与其超类别匹配。

零镜头加权损失:使用少量图像示例进行训练容易学习图像背景中的假相关。为了将概念与其背景解耦,通过从零镜头图像分割模型[Lüddecke and Ecker 2021]获得的软分割掩码来加权标准条件扩散损失。掩码值按其最大值进行归一化。 将Perfusion应用于多层:类似于[Gal et al. 2022],对于每个概念,为一个超类别名称选择一个单词。使用该单词来初始化其词嵌入,并将嵌入视为学习参数。将Perfusion编辑应用于UNet去噪器的所有交叉注意力层。对于每个 K路径层(𝑙),预先计算并冻结𝒐𝐾:𝑙 ∗ 为 𝒐𝐾:𝑙 = 𝑾𝑙 𝒆 ,其中提示说“一张<超级 ∗ 𝐾 超类别 class_word>的照片”,并且更新𝒊∗随着训练的进行。在每个V路径层上,将𝒐𝑉 :𝑙视为学习参数。 ∗ 训练细节:用0.03的学习率训练𝒐∗,对于嵌入,设置了0.006的学习率。使用Flash-Attention [Dao et al. 2022; Lefaudeux et al. 2022]使用16的批量大小。只使用翻转增强𝑝 = 50%。不翻转不对称的对象。使用一个由8个提示组成的验证集,每25个训练步骤采样一次,并选择具有最大化CLIP图像相似度得分和CLIP文本相似度得分之间谐波平均值的模型的步骤。在实验细节中更详细地描述了CLIP指标。为了调节生成,随机采样中性上下文文本,这些文本是从CLIP ImageNet模板[Radford et al. 2021]派生的。模板列表提供在补充材料中。 的方法在单个A100 GPU上训练平均210步,花费约4分钟,最多400步(约7 分钟)。
这篇文章主要的工作就是,想让图文特征在映射空间对的更齐,更容易被操控,发现以前texual_inverse文本latent特征和图的latent特征在融合、映射时候注意力不够精准,所以设计了一种新的融合框架,可以更细粒度的对齐文本和图特征,让模型具有更好的文本控制力、并且有zero-shot的泛化能力。
小结
1.介绍了文本生成图提高可控性的几种思路
2.介绍了市面主流的可控模型几个解决方案
3.回归到问题本质,更细粒度的控制更精准的控制才是未来
4.多模态和数据的规范化是未来竞争实力
版权归原作者 远洋之帆 所有, 如有侵权,请联系我们删除。